Python-Scrapy库的安装与使用
Posted 热绪
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python-Scrapy库的安装与使用相关的知识,希望对你有一定的参考价值。
Python-Scrapy库的安装与使用
安装scrapy
在Linux下安装scrapy:
sudo apt install python3 python3-dev
sudo apt install python3-pip
pip3 install scrapy
测试安装是否成功:import scrapy
在命令行终端输入:scrapy 查看相关信息
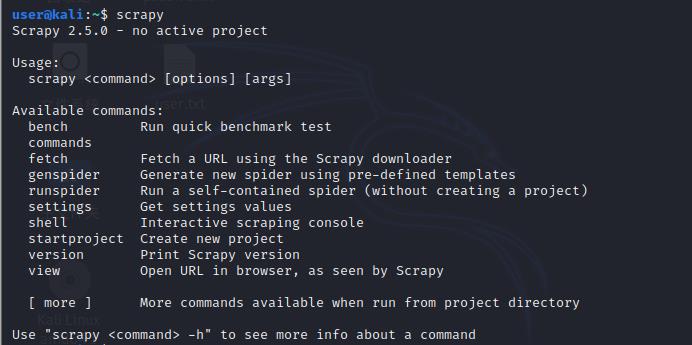
创建工程
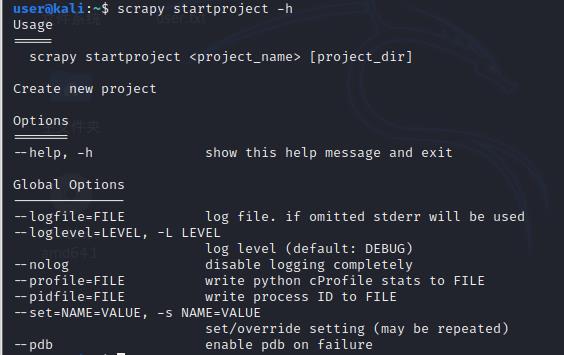
scrapy startproject [工程名] 创建工程
scrapy startproject -h 查看帮助信息
使用scrapy startproject test1 创建测试用例(默认位置就是当前位置)

根据提示,进入相关目录。

工程文件作用:
scrapy.cfg 工程部署文件
items.py 设置要爬取的字段
pipelines.py 设置保存爬取内容
settings.py 设置文件,比如User-Agent
spiders 目录 :保存生成的爬虫文件

测试
我们切换到test1目录下,按照样例进行测试

再次访问spiders目录发现生成了爬虫文件

我们使用cat查看example.py文件
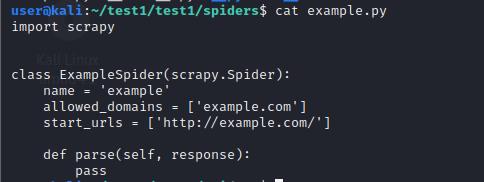
这段代码即是对example.com进行爬取的爬虫的基本框架。
以上是关于Python-Scrapy库的安装与使用的主要内容,如果未能解决你的问题,请参考以下文章