从性能优化的角度看virtio技术的演进和发展 (1/2)
Posted 宋宝华
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了从性能优化的角度看virtio技术的演进和发展 (1/2)相关的知识,希望对你有一定的参考价值。
作者简介
孙雷,曾在联想研究院和NEC研究院工作10年,任资深研究员,研发经理。
负责云计算底层技术,包括软件定义网络(SDN),云网络(OpenStack),数据面加速等等。2020年起开始创业,北京守志科技有限公司创始人。欢迎赐稿“Linux阅码场”,投稿请扫码微信联系“小月”,稿费300-500RMB(已经以任何形式,如公众号、博客、网站发表过的文章,请勿投稿):

01
virtio性能优化技术的整体梳理
在前一次的virtio基础篇中,我们介绍了virtio的基本原理,QEMU/KVM以及virtio的关系。我们还介绍了virtio设备的发现,初始化以及virtio-net从虚拟机中发送数据包的过程。
这一次的virtio进阶篇会从性能优化的角度,进一步介绍virtio技术演进和发展的过程。包括:
1). vhost-net技术 (virtio-net后端的内核态实现);
2). vhost-user (virtio-net后端在用户态的实现)以及与之紧密联系的DPDK加速技术;
3). vDPA (固化在网卡中virtio-net后端的硬件实现)。
就像我们之前介绍的那样,virtio的设计是分为前端和后端的。
在实现层面上,以virtio网络为例子,在最初的virtio-net的实现中,virtio的前端驱动程序在虚拟机的内核空间运行,而virtio的后端驱动程序实现在QEMU中运行在用户空间,前后端的通信机制是通过KVM(内核模块)实现的。
以虚拟机向外部发送数据为例,虚拟机通过写寄存器的方式通知外部的KVM,再进而通知virtio后端(实现在QEMU中)。在此基础上,又逐步发展出了vhost-net,vhost-user和vDPA三种加速技术。
虽然三种技术的目的都是提升处理网络数据包的能力,但是各自所采用的方法却有很大区别:
1).vhost-net:virtio-net后端以内核模块的方式实现,做为内核线程运行。和virtio-net的实现相比,减少了一次KVM到QEMU通信时的内核态/用户态的切换,让虚拟机的数据在内核态就把报文发送出去,进而提升性能;
2).vhost-user:为了进一步提升虚拟机网络的性能,DPDK完全不再沿用Linux内核的网络数据处理流程,基于Linux UIO技术在用户态直接和网卡交互处理网络数据,并且使用了内存大页,绑定CPU核,NUMA亲和性等方法进一步提升数据处理的性能。配合DPDK技术,virtio-net后端也在用户态做了实现,这就是vhost-user;
3).vDPA:DPDK毕竟还是软件加速方案,并且因为绑定CPU核导致独占相应的CPU资源。虽然提高了网络的性能,却是通过牺牲服务器的计算资源做为代价的。于是,在这样的背景下提出了vDPA (vhost Data Path Acceleration)技术。vDPA技术可以理解为virtio-net后端在网卡中的硬件实现,目前已经被一些网卡厂商支持。
在梳理了这三种技术和virtio-net之间的关系之后,我们接下来结合Linux内核,QEMU以及DPDK的代码深入分析它们的具体实现。
02
vhost-net
接下来我们先结合QEMU和Linux内核的代码回顾一下virtio-net的具体实现,之后再和vhost-net做一个对比,这样才能更好的说明vhost-net的优化思路。
● QEMU的vCPU线程以及IO处理
QEMU是一个多线程的用户态程序。其中启动虚拟机的vCPU线程的实现,可以参考代码qemu-1.5.3/cpus.c中第1073行的qemu_init_vcpu函数。
可以看出,在确认KVM是被使能的情况下,会进一步调用qemu_kvm_start_vcpu函数,再调用qemu_thread_create函数创建执行虚拟机的子线程(也可以叫做vCPU线程)。
由于需要支持多种硬件平台,所以针对不同的体系结构的平台,在qemu_thread_create函数内部做了封装,实现底层平台的上层封装。
比如POSIX平台的实现代码在qemu-1.5.3/util/qemu-thread-posix.c,Windows平台的实现在qemu-1.5.3/util/qemu-thread-win32.c。
void qemu_init_vcpu(void *_env)
{
CPUArchState *env = _env;
CPUState *cpu = ENV_GET_CPU(env);
cpu->nr_cores = smp_cores;
cpu->nr_threads = smp_threads;
cpu->stopped = true;
if (kvm_enabled()) {
qemu_kvm_start_vcpu(env);
} else if (tcg_enabled()) {
qemu_tcg_init_vcpu(cpu);
} else {
qemu_dummy_start_vcpu(env);
}
}
static void qemu_kvm_start_vcpu(CPUArchState *env)
{
CPUState *cpu = ENV_GET_CPU(env);
cpu->thread = g_malloc0(sizeof(QemuThread));
cpu->halt_cond = g_malloc0(sizeof(QemuCond));
qemu_cond_init(cpu->halt_cond);
qemu_thread_create(cpu->thread, qemu_kvm_cpu_thread_fn, env,
QEMU_THREAD_JOINABLE);
while (!cpu->created) {
qemu_cond_wait(&qemu_cpu_cond, &qemu_global_mutex);
}
}
关于QEMU中vCPU的执行(也就是运行虚拟机的线程)和外部IO的处理,可以参考下面的代码qemu-1.5.3/cpus.c第739行的qemu_kvm_cpu_thread_fn函数。其中kvm_cpu_exec是运行虚拟机,qemu_kvm_wait_io_event是处理外部的IO操作,两者都在一个大的死循环中。
结合从虚拟机内部发送数据的例子来说,virtio-net前端(虚拟机中的网卡驱动程序)写寄存器进行IO操作的时候,会触发VM_EXIT,之后KVM检查退出的理由,并且进一步处理IO在执行完IO操作之后,会再继续执行vCPU线程,就这样一直循环下去。
static void *qemu_kvm_cpu_thread_fn(void *arg)
{
CPUArchState *env = arg;
CPUState *cpu = ENV_GET_CPU(env);
int r;
qemu_mutex_lock(&qemu_global_mutex);
qemu_thread_get_self(cpu->thread);
cpu->thread_id = qemu_get_thread_id();
cpu_single_env = env;
r = kvm_init_vcpu(cpu);
if (r < 0) {
fprintf(stderr, "kvm_init_vcpu failed: %s\\n", strerror(-r));
exit(1);
}
qemu_kvm_init_cpu_signals(env);
/* signal CPU creation */
cpu->created = true;
qemu_cond_signal(&qemu_cpu_cond);
while (1) {
if (cpu_can_run(cpu)) {
r = kvm_cpu_exec(env);
if (r == EXCP_DEBUG) {
cpu_handle_guest_debug(env);
}
}
qemu_kvm_wait_io_event(env);
}
return NULL;
}
● QEMU/KVM的通信机制
QEMU/KVM的通信机制是基于eventfd实现的。
eventfd是内核实现的线程通信机制,通过系统调用可以创建eventfd,它可以用于线程间或者进程间的通信,比如用于实现通知,等待机制。
内核也可以通过eventfd和用户空间进程进行通信。eventfd的具体实现可以参考内核代码linux-3.10.0-957.1.3.el7/fs/eventfd.c文件的第25行,主要的数据结构是eventfd_ctx。
通过代码查看数据结构eventfd_ctx,可以看出eventfd的核心实现是在内核空间的一个64位的计数器。不同线程通过读写该eventfd通知或等待对方,内核也可以通过写这个eventfd通知用户程序。
在eventfd被创建之后,系统提供了对eventfd的读写操作的接口。写eventfd的时候,会增加计数器的数值,并且唤醒wait_queue队列;读eventfd的时候,就是将计数器的数值置为0。
struct eventfd_ctx {
struct kref kref;
wait_queue_head_t wqh;
/*
* Every time that a write(2) is performed on an eventfd, the
* value of the __u64 being written is added to "count" and a
* wakeup is performed on "wqh". A read(2) will return the "count"
* value to userspace, and will reset "count" to zero. The kernel
* side eventfd_signal() also, adds to the "count" counter and
* issue a wakeup.
*/
__u64 count;
unsigned int flags;
};
QEMU/KVM通信机制的实现是基于ioeventfd实现,对eventfd又做了一次封装。具体的实现代码在linux-3.10.0-957.1.3.el7/virt/kvm/eventfd.c第642行。
/*
* --------------------------------------------------------------------
* ioeventfd: translate a PIO/MMIO memory write to an eventfd signal.
*
* userspace can register a PIO/MMIO address with an eventfd for receiving
* notification when the memory has been touched.
* --------------------------------------------------------------------
*/
struct _ioeventfd {
struct list_head list;
u64 addr;
int length;
struct eventfd_ctx *eventfd;
u64 datamatch;
struct kvm_io_device dev;
u8 bus_idx;
bool wildcard;
};
在QEMU/KVM的系统虚拟化环境中,针对每个虚拟机,vhost-net会生成一个名为"vhost-[pid]"的内核线程,这里的"pid"即QEMU进程(也称作"hypervisor process")的PID。该内核线程替代了QEMU的等待轮询工作。与virtio-net的实现不同的是,eventfd_signal 唤醒的是内核vhost-net创建的内核线程。这个内核线程负责从虚拟队列中提取报文数据,然后发送给 tap接口。
与virtio-net的实现相比,vhost-net的内核线程在内核态处理网络数据,在发送到tap接口的时候少了一次数据拷贝。具体的实现代码在:linux-3.10.0-957.1.3.el7/drivers/vhost/vhost.c的vhost_dev_set_owner函数,在第486行调用kthread_create函数创建内核线程调用vhost_worker函数进行轮询。
/* Caller should have device mutex */
long vhost_dev_set_owner(struct vhost_dev *dev)
{
struct task_struct *worker;
int err;
/* Is there an owner already? */
if (vhost_dev_has_owner(dev)) {
err = -EBUSY;
goto err_mm;
}
/* No owner, become one */
dev->mm = get_task_mm(current);
worker = kthread_create(vhost_worker, dev, "vhost-%d", current->pid);
if (IS_ERR(worker)) {
err = PTR_ERR(worker);
goto err_worker;
}
dev->worker = worker;
wake_up_process(worker); /* avoid contributing to loadavg */
err = vhost_attach_cgroups(dev);
if (err)
goto err_cgroup;
err = vhost_dev_alloc_iovecs(dev);
if (err)
goto err_cgroup;
return 0;
err_cgroup:
kthread_stop(worker);
dev->worker = NULL;
err_worker:
if (dev->mm)
mmput(dev->mm);
dev->mm = NULL;
err_mm:
return err;
}
EXPORT_SYMBOL_GPL(vhost_dev_set_owner);
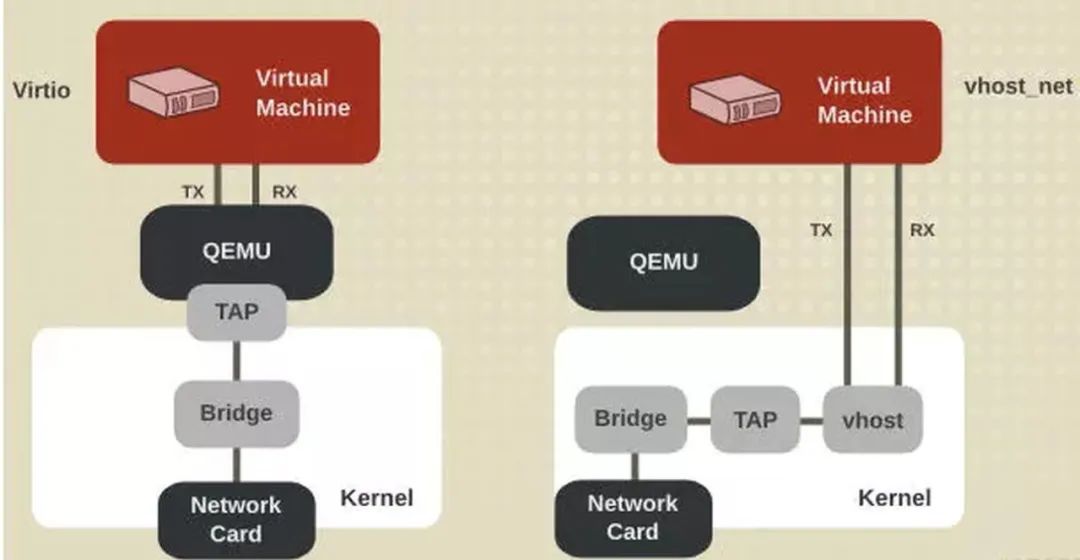
图1 vhost-net和virtio-net的对比图
03
总结
总结一下:虚拟机virtio前端驱动程序发送通知的函数最终是执行I/O写指令。在QEMU/KVM环境中,虚拟机执行I/O指令,会触发VMExit。在KVM的VMExit代码中会判断退出的原因,I/O操作对应的处理函数是handle_io()。接下来KVM是通过eventfd的机制通知virtio-net后端程序来处理。接下来的处理流程,使用virtio-net和vhost-net就不一样了。
Ø 使用virtio-net的情况:KVM会使用eventfd的通知机制,通知用户态的QEMU程序模拟外部I/O事件,所以这里有一次从内核空间到用户空间的切换。
Ø 使用vhost-net的情况:KVM会使用eventfd的通知机制,通知vhost-net的内核线程,这样就直接在vhost内核模块(vhost-net.ko)内处理。所以,和virtio-net相比就减少了一次从内核态到用户态的切换,从而提升网络IO的性能。
由于vhost-user和vDPA都和DPDK紧密相关,所以我们将在virtio进阶篇(2/2)中集中介绍。
敬请期待续集
以上是关于从性能优化的角度看virtio技术的演进和发展 (1/2)的主要内容,如果未能解决你的问题,请参考以下文章