hadoop离线day09--Apache Hive
Posted Vics异地我就
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了hadoop离线day09--Apache Hive相关的知识,希望对你有一定的参考价值。
hadoop离线day09--Apache Hive
目录
Dynamic partition inserts 动态分区插入
今日内容大纲
#1、HQL DDL 数据定义语言
创建表
分区表
分桶表
修改表 alter
常用的show命令
#2、HQL DML 数据操纵语言
load加载数据
insert插入数据
mysql:insert+values
hive:insert+select
动态分区插入
数据导出
#3、HQL DQL 数据查询语言
select
hive自己特有的查询
CTE语法
union语法
Hive join
inner join、left join
#4、Hive shell命令行 参数配置
bin/hive shell
bin/beeline jdbc
hive参数配置方式
1、HQL DDL 数据定义语言
-
分区表
-
分区表引入,产生背景
--创建一张表 映射一个文件 create table t_user(id int,name string,country string) row format delimited fields terminated by ','; --能否在一张表的目录下 映射多个文件呢? --可以 保证多个文件之间字段、类型、个数、顺序是一致 --查询:找出来自于中国的用户 select * from t_user where country ="china"; --问题:在where过滤的时候 需要进行全表扫描 判断过滤条件十分满足 --全表扫描性能不高 如何优化? --通过hdfs底层存储格式 猜想:能否基于文件去扫描指定的文件,而不是全表扫描 效率不就提高了吗?
-
分区表创建
--基于业务分析 决定根据国家分区 create table t_user_part(id int,name string,country string) partitioned by(country string) row format delimited fields terminated by ','; Error: Error while compiling statement: FAILED: SemanticException [Error 10035]: Column repeated in partitioning columns --建表报错 分区字段重复 create table t_user_part(id int,name string,country string) partitioned by(guojia string) row format delimited fields terminated by ',';
-
分区表加载数据
--猜想方式1:使用hadoop fs -put 上传表的目录下 失败 没有指定该文件属于哪个分区 没有指定分区值 --正确方式: load data语法 load data local inpath '/root/hivedata/chian.txt' into table t_user_part partition(guojia="zhongguo"); --加载china.txt文件到分区表中 并且指定该文件属于zhongguo分区。 load data local inpath '/root/hivedata/usa.txt' into table t_user_part partition(guojia="meiguo"); load data local inpath '/root/hivedata/japan.txt' into table t_user_part partition(guojia="riben");
-
分区表使用
--查询:找出来自于中国的用户 select * from t_user where country ="china"; --非分区字段查询 select * from t_user where guojia ="zhongguo"; --基于分区表分区字段查询
-
总结及注意事项
-
分区表是一种优化表,主要是提高查询效率,减少全表扫描。
-
分区的字段不能是表中已有的字段?为什么 分区字段也会作为结果显示查询内容上,不能重复。
-
分区字段是虚拟的字段,其内容不是来自于底层文件的映射,来自于加载数据时指定。
-
分区表底层形式就是在表的文件夹下面继续创建子文件,子文件的名字就是分区字段和分区值组合
#非分区表 /user/hive/warehouse/itcast.db/t_user china.txt japan.txt usa.txt #分区表 /user/hive/warehouse/itcast.db/t_user_part /guojia=zhongguo china.txt /guojia=riben japan.txt /guojia=meiguo usa.txt -
企业中常见的分区字段
-
时间维度 年 月 天
-
地域维度 省 市
-
-
-
多重分区表
-
Hive支持在多个分区字段,也就是所谓多重分区表,常见的是2分区表。
-
多分区的意思是指在前一个分区的基础上继续分区
-
底层来看就是文件夹下面继续创建子文件
--创建2分区表 create table t_user_double_part(id int,name string,country string) partitioned by(guojia string,sheng string) row format delimited fields terminated by ','; --load load data local inpath '/root/hivedata/china_sh.txt' into table t_user_double_part partition(guojia="zhongguo",sheng="shanghai"); load data local inpath '/root/hivedata/china_bj.txt' into table t_user_double_part partition(guojia="zhongguo",sheng="beijing"); load data local inpath '/root/hivedata/usa_dz.txt' into table t_user_double_part partition(guojia="meiguo",sheng="dezhou"); --查询 select * from t_user_double_part where guojia ="zhongguo"; select * from t_user_double_part where guojia ="zhongguo" and sheng ="shanghai";
-
-
-
分桶表
-
语法上剖析
[clustered by (col_name, col_name, ...) [sorted by (col_name [asc|desc], ...)] into num_buckets buckets] --精简 clustered by xxx into N buckets clustered by xxx 根据xxx分在一起 into N buckets 分为几桶 --通俗解释:根据xxx字段把表的数据分为N个部分。 t_user(id,name,country) 根据谁分? clustered by xxx xxx就是分的字段 分为几个部分?into N buckets N 如何分? --如果分桶的字段xxx是数值类型字段, xxx % N 余数相同的到一起 --如果分桶的字段xxx是字符串或者其他类型 xxx.hash % N 余数相同的到一起 --如果有需求 还可以知道每个分桶内排序规则 sorted by (col_name [asc|desc]) -
分桶表创建
create table stu_buck(Sno int,Sname string,Sex string,Sage int,Sdept string) clustered by(Sno) into 4 buckets row format delimited fields terminated by ',';
-
分桶表加载数据
--如何判断分桶表的数据加载成功 1、正确解析显示数据 2、底层文件分成N个部分 --直接hadoop fs-put 和load加载都是不可以的 --分桶表采用insert+select 间接的方式才能加载数据 --step1:创建一个普通的表 并加载数据到普通表中 create table student(Sno int,Sname string,Sex string,Sage int,Sdept string) row format delimited fields terminated by ','; --step2: 开启分桶功能 set hive.enforce.bucketing = true; --注意这个参数 hive.enforce.bucketing Default Value: Hive 0.x: false Hive 1.x: false Hive 2.x: removed, which effectively makes it always true (HIVE-12331) Added In: Hive 0.6.0 --step3: 把数据从普通表中查询出来插入到分桶表中 insert into table stu_buck select * from student; -
分桶表使用
-
和正常表一样使用,底层查询时hive自动优化。
-
-
分桶表总结及注意事项
-
分桶表也是一种优化手段表,主要提高join查询时候效率,减少笛卡尔积数量;
-
此外还可以方便抽样查询。
-
分桶表的字段必须是表中已有字段。
-
-
-
HQL DDL 数据定义语言
-
修改表
-
修改表的属性信息
-
修改表的分区属性信息
-
修改表的字段
-
-
语法核心关键字:alter
-
注意:在Hive中,修改表的操作使用不多,可以使用drop+create 替代。为什么?
#mysql中不这么干? create table--->insert values #意味着mysql加载数据的成本极高。 #hive中为什么可以? create table--->映射已经存在的文件(外部表保护文件) # 删除再创建的成本极低
-
栗子
--增加分区 先有分区文件 补充元数据 ALTER TABLE t_user_part ADD PARTITION (guojia='yingguo') location '/user/hive/warehouse/itcast.db/t_user_part/guojia=yingguo'; --删除分区 ALTER TABLE t_user_part DROP IF EXISTS PARTITION (guojia='yingguo'); --修改分区 重命名分区 ALTER TABLE t_user_part PARTITION (guojia='yingguo') RENAME TO PARTITION (guojia='dydg'); --列操作 ALTER TABLE table_name ADD|REPLACE COLUMNS (col_name STRING); --注:ADD 是代表新增一个字段,新增字段位置在所有列后面(partition 列前) --REPLACE 则是表示替换表中所有字段。 ALTER TABLE table_name RENAME TO new_table_name
show场景语法
--1、显示所有数据库 SCHEMAS和DATABASES的用法 功能一样 show databases; show schemas; --2、显示当前数据库所有表 show tables; SHOW TABLES [IN database_name]; --指定某个数据库 --3、显示表分区信息,分区按字母顺序列出,不是分区表执行该语句会报错 show partitions table_name; --4、显示表/分区的扩展信息 SHOW TABLE EXTENDED [IN|FROM database_name] LIKE table_name; show table extended like student; describe formatted itheima.student; --5、显示表的属性信息 show tblproperties student; --6、显示表建表语句 show create table student; --9、显示表中的所有列,包括分区列。 SHOW COLUMNS (FROM|IN) table_name [(FROM|IN) db_name]; show columns in student; --10、显示当前支持的所有自定义和内置的函数 show functions; --11、Describe desc --查看表信息 desc extended table_name; --查看表信息(格式化美观) desc formatted table_name; --查看数据库相关信息 describe database database_name;
#探究
1、hive做了什么
将结构化文件映射成为一张表 记录着映射信息(元数据)
2、MySQL中存储的是什么数据
存储着映射信息 元数据
3、HDFS中存储的是什么数据
存储的是结构化文件 表的真实的数据
#查看表的元数据信息 hive记录了这个表哪些信息
desc formatted student;
2、HQL DML 数据操纵语言
-
load
-
功能:加载操作是将数据文件移动到与 Hive表对应的位置的纯复制/移动操作。
-
语法
LOAD DATA [LOCAL] INPATH 'filepath' [OVERWRITE] INTO TABLE tablename [PARTITION (partcol1=val1, partcol2=val2 ...)]
-
核心关键字--local
-
有local 表示从本地文件系统加载到hive表中
-
没有local 表示从hdfs文件系统加载到hive表中
-
-
究竟哪个本地是本地文件系统。
-
栗子
create table student_from_local(Sno int,Sname string,Sex string,Sage int,Sdept string) row format delimited fields terminated by ','; create table student_from_hdfs(Sno int,Sname string,Sex string,Sage int,Sdept string) row format delimited fields terminated by ','; --1、从本地加载数据到student_from_local load data local inpath '/root/hivedata/students.txt' into table student_from_local; --从本地加载的时候 是一个数据复制操作 --底层的本质就是 hadoop fs -put --2、从HDFS加载数据到student_from_hdfs load data inpath '/stu/students.txt' into table student_from_hdfs; --从hdfs加载的时候 是一个数据移动操作 --底层的本质就是 hadoop fs -mv -
结论:官方推荐使用load命令加载数据到Hive表中。实际上无论什么方式,只有把文件放置在表的目录下就可以。

-
-
insert插入数据
-
回顾
mysql: insert into table values(1,"zhangsan"); --insert +values语法在hive中能否使用。 create table t_insert(id int,name string); insert into table t_insert values(1,"allen"); --语法可以在hive使用 但是效率较低。 推荐使用load加载数据方式。
-
insert在hive中如何
-
语法:insert+select
-
功能:把后面查询返回的结果作为内容插入到表中 也是ETL中常见的操作。
-
注意:查询返回结果的字段类型、顺序、含义、个数要和待插入表一致。
-
栗子
create table t_insert_1(name string); insert into t_insert_1 select name from t_insert; --如何插入的表是分区表 还需要指定分区值 insert into t_insert_1 partition() select name from t_insert;
-
-
开启智能本地模式
SET hive.exec.mode.local.auto=true;
-
Multi Inserts 多重插入 多次插入
-
一次扫描,多次插入 减少全表扫描的次数
from source_table insert overwrite table test_insert1 select id insert overwrite table test_insert2 select name;
-
-
Dynamic partition inserts 动态分区插入
-
探讨
--动态分区、静态分区 --研究的是:分区表的分区值是如何决定的? load data local inpath '/root/hivedata/usa.txt' into table t_user_part partition(guojia="meiguo"); usa.txt--->meiguo --sql中写死的 静态分区 insert +seletc --根据查询结果动态确定的分区 动态分区

-
栗子
--step1: 开启动态分区功能 设定动态分区的执行模式 set hive.exec.dynamic.partition=true; #是否开启动态分区功能,默认false关闭。 set hive.exec.dynamic.partition.mode=nonstrict; #动态分区的模式,默认strict,表示必须指定至少一个分区为静态分区,nonstrict模式表示允许所有的分区字段都可以使用动态分区。 Error: Error while compiling statement: FAILED: SemanticException [Error 10096]: Dynamic partition strict mode requires at least one static partition column. To turn this off set hive.exec.dynamic.partition.mode=nonstrict (state=42000,code=10096) --理解严格 非严格模式 insert into table d_p_t partition(month="2015-05",day) select ip,day from dynamic_partition_table; --严格模式 insert into table d_p_t partition(month,day) --非严格模式 select ip,month,day from dynamic_partition_table; --step2:执行动态分区 insert overwrite table d_p_t partition (month,day) select ip,substr(day,1,7) as month,day from dynamic_partition_table;
-
-
导出数据操作
-
语法
INSERT OVERWRITE [LOCAL] DIRECTORY directory1 SELECT ... FROM ...;
-
注意事项
-
local表示把数据导出到HS2所在机器的本地文件系统 否则就导出到HDFS.
-
OVERWRITE表示把目录下的数据给覆盖。
-
默认导出的数据以\\001作为字段分隔符 也可以指定分隔符。
-
-
栗子
INSERT OVERWRITE LOCAL DIRECTORY '/tmp/aaa' SELECT * FROM student; INSERT OVERWRITE DIRECTORY '/aaa' SELECT * FROM student;
-
-
3、HQL DQL 数据查询语言
-
完整语法树
[WITH CommonTableExpression (, CommonTableExpression)*] SELECT [ALL | DISTINCT] select_expr, select_expr, ... FROM table_reference [WHERE where_condition] [GROUP BY col_list] [ORDER BY col_list] [CLUSTER BY col_list | [DISTRIBUTE BY col_list] [SORT BY col_list] ] [LIMIT [offset,] rows];
-
CLUSTER BY 分桶查询
-
功能:根据指定的字段把数据分成若干部分,每个部分中再根据这个字段进行排序,只能正序
-
概况:根据字段 分且排序动作。
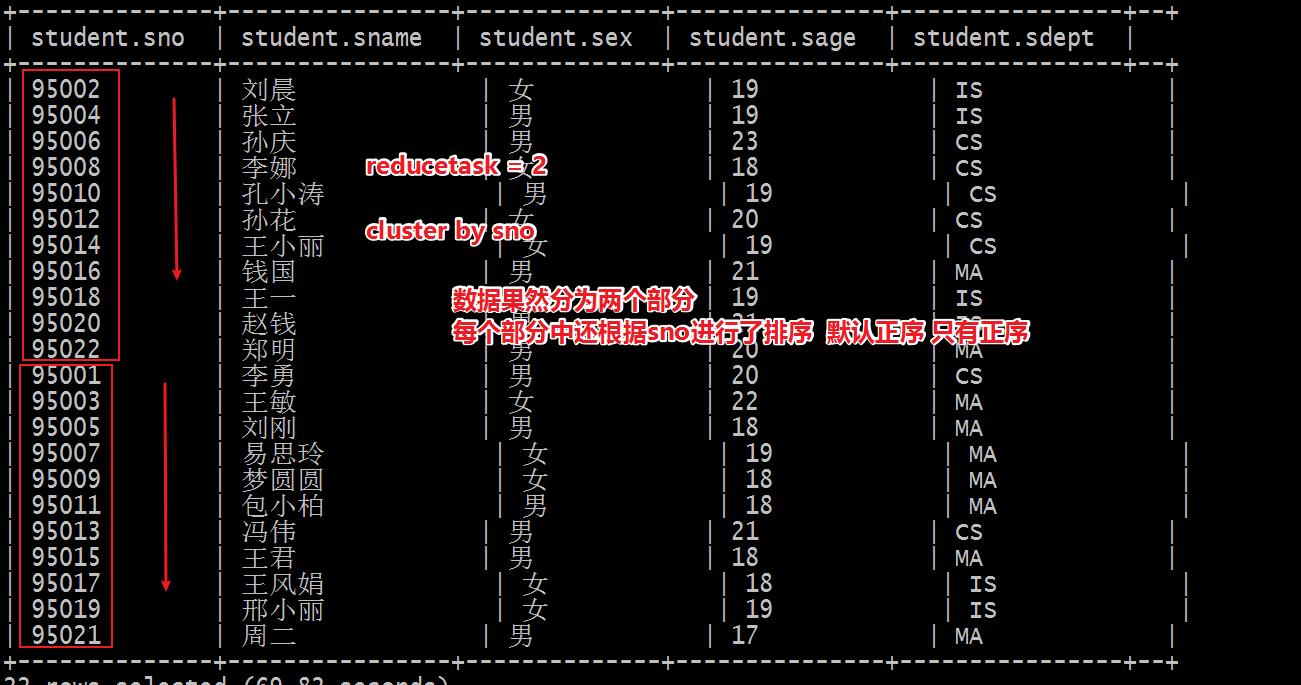
0: jdbc:hive2://node1:10000> select * from student; +--------------+----------------+--------------+---------------+----------------+--+ | student.sno | student.sname | student.sex | student.sage | student.sdept | +--------------+----------------+--------------+---------------+----------------+--+ --1、根据谁分 CLUSTER BY xxx --2、分成几个部分 取决于底层reducetask的个数 个数如何决定的呢? 如果用户不设置 自己根据数据量大小自动评估 如果用户手动设置 就以设置的为准 --3、如何分 规则和分桶表的规则一模一样 select * from student cluster by sno; ---默认情况下 根据输入数据量来自动评估reducetask个数 Number of reduce tasks not specified. Estimated from input data size: 1 --手动设置reducetask个数 set mapreduce.job.reduces =2; Number of reduce tasks not specified. Defaulting to jobconf value of: 2 set mapreduce.job.reduces =3; Number of reduce tasks not specified. Defaulting to jobconf value of: 3 --需求:根据sno分为2个部分 每个部分中根据sage 倒序排序 set mapreduce.job.reduces =2; select * from student cluster by sno sort by sage desc; Error: Error while compiling statement: FAILED: SemanticException 1:45 Cannot have both CLUSTER BY and SORT BY clauses. Error encountered near token 'sage' (state=42000,code=40000) -
-
DISTRIBUTE BY + SORT BY
-
功能:DISTRIBUTE BY 只负责分 SORT BY只负责排序 两个字段还可以不一样。
-
如果字段一样的话:CLUSTER BY(分且排序)= DISTRIBUTE BY(分) +SORT BY(排序)
set mapreduce.job.reduces =2; select * from student distribute by sno sort by sage desc;
-
-
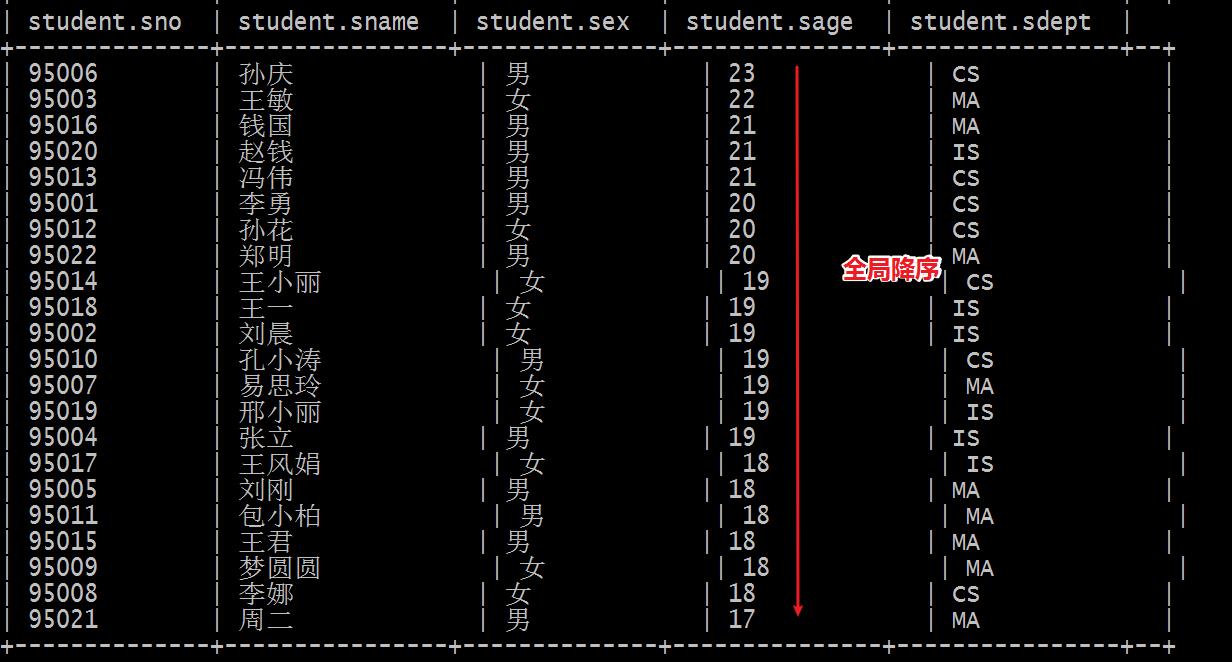
ORDER BY 全局排序
-
如何理解全局二字? 全局意味着所有的数据都必须在一个文件中,意味着底层只能有一个reducetask.
-
为了满足order by全局的实现,在编译期间hive会强制将reducetask个数设置为1。
set mapreduce.job.reduces =4; select * from student order by sage desc; --在编译期间 hive把个数设置为1 用户设置的不生效 Number of reduce tasks determined at compile time: 1
-
order by 、sort by
-
sort by是在数据进行完拆分,每个部分内部排序 局部排序
-
order by是全局数据排序 不会对数据拆分 数据在一起的 完整 全局!!!
-
-
-
-
union联合查询
-
功能:将多个select查询返回的结果集合并为一个结果集。
-
语法:
select_statement UNION [ALL | DISTINCT] select_statement UNION [ALL | DISTINCT] select_statement ...; --1、union= union distinct 结果集去重 --2、union all 结果集不去重
-
栗子
select sno,sname from student_from_local UNION select sno,sname from student_from_hdfs; --和上面一样 select sno,sname from student_from_local UNION DISTINCT select sno,sname from student_from_hdfs; --使用ALL关键字会保留重复行。 select sno,sname from student_from_local UNION ALL select sno,sname from student_from_hdfs limit 2;
-
注意事项
-
如果想针对某一条select结果进行条件控制 使用嵌套子查询包裹;
-
如果把条件控制写在最后一个select后,对整个union之后的结果集进行操作。
-
-
-
Common Table Expressions(CTE)
-
以with关键字引导的一个子查询 其命令可以在后续的查询中多次使用。
-
语法糖。
--select语句中的CTE with q1 as (select sno,sname,sage from student where sno = 95002) select * from q1; --嵌套子查询语法 select * from (select sno,sname,sage from student where sno = 95002) as q1; -- from风格 with q1 as (select sno,sname,sage from student where sno = 95002) from q1 select *; -- chaining CTEs 链式 with q1 as ( select * from student where sno = 95002), q2 as ( select sno,sname,sage from q1) select * from (select sno from q2) a;
-
-
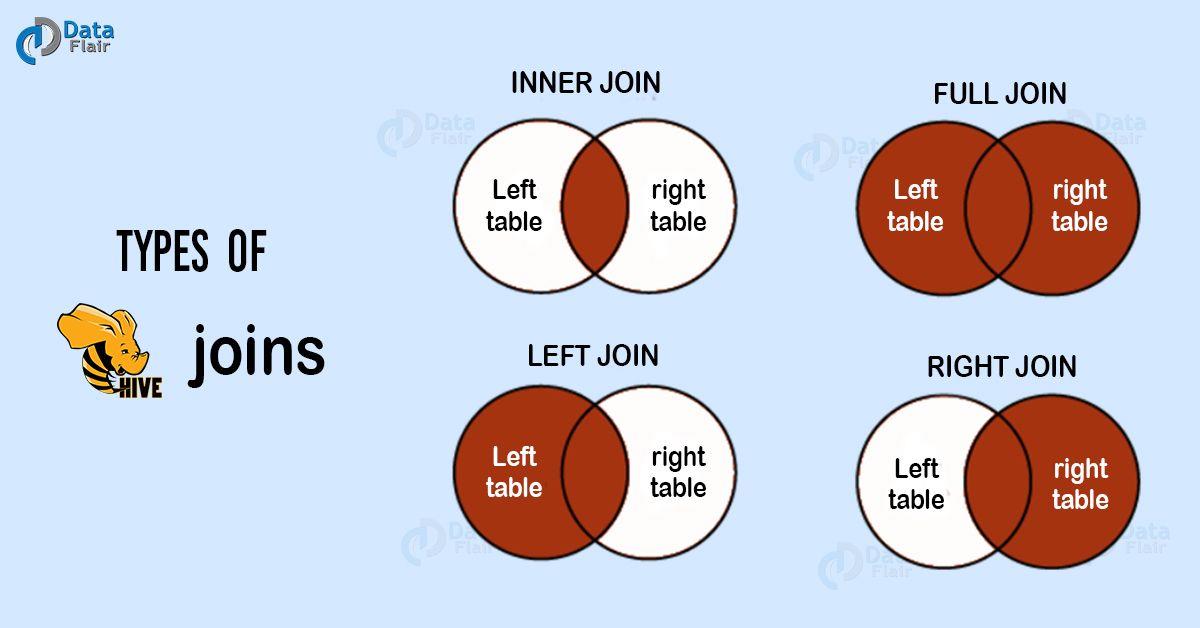
Hive join
-
-
-
产生背景
#现实中 不会把所有的数据都存储在一张表中 而是根据业务 应用分别存储。 #在某些查询的需求中 又需要基于多张表共同查询返回结果 需要join关联查询。
-
6种join语法
join_table: table_reference [INNER] JOIN table_factor [join_condition] | table_reference LEFT|RIGHT|FULL [OUTER] JOIN table_reference join_condition | table_reference LEFT SEMI JOIN table_reference join_condition | table_reference CROSS JOIN table_reference [join_condition] (as of Hive 0.10)
-
inner join
inner join == join 默认就是内连接 --左右两边都满足的返回
-
outer join
full outer join == outer join 全外连接 外连接
-
left join
以左表为准,显示左表的所有内容 右表与之关联 关联上的显示 关联不上的显示null
-
right join
与left join相反
-
left semi join
左半开连接 == 效果等于内关联只显示左表的部分 select * from a left semi join b on a.id = b.id; +-------+--------- | a.id | a.name +-------+--------- | 2 | b | 3 | c | 7 | y +-------+--------- select a.* from a inner join b on a.id=b.id; +-------+--------- | a.id | a.name +-------+--------- | 2 | b | 3 | c | 7 | y +-------+---------
-
cross join(#慎用)
--笛卡尔积join 交叉相差 往往不带on条件 --级联求和 级联累加 自己和自己join可以解决 --更好的方式 sum + windows function
-
-
注意事项
-
Hive 支持等值连接(a.id = b.id),不支持非等值(a.id>b.id)的连接。
select * from a join b on a.id = b.id; select * from a join b on a.id > b.id; --当下hive 2.1.0不支持。
-
-
难点
-
join的优化
-
map端join
-
reduce端join(common join)
-
bucket join
-
大小表join
-
大表join 空值处理问题
-
-
如何根据业务需求写join语句
-
-
4、Hive shell命令行 参数配置
-
shell命令行
-
位置:bin/hive
-
功能1:启动hive的相关服务
/export/server/hive/bin/hive --service hiveserver2|metastore
-
功能2:作为第一代客户端访问metastore服务
-
功能3:执行HQL脚本
#执行后面指定的sql /export/server/hive/bin/hive -e 'select sno from itcast.student limit 3' #执行后面指定的sql文件 vim xxx.sql $HIVE_HOME/bin/hive -f /home/my/hive-script.sql $HIVE_HOME/bin/hive -f hdfs://<namenode>:<port>/hive-script.sql #sql文件后缀名 见名知意 通常以.sql结尾 可以任意后缀名 保证里面内容sql语法正确即可。
-
-
Hive参数配置及方式
-
配置参数在哪里
https://cwiki.apache.org/confluence/display/Hive/Configuration+Properties
-
如何配置参数
-
方式1:hive-site.xml中 覆盖default。
影响的是这个安装包的任何一种使用方式。 不管是启动服务 还是基于本安装包启动客户端 都会加载该文件。
-
方式2:--hiveconf
/export/server/hive/bin/hive --service metastore /export/server/hive/bin/hive --service metastore --hiveconf hive.root.logger=DEBUG,console 影响的服务的生命周期 客户端的生命周期
-
方式3:使用set命令
set hive.exec.dynamic.partition=true; #是否开启动态分区功能,默认false关闭。 set hive.exec.dynamic.partition.mode=nonstrict; 影响的客户端和服务之间的session会话 session结束 设置参数失效 恢复默认值
-
-
企业开发中,推荐使用set命令
谁需要 谁设置 谁生效 影响其他人使用。
-
优先级:set命令最高
-
Hive作为基于Hadoop的软件 还会把Hadoop的配置文件加载进来 作为自己的配置的一部分。
-
以上是关于hadoop离线day09--Apache Hive的主要内容,如果未能解决你的问题,请参考以下文章