人像抠图——基于深度学习一键去除视频背景
Posted 知来者逆
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了人像抠图——基于深度学习一键去除视频背景相关的知识,希望对你有一定的参考价值。
前言
1.抠图技术应用很广泛,比如证件照,美体,人体区域特殊处理,还有B站的字幕穿人效果等等。这些的关键技术都在于高精度高性能的分割算法。RobustVideoMatting是来自字节跳动视频人像抠图算法(RVM),专为稳定人物视频抠像设计。 不同于现有神经网络将每一帧作为单独图片处理,RVM 使用循环神经网络,在处理视频流时有时间记忆。RVM 可在任意视频上做实时高清人像抠图。
2.关于RobustVideoMatting算法和模型训练步骤可以直接转到官方的git:https://github.com/PeterL1n/RobustVideoMatting。这里只实现模型的C++推理与部署。
3.使用的开发环境是win10,显卡RTX3080,cuda11.2,cudnn8.1,OpenCV4.5,onnxruntime,IDE 是Vs2019。
一、模型与依赖
1.官方公布了很多种格式的模型,有mnn,ncnn,onnx等等,这里使用的是onnx这个模型,直接从这官方公布的地址(gym7)下载就可以了。
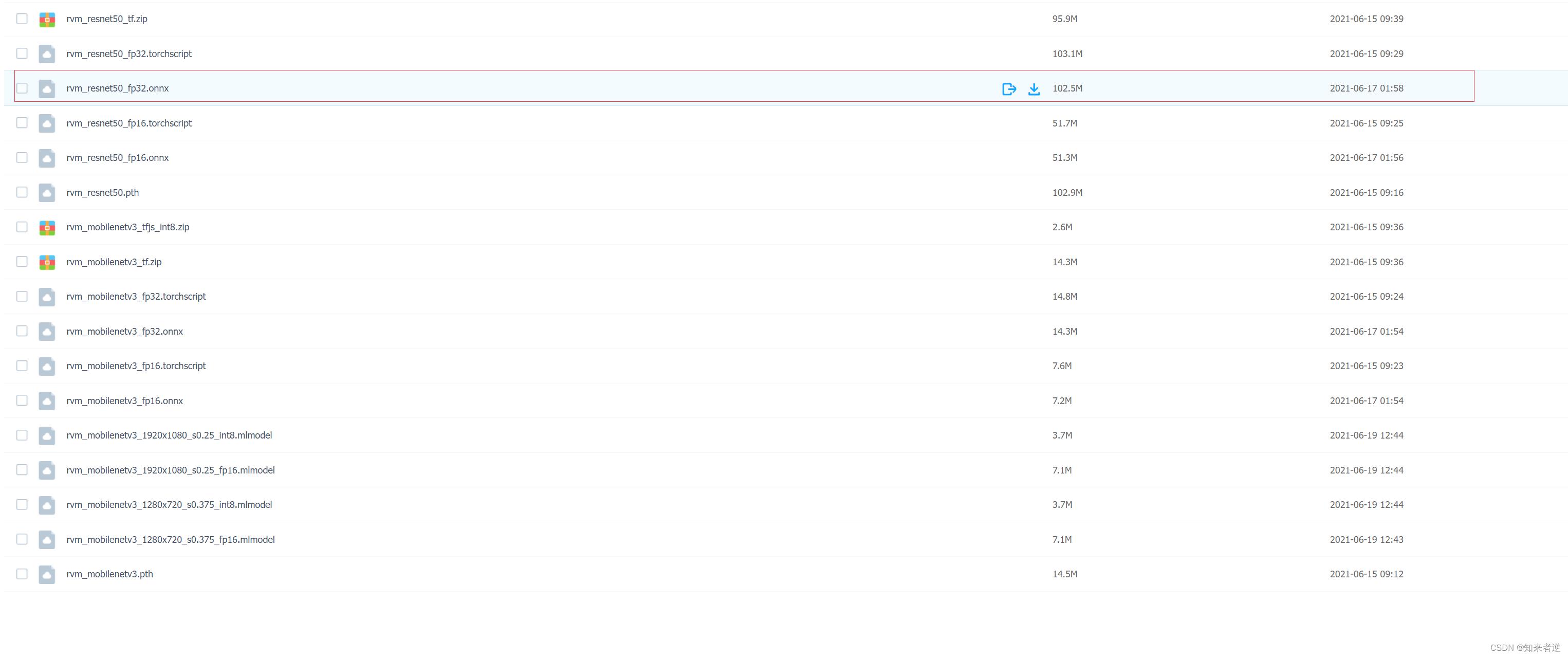
2.onnxruntime直接下载 官方编译好的release版本就可以使用了。
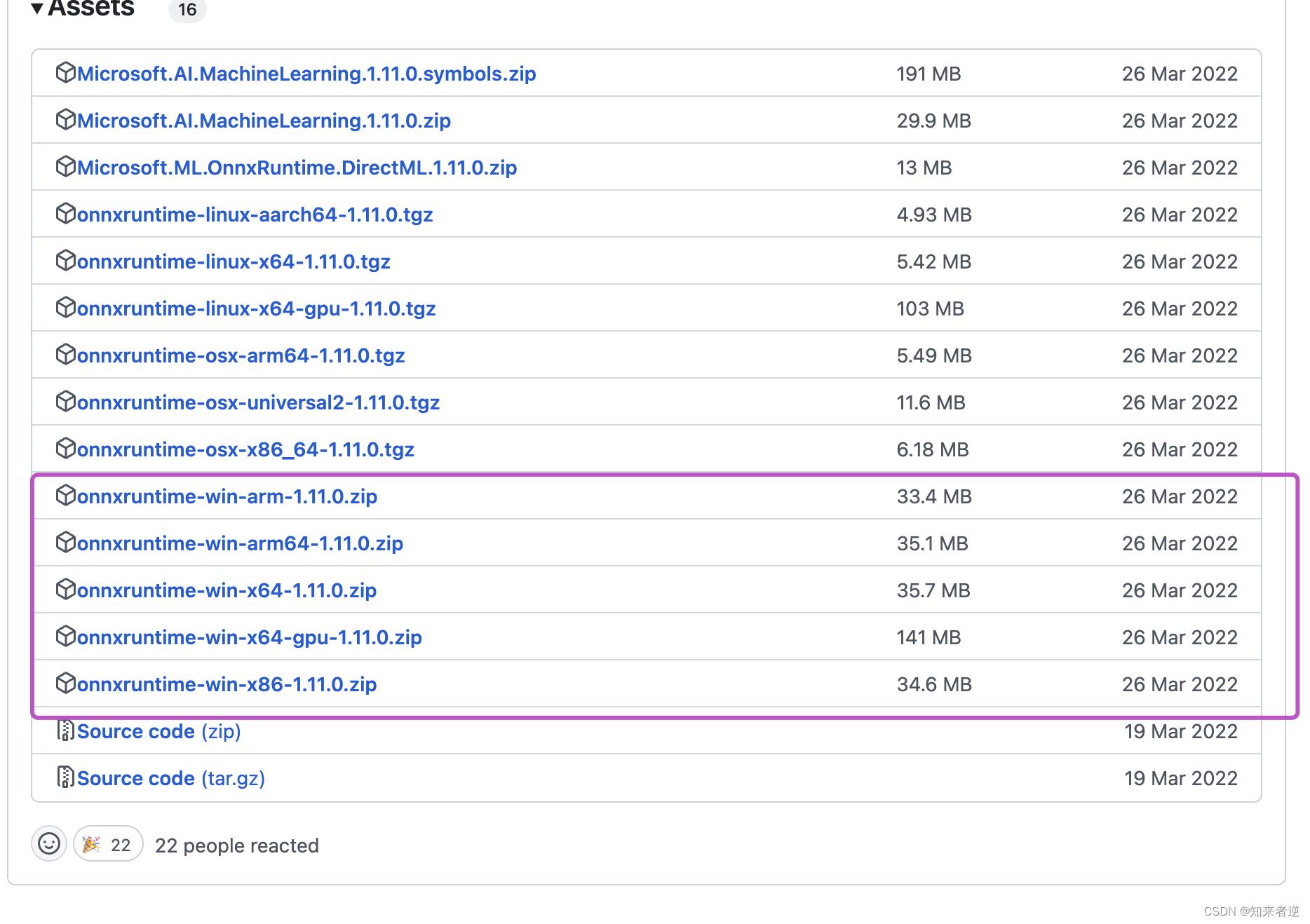
3.如果想用GPU进行推理,则要下载安装cuda,cudnn,具体安装方法网上有很多种,可以参考。
二、代码
1.推理代码
typedef struct MattingContentType
Mat fgr_mat;
Mat pha_mat;
Mat merge_mat;
bool flag;
MattingContentType() : flag(false)
;
MattingContent;
class RobustVideoMatting
public:
RobustVideoMatting(string model_path);
void detect(const Mat& mat, MattingContent& content, float downsample_ratio);
private:
Session* session_;
Env env = Env(ORT_LOGGING_LEVEL_ERROR, "robustvideomatting");
SessionOptions sessionOptions = SessionOptions();
unsigned int num_inputs = 6;
vector<const char*> input_node_names =
"src",
"r1i",
"r2i",
"r3i",
"r4i",
"downsample_ratio"
;
vector<vector<int64_t>> dynamic_input_node_dims =
1, 3, 1280, 720,
1, 1, 1, 1,
1, 1, 1, 1,
1, 1, 1, 1,
1, 1, 1, 1,
1
;
unsigned int num_outputs = 6;
vector<const char*> output_node_names =
"fgr",
"pha",
"r1o",
"r2o",
"r3o",
"r4o"
;
vector<float> dynamic_src_value_handler;
vector<float> dynamic_r1i_value_handler = 0.0f ;
vector<float> dynamic_r2i_value_handler = 0.0f ;
vector<float> dynamic_r3i_value_handler = 0.0f ;
vector<float> dynamic_r4i_value_handler = 0.0f ;
vector<float> dynamic_dsr_value_handler = 0.25f ;
int64_t value_size_of(const std::vector<int64_t>& dims);
bool context_is_update = false;
void normalize_(Mat img, vector<float>& output);
vector<Ort::Value> transform(const Mat& mat);
void generate_matting(vector<Ort::Value>& output_tensors, MattingContent& content);
void update_context(vector<Ort::Value>& output_tensors);
;
RobustVideoMatting::RobustVideoMatting(string model_path)
wstring widestr = wstring(model_path.begin(), model_path.end());
sessionOptions.SetGraphOptimizationLevel(ORT_ENABLE_EXTENDED);
session_ = new Session(env, widestr.c_str(), sessionOptions);
void RobustVideoMatting::normalize_(Mat img, vector<float>& output)
int row = img.rows;
int col = img.cols;
for (int c = 0; c < 3; c++)
for (int i = 0; i < row; i++)
for (int j = 0; j < col; j++)
float pix = img.ptr<uchar>(i)[j * 3 + 2 - c];
output[c * row * col + i * col + j] = pix / 255.0;
int64_t RobustVideoMatting::value_size_of(const std::vector<int64_t>& dims)
if (dims.empty()) return 0;
int64_t value_size = 1;
for (const auto& size : dims) value_size *= size;
return value_size;
vector<Ort::Value> RobustVideoMatting::transform(const Mat& mat)
Mat src = mat.clone();
const unsigned int img_height = mat.rows;
const unsigned int img_width = mat.cols;
vector<int64_t>& src_dims = dynamic_input_node_dims.at(0);
src_dims.at(2) = img_height;
src_dims.at(3) = img_width;
std::vector<int64_t>& r1i_dims = dynamic_input_node_dims.at(1);
std::vector<int64_t>& r2i_dims = dynamic_input_node_dims.at(2);
std::vector<int64_t>& r3i_dims = dynamic_input_node_dims.at(3);
std::vector<int64_t>& r4i_dims = dynamic_input_node_dims.at(4);
std::vector<int64_t>& dsr_dims = dynamic_input_node_dims.at(5);
int64_t src_value_size = this->value_size_of(src_dims);
int64_t r1i_value_size = this->value_size_of(r1i_dims);
int64_t r2i_value_size = this->value_size_of(r2i_dims);
int64_t r3i_value_size = this->value_size_of(r3i_dims);
int64_t r4i_value_size = this->value_size_of(r4i_dims);
int64_t dsr_value_size = this->value_size_of(dsr_dims);
dynamic_src_value_handler.resize(src_value_size);
this->normalize_(src, dynamic_src_value_handler);
std::vector<Ort::Value> input_tensors;
auto allocator_info = MemoryInfo::CreateCpu(OrtDeviceAllocator, OrtMemTypeCPU);
input_tensors.push_back(Value::CreateTensor<float>(allocator_info,
dynamic_src_value_handler.data(), dynamic_src_value_handler.size(), src_dims.data(), src_dims.size()));
input_tensors.push_back(Value::CreateTensor<float>(allocator_info,
dynamic_r1i_value_handler.data(), r1i_value_size, r1i_dims.data(), r1i_dims.size()));
input_tensors.push_back(Value::CreateTensor<float>(allocator_info,
dynamic_r2i_value_handler.data(), r2i_value_size, r2i_dims.data(), r2i_dims.size()));
input_tensors.push_back(Value::CreateTensor<float>(allocator_info,
dynamic_r3i_value_handler.data(), r3i_value_size, r3i_dims.data(), r3i_dims.size()));
input_tensors.push_back(Value::CreateTensor<float>(allocator_info,
dynamic_r4i_value_handler.data(), r4i_value_size, r4i_dims.data(), r4i_dims.size()));
input_tensors.push_back(Value::CreateTensor<float>(allocator_info,
dynamic_dsr_value_handler.data(), dsr_value_size, dsr_dims.data(), dsr_dims.size()));
return input_tensors;
void RobustVideoMatting::generate_matting(std::vector<Ort::Value>& output_tensors, MattingContent& content)
Ort::Value& fgr = output_tensors.at(0);
Ort::Value& pha = output_tensors.at(1);
auto fgr_dims = fgr.GetTypeInfo().GetTensorTypeAndShapeInfo().GetShape();
auto pha_dims = pha.GetTypeInfo().GetTensorTypeAndShapeInfo().GetShape();
const unsigned int height = fgr_dims.at(2);
const unsigned int width = fgr_dims.at(3);
const unsigned int channel_step = height * width;
float* fgr_ptr = fgr.GetTensorMutableData<float>();
float* pha_ptr = pha.GetTensorMutableData<float>();
Mat rmat(height, width, CV_32FC1, fgr_ptr);
Mat gmat(height, width, CV_32FC1, fgr_ptr + channel_step);
Mat bmat(height, width, CV_32FC1, fgr_ptr + 2 * channel_step);
Mat pmat(height, width, CV_32FC1, pha_ptr);
rmat *= 255.;
bmat *= 255.;
gmat *= 255.;
Mat rest = 1. - pmat;
Mat mbmat = bmat.mul(pmat) + rest * 153.;
Mat mgmat = gmat.mul(pmat) + rest * 255.;
Mat mrmat = rmat.mul(pmat) + rest * 120.;
std::vector<Mat> fgr_channel_mats, merge_channel_mats;
fgr_channel_mats.push_back(bmat);
fgr_channel_mats.push_back(gmat);
fgr_channel_mats.push_back(rmat);
merge_channel_mats.push_back(mbmat);
merge_channel_mats.push_back(mgmat);
merge_channel_mats.push_back(mrmat);
content.pha_mat = pmat;
merge(fgr_channel_mats, content.fgr_mat);
merge(merge_channel_mats, content.merge_mat);
content.fgr_mat.convertTo(content.fgr_mat, CV_8UC3);
content.merge_mat.convertTo(content.merge_mat, CV_8UC3);
content.flag = true;
void RobustVideoMatting::update_context(std::vector<Ort::Value>& output_tensors)
Ort::Value& r1o = output_tensors.at(2);
Ort::Value& r2o = output_tensors.at(3);
Ort::Value& r3o = output_tensors.at(4);
Ort::Value& r4o = output_tensors.at(5);
auto r1o_dims = r1o.GetTypeInfo().GetTensorTypeAndShapeInfo().GetShape();
auto r2o_dims = r2o.GetTypeInfo().GetTensorTypeAndShapeInfo().GetShape();
auto r3o_dims = r3o.GetTypeInfo().GetTensorTypeAndShapeInfo().GetShape();
auto r4o_dims = r4o.GetTypeInfo().GetTensorTypeAndShapeInfo().GetShape();
dynamic_input_node_dims.at(1) = r1o_dims;
dynamic_input_node_dims.at(2) = r2o_dims;
dynamic_input_node_dims.at(3) = r3o_dims;
dynamic_input_node_dims.at(4) = r4o_dims;
int64_t new_r1i_value_size = this->value_size_of(r1o_dims);
int64_t new_r2i_value_size = this->value_size_of(r2o_dims);
int64_t new_r3i_value_size = this->value_size_of(r3o_dims);
int64_t new_r4i_value_size = this->value_size_of(r4o_dims);
dynamic_r1i_value_handler.resize(new_r1i_value_size);
dynamic_r2i_value_handler.resize(new_r2i_value_size);
dynamic_r3i_value_handler.resize(new_r3i_value_size);
dynamic_r4i_value_handler.resize(new_r4i_value_size);
float* new_r1i_value_ptr = r1o.GetTensorMutableData<float>();
float* new_r2i_value_ptr = r2o.GetTensorMutableData<float>();
float* new_r3i_value_ptr = r3o.GetTensorMutableData<float>();
float* new_r4i_value_ptr = r4o.GetTensorMutableData<float>();
std::memcpy(dynamic_r1i_value_handler.data(),
new_r1i_value_ptr, new_r1i_value_size * sizeof(float));
std::memcpy(dynamic_r2i_value_handler.data(),
new_r2i_value_ptr, new_r2i_value_size * sizeof(float));
std::memcpy(dynamic_r3i_value_handler.data(),
new_r3i_value_ptr, new_r3i_value_size * sizeof(float));
std::memcpy(dynamic_r4i_value_handler.data(),
new_r4i_value_ptr, new_r4i_value_size * sizeof(float));
context_is_update = true;
void RobustVideoMatting::detect(const Mat& mat, MattingContent& content, float downsample_ratio)
if (mat.empty()) return;
dynamic_dsr_value_handler.at(0) = downsample_ratio;
std::vector<Ort::Value> input_tensors = this->transform(mat);
auto output_tensors = session_->Run(
Ort::RunOptions nullptr , input_node_names.data()