拜托!你真会用线程池吗?
Posted Java技术栈
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了拜托!你真会用线程池吗?相关的知识,希望对你有一定的参考价值。
来源:https://zhenbianshu.github.io
前言
由于线程的创建和销毁对操作系统来说都是比较重量级的操作,所以线程的池化在各种语言内都有实践,当然在 Java 语言中线程池是也非常重要的一部分,有 Doug Lea 大神对线程池的封装,我们使用的时候是非常方便,但也可能会因为不了解其具体实现,对线程池的配置参数存在误解。
我们经常在一些技术书籍或博客上看到,向线程池提交任务时,线程池的执行逻辑如下:
- 当一个任务被提交后,线程池首先检查正在运行的线程数是否达到核心线程数,如果未达到则创建一个线程。
- 如果线程池内正在运行的线程数已经达到了核心线程数,任务将会被放到 BlockingQueue 内。
- 如果 BlockingQueue 已满,线程池将会尝试将线程数扩充到最大线程池容量。
- 如果当前线程池内线程数量已经达到最大线程池容量,则会执行拒绝策略拒绝任务提交。
流程如图(摘自美团技术博客):
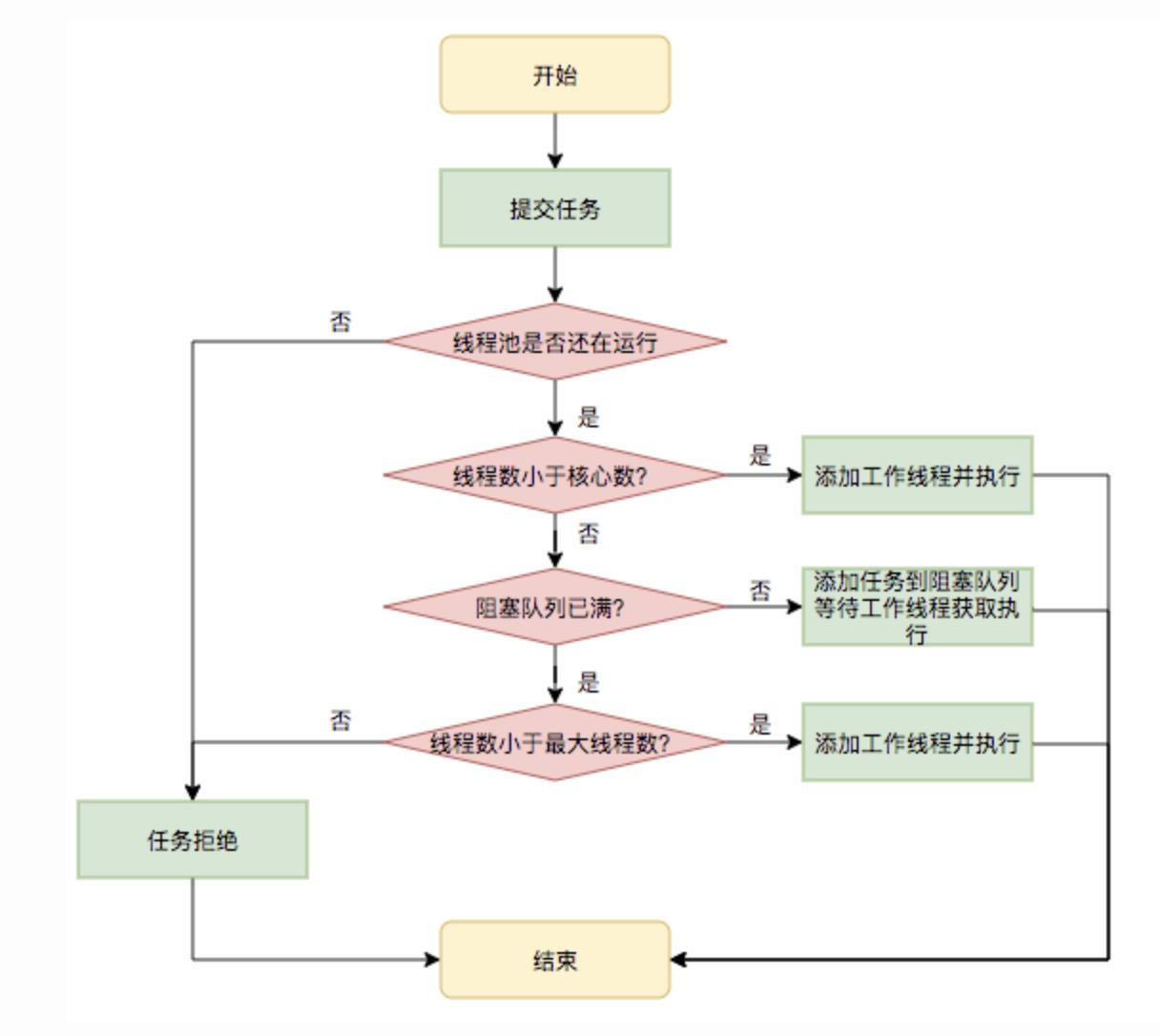
流程描述没有问题,但如果某些点未经过推敲,容易导致误解,而且描述中的情境太理想化,如果配置时不考虑运行时环境,也会出现一些非常诡异的问题。
核心池
线程池内线程数量小于等于 coreSize 的部分我称为核心池,核心池是线程池的常驻部分,内部的线程一般不会被销毁,我们提交的任务也应该绝大部分都由核心池内的线程来执行。
线程创建时机的误解
有关核心池最常见的一个误区是没搞清楚核心池内线程的创建时机,这个问题,我觉得甩 10% 的锅给 Doug Lea 大神应该不算过分,因为他在文档里写道 “If fewer than corePoolSize threads are running, try to start a new thread with the given command as its first task”,其中 "running" 这个词就比较有歧义,因为在我们理解里 running 是指当前线程已被操作系统调度,拥有操作系统时间分片,或者被理解为正在执行某个任务。
基于以上的理解,我们很容易就认为如果任务的 QPS 非常低,线程池内线程数量永远也达不到 coreSize。 即如果我们配置了 coreSize 为 1000,实际上 QPS 只有 1,单个任务耗时 1s,那么核心池大小就会一直是 1,即使有流量抖动,核心池也只会被扩容到 3。因为一个线程每秒执行执行一个任务,刚好不用创建新线程就足以应对 1QPS。
创建过程
但如果简单设计一个测试,使用 jstack 打印出线程栈并数一下线程池内线程数量,会发现线程池内的线程数会随着任务的提交而逐渐增大,直到达到 coreSize。
因为核心池的设计初衷是想它能作为常驻池,承载日常流量,所以它应该被尽快初始化,于是线程池的逻辑是在没有达到 coreSize 之前,每一个任务都会创建一个新的线程,对应的源码为:
public void execute(Runnable command) {
...
int c = ctl.get();
if (workerCountOf(c) < corePoolSize) { // workerCountOf() 方法是获取线程池内线程数量
if (addWorker(command, true))
return;
c = ctl.get();
}
...
}而文档里的 running 状态也指的是线程已经被创建,我们也知道线程被创建后,会在一个 while 循环里尝试从 BlockingQueue 里获取并执行任务,说它正在 running 也不为过。
基于此,我们对一些高并发服务进行的预热,其实并不是期望 JVM 能对热点代码做 JIT 等优化,对线程池、连接池和本地缓存的预热才是重点。
BlockingQueue
BlockingQueue 是线程池内的另一个重要组件,首先它是线程池”生产者-消费者”模型的中间媒介,另外它也可以为大量突发的流量做缓冲,但理解和配置它也经常会出错。
运行模型
最常见的错误是不理解线程池的运行模型。首先要明确的一点是线程池并没有准确的调度功能,即它无法感知有哪些线程是处于空闲状态的,并把提交的任务派发给空闲线程。
线程池采用的是”生产者-消费者”模式,除了触发线程创建的任务(线程的 firstTask)不会入 BlockingQueue 外,其他任务都要进入到 BlockingQueue,等待线程池内的线程消费,而任务会被哪个线程消费到完全取决于操作系统的调度。
对应的生产者源码如下:
public void execute(Runnable command) {
...
if (isRunning(c) && workQueue.offer(command)) { isRunning() 是判断线程池处理戚状态
int recheck = ctl.get();
if (! isRunning(recheck) && remove(command))
reject(command);
else if (workerCountOf(recheck) == 0)
addWorker(null, false);
}
...
}对应的消费者源码如下:
private Runnable getTask() {
for (;;) {
...
Runnable r = timed ?
workQueue.poll(keepAliveTime, TimeUnit.NANOSECONDS) :
workQueue.take();
if (r != null)
return r;
...
}
}BlockingQueue 的缓冲作用
基于”生产者-消费者”模型,我们可能会认为如果配置了足够的消费者,线程池就不会有任何问题。其实不然,我们还必须考虑并发量这一因素。
设想以下情况:有 1000 个任务要同时提交到线程池内并发执行,在线程池被初始化完成的情况下,它们都要被放到 BlockingQueue 内等待被消费,在极限情况下,消费线程一个任务也没有执行完成,那么这 1000 个请求需要同时存在于 BlockingQueue 内,如果配置的 BlockingQueue Size 小于 1000,多余的请求就会被拒绝。
那么这种极限情况发生的概率有多大呢?答案是非常大,因为操作系统对 I/O 线程的调度优先级是非常高的,一般我们的任务都是由 I/O 的准备或完成(如 tomcat 受理了 http 请求)开始的,所以很有可能被调度到的都是 tomcat 线程,它们在一直往线程池内提交请求,而消费者线程却调度不到,导致请求堆积。
我负责的服务就发生过这种请求被异常拒绝的情况,压测时 QPS 2000,平均响应时间为 20ms,正常情况下,40 个线程就可以平衡生产速度,不会堆积。但在 BlockingQueue Size 为 50 时,即使线程池 coreSize 为 1000,还会出现请求被线程池拒绝的情况。
这种情况下,BlockingQueue 的重要的意义就是它是一个能长时间存储任务的容器,能以很小的代价为线程池提供缓冲。根据上文可知,线程池能支持BlockingQueue Size个任务同时提交,我们把最大同时提交的任务个数,称为并发量,配置线程池时,了解并发量异常重要。
并发量的计算
我们常用 QPS 来衡量服务压力,所以配置线程池参数时也经常参考这个值,但有时候 QPS 和并发量有时候相关性并没有那么高,QPS 还要搭配任务执行时间来推算峰值并发量。
比如请求间隔严格相同的接口,平均 QPS 为 1000,它的并发量峰值是多少呢?我们并没有办法估算,因为如果任务执行时间为 1ms,那么它的并发量只有 1;而如果任务执行时间为 1s,那么并发量峰值为 1000。
可是知道了任务执行时间,就能算出并发量了吗?也不能,因为如果请求的间隔不同,可能 1min 内的请求都在一秒内发过来,那这个并发量还要乘以 60,所以上面才说知道了 QPS 和任务执行时间,并发量也只能靠推算。
计算并发量,我一般的经验值是 QPS*平均响应时间,再留上一倍的冗余,但如果业务重要的话,BlockingQueue Size 设置大一些也无妨(1000 或以上),毕竟每个任务占用的内存量很有限。
考虑运行时
GC
除了上面提到的各种情况下,GC 也是一个很重要的影响因素。
我们都知道 GC 是 Stop the World 的,但这里的 World 指的是 JVM,而一个请求 I/O 的准备和完成是操作系统在进行的,JVM 停止了,但操作系统还是会正常受理请求,在 JVM 恢复后执行,所以 GC 是会堆积请求的。
上文中提到的并发量计算一定要考虑到 GC 时间内堆积的请求同时被受理的情况,堆积的请求数可以通过 QPS*GC时间 来简单得出,还有一定要记得留出冗余。
业务峰值
除此之外,配置线程池参数时,一定要考虑业务场景。
假如接口的流量大部分来自于一个定时程序,那么平均 QPS 就没有了任何意义,线程池设计时就要考虑给 BlockingQueue 的 Size 设置一个大一些的值;而如果流量非常不平均,一天内只有某一小段时间才有高流量的话,而且线程资源紧张的情况下,就要考虑给线程池的 maxSize 留下较大的冗余;在流量尖刺明显而响应时间不那么敏感时,也可以设置较大的 BlockingQueue,允许任务进行一定程度的堆积。
当然除了经验和计算外,对服务做定时的压测无疑更能帮助掌握服务真实的情况。
小结
总结线程池的配置时,我最大的感受是一定要读源码!读源码!读源码!
只看一些书和文章的总结是无法吃透一些重要概念的,即使搞懂了大部分也很容易会在一些角落踩坑。
深入理解原理后,面对复杂情况,才有灵活配置的能力。
参考文献:
https://tech.meituan.com/2020/04/02/java-pooling-pratice-in-meituan.html 近期热文推荐:
1.600+ 道 Java面试题及答案整理(2021最新版)
2.终于靠开源项目弄到 IntelliJ IDEA 激活码了,真香!
3.阿里 Mock 工具正式开源,干掉市面上所有 Mock 工具!
4.Spring Cloud 2020.0.0 正式发布,全新颠覆性版本!
觉得不错,别忘了随手点赞+转发哦!
以上是关于拜托!你真会用线程池吗?的主要内容,如果未能解决你的问题,请参考以下文章