聊聊人像抠图背后的算法技术
Posted 华为云
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了聊聊人像抠图背后的算法技术相关的知识,希望对你有一定的参考价值。
本文分享自华为云社区《 人像抠图:算法概述及工程实现(一)》,原文作者:杜甫盖房子 。
本文将从算法概述、工程实现、优化改进三个方面阐述如何实现一个实时、优雅、精确的视频人像抠图项目。
什么是抠图
对于一张图I, 我们感兴趣的人像部分称为前景F,其余部分为背景B,则图像I可以视为F与B的加权融合:I = alpha * F + (1 - alpha) * BI=alpha∗F+(1−alpha)∗B,而抠图任务就是找到合适的权重alpha。值得一提的是,如图,查看抠图ground truth可以看到,alpha是[0, 1]之间的连续值,可以理解为像素属于前景的概率,这与人像分割是不同的。如图,在人像分割任务中,alpha只能取0或1,本质上是分类任务,而抠图是回归任务。
抠图ground truth:

分割ground truth:

相关工作
我们主要关注比较有代表性的基于深度学习的抠图算法。目前流行的抠图算法大致可以分为两类,一种是需要先验信息的Trimap-based的方法,宽泛的先验信息包括Trimap、粗糙mask、无人的背景图像、Pose信息等,网络使用先验信息与图片信息共同预测alpha;另一种则是Trimap-free的方法,仅根据图片信息预测alpha,对实际应用更友好,但效果普遍不如Trimap-based的方法。
Trimap-based
Trimap是最常用的先验知识,顾名思义Trimap是一个三元图,每个像素取值为{0,128,255}其中之一,分别代表前景、未知与背景,如图。

Deep Image Matting
多数抠图算法采用了Trimap作为先验知识。Adobe在17年提出了Deep Image Matting[^1],这是首个端到端预测alpha的算法,整个模型分Matting encoder-decoder stage与Matting refinement stage两个部分,Matting encoder-decoder stage是第一部分,根据输入图像与对应的Trimap,得到较为粗略的alpha matte。Matting refinement stage是一个小的卷积网络,用来提升alpha matte的精度与边缘表现。
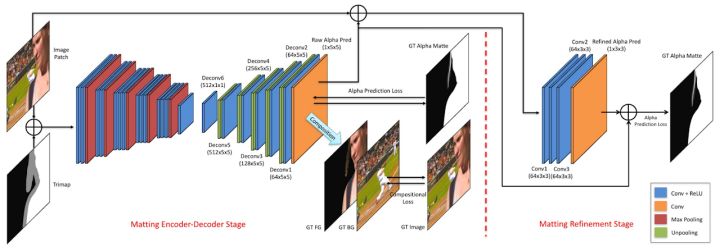

本文在当时达到了state-of-the-art,后续很多文章都沿用了这种“粗略-精细”的抠图思路,此外,由于标注成本高,过去抠图任务的数据是非常有限的。本文还通过合成提出了一个大数据集Composition-1K,将精细标注的前景与不同背景融合,得到了45500训练图像和1000测试图像,大大丰富了抠图任务的数据。
Background Matting
Background Matting[^2]是华盛顿大学提出的抠图算法,后续发布了Backgroun MattingV2,方法比较有创新点,并且在实际工程应用中取得了不错的效果。

同时,由于Adobe的数据都是基于合成的,为了更好的适应真实输入,文中提出一个自监督网络训练G_{Real}GReal来对未标注的真实输入进行学习。G_{Real}GReal输入与G_{Adobe}GAdobe相同,用G_{Adobe}GAdobe输出的alpha matte与F来监督G_{Real}GReal的输出得到loss,此外,G_{Real}GReal的输出合成得到的RGB还将通过一个鉴别器来判断真伪得到第二个loss,共同训练G_{Real}GReal。
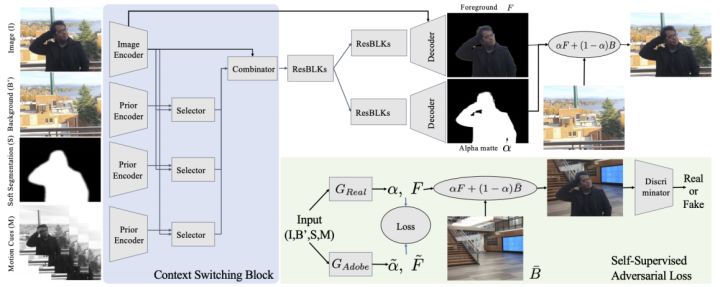
文中列举了一些使用手机拍摄得到的测试结果,可以看到大部分情况结果还是很不错的。

Background Matting V2
Background Matting得到了不错的效果,但该项目无法实时运行,也无法很好的处理高分辨率输入。所以项目团队又推出了Background Matting V2[^3],该项目可以以30fps的速度在4k输入上得到不错的结果。

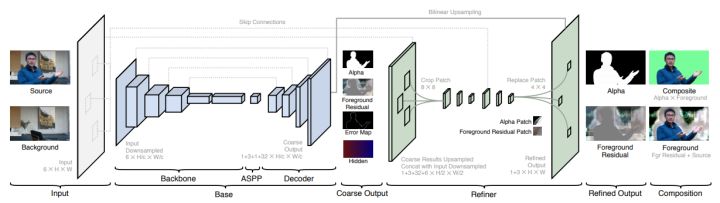
文章实现高效高分辨率抠图的一个重要想法是,alpha matte中大部分像素是0或1,只有少量的区域包含过渡像素。因此文章将网络分为base网络和refine网络,base网络对低分辨率图像进行处理,refine网络根据base网络的处理结果选择原始高分辨率图像上特定图像块进行处理。
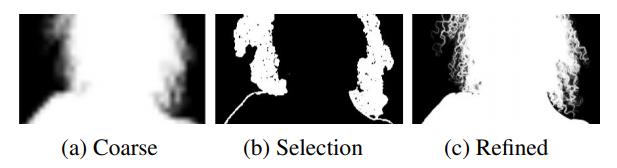
base网络输入为c倍下采样的图像与背景,通过encoder-decoder输出粗略的alpha matte、F、error map与hidden features。将采样c倍得到的error map E_cEc上采样到原始分辨率的\\frac{1}{4}41为E_4E4,则E_4E4每个像素对应原图4x4图像块,从E_4E4选择topk error像素,即为原始topk error 4x4图像块。在选择出的像素周围裁剪出多个8x8图像块送入refine网络。refine网络是一个two-stage网络,首先将输入通过部分CBR操作得到第一阶段输出,与原始输入中提取的8x8图像块cat后输入第二阶段,最后将refine后的图像块与base得到的结果交换得到最终的alpha matte和F。
此外文章还发布了两个数据集:视频抠图数据集VideoMatte240K与图像抠图数据集PhotoMatte13K/85。VideoMatte240K收集了484个高分辨率视频,使用Chroma-key软件生成了240000+前景和alpha matte对。PhotoMatte13K/85则是在良好光照下拍摄照片使用软件和手工调整的方法得到13000+前景与alpha matte数据对。大型数据集同样是本文的重要贡献之一。


此外还有一些文章如Inductive Guided Filter[^4]、MGMatting[^5]等,使用粗略的mask作为先验信息预测alpha matte,在应用时也比trimap友好很多。MGMatting同时也提出了一个有636张精确标注人像的抠图数据集RealWorldPortrait-636,可以通过合成等数据增广方法扩展使用。
Trimap-free
实际应用中先验信息获取起来是很不方便的,一些文章将先验信息获取的部分也放在网络中进行。
Semantic Human Matting
阿里巴巴提出的Semantic Human Matting[^6]同样分解了抠图任务,网络分为三个部分,T-Net对像素三分类得到Trimap,与图像concat得到六通道输入送入M-Net,M-Net通过encoder-decoder得到较为粗糙的alpha matte,最后将T-Net与M-Net的输出送入融合模块Fusion Module,最终得到更精确的alpha matte。
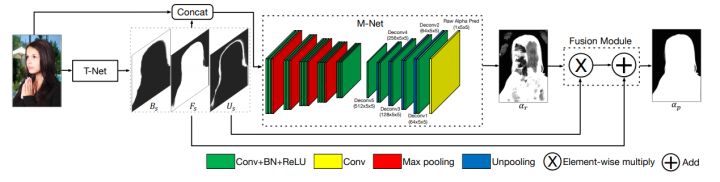
网络训练时的alpha loss分为alpha loss与compositional loss,与DIM类似,此外还加入了像素分类lossL_tLt,最终loss为:L = L_p + L_t=L_\\alpha + L_c + L_tL=Lp+Lt=Lα+Lc+Lt。文章实现了端到端Trimap-free的抠图算法,但较为臃肿。此外文章提出Fashion Model数据集,从电商网站收集整理了35000+标注的图片,但并没有开放。
Modnet
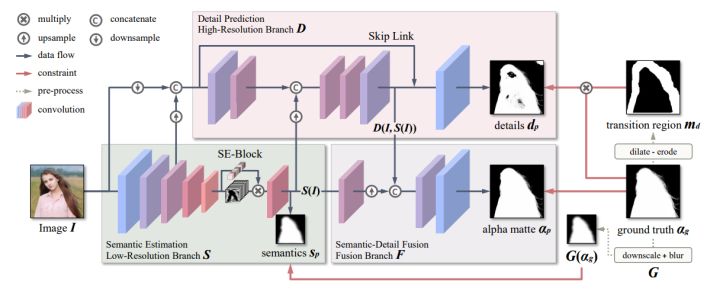
modnet[^7]认为神经网络更擅长学习单一任务,所以将抠图任务分为三个子任务,分别进行显式监督训练和同步优化,最终可以以63fps在512x512输入下达到soft结果,因此在后续的工程实现中我也选择了modnet作为Baseline。
网络的三个子任务分别是Semantic Estimation、Detail Prediction和Semantic-Detail Fusion,Semantic Estimation部分由backbone与decoder组成,输出相对于输入下采样16倍的semantics,用来提供语义信息,此任务的ground truth是标注的alpha经过下采样与高斯滤波得到的。 Detail Prediction任务输入有三个:原始图像、semantic分支的中间特征以及S分支的输出S_pSp,D分支同样是encoder-decoder结构,值得留意的该分支的loss,由于D分支只关注细节特征,所以通过ground truth alpha生成trimap,只在trimap的unknown区域计算d_pdp与\\alpha_gαg的L_1L1损失。F分支对语义信息与细节预测进行融合,得到最终的alpha matte与ground truth计算L_1L1损失,网络训练的总损失为:L=\\lambda_sL_s + \\lambda_dL_d+\\lambda_{\\alpha}L_{\\alpha}L=λsLs+λdLd+λαLα。

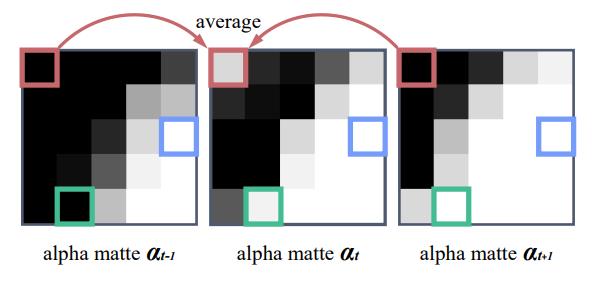
最后,文章还提出了一种使视频结果在时间上更平滑的后处理方式OFD,在前后两帧较为相似而中间帧与前后两帧距离较大时,使用前后帧的平均值平滑中间帧,但该方法会导致实际结果比输入延迟一帧。
此外,U^2U2-Net、SIM等网络可以对图像进行显著性抠图,感兴趣的话可以关注一下。
数据集
-
Adobe Composition-1K
-
VideoMatte240K
-
PhotoMatte85
评价指标
常用的客观评价指标来自于2009年CVPR一篇论文[^8],主要有:

此外,可以在paperwithcode上查看Image Matting任务的相关文章,在Alpha Matting网站上查看一些算法的evaluation指标。
本项目的最终目的是在HiLens Kit硬件上落地实现实时视频读入与背景替换,开发环境为HiLens配套在线开发环境HiLens Studio,先上一下对比baseline的改进效果:
使用modnet预训练模型modnet_photographic_portrait_matting.ckpt进行测试结果如下:
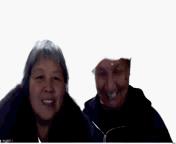
可以看到由于场景较为陌生、逆光等原因会导致抠图结果有些闪烁,虽然modnet可以针对特定视频进行自监督finetune,但我们的目的是在普遍意义上效果更好,因此没有对本视频进行自监督学习。
优化后的模型效果如下:

本视频并没有作为训练数据。可以看到,抠图的闪烁情况减少了很多,毛发等细节也基本没有损失。
工程落地
为了测试baseline效果,首先我们要在使用场景下对baseline进行工程落地。根据文档导入/转换本地开发模型可知
昇腾310 AI处理器支持模型格式为".om",对于Pytorch模型来说可以通过"Pytorch->Caffe->om"或"Pytorch->onnx->om"(新版本)的转换方式得到,这里我选择的是第一种。Pytorch->Caffe模型转换方法与注意事项在之前的博客中有具体阐述过,这里不赘述。转换得到Caffe模型后,可以在HiLens Studio中直接转为om模型,非常方便。
首先在HiLens Studio中新建一个技能,此处选择了空模板,只需要修改一下技能名称就可以。
将Caffe模型上传到model文件夹下:
在控制台中运行模型转换命令即可得到可以运行的om模型:
/opt/ddk/bin/aarch64-linux-gcc7.3.0/omg --model=./modnet_portrait_320.prototxt --weight=./modnet_portrait_320.caffemodel --framework=0 --output=./modnet_portrait_320 --insert_op_conf=./aipp.cfg
接下来完善demo代码。在测试时HiLens Studio可以在工具栏选择使用视频模拟摄像头输入,或连接手机使用手机进行测试:
具体的demo代码如下:
# -*- coding: utf-8 -*-
# !/usr/bin/python3
# HiLens Framework 0.2.2 python demo
import cv2
import os
import hilens
import numpy as np
from utils import preprocess
import time
def run(work_path):
hilens.init("hello") # 与创建技能时的校验值一致
camera = hilens.VideoCapture('test/camera0_2.mp4') # 模拟输入的视频路径
display = hilens.Display(hilens.HDMI)
# 初始化模型
model_path = os.path.join(work_path, 'model/modnet_portrait_320.om') # 模型路径
model = hilens.Model(model_path)
while True:
try:
input_yuv = camera.read()
input_rgb = cv2.cvtColor(input_yuv, cv2.COLOR_YUV2RGB_NV21)
# 抠图后替换的背景
bg_img = cv2.cvtColor(cv2.imread('data/tiantan.jpg'), cv2.COLOR_BGR2RGB)
crop_img, input_img = preprocess(input_rgb) # 预处理
s = time.time()
matte_tensor = model.infer([input_img.flatten()])[0]
print('infer time:', time.time() - s)
matte_tensor = matte_tensor.reshape(1, 1, 384, 384)
alpha_t = matte_tensor[0].transpose(1, 2, 0)
matte_np = cv2.resize(np.tile(alpha_t, (1, 1, 3)), (640, 640))
fg_np = matte_np * crop_img + (1 - matte_np) * bg_img # 替换背景
view_np = np.uint8(np.concatenate((crop_img, fg_np), axis=1))
print('all time:', time.time() - s)
output_nv21 = hilens.cvt_color(view_np, hilens.RGB2YUV_NV21)
display.show(output_nv21)
except Exception as e:
print(e)
break
hilens.terminate()其中预处理部分的代码为:
import cv2
import numpy as np
TARGET_SIZE = 640
MODEL_SIZE = 384
def preprocess(ori_img):
ori_img = cv2.flip(ori_img, 1)
H, W, C = ori_img.shape
x_start = max((W - min(H, W)) // 2, 0)
y_start = max((H - min(H, W)) // 2, 0)
crop_img = ori_img[y_start: y_start + min(H, W), x_start: x_start + min(H, W)]
crop_img = cv2.resize(crop_img, (TARGET_SIZE, TARGET_SIZE))
input_img = cv2.resize(crop_img, (MODEL_SIZE, MODEL_SIZE))
return crop_img, input_imgdemo部分的代码非常简单,点击运行即可在模拟器中看到效果:
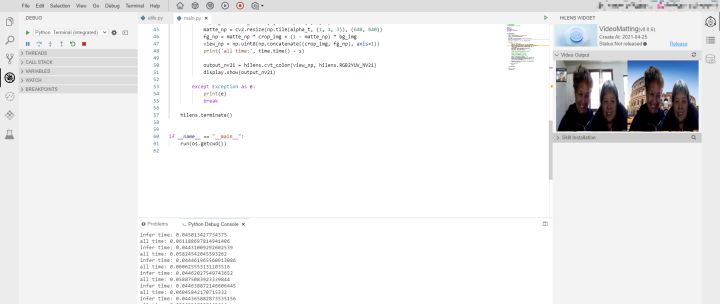
模型推理耗时44ms左右,端到端运行耗时60ms左右,达到了我们想要的实时的效果。
效果改进
预训练模型在工程上存在着时序闪烁的问题,原论文中提出了一种使视频结果在时间上更平滑的后处理方式OFD,即用前后两帧平均误差大的中间帧。但这种办法只适合慢速运动,同时会导致一帧延迟,而我们希望可以对摄像头输入进行实时、普适的时序处理,因此OFD不适合我们的应用场景。
在Video Object Segmentation任务中有一些基于Memory Network的方法(如STM),抠图领域也有新论文如DVM考虑引入时序记忆单元使抠图结果在时序上更稳定,但这些方法普遍需要前后n帧信息,在资源占用、推理实时性、适用场景上都与我们希望的场景不符合。
考虑到资源消耗与效果的平衡,我们采用将前一帧的alpha结果cat到当前帧RGB图像后共同作为输入的方法来使网络在时序上更稳定。
网络上的修改非常简单,只需在模型初始化时指定in_channels = 4:
modnet = MODNet(in_channels=4, backbone_pretrained=False)训练数据方面,我们选择一些VideoMatting的数据集:VideoMatte240K、ConferenceVideoSegmentationDataset。
最初,我们尝试将前一帧alpha作为输入、缺失前帧时补零这种简单的策略对模型进行训练:
if os.path.exists(os.path.join(self.alpha_path, alpha_pre_path)):
alpha_pre = cv2.imread(os.path.join(self.alpha_path, alpha_pre_path))
else:
alpha_pre = np.zeros_like(alpha)
net_input = torch.cat([image, alpha_pre], dim=0)收敛部署后发现,在场景比较稳定时模型效果提升较大,而在人进、出画面时模型适应较差,同时如果某一帧结果较差,将对后续帧产生很大影响。针对这些问题,考虑制定相应的数据增强的策略来解决问题。
- 人进、出画面时模型适应较差:数据集中空白帧较少,对人物入画出画学习不够,因此在数据处理时增加空白帧概率:
if os.path.exists(os.path.join(self.alpha_path, alpha_pre_path)) and random.random() < 0.7:
alpha_pre = cv2.imread(os.path.join(self.alpha_path, alpha_pre_path))
else:
alpha_pre = np.zeros_like(alpha)- 某一帧结果较差,将对后续帧产生很大影响:目前的结果较为依赖前一帧alpha,没有学会抛弃错误结果,因此在数据处理时对alpha_pre进行一定概率的仿射变换,使网络学会忽略偏差较大的结果;
- 此外,光照问题仍然存在,在背光或光线较强处抠图效果较差:对图像进行光照增强,具体的,一定概率情况下模拟点光源或线光源叠加到原图中,使网络对光照更鲁棒。光照数据增强有两种比较常用的方式,一种是通过opencv进行简单的模拟,具体可以参考augmentation.py,另外还有通过GAN生成数据,我们使用opencv进行模拟。
重新训练后,我们的模型效果已经可以达到前文展示的效果,在16T算力的HiLens Kit上完全达到了实时、优雅的效果。进一步的,我还想要模型成为耗时更少、效果更好的优秀模型~目前在做的提升方向是:
- 更换backbone:针对应用硬件选择合适的backbone一向是提升模型性价比最高的方法,直接根据耗时与资源消耗针对硬件搜一个模型出来最不错,目前搜出来的模型转为onnx测试结果(输入192x192):
GPU:
Average Performance excluding first iteration. Iterations 2 to 300. (Iterations greater than 1 only bind and evaluate)
Average Bind: 0.124713 ms
Average Evaluate: 16.0683 ms
Average Working Set Memory usage (bind): 6.53219e-05 MB
Average Working Set Memory usage (evaluate): 0.546117 MB
Average Dedicated Memory usage (bind): 0 MB
Average Dedicated Memory usage (evaluate): 0 MB
Average Shared Memory usage (bind): 0 MB
Average Shared Memory usage (evaluate): 0.000483382 MB
CPU:
Average Performance excluding first iteration. Iterations 2 to 300. (Iterations greater than 1 only bind and evaluate)
Average Bind: 0.150212 ms
Average Evaluate: 13.7656 ms
Average Working Set Memory usage (bind): 9.14507e-05 MB
Average Working Set Memory usage (evaluate): 0.566746 MB
Average Dedicated Memory usage (bind): 0 MB
Average Dedicated Memory usage (evaluate): 0 MB
Average Shared Memory usage (bind): 0 MB
Average Shared Memory usage (evaluate): 0 MB- 模型分支:在使用的观察中发现,大部分较为稳定的场景可以使用较小的模型得到不错的结果,所有考虑finetune LRBranch处理简单场景,HRBranch与FusionBranch依旧用来处理复杂场景,这项工作还在进行中。
[^1]: Xu, Ning, et al. “Deep image matting.” Proceedings of the IEEE conference on computer vision and pattern recognition. 2017
[^2]:Sengupta, Soumyadip, et al. “Background matting: The world is your green screen.” Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2020.
[^3]:Lin, Shanchuan, et al. “Real-Time High-Resolution Background Matting.” arXiv preprint arXiv:2012.07810 (2020).
[^4]:Li, Yaoyi, et al. “Inductive Guided Filter: Real-Time Deep Matting with Weakly Annotated Masks on Mobile Devices.” 2020 IEEE International Conference on Multimedia and Expo (ICME). IEEE, 2020.
[^5]: Yu, Qihang, et al. “Mask Guided Matting via Progressive Refinement Network.” arXiv e-prints (2020): arXiv-2012.
[^6]: Chen, Quan, et al. “Semantic human matting.” Proceedings of the 26th ACM international conference on Multimedia. 2018.
[^7]: Ke, Zhanghan, et al. “Is a Green Screen Really Necessary for Real-Time Human Matting?.” arXiv preprint arXiv:2011.11961 (2020).
[^8]:Rhemann, Christoph, et al. “A perceptually motivated online benchmark for image matting.” 2009 IEEE Conference on Computer Vision and Pattern Recognition. IEEE, 2009.
以上是关于聊聊人像抠图背后的算法技术的主要内容,如果未能解决你的问题,请参考以下文章
识别速度3.6ms/帧!人像抠图工业质检遥感识别,用这一个分割模型就够了...
基于阿里Semantatic Human Matting算法,实现精细化人物抠图
一键抠图Portrait Matting人像抠图 (C++和Android源码)