Hadoop之Hive分桶表
Posted 柳小葱
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hadoop之Hive分桶表相关的知识,希望对你有一定的参考价值。
🐁前一章节我们学习了hadoop的分区表,感兴趣的小伙伴可以查看下方的连接👇:
- 文章: Hadoop之Hive的分区表.
🍹今天我们来学习Hive中的分桶表,这一章节,使用较少,但需要了解即可。
1.分桶表
分区提供一个隔离数据和优化查询的便利方式。不过,并非所有的数据集都可形成合理的分区。对于一张表或者分区,Hive 可以进一步组织成桶,也就是更为细粒度的数据范围划分,将大文件拆成一个一个小文件。
重点是:分区针对的是数据的存储路径;分桶针对的是数据文件。
- 创建数据
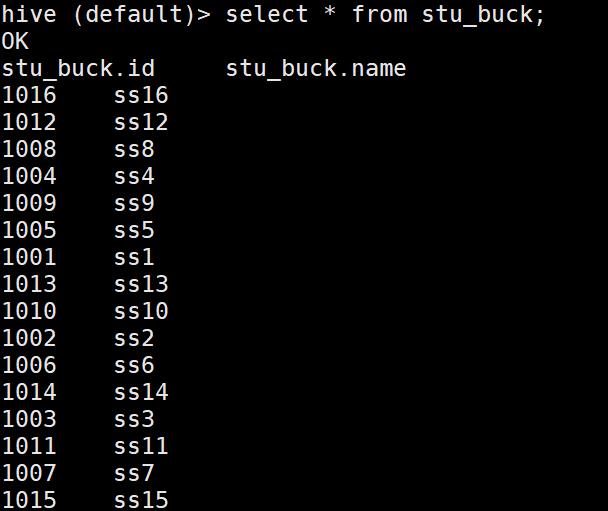
#数据集
1001 ss1
1002 ss2
1003 ss3
1004 ss4
1005 ss5
1006 ss6
1007 ss7
1008 ss8
1009 ss9
1010 ss10
1011 ss11
1012 ss12
1013 ss13
1014 ss14
1015 ss15
1016 ss16
- 创建数据表并导入数据
--创建分桶表
create table stu_buck(id int, name string)
clustered by(id) --分通字段必须在表的字段中
into 4 buckets
row format delimited fields terminated by '\\t';
--导入数据
load data local inpath '/opt/modul/datatest/student.txt'
into table stu_buck;
四个文件如下:
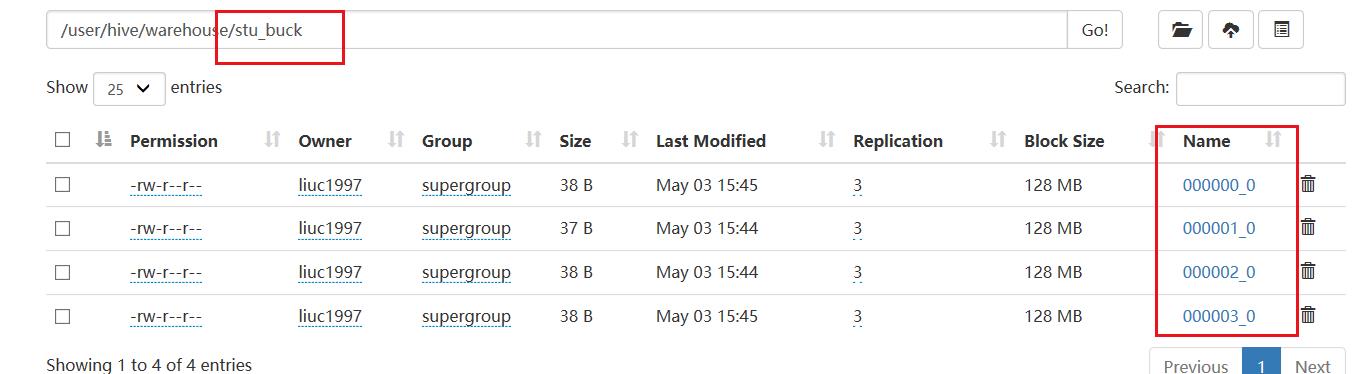
2.分桶规则与注意事项
- Hive 的分桶采用对分桶字段的值进行哈希,然后除以桶的个数求余的方式决定该条记录存放在哪个桶当中。
- reduce 的个数设置为-1,让 Job 自行决定需要用多少个 reduce 或者将 reduce 的个数设置为大于等于分桶表的桶数。
- 从 hdfs 中 load 数据到分桶表中,避免本地文件找不到问题。
- 也可以insert 方式将数据导入分桶表。
3.分桶表与抽样查询
对于非常大的数据集,有时用户需要使用的是一个具有代表性的查询结果而不是全部结果。Hive 可以通过对表进行抽样来满足这个需求。
抽样的语法
--x 的值必须小于等于 y 的值,x代表从哪个桶开始抽,Y代表将数据分为几份
TABLESAMPLE(BUCKET x OUT OF y)
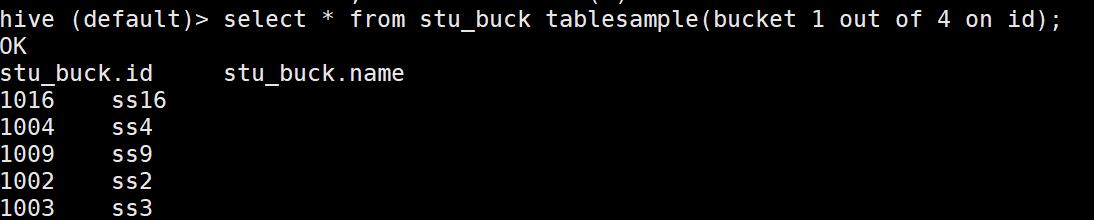
- 抽样查询表 stu_buck 中的数据。
select * from stu_buck tablesample(bucket 1 out of 4 on id);
参考资料
《大数据Hadoop3.X分布式处理实战》
以上是关于Hadoop之Hive分桶表的主要内容,如果未能解决你的问题,请参考以下文章