pytho爬虫之requests的使用
Posted lweiser
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了pytho爬虫之requests的使用相关的知识,希望对你有一定的参考价值。
一、requests库的安装
(1)、pip3 install requests
(2)、在pycharm中进行安装
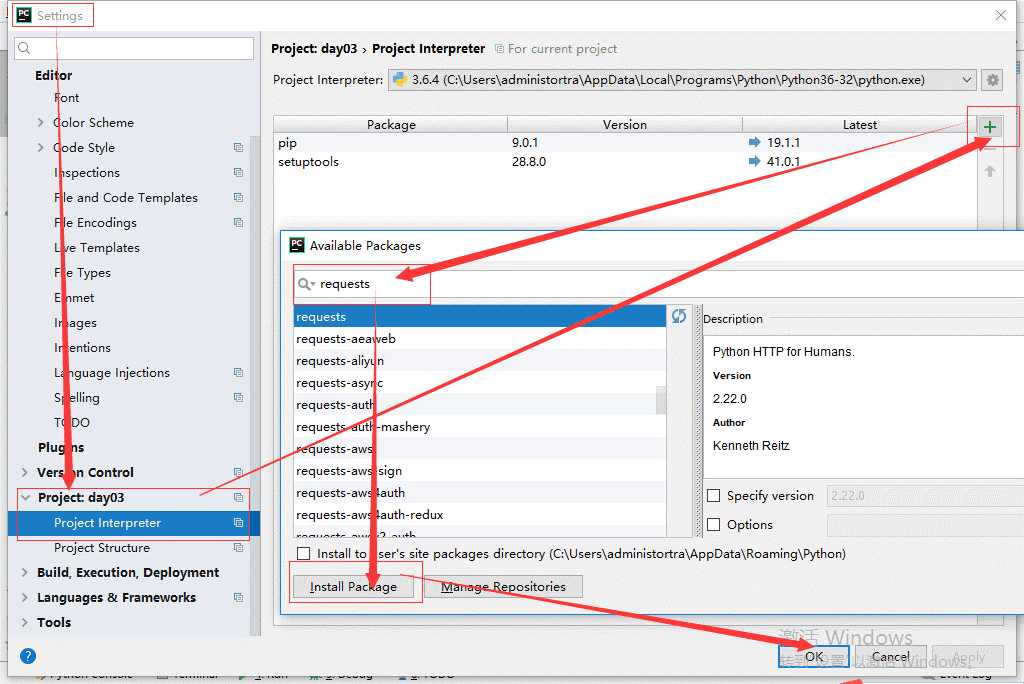
二、基于HTTP协议的requests的请求机制
1、http协议:(以请求百度为例)
(1)请求url:
https://www.baidu.com/
(2)请求方式:
GET
(3)请求头:
Cookie: 可能需要关注。
User-Agent: 用来证明你是浏览器
注意: 去浏览器的request headers中查找
Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (Khtml, like Gecko) Chrome/65.0.3325.146 Safari/537.36
Host: www.baidu.com
2、浏览器的使用
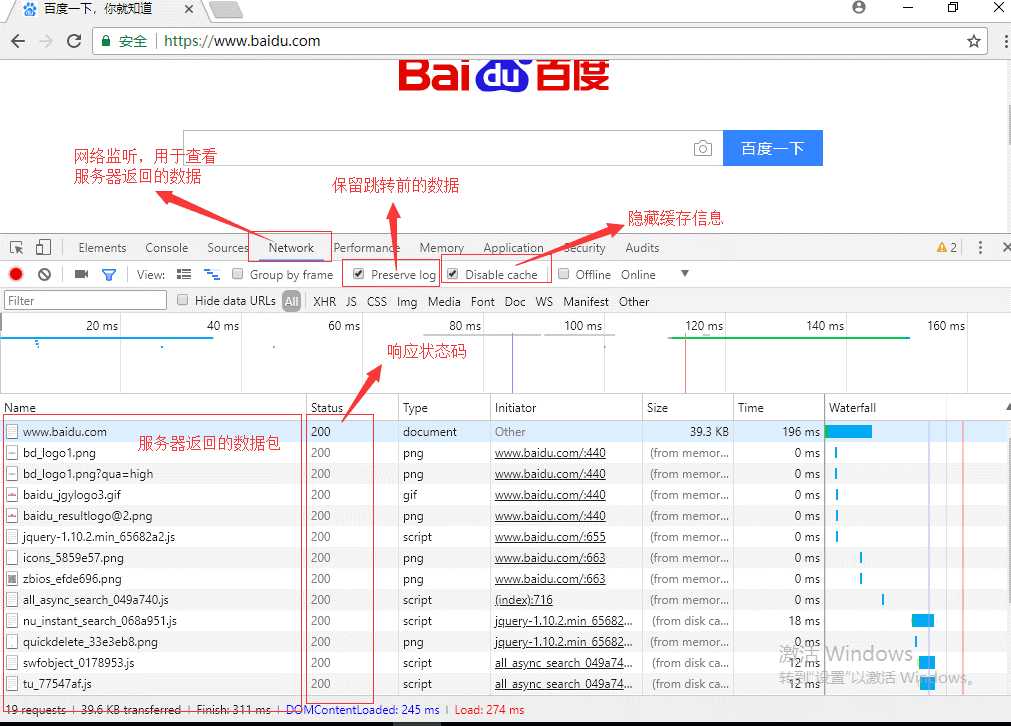
3、爬取百度主页
1 import requests 2 3 response = requests.get(url=‘https://www.baidu.com/‘) 4 response.encoding = ‘utf-8‘ 5 print(response) # <Response [200]> 6 # 返回响应状态码 7 print(response.status_code) # 200 8 # 返回响应文本 9 # print(response.text) 10 print(type(response.text)) # <class ‘str‘> 11 #将爬取的内容写入xxx.html文件 12 with open(‘baidu.html‘, ‘w‘, encoding=‘utf-8‘) as f: 13 f.write(response.text)
三、爬取“梨视频”中的视频
1 # 爬取梨视频 2 import requests 3 url=‘https://video.pearvideo.com/mp4/adshort/20190613/cont-1565846-14013215_adpkg-ad_hd.mp4‘ 4 res = requests.get(url) 5 #将爬取的视频写入文件 6 with open(‘梨视频.mp4‘, ‘wb‘) as f: 7 f.write(res.content)
以上是关于pytho爬虫之requests的使用的主要内容,如果未能解决你的问题,请参考以下文章