ElasticSearch学习笔记
Posted new一个对象777
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了ElasticSearch学习笔记相关的知识,希望对你有一定的参考价值。
ElasticSearch学习
Lucene概念
Lucene是apache软件基金会 jakarta项目组的一个子项目,是一个开放源代码的全文检索引擎工具包,但它不是一个完整的全文检索引擎,而是一个全文检索引擎的架构,提供了完整的查询引擎和索引引擎,部分文本分析引擎(英文与德文两种西方语言)。Lucene的目的是为软件开发人员提供一个简单易用的工具包,以方便的在目标系统中实现全文检索的功能,或者是以此为基础建立起完整的全文检索引擎。Lucene是一套用于全文检索和搜寻的开源程式库,由Apache软件基金会支持和提供。Lucene提供了一个简单却强大的应用程式接口,能够做全文索引和搜寻。在Java开发环境里Lucene是一个成熟的免费开源工具。就其本身而言,Lucene是当前以及最近几年最受欢迎的免费Java信息检索程序库。人们经常提到信息检索程序库,虽然与搜索引擎有关,但不应该将信息检索程序库与搜索引擎相混淆。
大数据就两个问题:存储 + 计算!
Lucene是一套信息检索工具包,jar包,不包含搜索引擎。
包含的:索引结构,读写索引的工具,排序,搜索规则,工具类等。
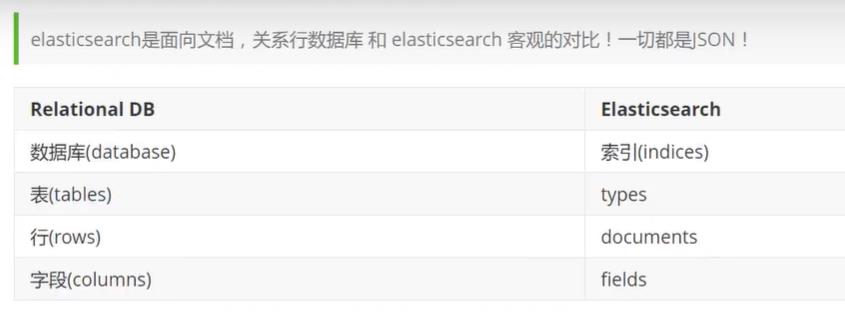
Lucene是一套信息检索工具包,并不包含搜索引擎系统,它包含了索引结构、读写索引工具、相关性工具、排序等功能,因此在使用Lucene时仍需要关注搜索引擎系统,例如数据获取、解析、分词等方面的东西。而solr和elasticsearch都是基于该工具包做的一些封装。
Lucene 和 ElasticSearch关系:
ElasticSearch是基于Lucene做了一些封装和增强。
solr利用zookpper进行分布式管理,而elasticsearch自身带有分布式协调管理功能;
solr比elasticsearch实现更加全面,solr官方提供的功能更多,而elasticsearch本身更注 重于核心功能,高级功能多由第三方插件提供;
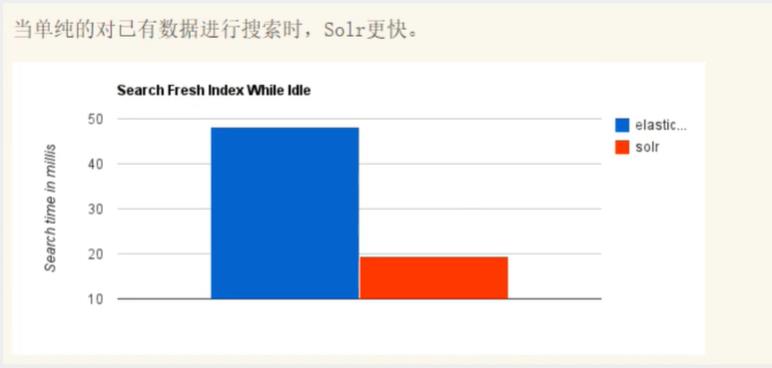
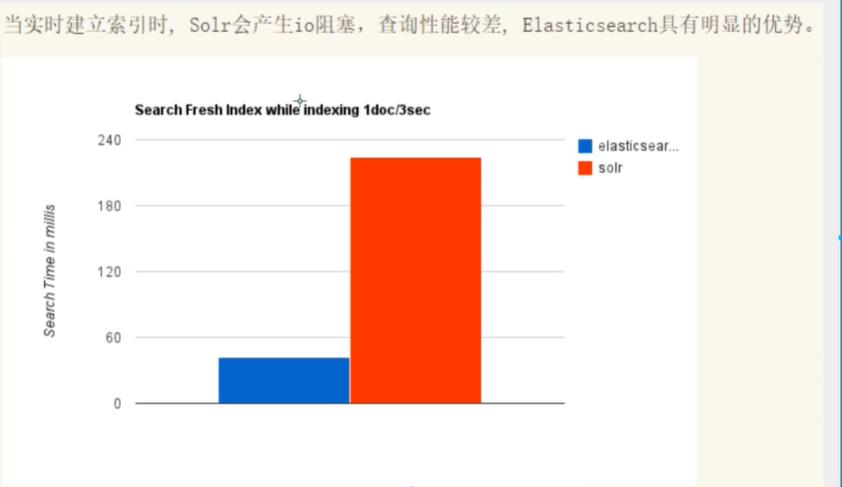
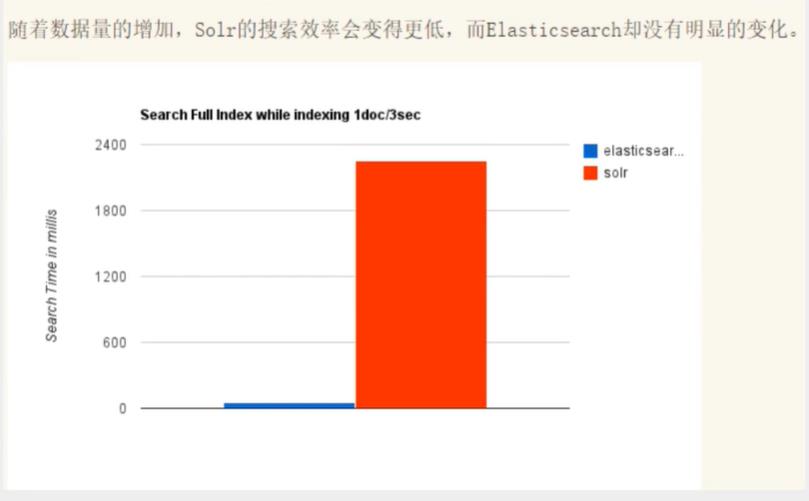
solr在传统的搜索应用中表现好于elasticsearch,而elasticsearch在实时搜索应用方面比solr表现好!
ElasticSearch概念
Elasticsearch是一个基于Lucene的搜索服务器。它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。Elasticsearch是用Java语言开发的,并作为Apache许可条款下的开放源码发布,是一种流行的企业级搜索引擎。Elasticsearch用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便。官方客户端在Java、.NET(C#)、php、Python、Apache Groovy、Ruby和许多其他语言中都是可用的。根据DB-Engines的排名显示,Elasticsearch是最受欢迎的企业搜索引擎,其次是Apache Solr,也是基于Lucene。
用于全文搜索,结构化搜索,分析。
Solr和ElasticSearch的区别

安装ElasticSearch
官网下载 :https://www.elastic.co/cn/downloads/elasticsearch 速度超级慢 建议去中文社区下载
运行
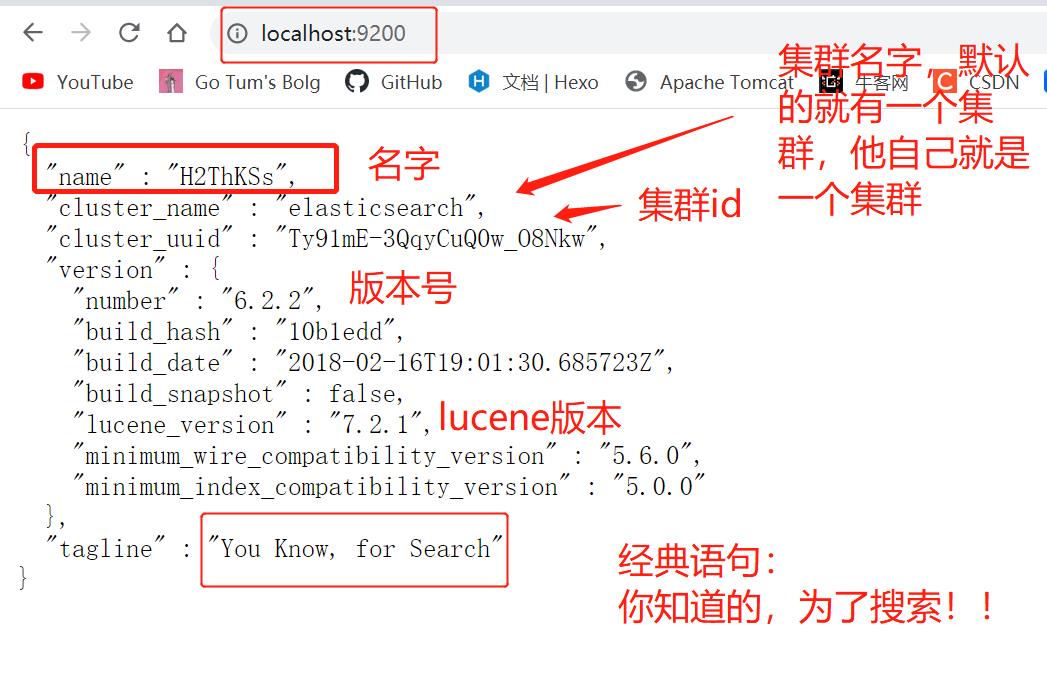
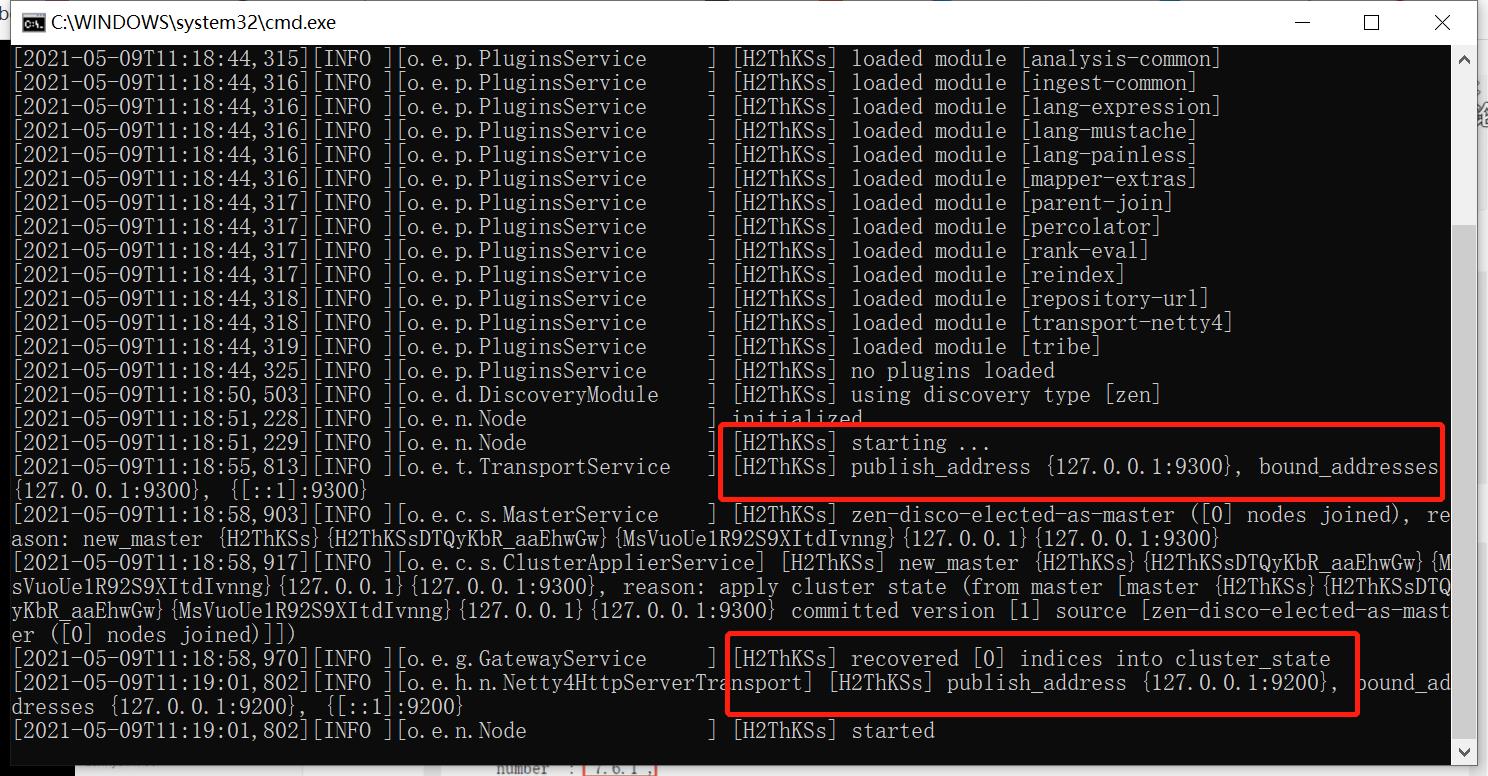
解压之后在bin目录里面打开elasticsearch.bat运行,然后在浏览器输入localhost:9200可以看到成功界面:
可视化界面
下载地址: https://github.com/mobz/elasticsearch-head
前提是有node和npm环境!!
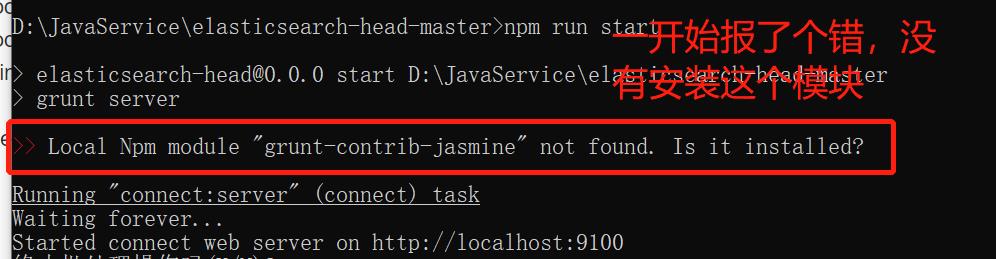
安装皆可:npm install grunt-contrib-jasmine --registry=https://registry.npm.taobao.org
安装完成之后再运行就不会报错了:
启动:
npm install
npm run start

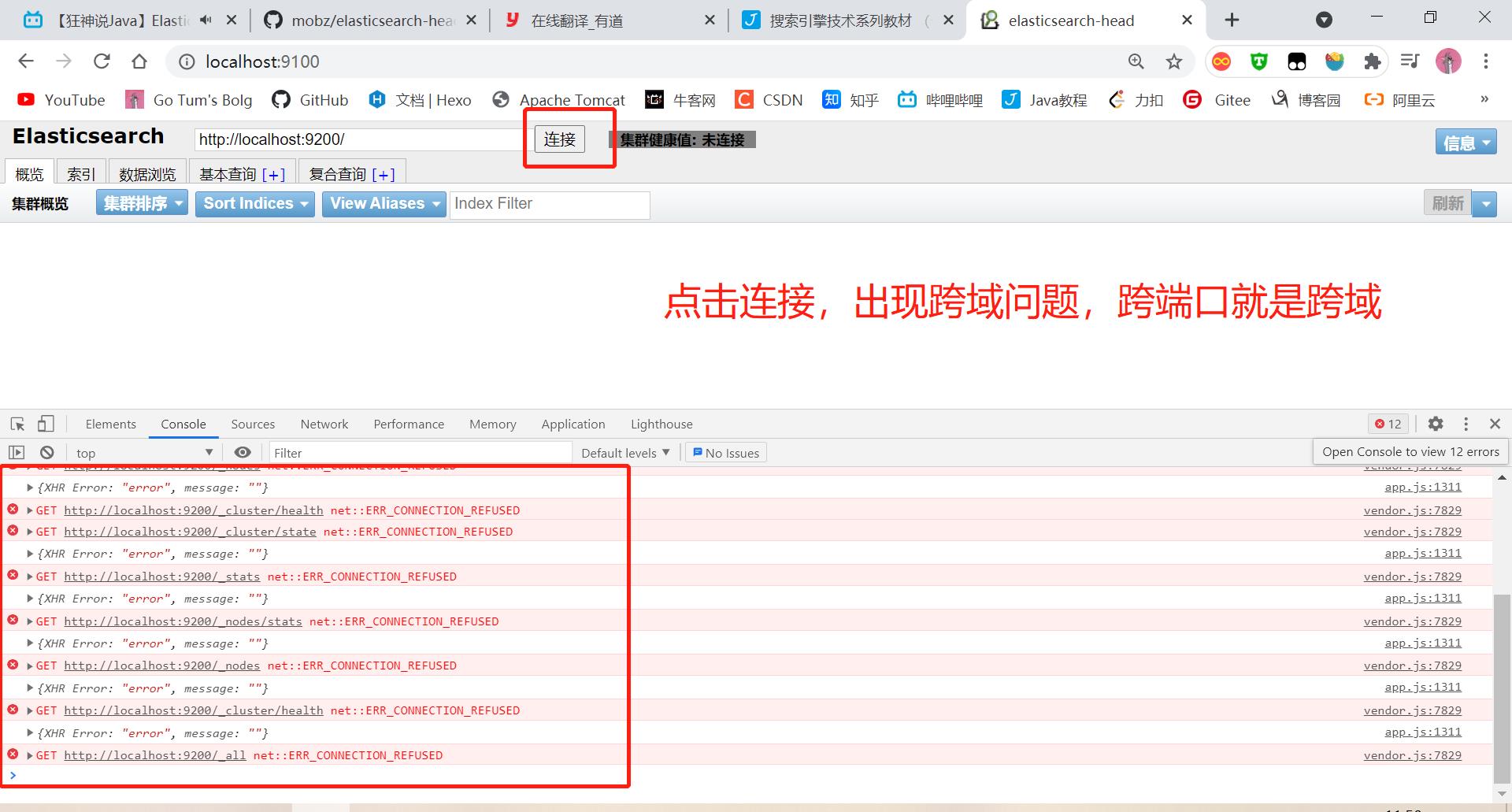
如何解决跨域问题
在elasticsearch的配置文件中
elasticsreach.yml中添加两行参数,如下,重启elasticsearch解决跨域问题
http.cors.enabled: true
http.cors.allow-origin: "*"

创建索引:
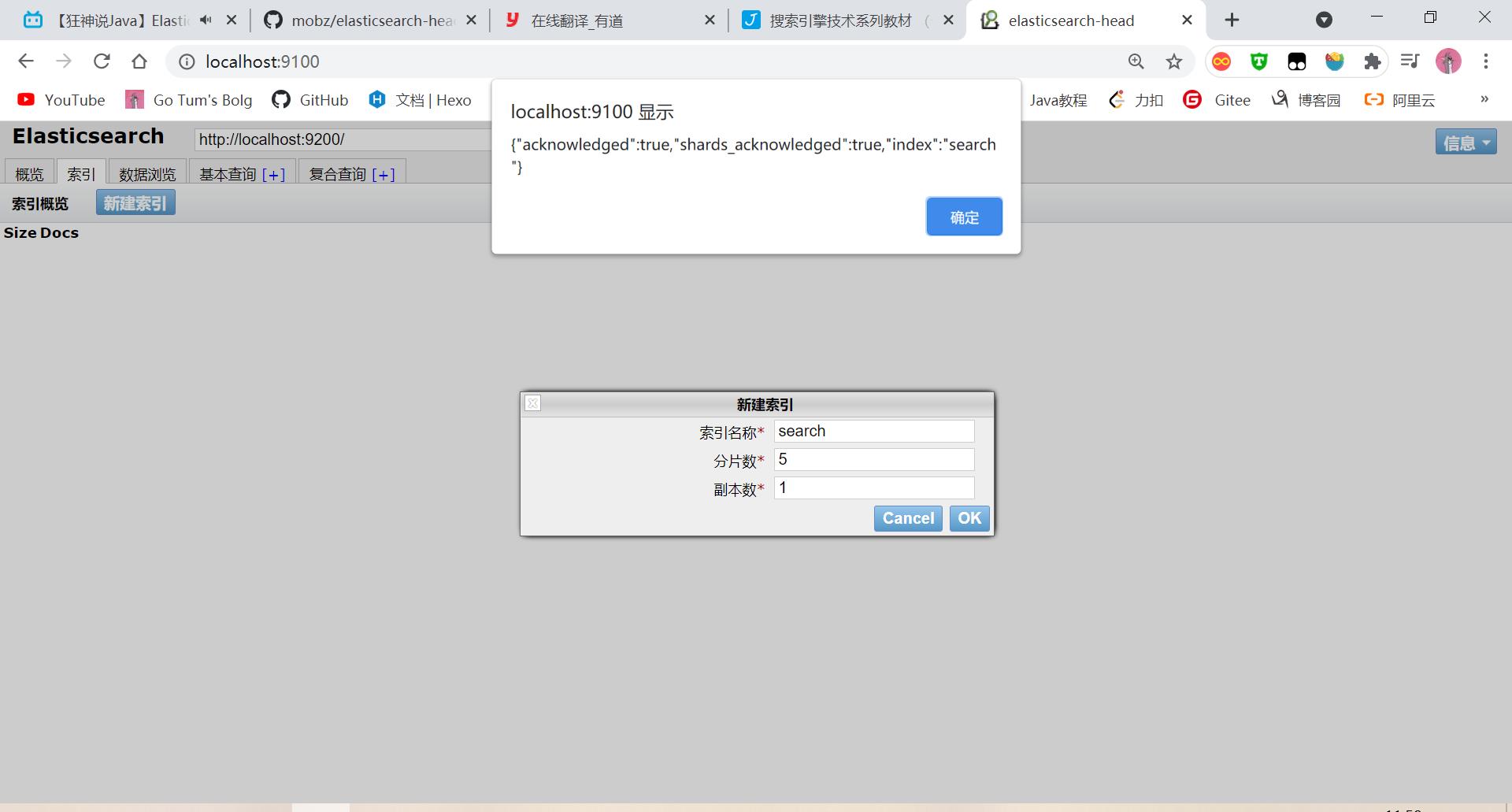
这个head可视化工具我们就当做一个数据展示工具,我们后面所以的查询操作都会在kibana中进行
安装Kibana 要和elasticsearch版本一致

下载解压:
解压后的目录:
启动 启动前提:elasticsearch必须开启, 因为有package.json文件 所以这是一个前端项目
旧版本:
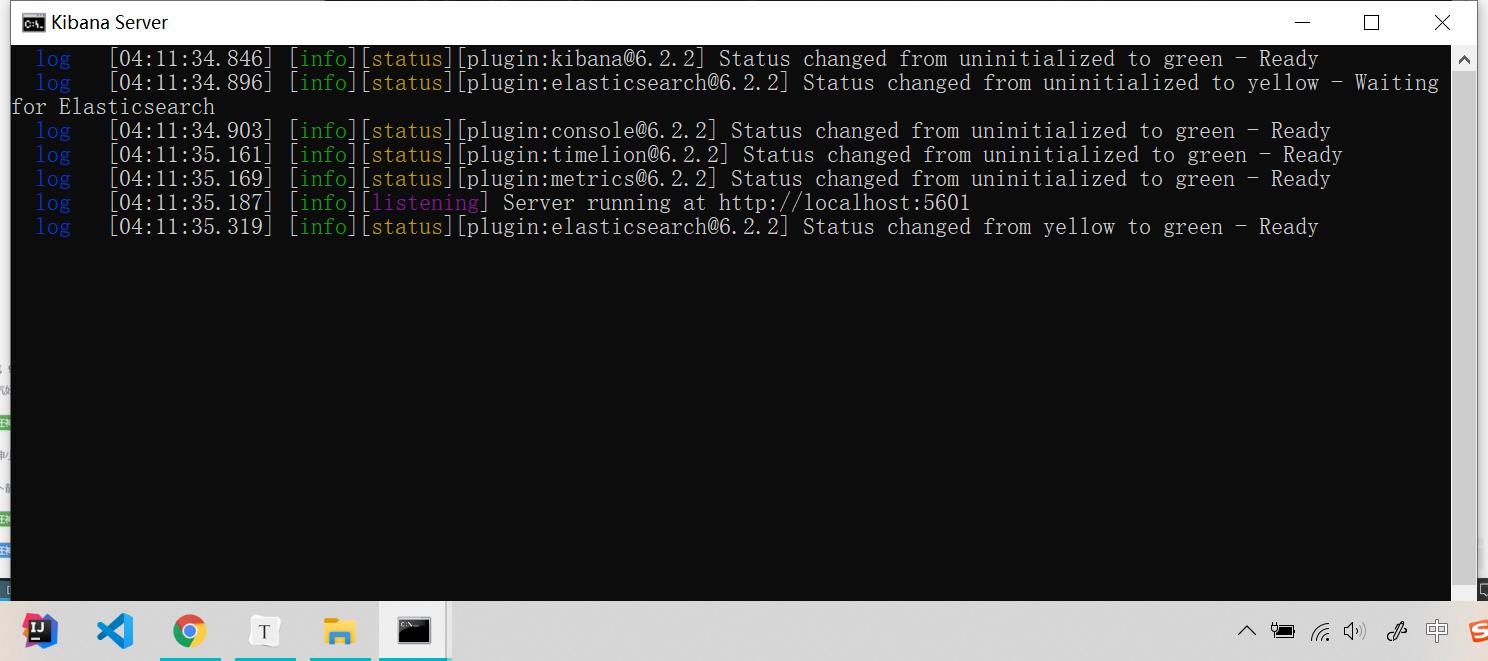
新版本:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Rkm7Lu7X-1620805263832)(D:\\Markdown\\image-20210509151039427.png)]](https://image.cha138.com/20210517/cd5db00b7c9240bf9a284a976348a0b5.jpg)
访问端口:localhost:5601
之后所有的操作都在这里面进行

汉化,我们这个包里面有定义好的国际化,直接拿来用就可以了
D:\\JavaService\\kibana-7.10.0-windows-x86_64\\x-pack\\plugins\\translations\\translations\\zh-CN.json
然后在配置文件中更改一下参数就可以了:i18n.locale: “zh-CN”
ES核心概念
索引
字段的类型 mapping
文档即记录
分片–倒排索引

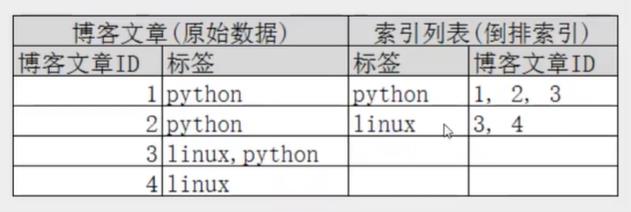
IK分词器插件
使用中文就用IK分词器,这个版本还是要一致。
将下载的包解压到插件目录下就可以了。
重新启动之后可以看到
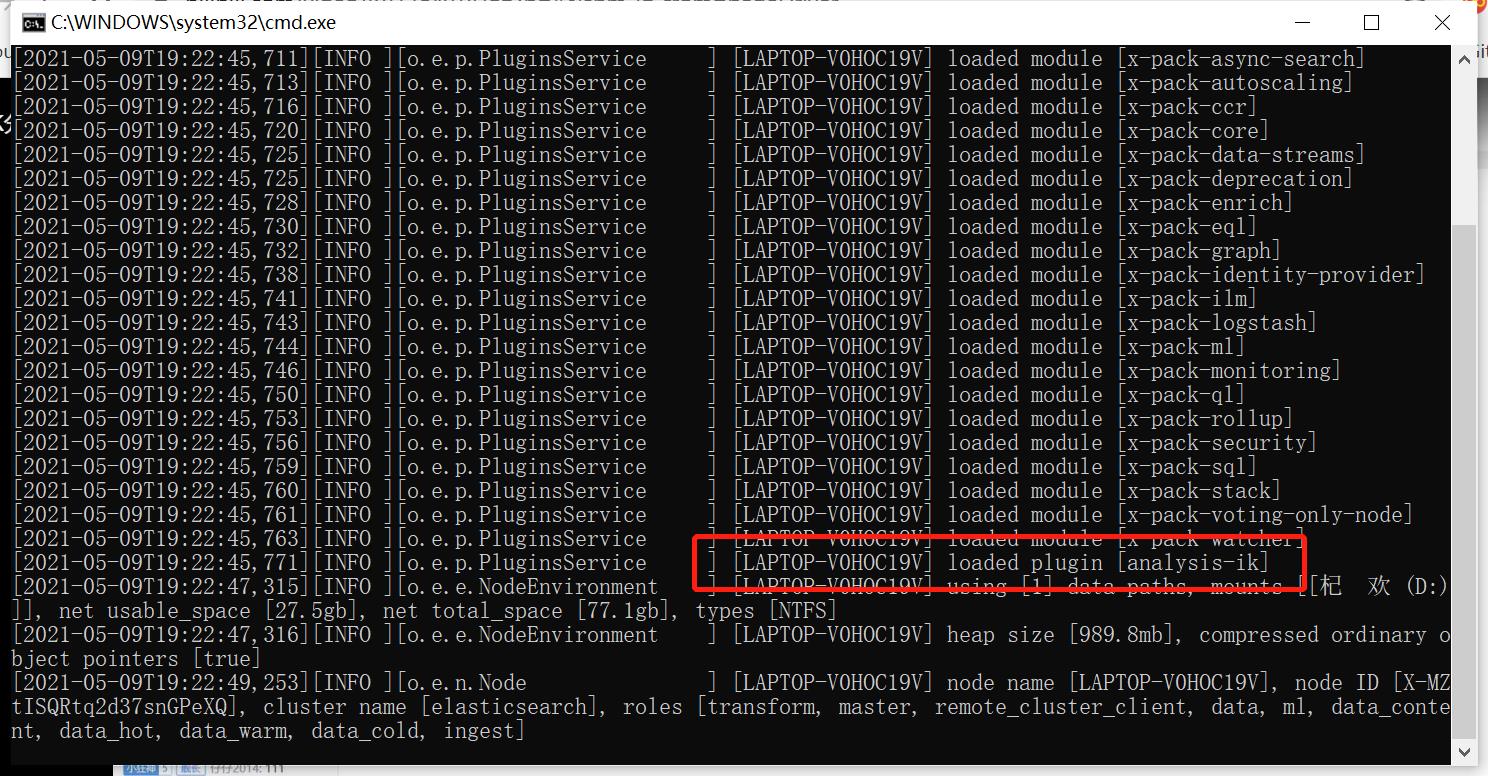
这说明插件已经被加载了。
用命令查看所有的插件可以看到我们刚按的ik插件。

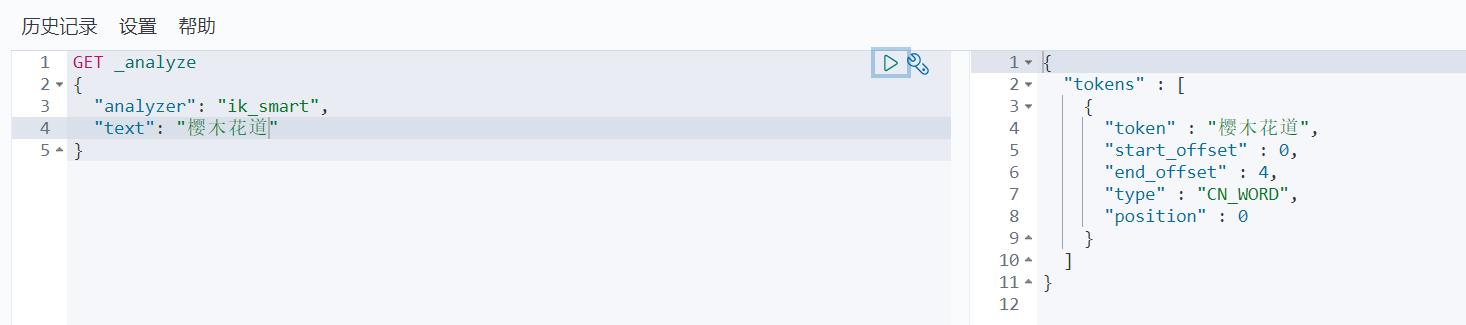
ik_smart 最少切分 没有重复
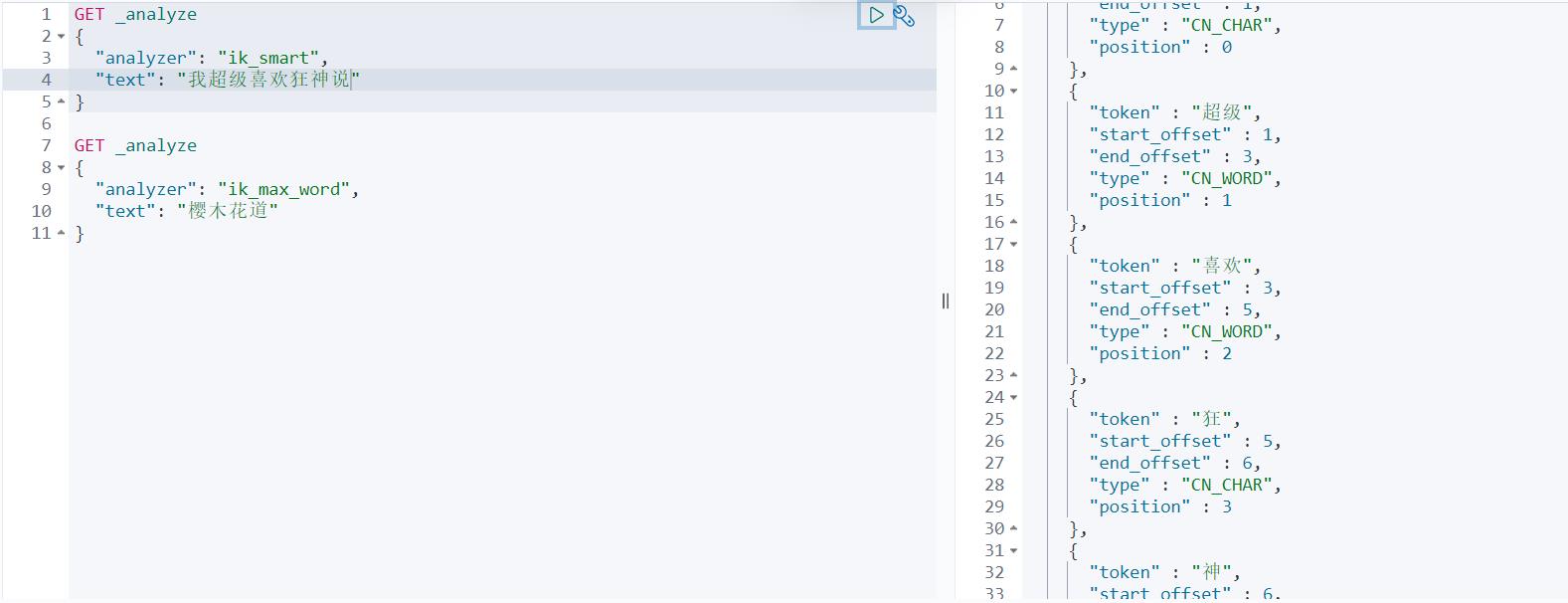
ik_max_word 最细粒度划分,穷尽所有的可能 有重复
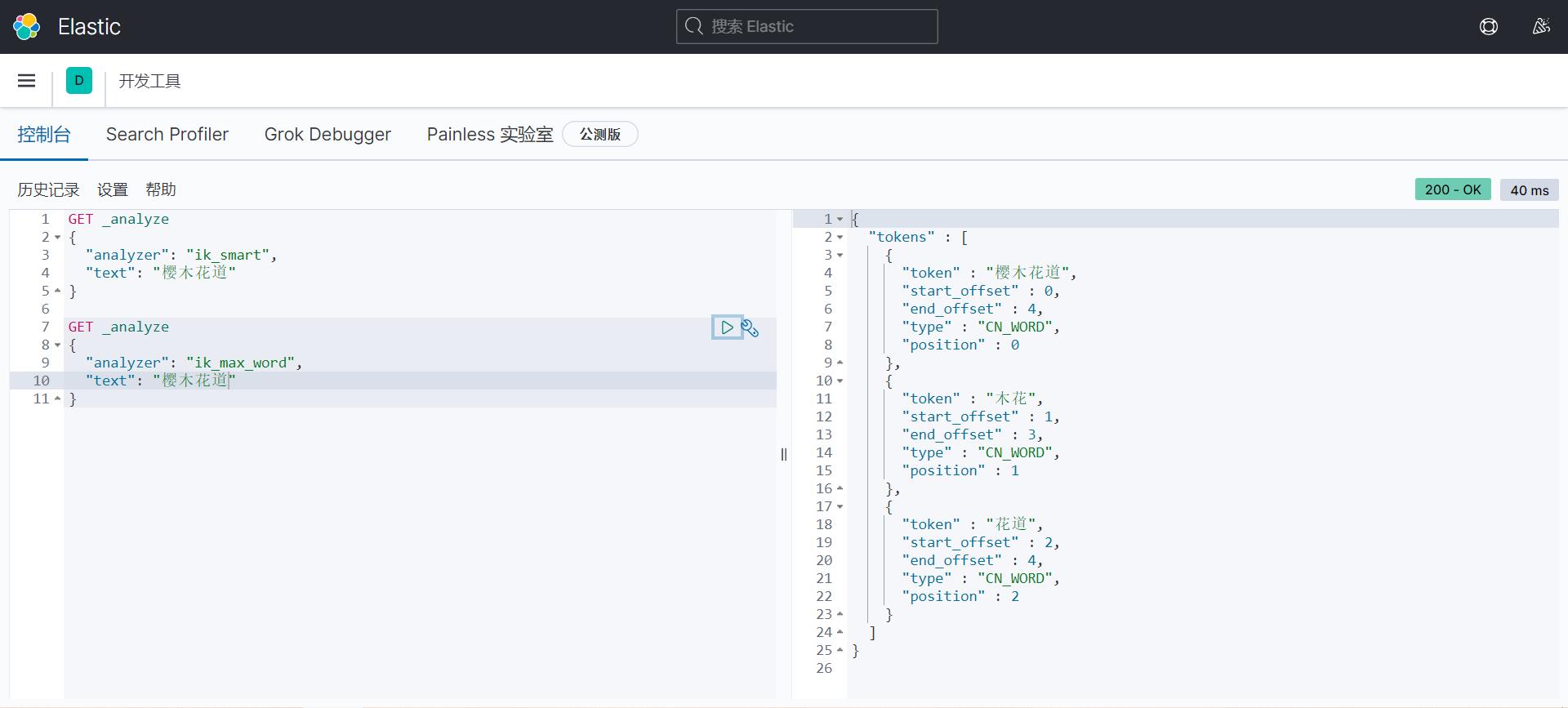
有一个问题,那就是我们想搜索狂神说这个词,但是在这里他默认的给拆分了,所以我们只能自己把狂神说这个词加到字典里面去。在ik插件中去配置就可以了。

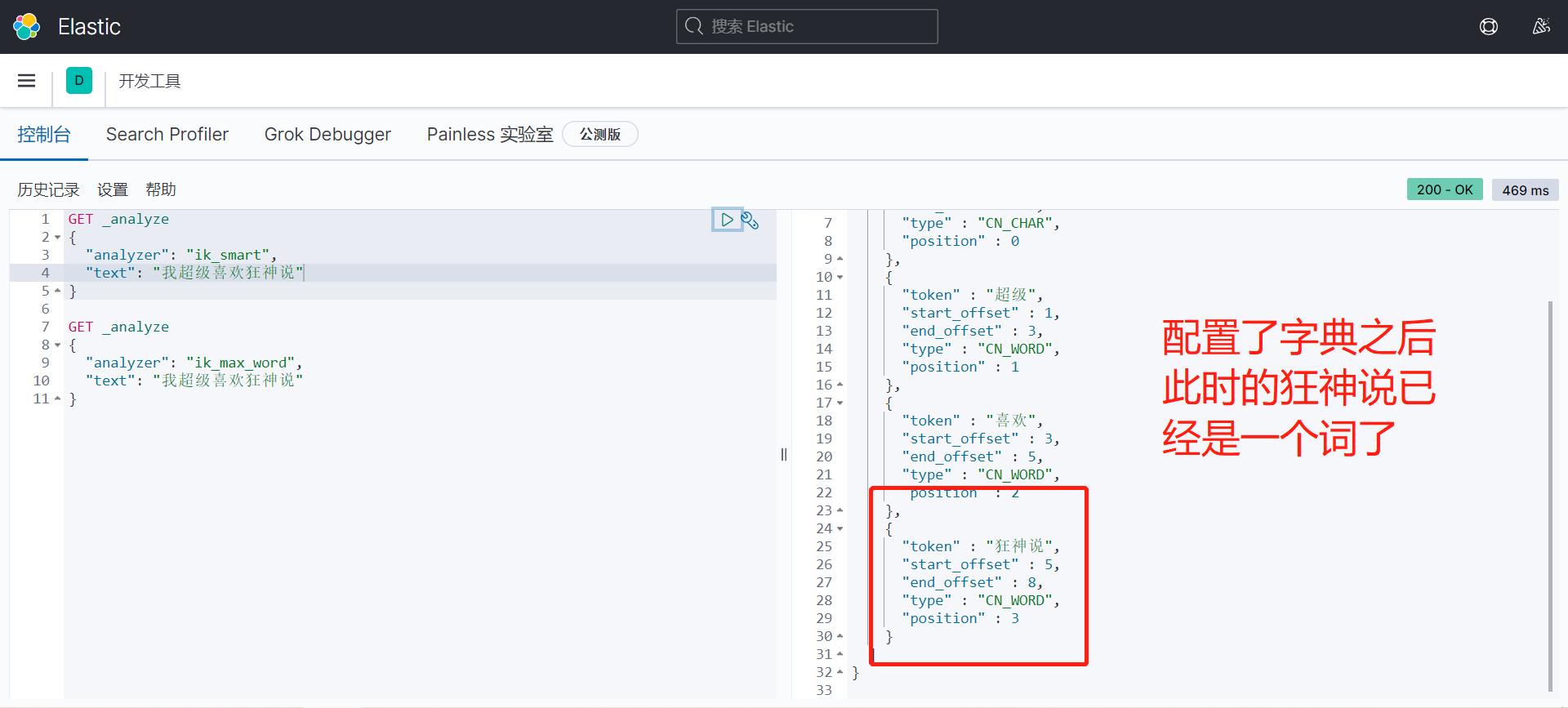
Rest风格说明
关于索引的基本操作
插入操作
- 创建索引 PUT命令是插入的意思
PUT /索引名/类型名(以后不用写)/文档ID
{
请求体
}
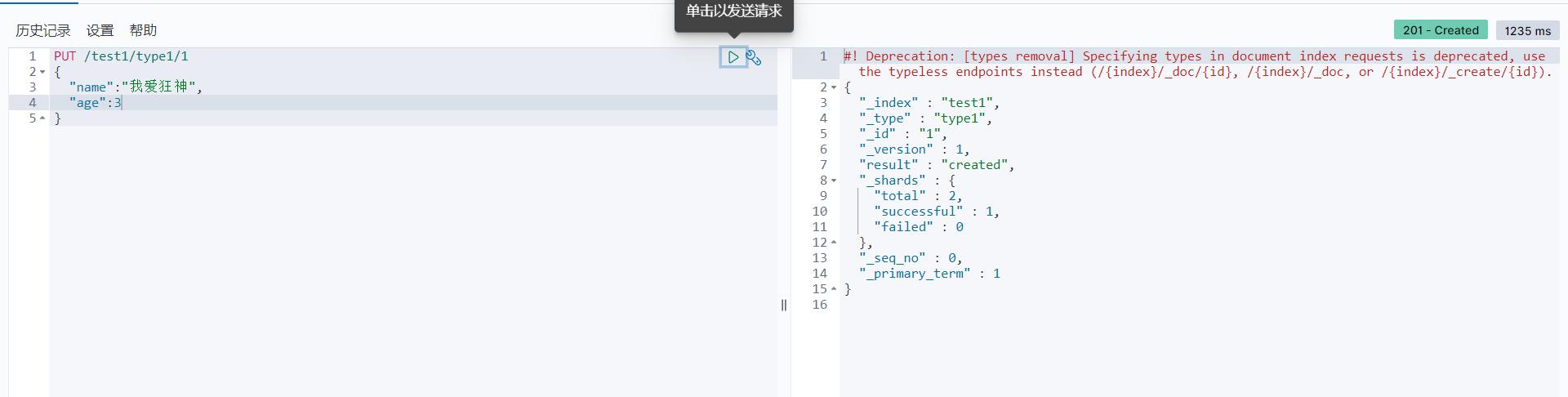


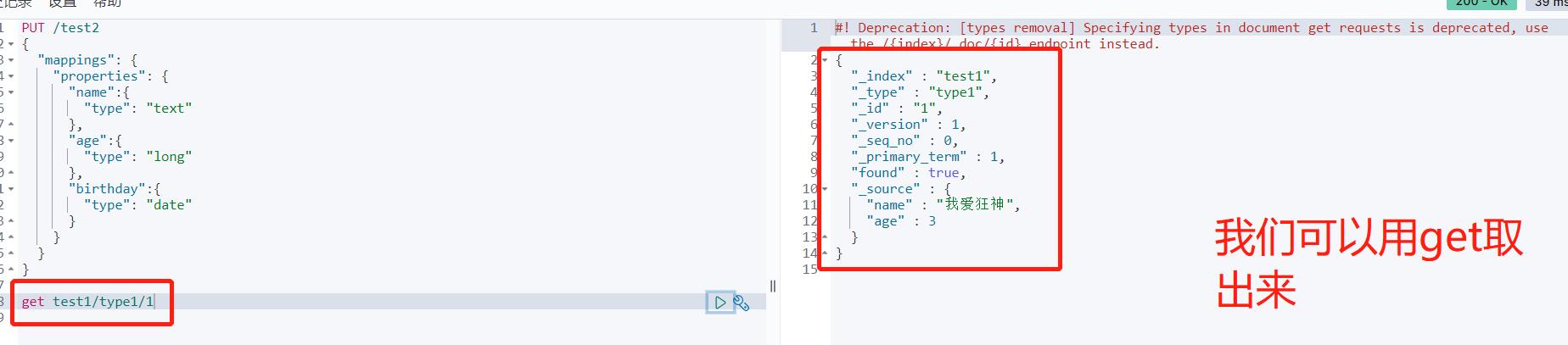
以后的type会被阉割,所以我们用_doc来代替就好了
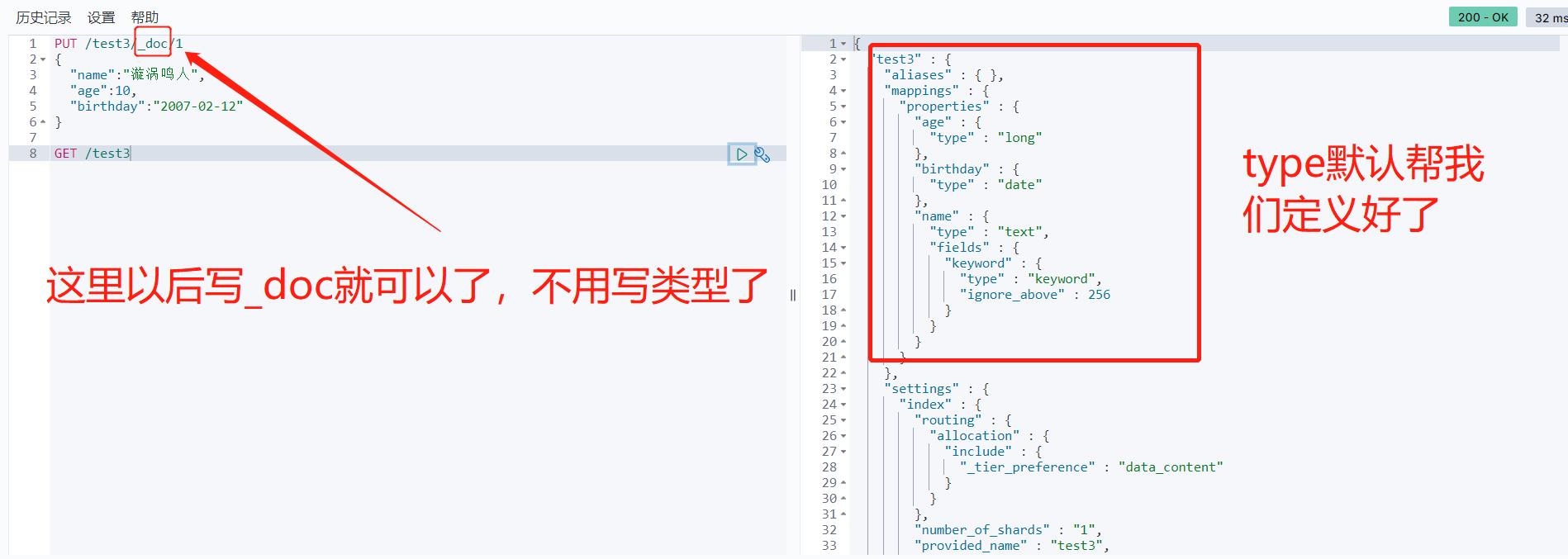
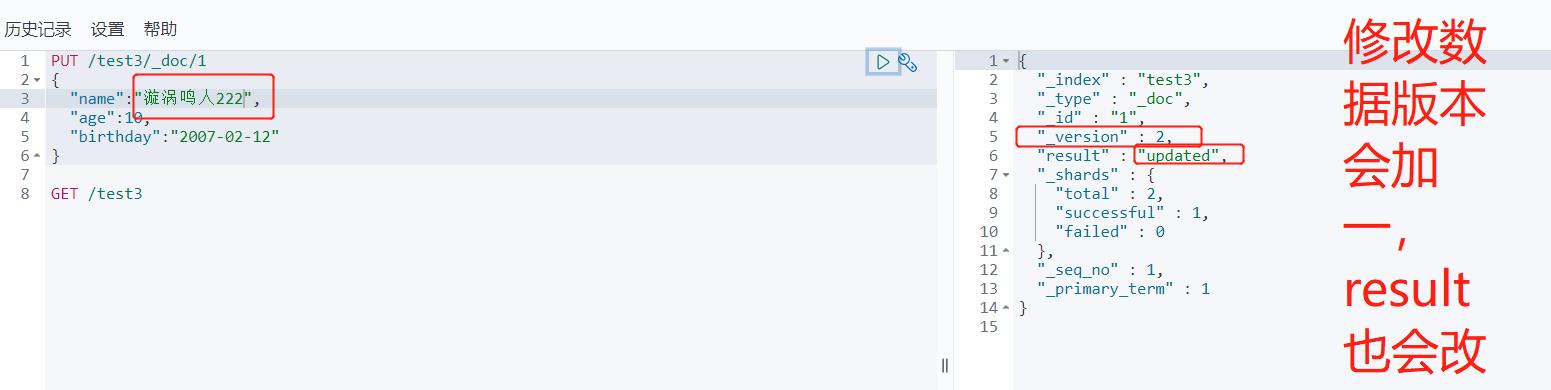

更新操作
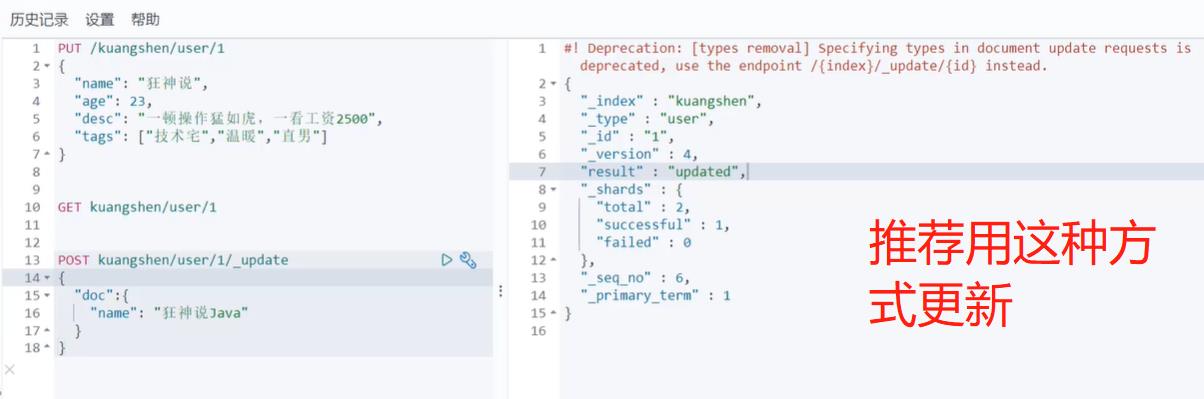

关于文档的基本操作 (重点)

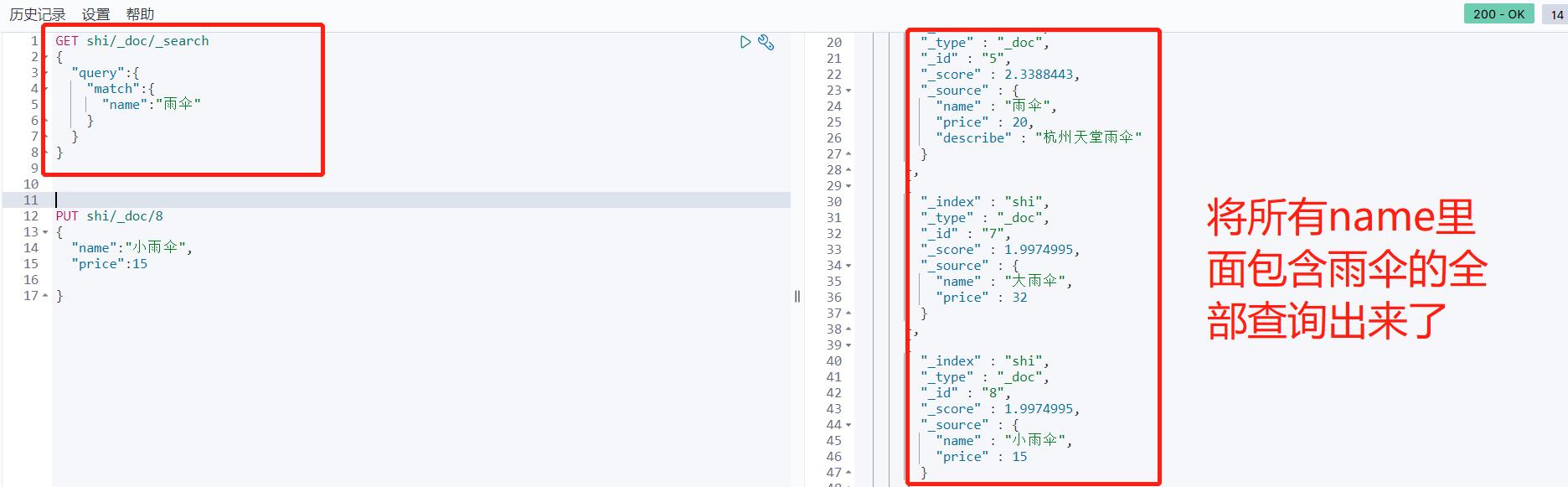
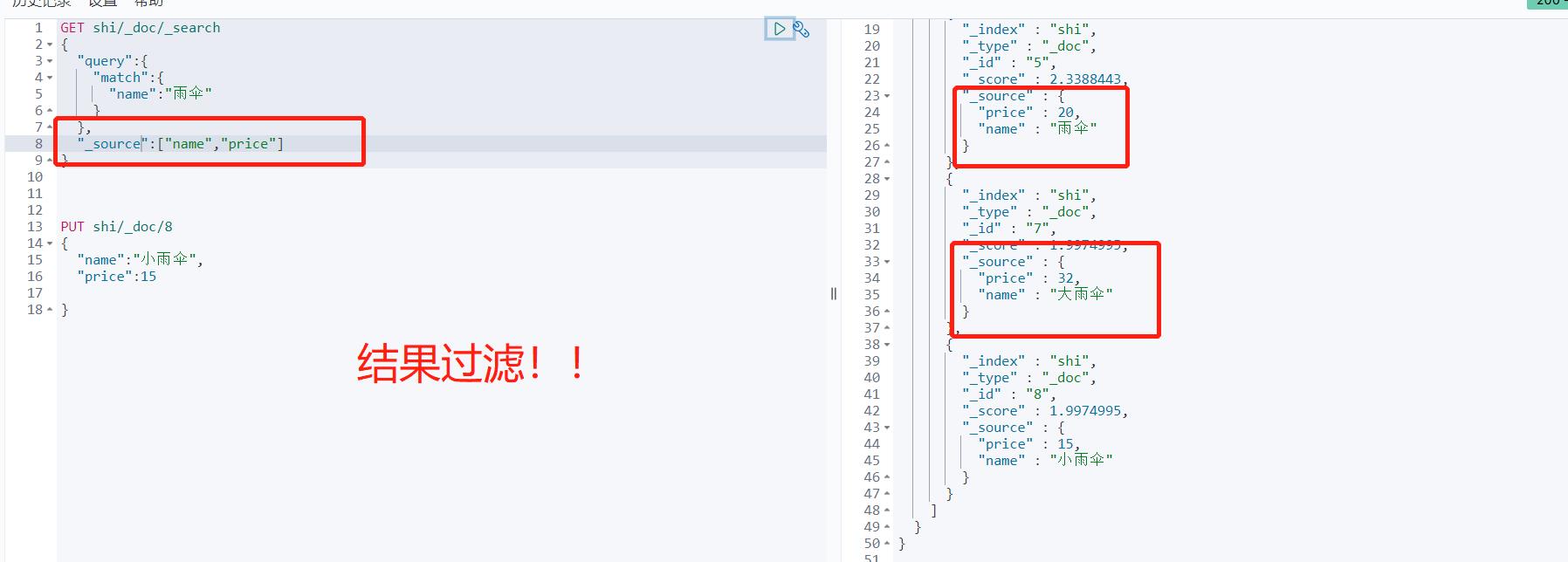
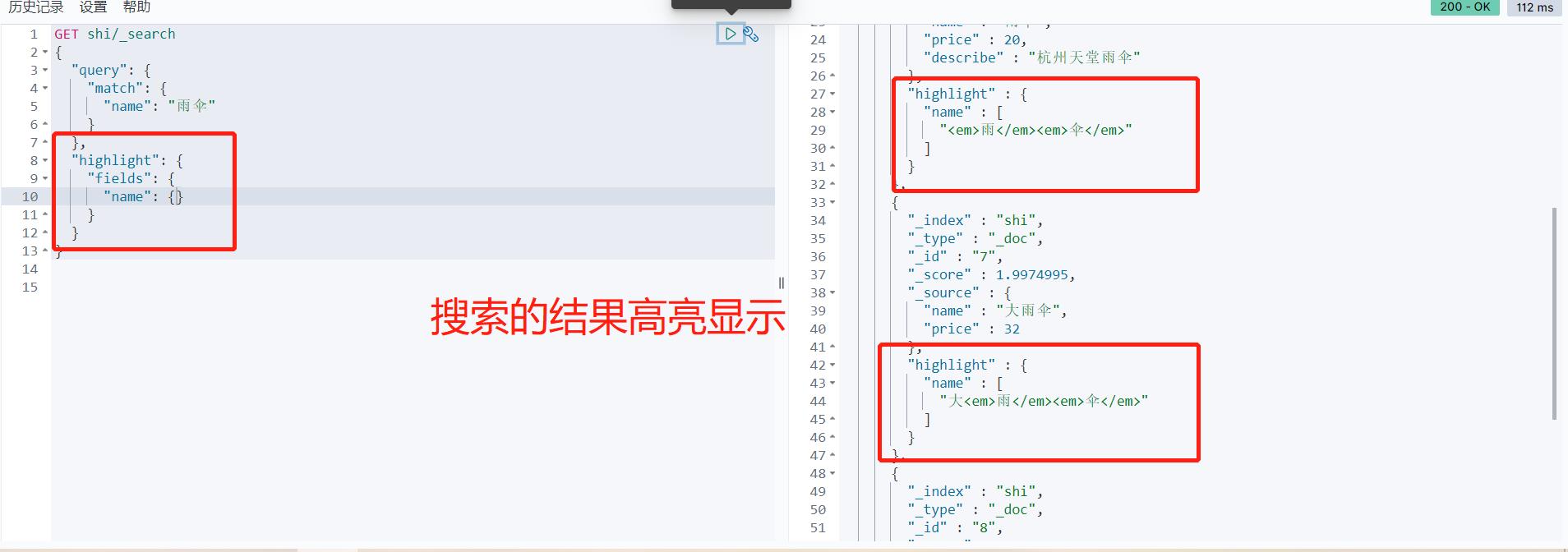
GET shi/_search
{
"query":{
"match":{
"name":"雨伞"
}
},
"_source":["name","price"]
}
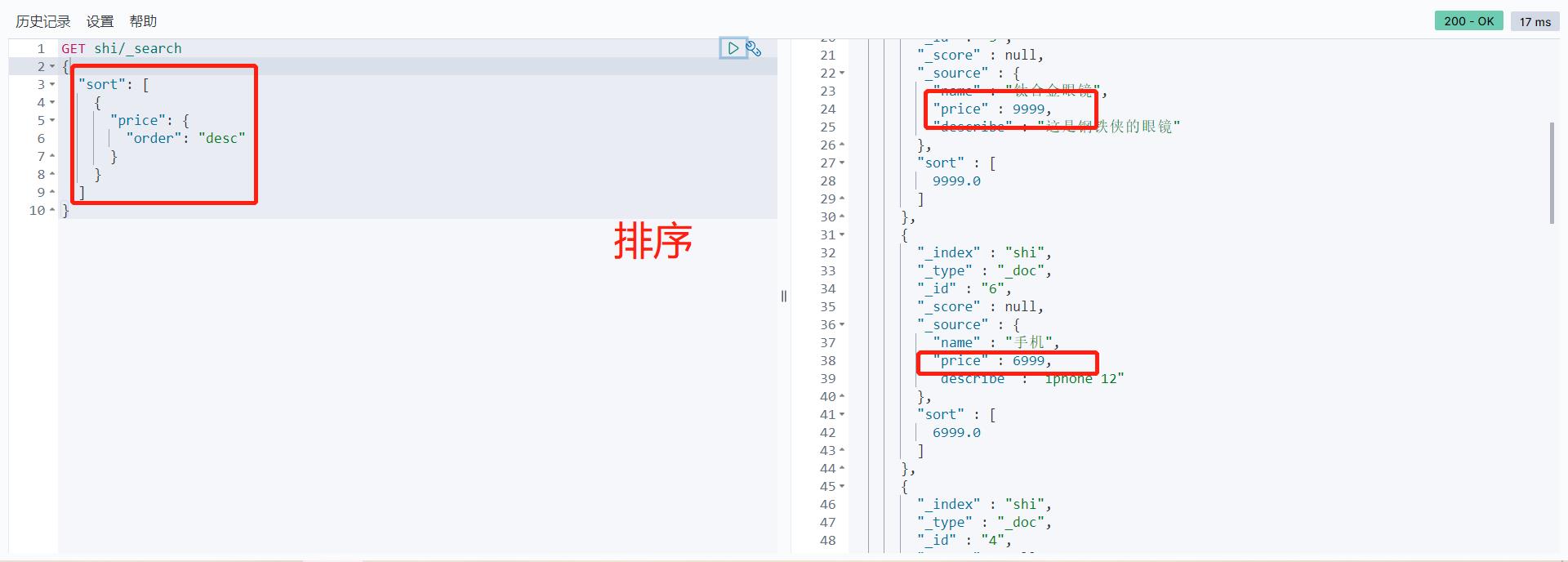
排序 分页
GET shi/_search
{
"query": {
"match": {
"name": "手"
}
},
"sort": [
{
"price": {
"order": "desc"
}
}
],
"from": 0,
"size": 2
}

# 复杂查询 - 查询 - 排序 - 分页
GET test/_search
{
"query": {
"match": {
"name": "樱木花"
}
},
"_source": ["name","age"],
"sort": [
{
"age": {
"order": "desc"
}
}
],
"from": 0,
"size": 3
}
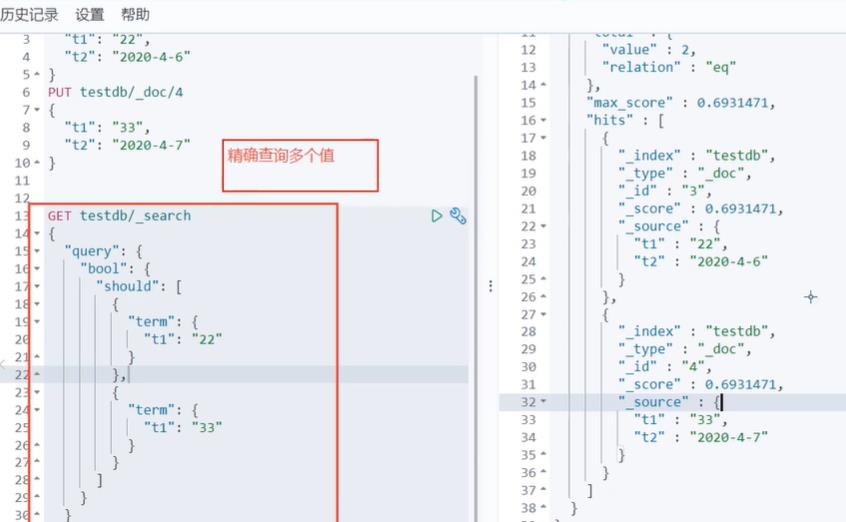
多条件精确查询 must命令相当于and should命令相当于or
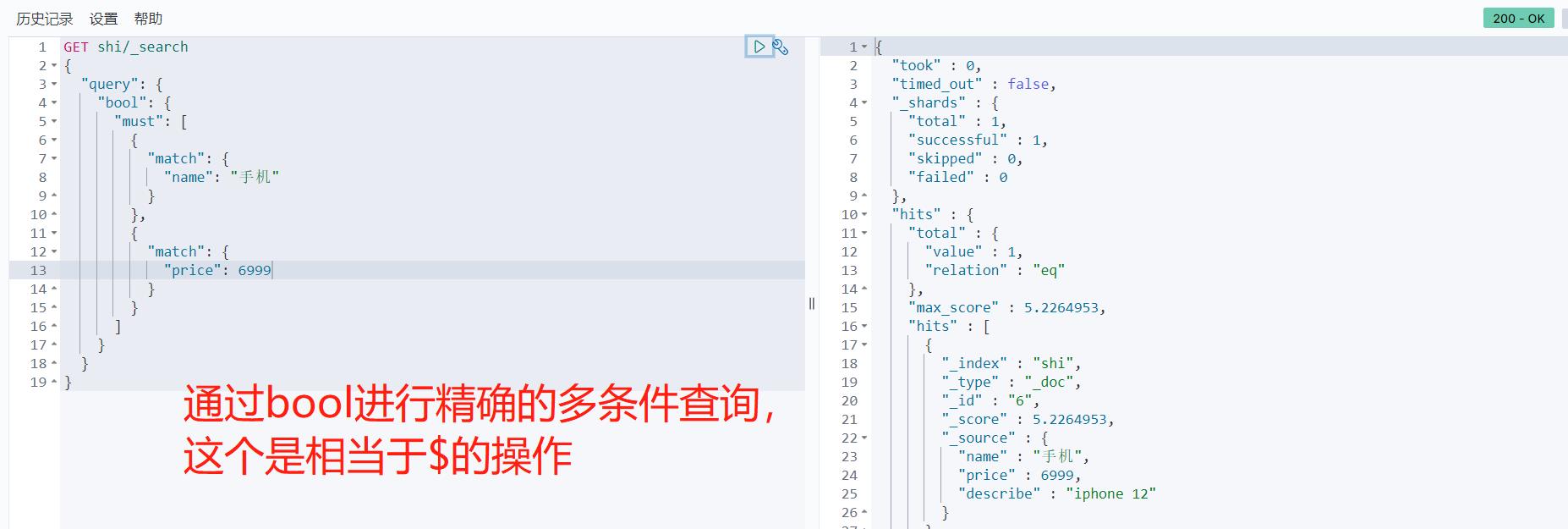
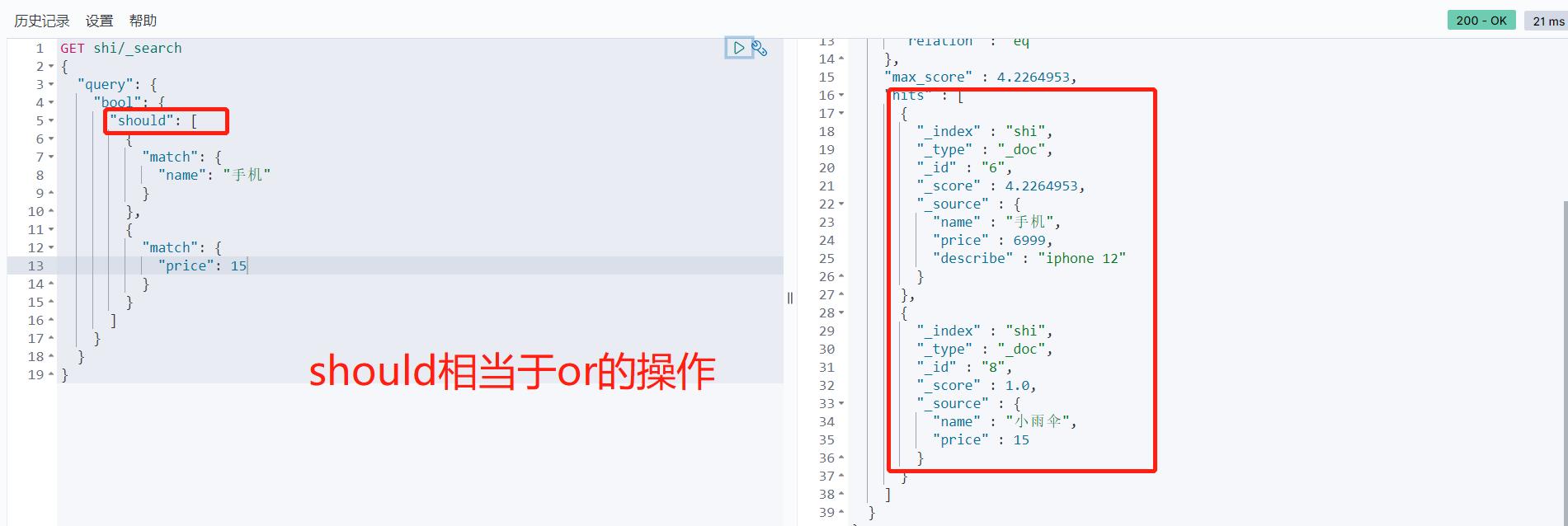
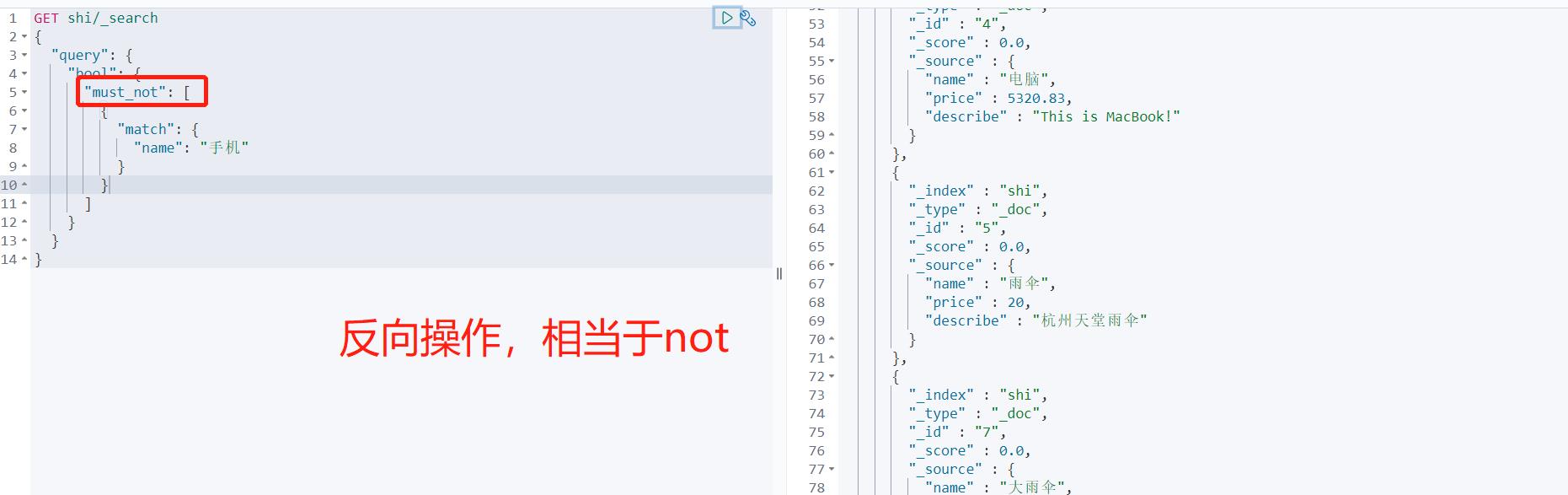
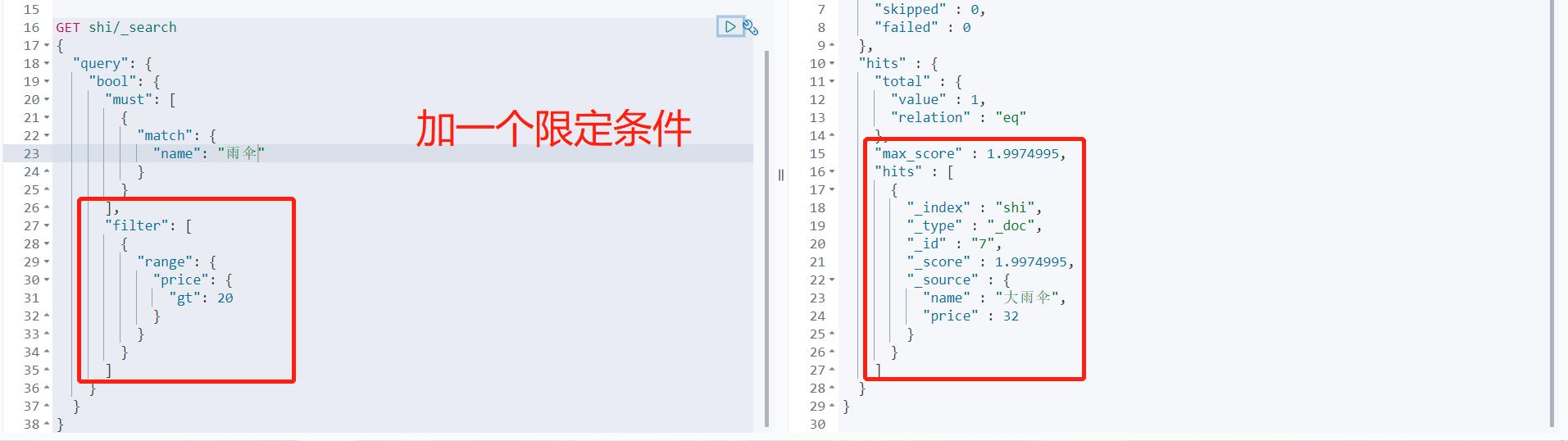
# 加了过滤器的精确多条件查询
GET test/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"name": "樱木"
}
}
],
"filter": [
{
"range": {
"age": {
"gte": 10,
"lte": 20
}
}
}
]
}
}
}
匹配多个条件
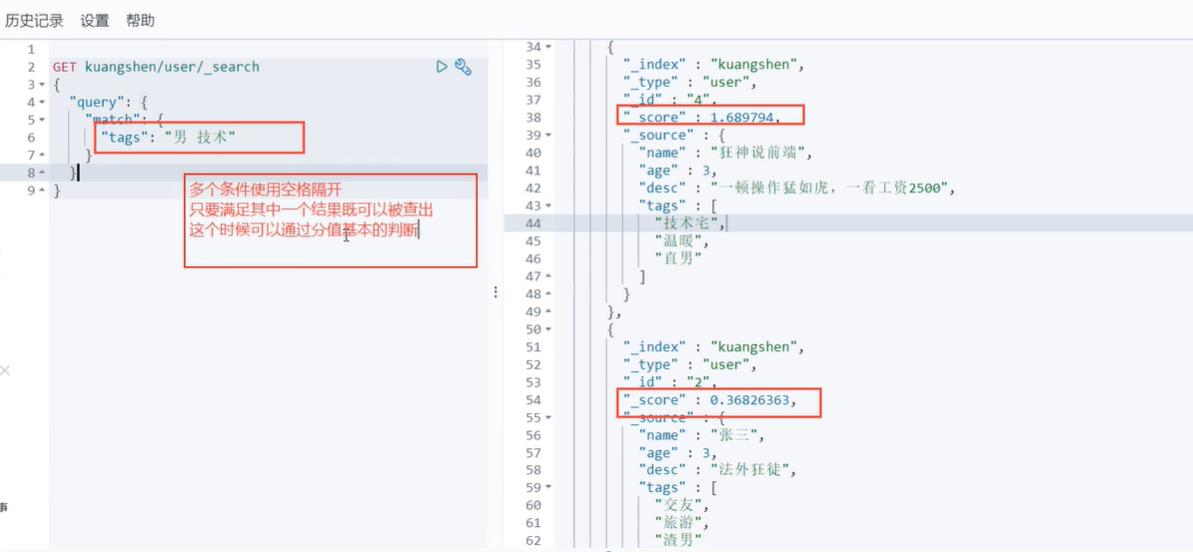
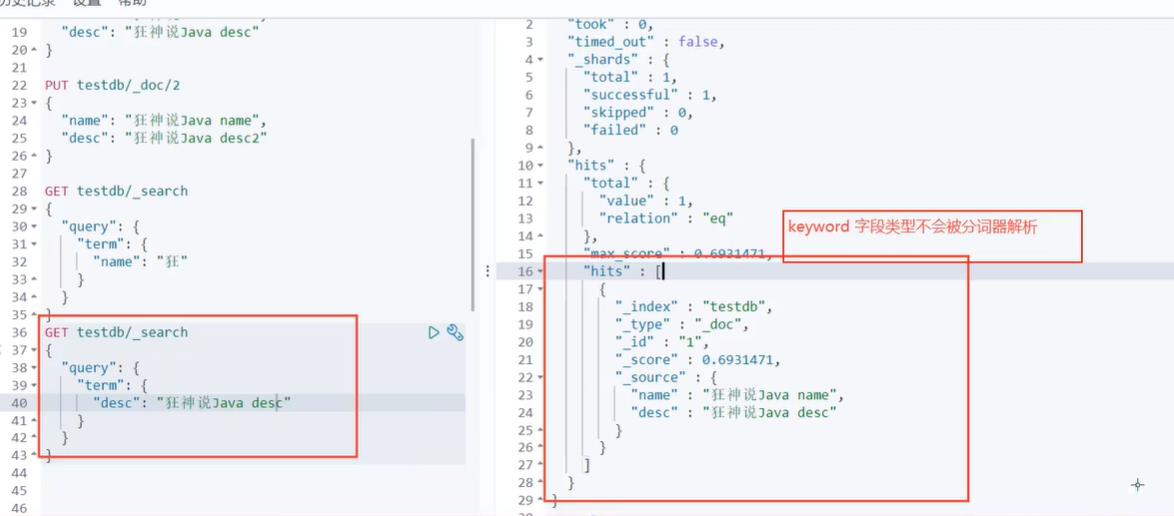
精确查询
简单来说一下精确查询的原理:
term query会去倒排索引中寻找确切的term,它并不知道分词器的存在,所以他只能查出当这个字段类型是不可以分词的情况,这种查询适合keyword、numeric、date等明确值的。
而match查询相当于模糊查询,match是知道分词器的存在的,并且每次查询都会进行分词,所以查到的结果会有很多。
因为term不考虑分词所以他查的条件就是字段所有的内容。
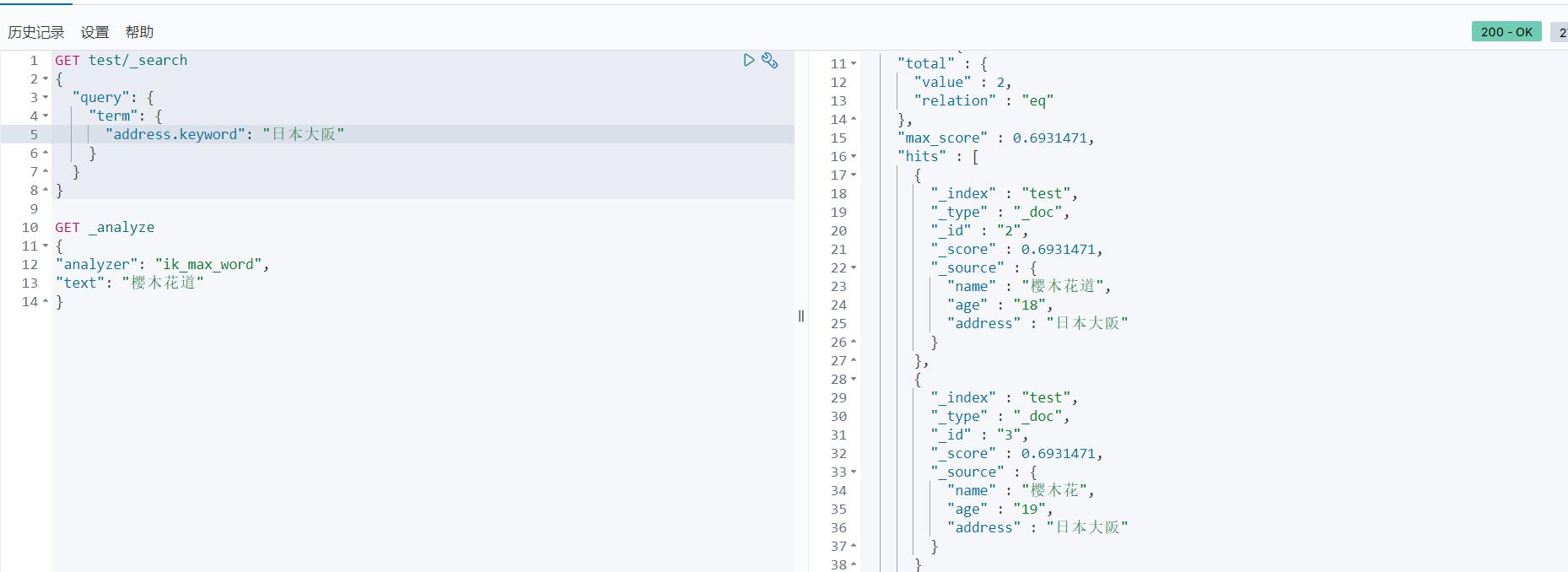
term:查询某个字段里含有某个关键词的文档
GET test/_search
{
"query": {
"term": {
"address.keyword": "日本大阪"
}
}
}
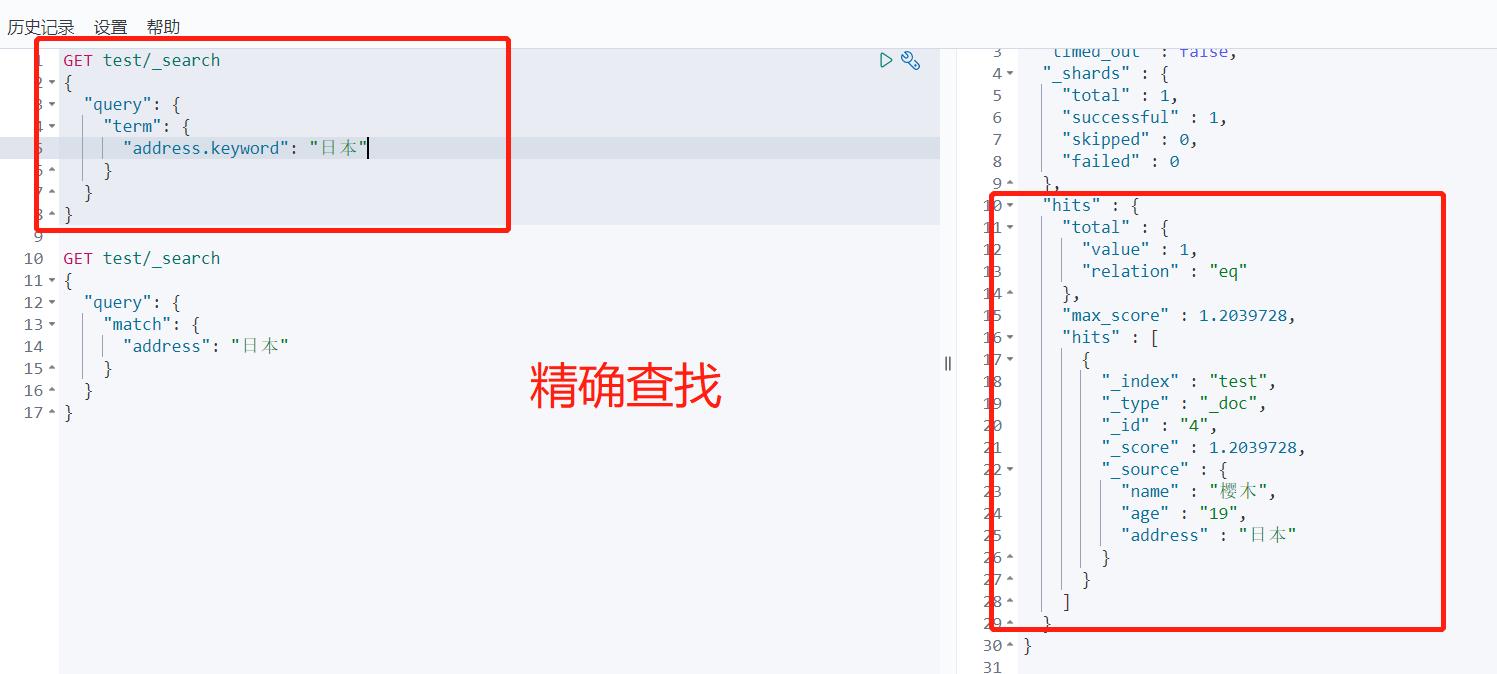

它和term区别可以理解为term是精确查询,这边match模糊查询;match会对my ss分词为两个单词,然后term对认为这是一个单词
term是根据倒排索引进行精确查找的。
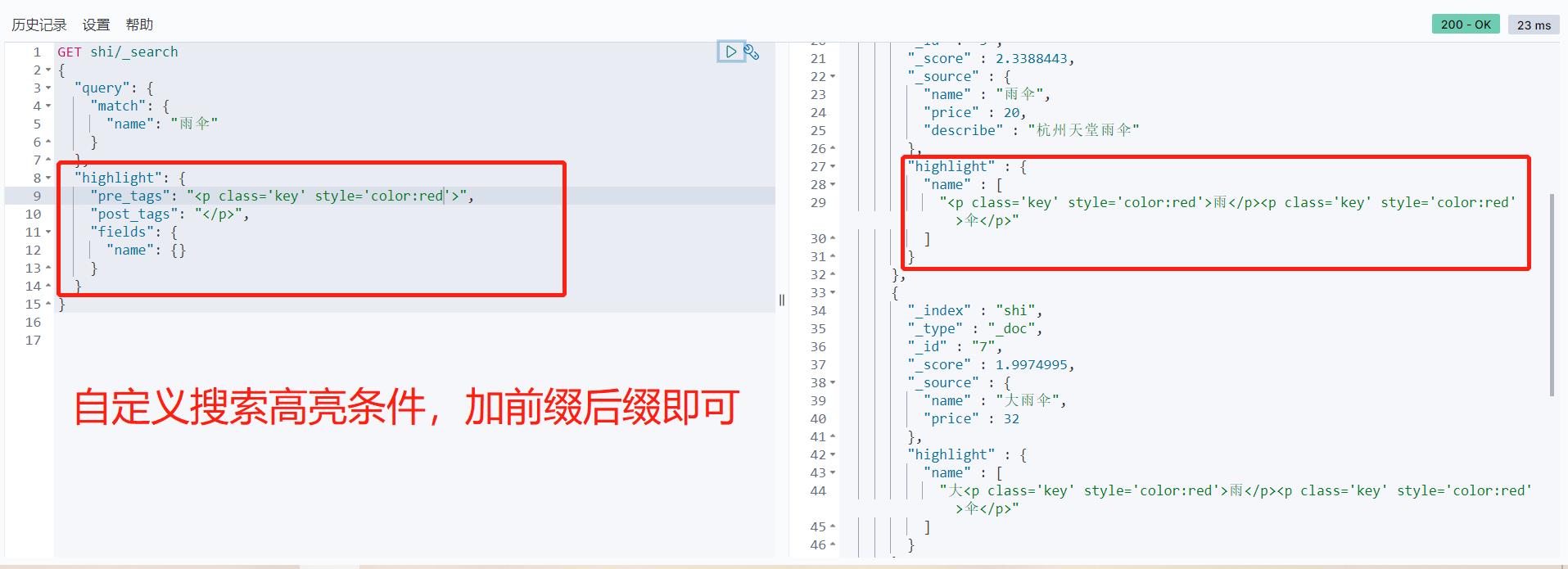
高亮查询
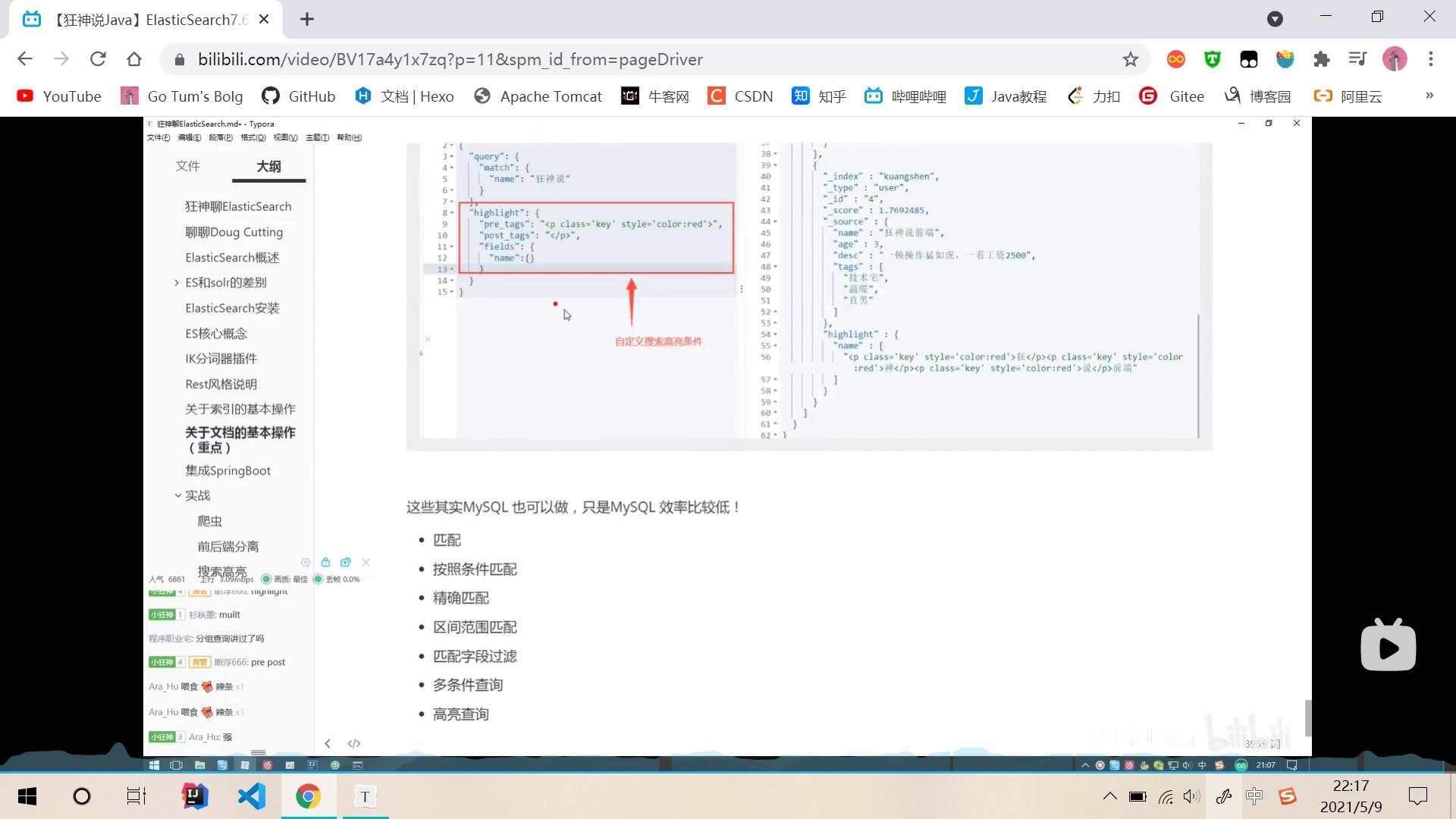
集成SpringBoot
- 依赖
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
<version>7.10.0</version>
</dependency>
- 怎么用
注意我们springboot自带的es版本和我们本地的版本不一样会造成预想不到的问题
# 找到自带的版本自定义修改就可以了
<elasticsearch.version>7.9.3</elasticsearch.version>
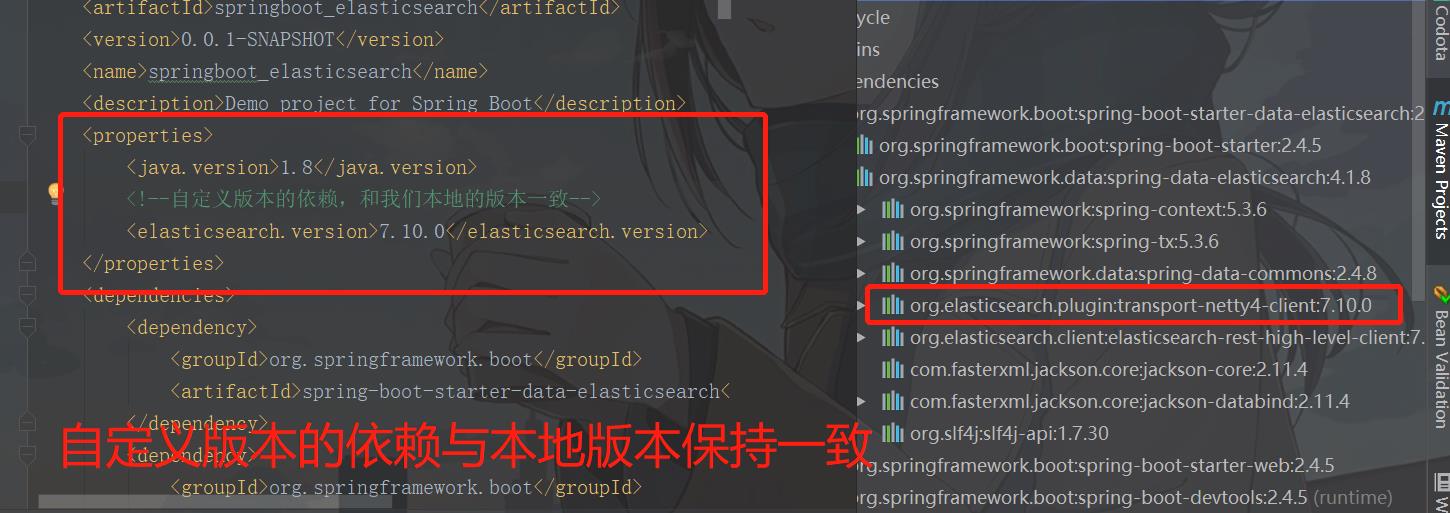
所有的关于数据库的都在springboot的自动配置包的data包下

编写配置类
package com.shi.config;
import org.apache.http.HttpHost;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestHighLevelClient;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class ElasticSearchClientConfig {
@Bean
public RestHighLevelClient restHighLevelClient(){
RestHighLevelClient client = new RestHighLevelClient(
RestClient.builder(
new HttpHost("localhost", 9200, "http")));
return client;
}
}
然后在测试中注入就可以了
@Autowired
private RestHighLevelClient restHighLevelClient;
//名称必须是默认的,否则会报错 否则加注解 @Qualifier("restHighLevelClient")
测试高级客户端API
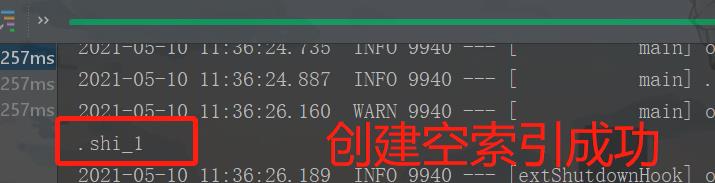
创建索引
// 创建索引
@Test
void createIndex() throws IOException {
// 创建索引请求
CreateIndexRequest request = new CreateIndexRequest(".shi_1");
// 客户端运行请求,然后响应
CreateIndexResponse createIndexResponse = client.indices().create(request, RequestOptions.DEFAULT);
System.out.println(createIndexResponse.index());
}

获取索引
// 获取索引
@Test
void existIndex() throws IOException {
GetIndexRequest getIndexRequest = new GetIndexRequest(".shi_1");
boolean exists = client.indices().exists(getIndexRequest, RequestOptions.DEFAULT);
System.out.println(exists);
}// 返回true
删除索引
// 删除索引
@Test
void deleteIndex() throws IOException {
DeleteIndexRequest t2 = new DeleteIndexRequest("t2");
AcknowledgedResponse delete = client.indices().delete(t2, RequestOptions.DEFAULT);
System.out.println(delete);
}// 返回true true代表删除成功
添加索引
由于我们的user对象需要转化成json的格式方便存储和读取,所以我们用阿里巴巴的fastjson包来转化
<!-- https://mvnrepository.com/artifact/com.alibaba/fastjson -->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.75</version>
</dependency>
// 添加文档
@Test
void addDocument() throws IOException {
// 创建对象
User user = new User("海波东", 52);
// 创建请求
IndexRequest request = new IndexRequest(".shi_1");
// 规则 put shi/_doc/1
request.id("1");
request.timeout("1s");
//将我们的数据放入请求
request.source(JSON.toJSONString(user), XContentType.JSON);
// 客户端发送请求 获取响应结果
IndexResponse index = client.index(request, RequestOptions.DEFAULT);
System.out.println(index.toString());
System.out.println(index.status());
}


获取文档 查看文档是否存在
// 获取文档 查看文档是否存在
@Test
void existDocument() throws IOException {
GetRequest getRequest = new GetRequest(".shi_1", "1");
//不获取返回的上下文了
getRequest.fetchSourceContext(new FetchSourceContext(false));
getRequest.storedFields("_none_");
boolean exists = client.exists(getRequest, RequestOptions.DEFAULT);
System.out.println(exists);
} // 返回true 表示存在该文档
获取文档信息
// 获取文档信息
@Test
void getDocument() throws IOException{
GetRequest request = new GetRequest(".shi_1", "1");
GetResponse response = client.get(request, RequestOptions.DEFAULT);
// 打印文档键值对
System.out.println(response.getSourceAsString());
// 打印文档所有内容
System.out.println(response);
}
}
更新文档信息
// 更新文档
@Test
void updateDocument() throws IOException{
UpdateRequest request = new UpdateRequest(".shi_1", "1");
request.timeout("1s");
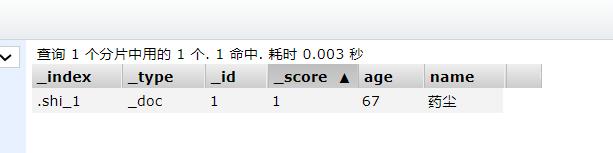
User user = new User("药尘", 67);
request.doc(JSON.toJSONString(user),XContentType.JSON);
UpdateResponse update = client.update(request, RequestOptions.DEFAULT);
System.out.println(update.status());
} // 返回OK
删除文档信息
// 删除文档信息
@Test
void deleteDocument() throws IOException {
DeleteRequest deleteRequest = new DeleteRequest(".shi_1", "2");
deleteRequest.timeout("1s");
DeleteResponse delete = client.delete(deleteRequest, RequestOptions.DEFAULT);
System.out.println(delete.status());
} // 返回OK 表示删除成功
批量增加文档信息
// 批量增加文档信息
@Test
void addBlukDocument() throws IOException {
BulkRequest bulkRequest = new BulkRequest();
bulkRequest.timeout("10s");
List<User> list = new ArrayList<>();
list.add(new User("千仞雪",20));
list.add(new User("千仞雪1",21));
list.add(new User("千仞雪2",22));
list.add(new User("千仞雪3",22));
list.add(new User("千仞雪4",23));
list.add(new User("千仞雪5",21));
for (以上是关于ElasticSearch学习笔记的主要内容,如果未能解决你的问题,请参考以下文章
ElasticSearch学习问题记录——Invalid shift value in prefixCoded bytes (is encoded value really an INT?)(代码片段