干货 推荐系统评价指标,文末送书!
Posted 机器学习算法与Python学习-公众号
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了干货 推荐系统评价指标,文末送书!相关的知识,希望对你有一定的参考价值。

作者:刘宇 赵宏宇 刘书斌 孙明珠
导读:推荐系统落地到业务中,需要搭建支撑推荐系统的各个模块,其中效果评估模块是非常重要的一个模块。本章通过介绍推荐系统的评价体系、评估方法和评价指标,讲述推荐系统评估模块,包括怎样评估推荐系统的效果、有哪些评估手段、在推荐业务中的哪些阶段进行评估、具体的评估方法。
五一福利
奖品:《智能搜索和推荐系统:原理、算法与应用》x 5
资深技术专家撰写,阿里、美团、Hulu多位专家推荐,零基础掌握搜索和推荐系统原理、架构、算法,以及机器学习、深度学习、NLP在其中应用。
参与方式:文末留言,赞数最多的5位为本次中奖者
开奖时间:2021年5月6号20点
备注:如有问题,请添加小助手微信:MLAPython,备注(姓名-单位-研究方向)
01
推荐评估的目的
推荐系统评估与推荐系统的产品定位息息相关。推荐系统是信息高效分发的手段,用于更快更好地满足用户的不确定需求。所以,推荐系统的精准度、惊喜度、多样性等都是评估的指标。同时,推荐系统要具备稳定性。稳定性可以通过实验评估。在实现方面,是否能支撑大规模用户访问等也是推荐系统评估指标。
推荐系统评估的目的是从上述维度评估推荐系统的实际效果及表现,从中发现优化点,以便能够最好地满足用户需求,为用户提供更优质的推荐服务,同时获取更多的商业利益。
02
推荐系统的评价指标
怎么评估推荐系统?从哪些维度来评估推荐系统?这是评估推荐系统不可回避的两个问题。对于一个推荐系统,我们可以从用户、平台方、标的物、推荐系统本身 4 个维度进行评估,如图 1 所示。
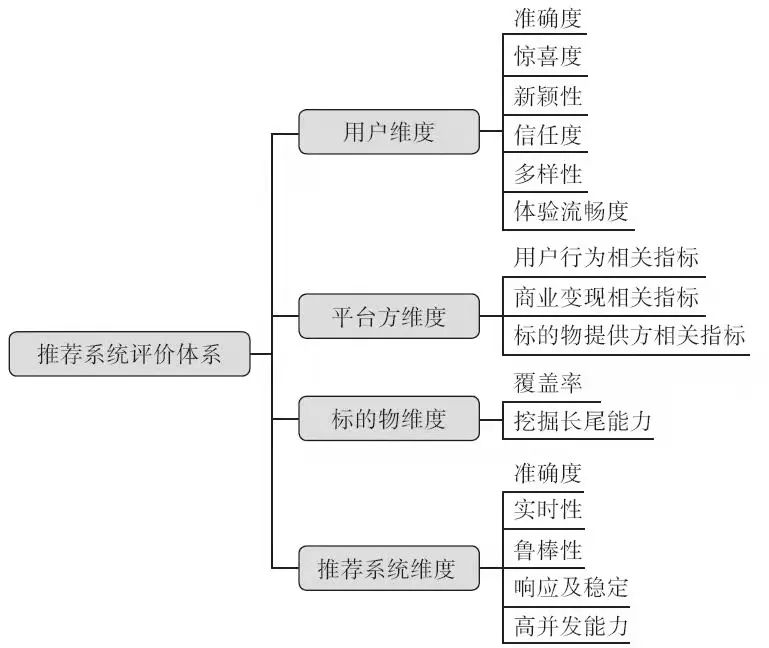
图 1 推荐系统的评价体系
下面分别对这 4 个维度进行介绍。
1. 用户维度
用户维度是指从用户的角度出发,用户喜欢什么,系统就推荐什么。从用户维度看,我们可以从准确度、惊喜度、新颖性、信任度、多样性、体验流畅度这几个方面进行评估。
1)准确度指推荐的物品是不是用户需要的。以视频推荐为例,如果用户点击观看了推荐的电影,说明推荐的电影是用户喜欢的,推荐准确度高。这里的准确度主要表示用户的主观体验。
2)惊喜度指推荐给用户一些完全与他们历史喜欢物品不相似,但是用户却喜欢的物品。这些推荐可能超出用户的预期,给用户一种耳目一新的感觉。
3)新颖性指推荐给用户一些应该感兴趣但是不知道的内容。比如,用户非常喜欢张震岳的歌曲,如果推荐给他《旋风小子》这部电影,假设用户从未听说张震岳演过电影,且用户确实喜欢这部电影,那么当前的推荐就属于新颖推荐。
4)信任度指用户对推荐系统或者推荐结果的认可程度。比如,用户喜欢头条推荐的内容,就会持续点击或浏览系统的推送内容。
5)多样性指推荐系统会提供多品类的标的物,以便拓展用户的兴趣范围及提升用户体验,如图 2 所示。比如,系统推荐了不同风格的音乐,且用户体验效果更好,则认为该系统具有大量的乐曲。
6)体验流畅度指系统与用户交互时,用户体验不会出现卡顿。从系统角度看,要求推
荐系统性能更可靠,提供服务更流畅,不会出现卡顿和响应不及时的情况。
图 2 推荐系统提供多品类标的物
2. 平台维度
平台维度是指从标的物提供方和用户角度出发,通过衡量双方利益来评价整体效益。
因此,我们既可以从标的物提供方进行评价,也可以从用户方的商业价值进行评价,同时可以针对双方进行评价。评价的指标包括商业指标,如大部分互联网产品通过广告赚取的收益。除了关注商业指标外,我们还需要关注用户留存、用户活跃、用户转化等指标。所以从平台维度看,我们可以从以下三类指标评价推荐系统:第一类是用户行为的相关指标;
第二类是商业变现的相关指标;第三类是标的物提供方指标。
(1)用户行为的相关指标
用户行为的相关指标包括以下相关指标。比如,PV(Page View)指标(页面访问率或者页面点击率、页面的刷新次数);日活或月活(周期内活跃用户的数量)指标可以反映用户黏性;留存率(下一个周期留存继续使用的用户)也反映了用户的黏性;转化率(期望的行为数与行为总数的商)。
(2)商业变现的相关指标
商业变现的相关指标可由涉及的具体商业指标衡量。衡量推荐系统商业价值,需要从产品的赢利模式谈起。目前,互联网产品主要有 4 种盈利模式:游戏(游戏开发、游戏代理等)、广告、电商、增值服务(如会员等),后三种模式都可以通过优化推荐技术做得更好。
推荐技术的优化目标可以以商业表现为最终目标,比如考虑提升系统的曝光与转化,提升用户的留存率、活跃度、延长停留时长等。
(3)标的物提供方指标
标的物提供方指标指与商家相关的指标。平台方需要服务好用户和标的物提供方(比如视频网站是需要花钱购买视频版权的)。大部分互联网产品都会通过广告赚取收益。
3. 标的物维度
当然,我们也可以从标的物视角去评价推荐系统,比如通过覆盖率和挖掘长尾用户的
能力去评估。
1)覆盖率主要是考察推荐的覆盖范围。
 式(9-1)中,
式(9-1)中,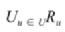 表示所有提供推荐服务的用户的集合,I 表示所有标的物的集合,是给用户 u 推荐的全量物品。
表示所有提供推荐服务的用户的集合,I 表示所有标的物的集合,是给用户 u 推荐的全量物品。
2)挖掘长尾用户的能力是推荐系统的一个重要价值,具体指将小众的标的物分发给喜欢该类标的物的用户的能力。
4. 推荐系统本身的维度
推荐系统本身视角指从自身出发去衡量整个系统的优劣。前面章节在介绍推荐系统时,强调了推荐算法在推荐系统中的重要作用,因此评价推荐系统可以从评价算法出发。在评
价过程中,我们可以考虑从以下几个方面进行。
1)准确度是指核心推荐算法的准确程度。在推荐场景下,无论有监督学习还是无监督学习,机器学习模型都有一定的解决实际问题的能力。所以,我们可以从模型解决实际问题的能力等进行评价。比如,在推荐排序中,我们可以使用准确率、召回率和 nDCG 等指标来评判推荐算法准确度。简单来说,准确率反映的是模型正确预测的结果,召回率反映的是仅考虑预测结果中正召回结果占正确结果的比例,而 nDCG 考量了最终的排序结果与原始排序结果的差异性。
注意,这里的准确度和用户视角的准确度可以一致也可以不一致。用户视角的准确度强调的主观感受,而这里强调客观存在。
2)实时性是指用户的兴趣随时间变化而变化,推荐系统能做到近实时的推荐是非常重要的。
3)鲁棒性是指推荐系统及推荐算法不会因为“脏”数据而脆弱,能够为用户提供稳定的服务。从宏观上讲,推荐系统依赖于用户行为日志;从微观上讲,推荐算法也依赖于用户行为日志。如果用户行为日志产生偏差,推荐系统不会因为“脏”数据影响最终的推荐效果。比如,可以在系统中引入知识图谱,用知识图谱来纠正因用户行为日志产生的偏差,减小“脏”数据对推荐效果产生的负面影响。
3)推荐系统响应推荐服务的时长以及推荐服务的稳定性。推荐服务的稳定包括推荐是否可以正常访问,推荐服务是否挂起等。
4)高并发能力是指推荐服务在较高频次的用户请求下能正常稳定地运行。
补充:在实际生产中,我们遇到的问题往往非常复杂,并且为了让模型能更好地解决当前问题,需要用不同的方法去评价推荐模型。
比如,如果在一个应用场景中采用了单文档排序方法,那么我们会偏向于使用准确率与召回率去评价模型。当然,我们也可以选择使用 nDCG 去评价模型。但是,它对于排序
顺序并不敏感,所以评价结果可能不会太好。如果针对强调排序顺序固定或极其敏感的场
景,通常建议使用 nDCG。
03
评测指标的内容
1. RMSE 和 R 方
前文已经介绍了不少关于测评指标的内容,这里再补充一些,首先是 MAE 和 RMSE。
平均绝对误差(Mean Absolute Error,MAE)是绝对误差的平均值,如公式(9-2)所示:
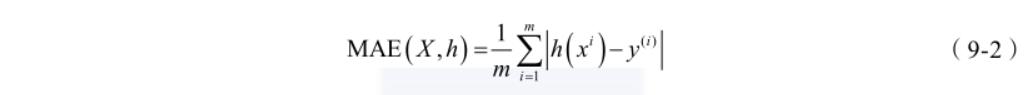
RMSE(Root Mean Square Error,均方根误差)是用来衡量观测值同真实值之间偏差,
如式(9-3)所示:
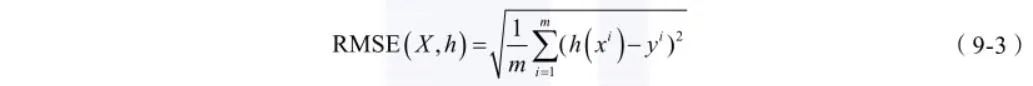
如式(9-2)、(9-3)所示,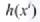 是模型的预测值(观测值),而
是模型的预测值(观测值),而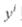 则是真实值。
则是真实值。
与所有的均方根方法一样,RMSE 方法对于异常值比较敏感。通俗地讲,RMSE 方法更能准确地评价同样准确率下的不同模型,能够有效地判定哪一个预测结果更可靠。在场景上,如果不苛求模型的准确度,我们希望模型的预测结果更可靠,那么 RMSE 方法则更适用。
R 方(R-Squared)是一种评价模型与真实值之间拟合程度的方法,如式(9-4)所示:
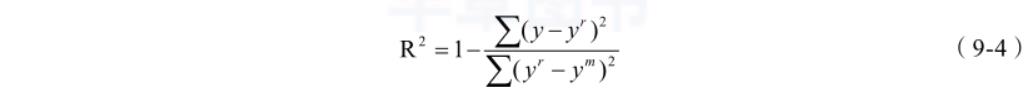
其中,y 是预测值,y r 是真实值而 y m 则是均值。那么,R 2 其实是用平方误差 / 平方差。
这样做的好处在于 R 2 可以简单直接地评价预测值与真实值的耦合程度,即 R 2 =0 时,模型
与真实结果几乎不拟合;R 2 =1 时,模型与真实结果几乎全拟合。同时,R 2 还解决了 RMES
和 MAE 中样本波动的问题。
2. MAP和MRR
MAP(Mean Average Precision,平均正确率),其中 AP 的计算方法如式(9-5)所示:
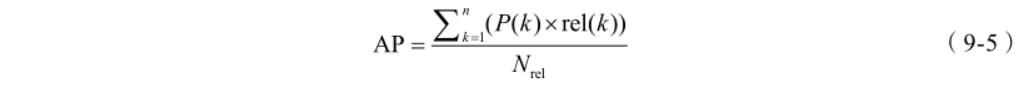
其中,k 为检索结果队列中的排序位置;P(k) 为前 k 个结果的准确率,即 ;
;
N 表示总文档数量;rel(k) 表示位置 k 的文档是否相关,相关为 1,不相关为 0 ;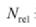 表示相关文档数量。
表示相关文档数量。
MAP 即对将多个查询对应的 AP 求平均。MAP 是反映系统在全部相关文档上性能的单
值指标。系统检索出来的相关文档越靠前,MAP 就可能越高。
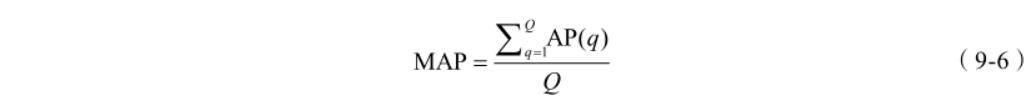
其中,Q 为查询的数量。
MRR(Mean Reciprocal Rank,平均倒数排名)是把标准答案在被评价系统给出结果中的
排序取倒数作为它的准确度,再对所有的问题取平均。该方法的细内容情可以查看第 6 章。
3. 其他相关指标
前文介绍了很多方法去评价模型,但是这些评价结果很可能会随着数据的变动而变动,
所以,我们就需要一个可以无视数据波动的模型效果评价指标。如果我们把召回设定为 TPR,
则有 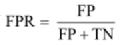 ,以 FPR 作为横坐标,TPR 作为纵坐标,随着阈值的变动可以得到一个用来评价分类器性能的、在 (0,0) 与 (1,1) 之间的线段。
,以 FPR 作为横坐标,TPR 作为纵坐标,随着阈值的变动可以得到一个用来评价分类器性能的、在 (0,0) 与 (1,1) 之间的线段。
这里要特殊说明一下,以二分类模型举例,分类器训练之后得到一个可以利用固定阈值和样本预测值进行分类的模型。在预测值固定不变的情况下,调整阈值,那么分类结果也会随之变动。同理,这个过程中 TPR 和 FPR 也会随之变动。将不同阈值下的 TPR 和FPR 的结果展示在坐标系上,最终就可以得到 ROC 曲线。
AUC 则是 ROC 曲线靠近横坐标侧的面积。因为 ROC 曲线均为凸曲线,所以 AUC的值在 0.5~1 之间浮动。AUC 其实描述的是模型的性能,AUC 越大,当前越存在一个合适的阈值使得模型的分类效果越好。另外,这里还要说明一点的是,为什么 ROC 曲线总是凸曲线?ROC 其实取决于 TPR 和 FPR 之间的变换关系,一旦预测结果为凹曲线,我们只需要调换正负预测关系,则凹曲线自然就变换成了凸曲线。如果模型使用场景更需要正向预测的性能表现,而出现凹曲线,在不能变换正负预测关系的情况下,AUC 低于 0.5。对于AUC 低于 0.5 的模型,我们更偏向于通过调整数据和参数等其他手段,以保证 ROC 曲线呈现凸曲线。一旦 AUC 低于 0.5,以二分类模型举例,我们可以理解为当前模型一定程度上比随机猜测的结果还要差,其模型毫无性能可言。
最后,为什么我们要使用 ROC 和 AUC 评价指标?很重要的原因是 ROC 的横纵坐标分别是 FPR 和 TPR,得益于其计算方式,两者对于样本正负比例的变化是不敏感的。这种情况下,ROC 与 AUC 指标更能集中突显模型分类性能的好坏,而尽可能不受其他因素的影响。
以上内容摘自《智能搜索和推荐系统:原理、算法与应用》一书,经出版方授权发布。
福利时间
奖品:《智能搜索和推荐系统:原理、算法与应用》x 5
资深技术专家撰写,阿里、美团、Hulu多位专家推荐,零基础掌握搜索和推荐系统原理、架构、算法,以及机器学习、深度学习、NLP在其中应用。
参与方式:文末留言,赞数最多的5位为本次中奖者
开奖时间:2021年5月6号20点
备注:如有问题,请添加小助手微信:MLAPython,备注(姓名-单位-研究方向)
以上是关于干货 推荐系统评价指标,文末送书!的主要内容,如果未能解决你的问题,请参考以下文章