Apache Pulsar 之企业级特性-多租户介绍
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Apache Pulsar 之企业级特性-多租户介绍相关的知识,希望对你有一定的参考价值。
参考技术AApache Pulsar 最初诞生于雅虎,当时就是为了解决雅虎内部各个部门之间数据的协调,所以多租户特性显得至关重用,Pulsar 从诞生之日起就考虑到多租户这一特性,并在后续的实现过程中,将其不断的完善。 多租户这一特性,使得各个部门之间可以共享同一份数据,不用单独部署独立的系统来操作数据,很好的保证了各部门间数据一致性的问题,同时简化维护成本。
在介绍 Pulsar 多租户之前,先来看一下,正常一个系统要实现一个多租户需要做哪些事情:
Pulsar 的多租户设计符合上述要求:
如下图所示:在一个 Pulsar 集群中,有三个概念:tenant(图中的 property 是之前的一种叫法,现在更习惯将其称为:tenant)、namespace、topic。这一点从 pulsar 中 topic 的命名组成也可以反应出来,例如: persistent://tenant/namespace/topic ,在 Pulsar 中,使用 tenant , namespace , topic-name 来唯一标识一个 topic。
tenant 代表的是租户名,它是一个资源的隔离单位,一个 tenant 下可以有多个 namespace。namespace 用来管理其下面所属的 topics,可以在 namespace 级别给 topic 设置相应的策略,比如 retention,backlog,ratelimit。一个 namespace 下又可以有多个 topic,他们的权限大小也是由上到下。Pulsar 的多租户通过 tenant、namespace、topic 形成多级管理系统。
开篇中提到,一个多租户系统需要在租户内提供系统级别的安全性,细分来讲,主要可以归类为一下两点:
在 Pulsar 中,多租户的安全性是通过身份验证和授权机制实现的。当 client 连接到 pulsar broker 时,broker 会使用身份验证插件来验证此客户端的身份,然后为其分配一个 string 类型的 role token 。role token 主要有如下作用:
Pulsar 目前支持两种身份认证:
当然,用户也可以使用自己实现的身份认证程序。
当身份认证系统识别出客户端的 role token 之后,Pulsar broker 会使用授权系统来告诉客户端当前你可以执行哪些操作。 授权操作是在 tenant 级别进行配置的 ,这意味着在 Pulsar 集群中,允许用户根据不同的角色设定多个授权方案。 具体的权限操作是在 namespace 级别进行设置和管理的 ,例如:针对某一个 topic 是否具有 produce 或 consume 的权限归属于 namespace 这个级别来控制。换句话来说:在 tenant 级别 用户可以配置,什么样的 role 拥有对哪些 tenant 操作的权限,在 namespace 级别用户可以配置,针对某一 topic 当前 role 拥有什么样的权限,又回到了开头所介绍的,namespace 主要用来管理它所包含的 topics 的属性。
通过认证和授权系统巧妙的将租户与 topics 之间的执行权限等问题剥离开来,从而实现在租户内满足系统级别安全性的目的。
隔离性主要分为如下两种:
在 Pulsar 中,为了保证良好的扩展性,采用了存储和计算分离的架构设计,而存储(bookie)和计算 (broker)又是 produce 和 consume 所共享的资源,为了更好的实现隔离性,Pulsar 分别在存储和计算层做了不同的处理。
在存储方面,Apache Pulsar 使用了另外一个 Apache 的顶级项目 Bookkeeper 来作为其存储层。bookie 是 Bookkeeper 中的一个实例,一个 bookie 拥有多个 ledgers,每个 ledger 对应 Pulsar 中的一个 topic。Bookkeeper 本身的 I/O 分离 能够很好的为此做支撑。在单个 bookie 中,有一个 journal 日志文件(一般有一块专有的 journal 盘用于 journal 文件的写入)(类似于 LSMTree 中的 WAL 文件)会以 append 的形式将所有的写操作追加写入其内部。当写入完成之后,后台会有一个单独的线程来定期将 journal 文件的数据 flush 到磁盘中。这种 I/O 架构的设计实现了写入和读取操作之间的隔离,这样租户可以尽可能快的读取数据,同时写的吞吐量和延迟不会受到读取操作的影响。
除了 I/O 隔离外,不同的租户可以为不同的 namespace 配置不同的存储配额。如果租户内消息的大小达到了存储配额的限制,Pulsar 会采取相应的措施,例如:阻止消息生成,抛出异常或丢弃消息等。
为了满足 SLAs, Pulsar 在 Broker 层面也提供了多种机制。首先,在 Pulsar broker 中的一切操作都是异步进行的。每个 Broker 使用的内存资源是有上限的,当 Broker 达到配置的 CPU 或内存使用的阈值,Pulsar 会迅速的将流量转移到负载较小的 Broker 上来处理。在 Pulsar 中,有一个组件 load manager component 专门用来处理这种情况,这受益于 Pulsar 优秀的架构设计:计算与存储分离。这使得 Broker 近乎是无状态的,Broker 本身不存储任何数据,所以这种流量负载的转移成本很小而且速度很快,所以在这里并不需要担心流量负载时租户的特性是否会打折扣。
其次,在消息的生产和消费方面,Pulsar 都做了流量控制。在生产者方面 ,租户可以配置当前消息发送到 broker 和 bookies 的速度,避免当前用户发送消息的速度大于系统本身处理消息的能力。在消费者方面,租户可以配置当前 broker 可以给 consumer 发送多少未完成的消息。除此之外,Pulsar 还可以限制 Broker 以指定的速率向消费者投递消息,避免消费者的消费能力大于当前 Broker 的处理能力。
软隔离中提到的机制可以确保 Pulsar 在共享 Broker 和 Bookies 资源时能很好的保证隔离性。但是,在某些情况下,应用程序也需要物理资源隔离。Pulsar 允许将某些租户或名称空间与特定 Broker 进行隔离。这可确保这些租户或命名空间可以充分利用该特定 Broker 上的资源。
此选项还可用于测试不同的配置,调试并快速响应生产中发生的任何意外情况。例如,当前有一个用户可能在 Broker 触发可能影响其他租户性能的不良行为。在这种情况下,可以将该特定租户物理隔离出来,然后进行确认或者修复。
除了物理隔离 Broker 上的流量之外,你还可以隔离存储相关的业务。可以在 namespace 级别来配置相关的 placement policy 来达到目的。
你不得不知道的 Apache Pulsar 三大跨地域复制解决方案

导读
Apache Pulsar 是一个多租户、高性能的服务间消息传输解决方案,支持多租户、低延时、读写分离、跨地域复制、快速扩容、灵活容错等特性。其原生支持了跨洲际级别的跨地域复制的解决方案,并结合其自身的 tenant 和 namespace 级别的抽象,可以灵活的支持不多种类,不同场景下的跨地域复制解决方案。
作者介绍
冉小龙
腾讯云微服务产品中心研发工程师
Apache Pulsar Committer
Apache BookKeeper Contributor

需求意义
在 Geo-Replication 的设计支撑下,其一,我们可以比较容易的将服务分散到多个机房;其二,可以应对机房级别的故障,即在一个机房不可用的情况下,服务可以转接到其它的机房来继续对外提供服务。
摘要
Apache Pulsar 内置了多集群跨地域复制的功能,GEO-Repliaaction 是指把分散在不同物理地域的集群通过一定的配置方式让其能在集群之间进行数据的相互复制。
根据消息是否为异步读写的维度,跨地域复制可以分为如下两种方案:
-
同步模式:如果对数据的容灾级别要求非常高,可以采用同步跨城部署模式,数据副本会存在不同城市之间,不足是跨城之间网络的波动会对性能有较大的影响,因为需要等待多个城市都写成功才会返回客户端成功。 异步模式:如果对数据的容灾级别不是那么高,可以采用异步跨城部署模式,例如有两个独立的数据中心上海和多伦多,写入上海的消息会异步再写一份到多伦多,优点不影响主流程性能,不足多一份存储开销。
下面我们讨论的是异步模式下,pulsar 的跨地域复制方案。
Pulsar 目前支持以下三种异步跨地域复制的方案:
-
全连通
-
单向复制
-
Failover 模式
从是否具有 configurationStoreServers (global zookeeper)的角度可以分为以下两种异步跨地域复制方案:
-
全连通
2. 没有 configurationStoreServers
-
单向复制
Failover 模式
在整个跨地域复制中的一个核心理念在于,各个集群之间的数据是否能够互通,它们之间的交互主要依靠如下配置信息:
-
cluster (cluster name) -
zookeeper (local cluster zk servers) -
configuration-store (global zk servers) -
web-service-url -
web-service-url-tls -
broker-service-url -
broker-service-url-tls
在初始化 pulsar cluster 时,用户可以指定上述对应的信息,示例如下:
initialize-cluster-metadata \--cluster pulsar-cluster-1 \--zookeeper zk1.us-west.example.com:2181 \--configuration-store zk1.us-west.example.com:2181 \--web-service-url http://pulsar.us-west.example.com:8080 \--web-service-url-tls https://pulsar.us-west.example.com:8443 \--broker-service-url pulsar://pulsar.us-west.example.com:6650 \--broker-service-url-tls pulsar+ssl://pulsar.us-west.example.com:6651
Full-mesh(全连通)
Full-mesh 的形式允许数据在多个集群中共享,如下图:
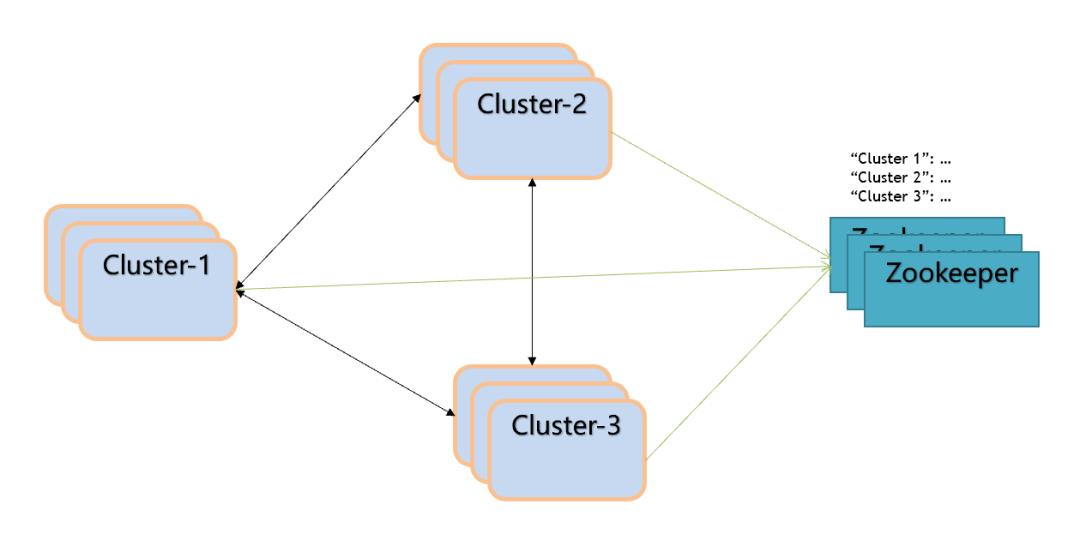
概念解析
-
configurationStoreServers: 存储的是各个集群的配置信息,也就是让集群之间能够互相感知到对方的地址信息。除此之外还会存储 tenant 和 namespace 的信息,主要目的在于简化操作流程,当更新其中一个集群的信息,其它集群都可以通过 global zookeeper 获取到这次信息的更改。 -
tenant: 当前创建的 tenant 允许哪些集群进行操作(–allowed-clusters) namespace: 当前创建的 namespace 允许在哪几个集群之间进行数据的复制 (–clusters)
原理
对于多个集群之间的数据复制,我们均可以简化到两个集群之间的数据复制,基于这个理念,Geo-Replication 的原理如下图所示:
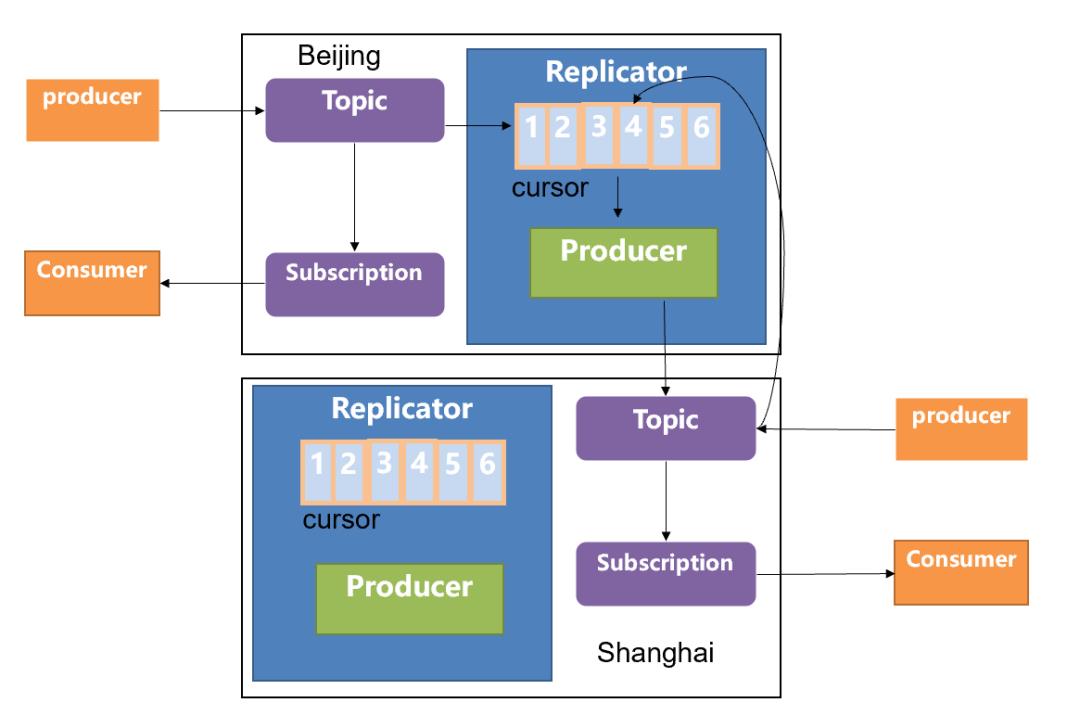
当前拥有两个集群,分别部署在北京和上海,当用户在北京的集群中使用 producer 发送数据时,首先会发送到北京机房的本地集群中(topic1)与此同时会去创建一个 replication cursor,用于专门复制数据的一个游标,通过这个 cursor 信息,你可以判断当前数据究竟复制到哪一个阶段。同时会去创建 replication producer,它会把数据从北京机房的 topic1 中读取数据,然后将数据写到上海机房的 topic1 中,上海机房的 broker 收到 producer 的请求之后,会写到本地相同的 topic 中来(topic1)。此时如果上海机房的用户开启 consumer 去消费数据的话,会接收到由北京机房 producer 生产的数据信息。反之亦然。
在这里需要说明如下问题:
-
在全连通的场景下,北京机房的数据会复制给上海机房的集群,上海机房的数据也会复制给北京的机房,那么是否会出现北京机房的数据复制给上海机房之后,上海机房反向再把该条数据复制回到北京,形成数据的死循环?因为当 producer 在发送消息时,它是知道自己当前所在的集群是属于哪一个的,当生产的消息经过 replication producer 的复制时,会在该消息标记一个 label:replication_from,代表这条消息从哪里来,可以解决反向复制的问题。 -
在 Geo-Replication 的场景下,同样可以保证消息的 exactly-once 的语义(at-least-once + broker 端的去重(producer-name + sequence ID)) 复制的延迟取决于两个机房之间网络的时延,如果时延比较大,需要考虑两个机房之间的网络情况。
一旦配置了 global zookeeper 之后,数据之间的复制都是双向复制的,所有 global zookeeper 下面挂载的集群之间的数据都是互通的。
单向复制
那么在不配置 global zookeeper 的情况下,如何去做跨集群复制的场景呢?
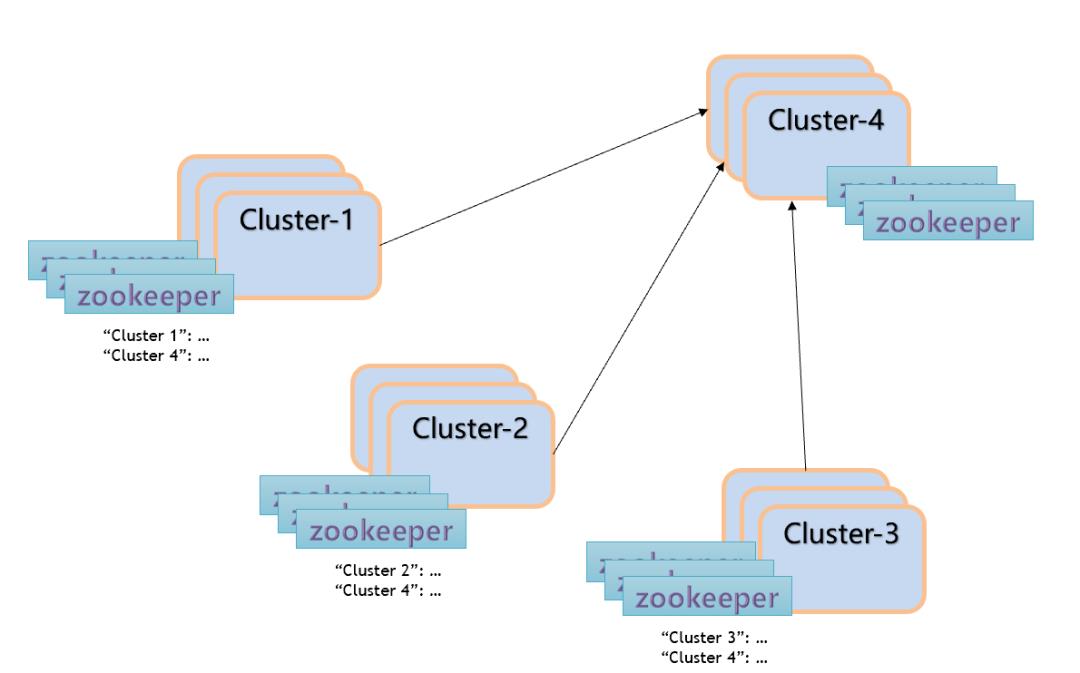
Failover 模式
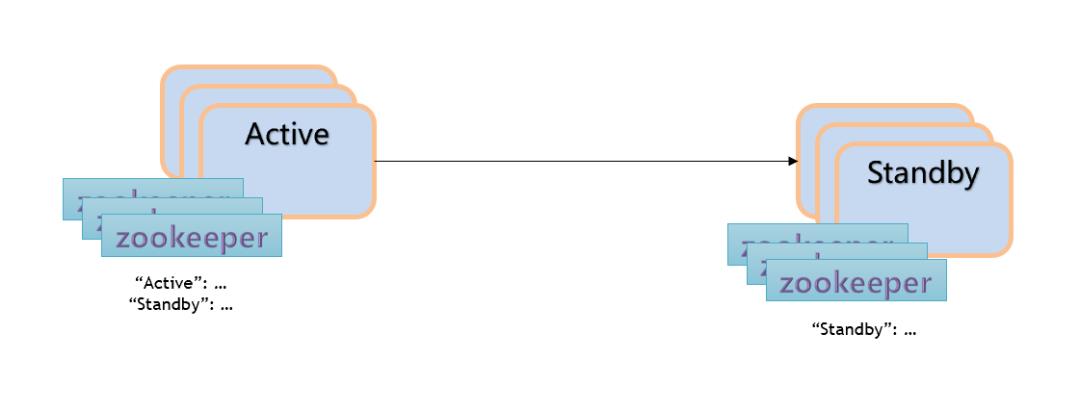
Failover 模式是单向复制的特例。
Failover 模式下,远端机房的集群只是用来做数据的备份,并不会有 producer 和 consumer 的存在,只有当当前处于 active 的集群宕机之后,才会把对应的 producer 和 consumer 切换到对应的 standby 集群中来继续消费。因为有 replication sub 的存在,所以会一同将订阅的状态也复制到备份机房。
目前 pulsar Geo-Replication
存在的问题
-
Pulsar 只能保证单机房生产的消息顺序,在多机房的场景下没办法保证多个机房的消息全局有序 -
由于 cursor snapshot 是定期进行的,在时间上精确度不会太高,多少有些偏差。 -
目前只会同步 “Mark delete position” 的位置,对于单独签收的消息暂时无法同步。 -
只有在所有相关集群都处于「可用」状态时,才可以进行 cursor snapshot。 当使用 cursor snapshot 后,会产生一些缓存,影响到后续涉及 backlog 的计算结果。
往期
推荐

了解更多微服务、消息队列的相关信息!
解锁超多鹅厂周边!
以上是关于Apache Pulsar 之企业级特性-多租户介绍的主要内容,如果未能解决你的问题,请参考以下文章
博文推荐 | Apache Pulsar 三大跨地域复制解决方案
你不得不知道的 Apache Pulsar 三大跨地域复制解决方案
博文干货|在 Kotlin 中使用 Apache Pulsar
05_Pulsar的主要组件介绍与命令使用名称空间Pulsar的topic相关操作Pulsar Topic(主题)相关操作_高级操作