三欠拟合和过拟合
Posted 满目星辰wwq
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了三欠拟合和过拟合相关的知识,希望对你有一定的参考价值。
多项式拟合实例
导入必要的模块
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.preprocessing import StandardScaler
from sklearn.preprocessing import PolynomialFeatures
from sklearn.linear_model import LinearRegression, Ridge
from sklearn.metrics import mean_squared_error
生成数据
生成100个训练样本
# 设置随机种子
np.random.seed(34)
sample_num = 100
# 从-5到5中随机抽取100个浮点数
x_train = np.random.uniform(-5, 5, size=sample_num)
# 将x从shape为(sample_num,)变为(sample_num,1)
X_train = x_train.reshape(-1,1)
# 生成y值的实际函数
y_train_real = 0.5 * x_train ** 3 + x_train ** 2 + 2 * x_train + 1
# 生成误差值
err_train = np.random.normal(0, 5, size=sample_num)
# 真实y值加上误差值,得到样本的y值
y_train = y_train_real + err_train
# 画出样本的散点图
plt.scatter(x_train, y_train, marker='o', color='g', label='train dataset')
# 画出实际函数曲线
plt.plot(np.sort(x_train), y_train_real[np.argsort(x_train)], color='b', label='real curve')
plt.legend()
plt.xlabel('x')
plt.ylabel('y')
plt.show()
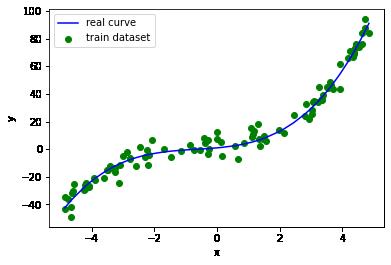
生成测试集
# 设置随机种子
np.random.seed(12)
sample_num = 100
# 从-5到5中随机抽取100个浮点数
x_test = np.random.uniform(-5, 5, size=sample_num)
# 将x从shape为(sample_num,)变为(sample_num,1)
X_test = x_test.reshape(-1,1)
# 生成y值的实际函数
y_test_real = 0.5 * x_test ** 3 + x_test ** 2 + 2 * x_test + 1
# 生成误差值
err_test = np.random.normal(0, 5, size=sample_num)
# 真实y值加上误差值,得到样本的y值
y_test = y_test_real + err_test
# 画出样本的散点图
plt.scatter(x_test, y_test, marker='o', color='c', label='test dataset')
plt.legend()
plt.xlabel('x')
plt.ylabel('y')
plt.show()
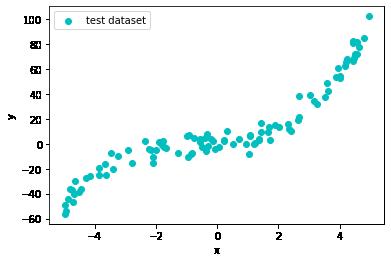
问题:加入我们不知道生成样本的函数,如何用线性回归模型拟合这些样本?
多项式模型拟合
1阶线性模型拟合
# 线性回归模型训练
reg1 = LinearRegression()
reg1.fit(X_train, y_train)
# 模型预测
y_train_pred1 = reg1.predict(X_train)
# 画出样本的散点图
plt.scatter(x_train, y_train, marker='o', color='g', label='train dataset')
# 画出实际函数曲线
plt.plot(np.sort(x_train), y_train_real[np.argsort(x_train)], color='b', label='real curve')
# 画出预测函数曲线
plt.plot(np.sort(x_train), y_train_pred1[np.argsort(x_train)], color='r', label='prediction curve')
plt.legend()
plt.xlabel('x')
plt.ylabel('y')
plt.show()
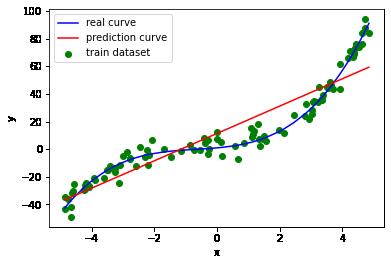
直线太过简单,不能很好地描述数据的变化关系。
3阶多项式模型拟合
使用到的api:
创建多项式特征sklearn.preprocessing.PolynomialFeatures
用到的参数:
-
degree:设置多项式特征的阶数,默认2。
-
include_bias:是否包括偏置项,默认True。
使用fit_transform函数对数据做处理。
特征标准化sklearn.preprocessing.StandardScaler(减去均值除再除以标准差)
使用fit_transform函数对数据做处理。
# 生成多项式数据
poly = PolynomialFeatures(degree=3, include_bias=False)
X_train_poly = poly.fit_transform(X_train)
# 数据标准化(减均值除标准差)
scaler = StandardScaler()
X_train_poly_scaled = scaler.fit_transform(X_train_poly)
# 线性回归模型训练
reg3 = LinearRegression()
reg3.fit(X_train_poly_scaled, y_train)
# 模型预测
y_train_pred3 = reg3.predict(X_train_poly_scaled)
# 画出样本的散点图
plt.scatter(x_train, y_train, marker='o', color='g', label='train dataset')
# 画出实际函数曲线
# plt.plot(np.sort(x_train), y_train_real[np.argsort(x_train)], color='b', label='real curve')
# 画出预测函数曲线
plt.plot(np.sort(x_train), y_train_pred3[np.argsort(x_train)], color='r', label='prediction curve')
plt.legend()
plt.xlabel('x')
plt.ylabel('y')
plt.show()
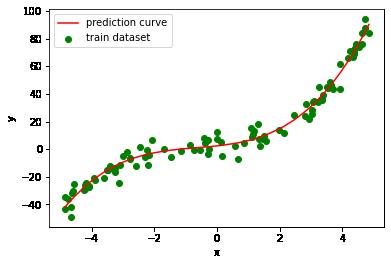
曲线拟合得非常不错。
10阶多项式模型拟合
# 生成多项式数据
poly = PolynomialFeatures(degree=10, include_bias=False)
X_train_poly = poly.fit_transform(X_train)
# 数据标准化(减均值除标准差)
scaler = StandardScaler()
X_train_poly_scaled = scaler.fit_transform(X_train_poly)
# 线性回归模型训练
reg10 = LinearRegression()
reg10.fit(X_train_poly_scaled, y_train)
# 模型预测
y_train_pred10 = reg10.predict(X_train_poly_scaled)
# 画出样本的散点图
plt.scatter(x_train, y_train, marker='o', color='g', label='train dataset')
# 画出实际函数曲线
plt.plot(np.sort(x_train), y_train_real[np.argsort(x_train)], color='b', label='real curve')
# 画出预测函数曲线
plt.plot(np.sort(x_train), y_train_pred10[np.argsort(x_train)], color='r', label='prediction curve')
plt.legend()
plt.xlabel('x')
plt.ylabel('y')
plt.show()
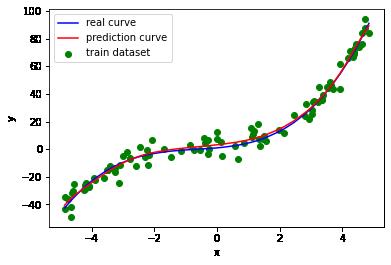
曲线拟合得也还可以。
30阶多项式模型拟合
# 生成多项式数据
poly = PolynomialFeatures(degree=30, include_bias=False)
X_train_poly = poly.fit_transform(X_train)
# 数据标准化(减均值除标准差)
scaler = StandardScaler()
X_train_poly_scaled = scaler.fit_transform(X_train_poly)
# 线性回归模型训练
reg30 = LinearRegression()
reg30.fit(X_train_poly_scaled, y_train)
# 模型预测
y_train_pred30 = reg30.predict(X_train_poly_scaled)
# 画出样本的散点图
plt.scatter(x_train, y_train, marker='o', color='g', label='train dataset')
# 画出实际函数曲线
# plt.plot(np.sort(x_train), y_train_real[np.argsort(x_train)], color='b', label='real curve')
# 画出预测函数曲线
plt.plot(np.sort(x_train), y_train_pred30[np.argsort(x_train)], color='r', label='prediction curve')
plt.legend()
plt.xlabel('x')
plt.ylabel('y')
plt.show()
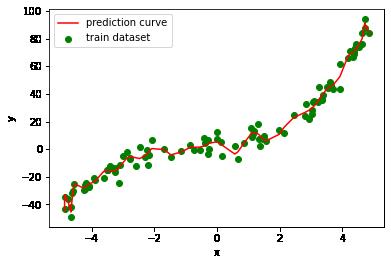
曲线变得弯曲而复杂,把训练样本点的噪声变化也学习到了。
指标对比
# 计算MSE
mse1 = mean_squared_error(y_train_pred1, y_train)
mse3 = mean_squared_error(y_train_pred3, y_train)
mse10 = mean_squared_error(y_train_pred10, y_train)
mse30 = mean_squared_error(y_train_pred30, y_train)
# 打印结果
print('MSE:')
print('1 order polynomial: {:.2f}'.format(mse1))
print('3 order polynomial: {:.2f}'.format(mse3))
print('10 order polynomial: {:.2f}'.format(mse10))
print('30 order polynomial: {:.2f}'.format(mse30))
MSE:
1 order polynomial: 149.92
3 order polynomial: 24.32
10 order polynomial: 23.64
30 order polynomial: 15.05
训练集mse指标从好到坏的模型是:30阶多项式、10阶多项式、3阶多项式、1阶多项式。
测试集检验
1阶线性模型预测
# 模型预测
y_test_pred1 = reg1.predict(X_test)
# 画出样本的散点图
plt.scatter(x_test, y_test, marker='o', color='c', label='test dataset')
# 画出预测函数曲线
plt.plot(np.sort(x_test), y_test_pred1[np.argsort(x_test)], color='r', label='1 order')
plt.legend()
plt.xlabel('x')
plt.ylabel('y')
plt.show()
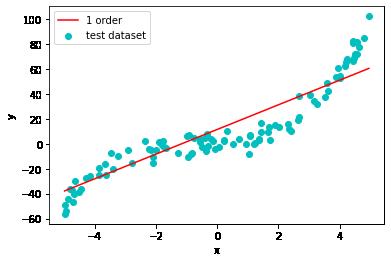
3阶多项式模型预测
# 生成多项式数据
poly = PolynomialFeatures(degree=3, include_bias=False)
X_test_poly = poly.fit_transform(X_test)
# 数据标准化(减均值除标准差)
scaler = StandardScaler()
X_test_poly_scaled = scaler.fit_transform(X_test_poly)
# 模型预测
y_test_pred3 = reg3.predict(X_test_poly_scaled)
# 画出样本的散点图
plt.scatter(x_test, y_test, marker='o', color='c', label='test dataset')
# 画出预测函数曲线
plt.plot(np.sort(x_test), y_test_pred3[np.argsort(x_test)], color='r', label='3 order')
plt.legend()
plt.xlabel('x')
plt.ylabel('y')
plt.show()
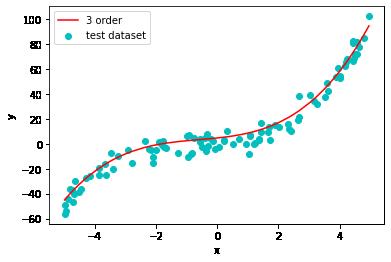
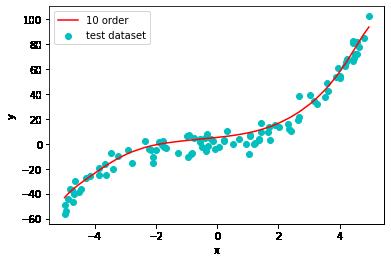
10阶多项式模型预测
# 生成多项式数据
poly = PolynomialFeatures(degree=10, include_bias=False)
X_test_poly = poly.fit_transform(X_test)
# 数据标准化(减均值除标准差)
scaler = StandardScaler()
X_test_poly_scaled = scaler.fit_transform(X_test_poly)
# 模型预测
y_test_pred10 = reg10.predict(X_test_poly_scaled)
# 画出样本的散点图
plt.scatter(x_test, y_test, marker='o', color='c', label='test dataset')
# 画出预测函数曲线
plt.plot(np.sort(x_test), y_test_pred10[np.argsort(x_test)], color='r', label='10 order')
plt.legend()
plt.xlabel('x')
plt.ylabel('y')
plt.show()
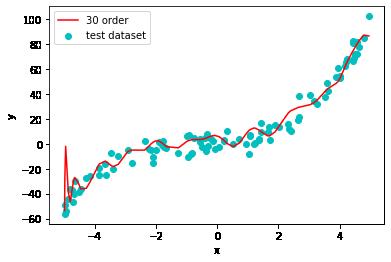
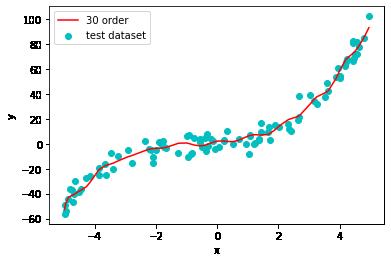
30阶多项式模型预测
# 生成多项式数据
poly = PolynomialFeatures(degree=30, include_bias=False)
X_test_poly = poly.fit_transform(X_test)
# 数据标准化(减均值除标准差)
scaler = StandardScaler()
X_test_poly_scaled = scaler.fit_transform(X_test_poly)
# 模型预测
y_test_pred30 = reg30.predict(X_test_poly_scaled)
# 画出样本的散点图
plt.scatter(x_test, y_test, marker='o', color='c', label='test dataset')
# 画出预测函数曲线
plt.plot(np.sort(x_test), y_test_pred30[np.argsort(x_test)], color='r', label='30 order')
plt.legend()
plt.xlabel('x')
plt.ylabel('y')
plt.show()
指标对比
# 计算MSE
mse1 = mean_squared_error(y_test_pred1, y_test)
mse3 = mean_squared_error(y_test_pred3, y_test)
mse10 = mean_squared_error(y_test_pred10, y_test)
mse30 = mean_squared_error(y_test_pred30, y_test)
# 打印结果
print('MSE:')
print('1 order polynomial: {:.2f}'.format(mse1))
print('3 order polynomial: {:.2f}'.format(mse3))
print('10 order polynomial: {:.2f}'.format(mse10))
print('30 order polynomial: {:.2f}'.format(mse30))
MSE:
1 order polynomial: 191.05
3 order polynomial: 39.71
10 order polynomial: 41.00
30 order polynomial: 85.45
测试集mse指标从好到坏的模型是:3阶多项式、10阶多项式、30阶多项式、1阶多项式。
欠拟合和过拟合
欠拟合(Underfitting):选择的模型过于简单,以致于模型对训练集和未知数据的预测都很差的现象。
过拟合(Overfitting):选择的模型过于复杂(所包含的参数过多),以致于模型对训练集的预测很好,但对未知数据预测很差的现象(泛化能力差)。
过拟合常见解决方法
增加训练样本数目
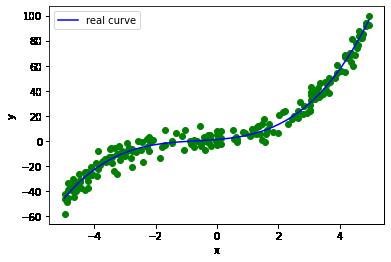
生成200个训练样本
# 设置随机种子
np.random.seed(34)
sample_num = 200
# 从-10到10中随机抽取200个浮点数
x_train = np.random.uniform(-10, 10, size=sample_num)
# 将x从shape为(sample_num,)变为(sample_num,1)
X_train = x_train.reshape(-1,1)
# 生成y值的实际函数
y_train_real = 0.5 * x_train ** 3 + x_train ** 2 + 2 * x_train + 1
# 生成误差值
err_train = np.random.normal(0, 5, size=sample_num)
# 真实y值加上误差值,得到样本的y值
y_train = y_train_real + err_train
# 画出样本的散点图
plt.scatter(x_train, y_train, marker='o', color='g')
# 画出实际函数曲线
plt.plot(np.sort(x_train), y_train_real[np.argsort(x_train)], color='b', label='real curve')
plt.legend()
plt.xlabel('x')
plt.ylabel('y')
plt.show()
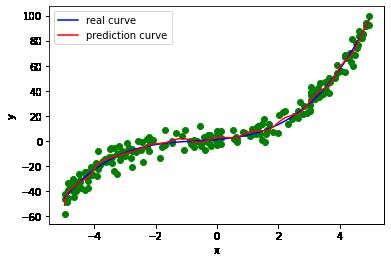
30阶多项式模型训练
# 生成多项式数据
poly = PolynomialFeatures(degree=30, include_bias=False)
X_train_poly = poly.fit_transform(X_train)
# 数据标准化(减均值除标准差)
scaler = StandardScaler()
X_train_poly_scaled = scaler.fit_transform(X_train_poly)
# 线性回归模型训练
reg30 = LinearRegression()
reg30.fit(X_train_poly_scaled, y_train)
# 模型预测
y_train_pred30 = reg30.predict(X_train_poly_scaled)
# 画出样本的散点图
plt.scatter(x_train, y_train, marker='o', color='g')
# 画出实际函数曲线
plt.plot(np.sort(x_train), y_train_real[np.argsort(x_train)], color='b', label='real curve')
# 画出预测函数曲线
plt.plot(np.sort(x_train), y_train_pred30[np.argsort(x_train)], color='r', label='prediction curve')
plt.legend()
plt.xlabel('x')
plt.ylabel('y')
plt.show()
# 计算MSE
mse = mean_squared_error(y_train_pred30, y_train)
print('MSE: {}'.format(mse))
MSE: 24.924693781595153
30阶多项式模型预测
# 生成多项式数据
poly = PolynomialFeatures(degree=30, include_bias=False)
X_test_poly = poly.fit_transform(X_test)
# 数据标准化(减均值除标准差)
scaler = StandardScaler()
X_test_poly_scaled = scaler.fit_transform(X_test_poly)
# 模型预测
y_test_pred30 = reg30.predict(X_test_poly_scaled)
# 画出样本的散点图
plt.scatter(x_test, y_test, marker='o', color='c', label='test dataset')
# 画出预测函数曲线
plt.plot(np.sort(x_test), y_test_pred30[np.argsort(x_test)], color='r', label='30 order')
plt.legend()
plt.xlabel('x')
plt.ylabel('y')
plt.show()
计算MSE
mse30 = mean_squared_error(y_test_pred30, y_test)
# 打印结果
print('MSE:')
print('30 order polynomial: {:.2f}'以上是关于三欠拟合和过拟合的主要内容,如果未能解决你的问题,请参考以下文章