你不得不知道的 Apache Pulsar 三大跨地域复制解决方案
Posted 腾讯云中间件
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了你不得不知道的 Apache Pulsar 三大跨地域复制解决方案相关的知识,希望对你有一定的参考价值。

导读
Apache Pulsar 是一个多租户、高性能的服务间消息传输解决方案,支持多租户、低延时、读写分离、跨地域复制、快速扩容、灵活容错等特性。其原生支持了跨洲际级别的跨地域复制的解决方案,并结合其自身的 tenant 和 namespace 级别的抽象,可以灵活的支持不多种类,不同场景下的跨地域复制解决方案。
作者介绍
冉小龙
腾讯云微服务产品中心研发工程师
Apache Pulsar Committer
Apache BookKeeper Contributor

需求意义
在 Geo-Replication 的设计支撑下,其一,我们可以比较容易的将服务分散到多个机房;其二,可以应对机房级别的故障,即在一个机房不可用的情况下,服务可以转接到其它的机房来继续对外提供服务。
摘要
Apache Pulsar 内置了多集群跨地域复制的功能,GEO-Repliaaction 是指把分散在不同物理地域的集群通过一定的配置方式让其能在集群之间进行数据的相互复制。
根据消息是否为异步读写的维度,跨地域复制可以分为如下两种方案:
-
同步模式:如果对数据的容灾级别要求非常高,可以采用同步跨城部署模式,数据副本会存在不同城市之间,不足是跨城之间网络的波动会对性能有较大的影响,因为需要等待多个城市都写成功才会返回客户端成功。 异步模式:如果对数据的容灾级别不是那么高,可以采用异步跨城部署模式,例如有两个独立的数据中心上海和多伦多,写入上海的消息会异步再写一份到多伦多,优点不影响主流程性能,不足多一份存储开销。
下面我们讨论的是异步模式下,pulsar 的跨地域复制方案。
Pulsar 目前支持以下三种异步跨地域复制的方案:
-
全连通
-
单向复制
-
Failover 模式
从是否具有 configurationStoreServers (global zookeeper)的角度可以分为以下两种异步跨地域复制方案:
-
全连通
2. 没有 configurationStoreServers
-
单向复制
Failover 模式
在整个跨地域复制中的一个核心理念在于,各个集群之间的数据是否能够互通,它们之间的交互主要依靠如下配置信息:
-
cluster (cluster name) -
zookeeper (local cluster zk servers) -
configuration-store (global zk servers) -
web-service-url -
web-service-url-tls -
broker-service-url -
broker-service-url-tls
在初始化 pulsar cluster 时,用户可以指定上述对应的信息,示例如下:
initialize-cluster-metadata \--cluster pulsar-cluster-1 \--zookeeper zk1.us-west.example.com:2181 \--configuration-store zk1.us-west.example.com:2181 \--web-service-url http://pulsar.us-west.example.com:8080 \--web-service-url-tls https://pulsar.us-west.example.com:8443 \--broker-service-url pulsar://pulsar.us-west.example.com:6650 \--broker-service-url-tls pulsar+ssl://pulsar.us-west.example.com:6651
Full-mesh(全连通)
Full-mesh 的形式允许数据在多个集群中共享,如下图:
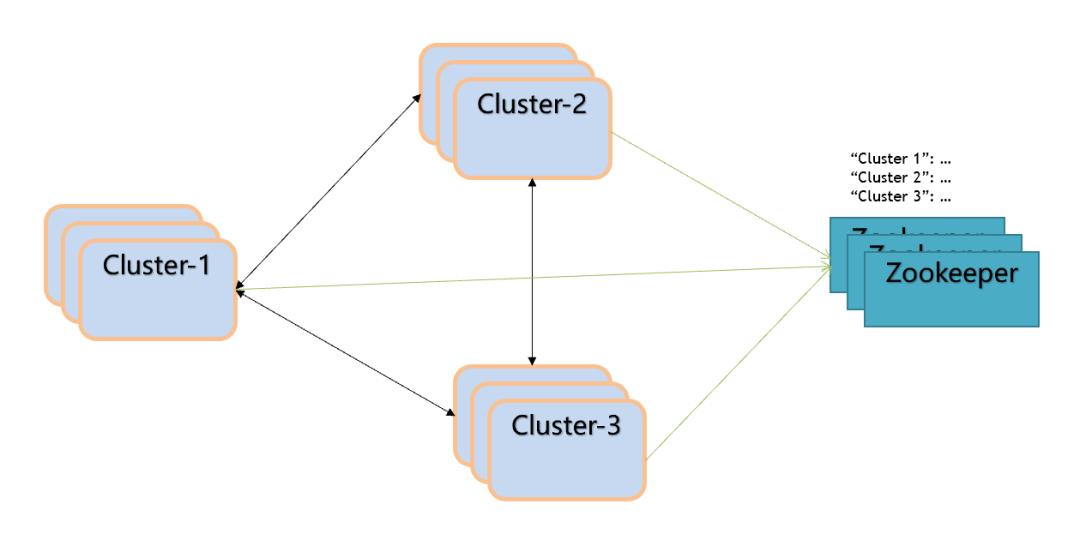
概念解析
-
configurationStoreServers: 存储的是各个集群的配置信息,也就是让集群之间能够互相感知到对方的地址信息。除此之外还会存储 tenant 和 namespace 的信息,主要目的在于简化操作流程,当更新其中一个集群的信息,其它集群都可以通过 global zookeeper 获取到这次信息的更改。 -
tenant: 当前创建的 tenant 允许哪些集群进行操作(–allowed-clusters) namespace: 当前创建的 namespace 允许在哪几个集群之间进行数据的复制 (–clusters)
原理
对于多个集群之间的数据复制,我们均可以简化到两个集群之间的数据复制,基于这个理念,Geo-Replication 的原理如下图所示:
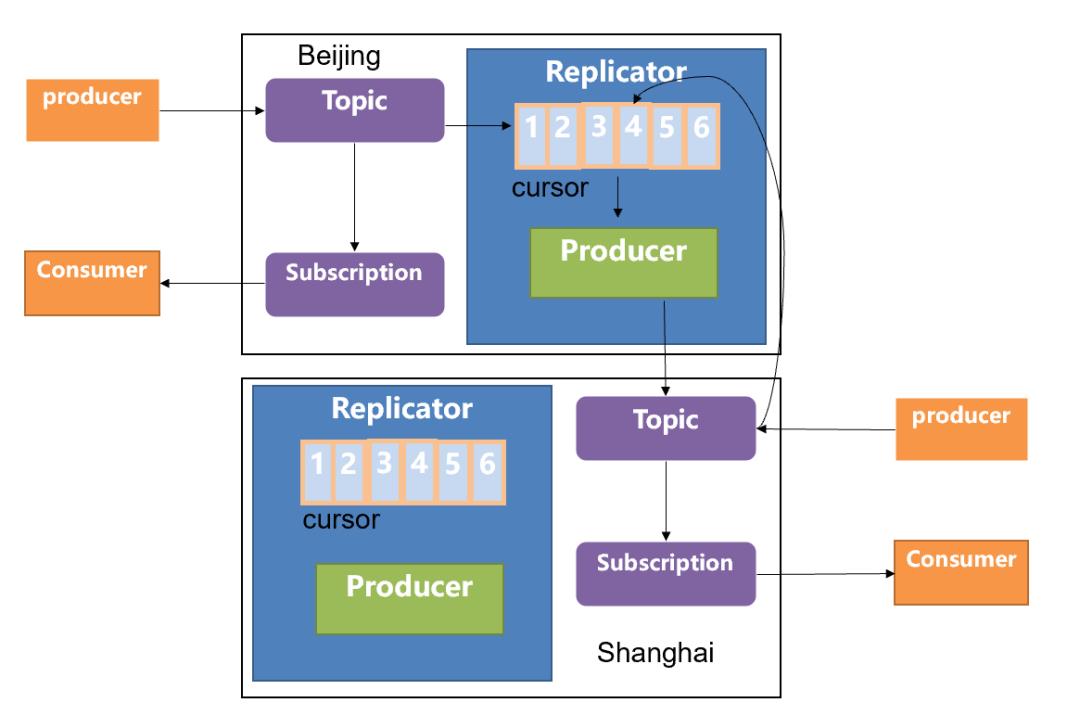
当前拥有两个集群,分别部署在北京和上海,当用户在北京的集群中使用 producer 发送数据时,首先会发送到北京机房的本地集群中(topic1)与此同时会去创建一个 replication cursor,用于专门复制数据的一个游标,通过这个 cursor 信息,你可以判断当前数据究竟复制到哪一个阶段。同时会去创建 replication producer,它会把数据从北京机房的 topic1 中读取数据,然后将数据写到上海机房的 topic1 中,上海机房的 broker 收到 producer 的请求之后,会写到本地相同的 topic 中来(topic1)。此时如果上海机房的用户开启 consumer 去消费数据的话,会接收到由北京机房 producer 生产的数据信息。反之亦然。
在这里需要说明如下问题:
-
在全连通的场景下,北京机房的数据会复制给上海机房的集群,上海机房的数据也会复制给北京的机房,那么是否会出现北京机房的数据复制给上海机房之后,上海机房反向再把该条数据复制回到北京,形成数据的死循环?因为当 producer 在发送消息时,它是知道自己当前所在的集群是属于哪一个的,当生产的消息经过 replication producer 的复制时,会在该消息标记一个 label:replication_from,代表这条消息从哪里来,可以解决反向复制的问题。 -
在 Geo-Replication 的场景下,同样可以保证消息的 exactly-once 的语义(at-least-once + broker 端的去重(producer-name + sequence ID)) 复制的延迟取决于两个机房之间网络的时延,如果时延比较大,需要考虑两个机房之间的网络情况。
一旦配置了 global zookeeper 之后,数据之间的复制都是双向复制的,所有 global zookeeper 下面挂载的集群之间的数据都是互通的。
单向复制
那么在不配置 global zookeeper 的情况下,如何去做跨集群复制的场景呢?
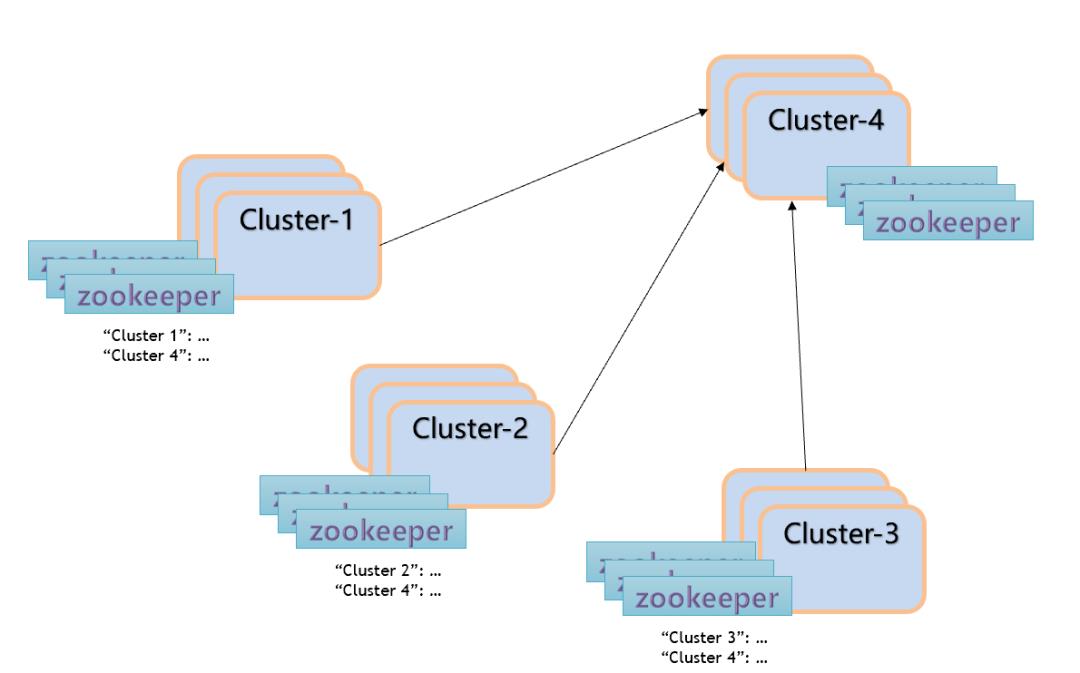
Failover 模式
Failover 模式是单向复制的特例。
Failover 模式下,远端机房的集群只是用来做数据的备份,并不会有 producer 和 consumer 的存在,只有当当前处于 active 的集群宕机之后,才会把对应的 producer 和 consumer 切换到对应的 standby 集群中来继续消费。因为有 replication sub 的存在,所以会一同将订阅的状态也复制到备份机房。
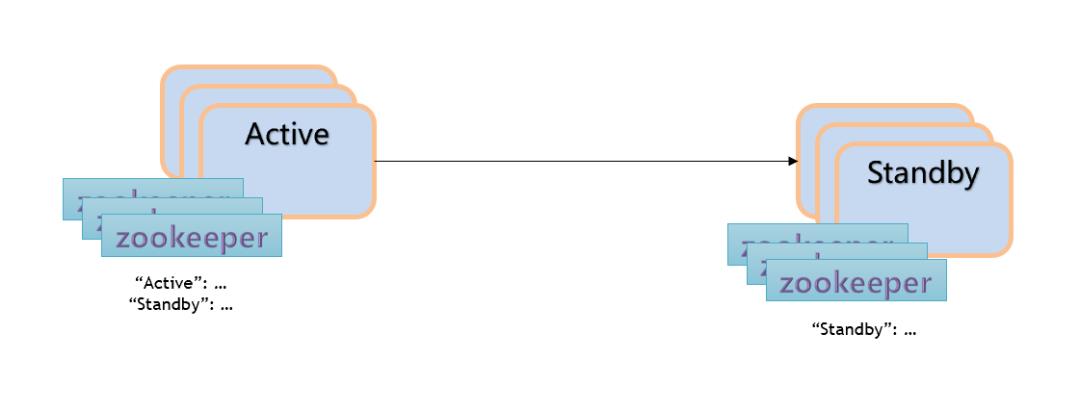
目前 pulsar Geo-Replication
存在的问题
-
Pulsar 只能保证单机房生产的消息顺序,在多机房的场景下没办法保证多个机房的消息全局有序 -
由于 cursor snapshot 是定期进行的,在时间上精确度不会太高,多少有些偏差。 -
目前只会同步 “Mark delete position” 的位置,对于单独签收的消息暂时无法同步。 -
只有在所有相关集群都处于「可用」状态时,才可以进行 cursor snapshot。 当使用 cursor snapshot 后,会产生一些缓存,影响到后续涉及 backlog 的计算结果。
往期
推荐

了解更多微服务、消息队列的相关信息!
解锁超多鹅厂周边!
以上是关于你不得不知道的 Apache Pulsar 三大跨地域复制解决方案的主要内容,如果未能解决你的问题,请参考以下文章