R机器学习:朴素贝叶斯与支持向量机的原理与实现
Posted Codewar
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了R机器学习:朴素贝叶斯与支持向量机的原理与实现相关的知识,希望对你有一定的参考价值。
今天要给大家介绍的依然是两个分类算法,The naive Bayes and support vector machine (SVM),两个算法的原理有些许不同,不过还是放一篇文章中吧,毕竟我的文章都是干货满满。
什么是朴素贝叶斯算法

上一篇文章其实有给大家写贝叶斯R机器学习:分类算法之判别分析LDA,QDA的原理与实现 ,这儿再让大家加深下印象。
现在问大家一个问题:一个罕见病的发病率为0.2%,这个病的检测的正确率为0.9(如果你真有病,0.9可能性可以被检测出来),人群中这个病的检测的阳性率为0.05,那么我问,如果你在一次检测中得到了阳性的结果,你得此病的概率为多少?
有些同学张口就来,0.9!
错,因为0.9并没有考虑这个病的发病率啊,也没考虑假阳性率啊。
所以这个问题正确的算法应该是使用贝叶斯公式:
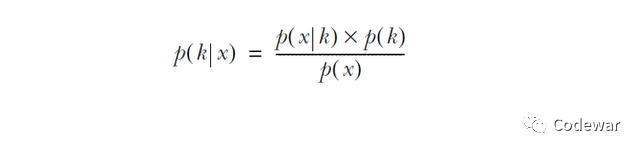
其中:
p(k|x)叫做后验,此例中为检测阳性的情况下得病的概率
p(x|k)叫做似然,此例中为得病的情况下检测阳性的概率
p(k)叫做先验,此例中为人群中真实的患病率
p(x)叫做证据,此例中为检验的阳性率,包括假阳性
知道了上面这些知识,现在我再问你如果你某一次检验测得阳性,那么你真的患此罕见病的概率为,是不是为0.9*0.002/0.05=3.2%,看到没就算你检验阳性,但是考虑到这个病的罕见性和检验的假阳性,其实你真实患此病的概率并不高。
以上例子就体现了贝叶斯的魔力。

机器学习中的贝叶斯
在机器学习中我们也可以利用贝叶斯定理来进行分类,看一个实际例子,我们想预测微博的主题,主题有4类,分别是时政,运动,电影,其他,我们的预测变量就是看微博中是否出现opinion,score,game和cinema这些词。
这是一个简化后的学习问题,实际情况下我们要使用的预测变量肯定不止这些,但原理都是一样的。
然后,每次遇到一条微博,这条微博属于特定主题的概率就可以使用贝叶斯法则预测出来:
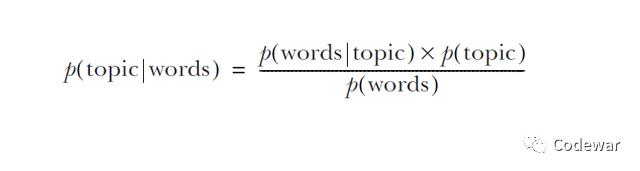
那么在真实的情况下我们会用很多词(本例中只有4个)来预测主题,此时我们的式子会进行拓展,我们的贝叶斯的等号右边部分就成了很多个似然先验的积除以很多个证据,如下所示:
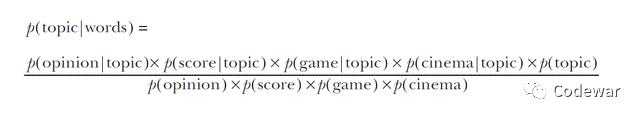
举个例子,比如现在手上一条微博有opinion, score, and game这3个词,那么此时我们的整个的似然就是:
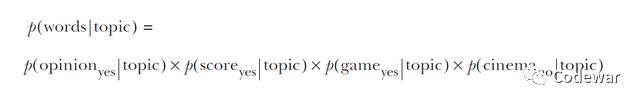
上面这个似然的式子就告诉我们:在某个主题下含有某个特定词的的微博的似然就和这个主题下含有该词的微博的数量成正比。我们把所有单个词的似然相乘就得到了多个词组合的似然,这么一种朴素而简单的乘法,就是朴素贝叶斯的名字的由来。
既然可以简单的相乘,这个背后的假设就是词之间的出现是独立的事件:
By estimating the likelihood for each predictor variable individually and then multiplying them, we are making the very strong assumption that the predictor variables are independent
大家要知道,很多情况下这个假设并不成立,通常情况下朴素贝叶斯依然可以表现的很好,但是如果预测变量之间的相关性太大就不建议用朴素贝叶斯了。
写到这儿,大家可能要问,证据呢?公式里面不是还有个分母嘛?跑哪去了。
问得好,
在贝叶斯法则的式子中,后验以及似然和先验都是能够很好地从数据中获得或者直接从数据中学习得到的,比如我们的例子中,每个主题有哪些词(似然)和每个主题的概率(先验)都是很好得到的,而我们的证据在这个例子中就是一条微博可能出现的词却是无法预测的。所以我们会把贝叶斯法则的分母部分去掉:
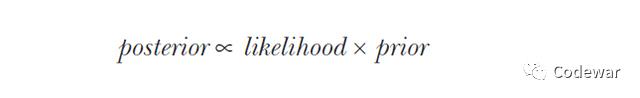
去掉分母之后就成了后验与似然和先验的积成正比,也就是似然与先验的积越大相应的后验就越大,在此例中也就是微博所属的主题的可能性越大,知道这个同样也可以满足我们划分类别的需求。
就划给后验最大的主题嘛。
我们对同一条微博每一个主题都计算后验:
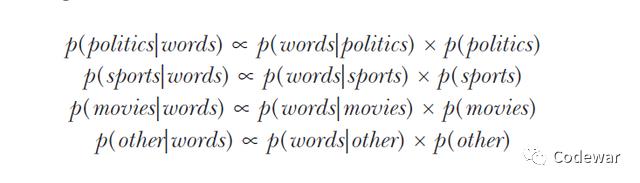
然后我们选取后验最大的哪一个主题就是我们这条微博对应的主题。
以上就是朴素贝叶斯算法的基本思想,希望能启发大家。
训练一个朴素贝叶斯模型
我们现在有如下的数据,数据是关于议员投票的,v1到v16是一个议员的16次投票情况,我们要做的就是用这16次投票情况来预测我们的议员到底是共和党的还是民主当的。
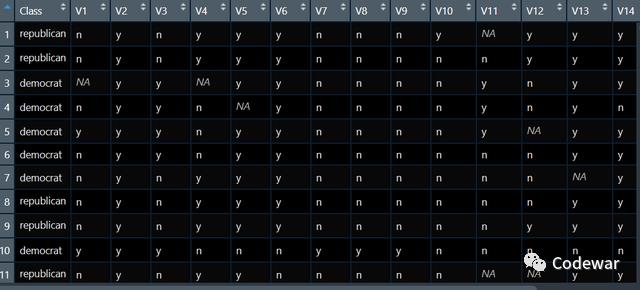
模型的训练依然是3步,第一步设定任务,第二步设定学习器,第3步训练,代码如下:
votesTask <- makeClassifTask(data = votesTib, target = "Class")
bayes <- makeLearner("classif.naiveBayes")
bayesModel <- train(bayes, votesTask)运行上面的代码我们的朴素贝叶斯分类模型就训练好了。
接下来看模型验证。
模型验证
我们使用10折验证,代码如下:
kFold <- makeResampleDesc(method = "RepCV", folds = 10, reps = 50,
stratify = TRUE)
bayesCV <- resample(learner = bayes, task = votesTask,
resampling = kFold,
measures = list(mmce, acc, fpr, fnr))因为我们的问题是一个2分类问题,所以我们评价指标额外输出假阳性和假阴性率。

可以看到90%的个案都被我们的模型预测正确了,还行哈。
我们接下来用我们这个模型来预测新数据。
使用模型做预测
假设现在新来一个议员,他的16次投票情况如下:
politician <- tibble(V1 = "n", V2 = "n", V3 = "y", V4 = "n", V5 = "n",
V6 = "y", V7 = "y", V8 = "y", V9 = "y", V10 = "y",
V11 = "n", V12 = "y", V13 = "n", V14 = "n",
V15 = "y", V16 = "n")我们现在用我们训练的朴素贝叶斯模型来预测这个议员到底是共和党的还是民主党的,代码如下:
politicianPred <- predict(bayesModel, newdata = politician)
getPredictionResponse(politicianPred)
可以看到我们的模型预测这个新议员为民主党的。
支持向量机
我们接着看支持向量机,支持向量机是通过给我们的原始数据增加维度从而到达到划分类别的目的的一种方法。
想象一个例子,你想预测你老板的心情,然后你偷偷收集了数据,包括你上班玩了多久游戏,公司每天挣了多少钱,然后你也记录了第二天老板的心情,然后你就这么记录了一周,然后你打算用这些数据来预测老板的心情。
假如下面这个图就是你记录的数据,横轴是你上班玩游戏的时间,纵轴是公司赚的钱,共两个预测变量,那么SVM要做的就是在数据中找到相应的超平面,对于我们这个二维数据,超平面就是一条线,要使得这个超平面可以很好第划分两类数据。
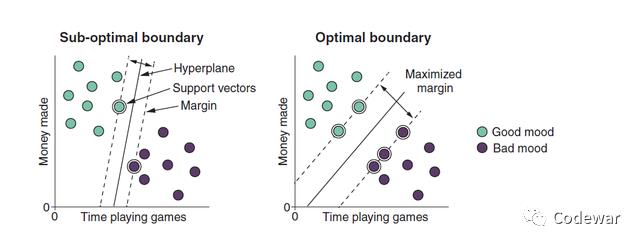
如何做到的呢?
其实对我们上面的这个例子,你可以找很多的超平面,这些超平面都可以完美无误地划分老板的心情,但是我们要追求的是最佳超平面,这个最佳的超平面可以最大化两类边缘距离margin:
The margin is a distance around the hyperplane that touches the fewest training cases
就是说这个最佳超平面到每类的最近的点的距离是最大的。而这些最近的点就叫做支持向量。
为啥叫支持向量呢,搞这么奇怪的名字。
The cases in the data that touch the margin are called support vectors because they support the position of the hyperplane (hence, the name of the algorithm)
解释是,这些点支持了超平面的位置,所以就叫支持向量。
从这个意义上看,作为支持向量的这些点是非常重要的,它直接影响超平面的位置,也就是直接影响整个算法。看下图:
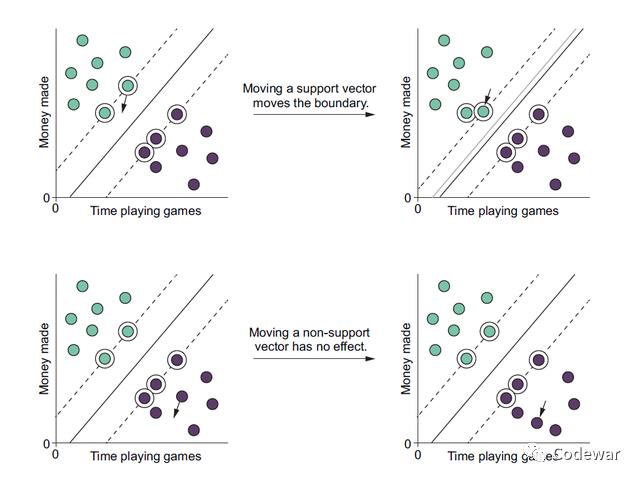
从上面的图中可以看出,如果我们把数据中一个支持向量移个位置,那么我们的超平面也就相应的移位,但是如果我们将其他的个案移位,其实是对超平面没有影响的,所以数据中的支持向量是重中之重。
在上面的例子中我们的数据类别是可以很好地区分为2类的,但是实际中每类数据经常会混杂在一起,仅凭一条线其实是分不开两类数据的,这个时候我们如何找超平面呢?
这个时候又得给大家介绍另外的两个概念,一个叫hard margin,另一个叫soft-margin,所谓的hard margin就是在类边缘之间是不允许有数据存在的,就像我们刚刚的例子的情况一样,这个时候两类是完全可分的,所谓的soft-margin就是超平面分完后,两类边缘之间依然有数据,这些数据就是无法被准确划分的,通常soft-margin用的比较多。
那么,我们可以到底允许几个数据存在在边缘之间呢?这个是由我们通过超参数来控制的,就是我们可以控制这个边缘的软硬程度,越硬我们依赖的支持向量就越少,越容易过拟合,越软就越多,越容易欠拟合:
The harder the margin is, the fewer cases will be inside it; the hyperplane will depend on a smaller number of support vectors. The softer the margin is, the more cases will be inside it; the hyperplane will depend on a larger number of support vectors.
SVM用于线性不可分的数据
SVM令人惊叹的一点就是,它可以给数据额外增加维度,让原本线性不可分的数据变成线性可分。非常巧妙,具体是怎么做的呢,我们看下图:左上角是我们的数据,我们有两个预测变量variable1和variable2,从图中可以看到仅凭这两个预测变量我们是无法将两类数据线性分开的,但是,我们可以通过SVM算法给我们的数据增加一个维度(如右上图),此时形成一个二维的超平面就可以成功地将数据分为两类。
这个SVM扯出来的新的平面,叫做核kernel。
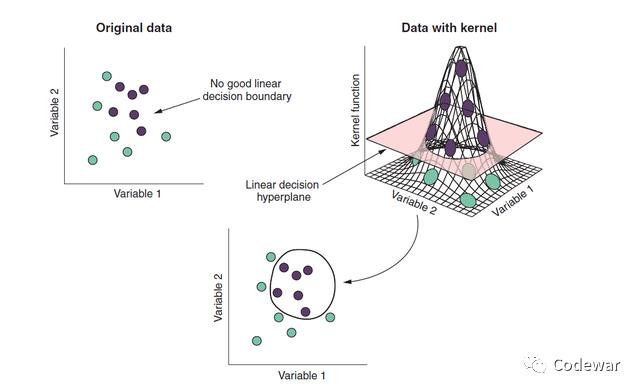
那么SVM是如何形成这个新的平面,也就是新的核的呢?
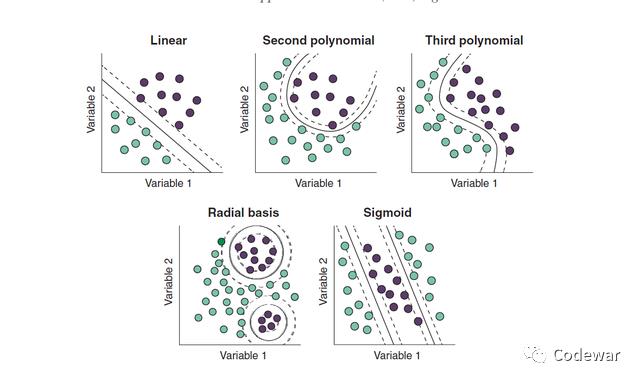
是通过一个叫核函数的东西,常见的核函数见下图:

在训练的时候到底用哪个核函数是你决定的,所以核函数也是SVM的超参数,我们可以进行超参调试(之前的文章有介绍),一般不同的核函数适用不同的数据情形,见下图:
SVM不止核函数这一个超参数,还有很多,我们接着介绍:
SVM的超参数
首先第一个超参数就是核函数,你得自己设定核函数,规定你到底想怎么样把数据扯成多一维,第二个超参数叫做The degree hyperparameter(我也不知道这个中文怎么翻译合适,反正中文资料好少哦,所以我写的文章大家且看且珍惜);这个参数是规定你划分支持向量边界的时候的曲度的。
The degree hyperparameter, which controls how “bendy” the decision boundary will be for the polynomial kernel
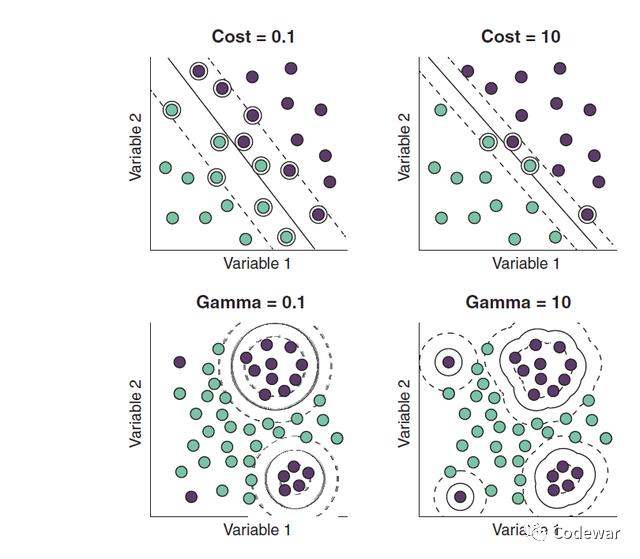
第三个超参数是C参数,这个参数是规定边界软硬程度的(边界内容许几个个案)。
The cost or C hyperparameter, which controls how “hard” or “soft” the margin is
第4个超参是伽马参数,这个参数规定个体支持向量的影响权重。
The gamma hyperparameter, which controls how much influence individual cases have on the position of the decision boundary
这儿给大家解释下C和伽马,C越大边界内容许的个案越多(如下图的上半部分),伽马越大单个个案的影响越大,模型可以越精细,越容易过拟合(如下图下半部分):
反正就是SVM的超参挺多,为了模型好,训练的时候都得调试。
SVM实例操练
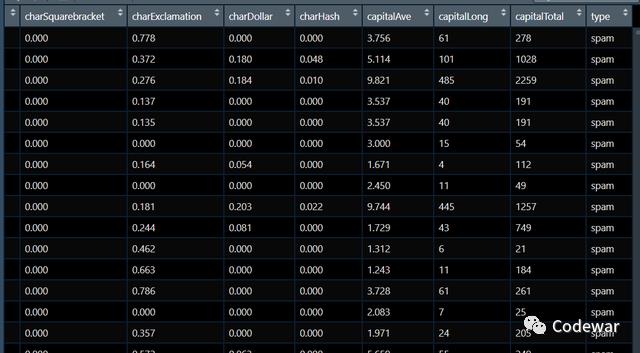
我现在有一个垃圾邮件数据库,数据包含邮件类型type,还有57个邮件的特征,我们要做的就是训练一个SVM模型来预测新的邮件是不是垃圾邮件。
数据大概长这样:
训练模型依然是3步走:第一定义任务,第二定义学习器,第三训练,因为我们SVM会有超参调试,所以调试好了再进行第三步,前两步的代码如下:
spamTask <- makeClassifTask(data = spamTib, target = "type")
svm <- makeLearner("classif.svm")接下来设置超参范围并进行调试:
kernels <- c("polynomial", "radial", "sigmoid")
svmParamSpace <- makeParamSet(
makeDiscreteParam("kernel", values = kernels),
makeIntegerParam("degree", lower = 1, upper = 3),
makeNumericParam("cost", lower = 0.1, upper = 10),
makeNumericParam("gamma", lower = 0.1, 10))
randSearch <- makeTuneControlRandom(maxit = 20)
cvForTuning <- makeResampleDesc("Holdout", split = 2/3)
tunedSvmPars <- tuneParams("classif.svm", task = spamTask,
resampling = cvForTuning,
par.set = svmParamSpace,
control = randSearch)
parallelStop()
tunedSvmPars#看调试结果因为我们需要调试的超参比较多,为了节省算力,所以最优超参的寻找方法我们用的random search法,然后对每个超参组合我们用简单交叉验证进行评估,最终找到最好的超参组合。
最终我们得到的超参组合为

好了,我们现在就根据调试出来的最优的超参来进行第3步,也就是训练我们的模型:
tunedSvm <- setHyperPars(makeLearner("classif.svm"),
par.vals = tunedSvmPars$x)
tunedSvmModel <- train(tunedSvm, spamTask)运行上面的代码模型就训练好了,接下来进行交叉验证:
outer <- makeResampleDesc("CV", iters = 3)
svmWrapper <- makeTuneWrapper("classif.svm", resampling = cvForTuning,
par.set = svmParamSpace,
control = randSearch)
cvWithTuning <- resample(svmWrapper, spamTask, resampling = outer)
cvWithTuning交叉验证的时候依然要考虑超参,因为我们的训练的数据不同最优超参也应该是不同的,所以在模型的验证时也应该考虑超参调试,所以上面的代码将超参调试进行了封装后一同放到了交叉验证的流程中。
最终我们得到了最终的模型:
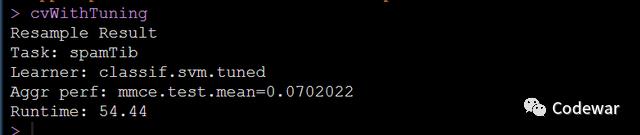
可以看到我们的模型分类对了1-0.07=99.3%的个案,可以说是一个非常好的SVM的模型了。
小结
今天给大家写了朴素贝叶斯和支持向量机的原理和实现方法,感谢大家耐心看完,自己的文章都写的很细,代码都在原文中,希望大家都可以自己做一做,请关注后私信回复“数据链接”获取所有数据和本人收集的学习资料。如果对您有用请先收藏,再点赞转发。
也欢迎大家的意见和建议,大家想了解什么统计方法都可以在文章下留言,说不定我看见了就会给你写教程哦。
猜你喜欢:
机器学习:逻辑回归分类器(一)
机器学习算法发展的简要历史
机器学习:什么是自然语言处理
python机器学习:机器学习模型评价-交叉验证与留一验证
机器学习:简单理解支持向量机SVM
python机器学习:多元线性回归模型实战
R机器学习:分类算法之K最邻进算法(KNN)的原理与实现
python机器学习:线性回归中的哑变量转换
python非监督机器学习入门:K均值聚类实例操练
Python机器学习入门:线性回归实例操练
python机器学习:回归问题学习模型的评价方法及代码实现
python机器学习:如何划分训练集和测试集
python机器学习:如何储存训练好的模型并重新调用
python机器学习:分类问题学习模型的评价方法及代码实现
R机器学习:分类算法之判别分析LDA,QDA的原理与实现
R机器学习:分类算法之logistics回归分类器的原理和实现
什么是机器学习,为什么我们需要机器学习
机器学习:分类问题
机器学习中的数据预处理
机器学习:独热编码one-hot encoding
机器学习:朴素贝叶斯的机理
机器学习:避免过度拟合的方法
机器学习实战:迷你数据库+超详细解释
机器学习:基于决策数的广告点击率预测
机器学习:用例子手撕朴素贝叶斯
机器学习中的过拟合,欠拟合和偏倚方差折衷
扫描二维码获取
更多精彩
Codewar
以上是关于R机器学习:朴素贝叶斯与支持向量机的原理与实现的主要内容,如果未能解决你的问题,请参考以下文章
机器学习:基于朴素贝叶斯实现单词拼写修正器(附Python代码)
机器学习强基计划4-3:详解朴素贝叶斯分类原理(附例题+Python实现)