图解 | 深入理解高性能网络开发路上的绊脚石 - 同步阻塞网络 IO
Posted C语言与CPP编程
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了图解 | 深入理解高性能网络开发路上的绊脚石 - 同步阻塞网络 IO相关的知识,希望对你有一定的参考价值。

在网络开发模型中,有一种非常易于开发同学使用的方式,那就是同步阻塞的网络 IO(在 Java 中习惯叫 BIO)。
例如我们想请求服务器上的一段数据,那么 C 语言的一段代码 demo 大概是下面这样:
int main()
{
int sk = socket(AF_INET, SOCK_STREAM, 0);
connect(sk, ...)
recv(sk, ...)
}
但是在高并发的服务器开发中,这种网络 IO 的性能奇差。因为
1.进程在 recv 的时候大概率会被阻塞掉,导致一次进程切换
2.当连接上数据就绪的时候进程又会被唤醒,又是一次进程切换
3.一个进程同时只能等待一条连接,如果有很多并发,则需要很多进程
如果用一句话来概括,那就是:同步阻塞网络 IO 是高性能网络开发路上的绊脚石! 俗话说得好,知己知彼方能百战百胜。所以我们今天先不讲优化,只深入分析同步阻塞网络 IO 的内部实现。
在上面的 demo 中虽然只是简单的两三行代码,但实际上用户进程和内核配合做了非常多的工作。先是用户进程发起创建 socket 的指令,然后切换到内核态完成了内核对象的初始化。接下来 Linux 在数据包的接收上,是硬中断和 ksoftirqd 进程在进行处理。当 ksoftirqd 进程处理完以后,再通知到相关的用户进程。
从用户进程创建 socket,到一个网络包抵达网卡到被用户进程接收到,总体上的流程图如下:

我们今天用图解加源码分析的方式来详细拆解一下上面的每一个步骤,来看一下在内核里是它们是怎么实现的。阅读完本文,你将深刻地理解在同步阻塞的网络 IO 性能低下的原因!
一、创建一个 socket
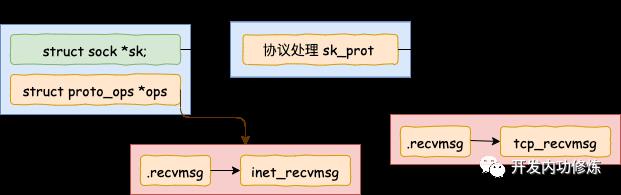
开篇源码中的 socket 函数调用执行完以后,内核在内部创建了一系列的 socket 相关的内核对象(是的,不是只有一个)。它们互相之间的关系如图。当然了,这个对象比图示的还要更复杂。我只在图中把和今天的主题相关的内容展现了出来。

我们来翻翻源码,看下上面的结构是如何被创造出来的。
//file:net/socket.c
SYSCALL_DEFINE3(socket, int, family, int, type, int, protocol)
{
......
retval = sock_create(family, type, protocol, &sock);
}
sock_create 是创建 socket 的主要位置。其中 sock_create 又调用了 __sock_create。
//file:net/socket.c
int __sock_create(struct net *net, int family, int type, int protocol,
struct socket **res, int kern)
{
struct socket *sock;
const struct net_proto_family *pf;
......
//分配 socket 对象
sock = sock_alloc();
//获得每个协议族的操作表
pf = rcu_dereference(net_families[family]);
//调用每个协议族的创建函数, 对于 AF_INET 对应的是
err = pf->create(net, sock, protocol, kern);
}
在 __sock_create 里,首先调用 sock_alloc 来分配一个 struct sock 对象。接着在获取协议族的操作函数表,并调用其 create 方法。对于 AF_INET 协议族来说,执行到的是 inet_create 方法。
//file:net/ipv4/af_inet.c
tatic int inet_create(struct net *net, struct socket *sock, int protocol,
int kern)
{
struct sock *sk;
//查找对应的协议,对于TCP SOCK_STREAM 就是获取到了
//static struct inet_protosw inetsw_array[] =
//{
// {
// .type = SOCK_STREAM,
// .protocol = IPPROTO_TCP,
// .prot = &tcp_prot,
// .ops = &inet_stream_ops,
// .no_check = 0,
// .flags = INET_PROTOSW_PERMANENT |
// INET_PROTOSW_ICSK,
// },
//}
list_for_each_entry_rcu(answer, &inetsw[sock->type], list) {
//将 inet_stream_ops 赋到 socket->ops 上
sock->ops = answer->ops;
//获得 tcp_prot
answer_prot = answer->prot;
//分配 sock 对象, 并把 tcp_prot 赋到 sock->sk_prot 上
sk = sk_alloc(net, PF_INET, GFP_KERNEL, answer_prot);
//对 sock 对象进行初始化
sock_init_data(sock, sk);
}
在 inet_create 中,根据类型 SOCK_STREAM 查找到对于 tcp 定义的操作方法实现集合 inet_stream_ops 和 tcp_prot。并把它们分别设置到 socket->ops 和 sock->sk_prot 上。

我们再往下看到了 sock_init_data。在这个方法中将 sock 中的 sk_data_ready 函数指针进行了初始化,设置为默认 sock_def_readable()。

//file: net/core/sock.c
void sock_init_data(struct socket *sock, struct sock *sk)
{
sk->sk_data_ready = sock_def_readable;
sk->sk_write_space = sock_def_write_space;
sk->sk_error_report = sock_def_error_report;
}
当软中断上收到数据包时会通过调用 sk_data_ready 函数指针(实际被设置成了 sock_def_readable()) 来唤醒在 sock 上等待的进程。这个咱们后面介绍软中断的时候再说,这里记住这个就行了。
至此,一个 tcp对象,确切地说是 AF_INET 协议族下 SOCK_STREAM对象就算是创建完成了。这里花费了一次 socket 系统调用的开销
二、等待接收消息
接着我们来看 recv 函数依赖的底层实现。首先通过 strace 命令跟踪,可以看到 clib 库函数 recv 会执行到 recvfrom 系统调用。
进入系统调用后,用户进程就进入到了内核态,通过执行一系列的内核协议层函数,然后到 socket 对象的接收队列中查看是否有数据,没有的话就把自己添加到 socket 对应的等待队列里。最后让出CPU,操作系统会选择下一个就绪状态的进程来执行。整个流程图如下:
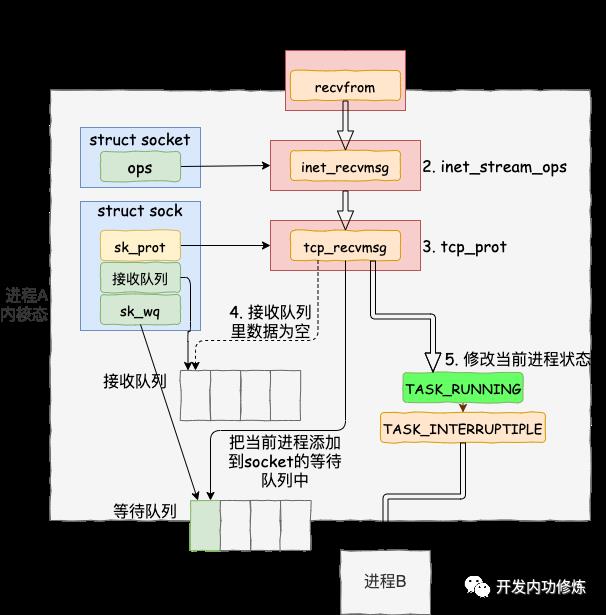
看完了整个流程图,接下来让我们根据源码来看更详细的细节。其中我们今天要关注的重点是 recvfrom 最后是怎么把自己的进程给阻塞掉的(假如我们没有使用 O_NONBLOCK 标记)。
//file: net/socket.c
SYSCALL_DEFINE6(recvfrom, int, fd, void __user *, ubuf, size_t, size,
unsigned int, flags, struct sockaddr __user *, addr,
int __user *, addr_len)
{
struct socket *sock;
//根据用户传入的 fd 找到 socket 对象
sock = sockfd_lookup_light(fd, &err, &fput_needed);
......
err = sock_recvmsg(sock, &msg, size, flags);
......
}
sock_recvmsg ==> __sock_recvmsg => __sock_recvmsg_nosec
static inline int __sock_recvmsg_nosec(struct kiocb *iocb, struct socket *sock,
struct msghdr *msg, size_t size, int flags)
{
......
return sock->ops->recvmsg(iocb, sock, msg, size, flags);
}
调用 socket 对象 ops 里的 recvmsg, 回忆我们上面的 socket 对象图,从图中可以看到 recvmsg 指向的是 inet_recvmsg 方法。
//file: net/ipv4/af_inet.c
int inet_recvmsg(struct kiocb *iocb, struct socket *sock, struct msghdr *msg,
size_t size, int flags)
{
...
err = sk->sk_prot->recvmsg(iocb, sk, msg, size, flags & MSG_DONTWAIT,
flags & ~MSG_DONTWAIT, &addr_len);
这里又遇到一个函数指针,这次调用的是 socket 对象里的 sk_prot 下面的 recvmsg方法。同上,得出这个 recvmsg 方法对应的是 tcp_recvmsg 方法。
//file: net/ipv4/tcp.c
int tcp_recvmsg(struct kiocb *iocb, struct sock *sk, struct msghdr *msg,
size_t len, int nonblock, int flags, int *addr_len)
{
int copied = 0;
...
do {
//遍历接收队列接收数据
skb_queue_walk(&sk->sk_receive_queue, skb) {
...
}
...
}
if (copied >= target) {
release_sock(sk);
lock_sock(sk);
} else //没有收到足够数据,启用 sk_wait_data 阻塞当前进程
sk_wait_data(sk, &timeo);
}
终于看到了我们想要看的东西,skb_queue_walk 是在访问 sock 对象下面的接收队列了。

如果没有收到数据,或者收到不足够多,则调用 sk_wait_data 把当前进程阻塞掉。
//file: net/core/sock.c
int sk_wait_data(struct sock *sk, long *timeo)
{
//当前进程(current)关联到所定义的等待队列项上
DEFINE_WAIT(wait);
// 调用 sk_sleep 获取 sock 对象下的 wait
// 并准备挂起,将进程状态设置为可打断 INTERRUPTIBLE
prepare_to_wait(sk_sleep(sk), &wait, TASK_INTERRUPTIBLE);
set_bit(SOCK_ASYNC_WAITDATA, &sk->sk_socket->flags);
// 通过调用schedule_timeout让出CPU,然后进行睡眠
rc = sk_wait_event(sk, timeo, !skb_queue_empty(&sk->sk_receive_queue));
...
我们再来详细看下 sk_wait_data 是怎么把当前进程给阻塞掉的。

首先在 DEFINE_WAIT 宏下,定义了一个等待队列项 wait。在这个新的等待队列项上,注册了回调函数 autoremove_wake_function,并把当前进程描述符 current 关联到其 .private成员上。
//file: include/linux/wait.h
#define DEFINE_WAIT(name) DEFINE_WAIT_FUNC(name, autoremove_wake_function)
#define DEFINE_WAIT_FUNC(name, function) \\
wait_queue_t name = { \\
.private = current, \\
.func = function, \\
.task_list = LIST_HEAD_INIT((name).task_list), \\
}
紧接着在 sk_wait_data 中 调用 sk_sleep 获取 sock 对象下的等待队列列表头 wait_queue_head_t。sk_sleep 源代码如下:
//file: include/net/sock.h
static inline wait_queue_head_t *sk_sleep(struct sock *sk)
{
BUILD_BUG_ON(offsetof(struct socket_wq, wait) != 0);
return &rcu_dereference_raw(sk->sk_wq)->wait;
}
接着调用 prepare_to_wait 来把新定义的等待队列项 wait 插入到 sock 对象的等待队列下。
//file: kernel/wait.c
void
prepare_to_wait(wait_queue_head_t *q, wait_queue_t *wait, int state)
{
unsigned long flags;
wait->flags &= ~WQ_FLAG_EXCLUSIVE;
spin_lock_irqsave(&q->lock, flags);
if (list_empty(&wait->task_list))
__add_wait_queue(q, wait);
set_current_state(state);
spin_unlock_irqrestore(&q->lock, flags);
}
这样后面当内核收完数据产生就绪时间的时候,就可以查找 socket 等待队列上的等待项,进而就可以找到回调函数和在等待该 socket 就绪事件的进程了。
最后再调用 sk_wait_event 让出 CPU,进程将进入睡眠状态,这会导致一次进程上下文的开销。
接下来的小节里我们将能看到进程是如何被唤醒的了。
三、软中断模块
接着我们再转换一下视角,来看负责接收和处理数据包的软中断这边。关于网络包到网卡后是怎么被网卡接收,最后在交由软中断处理的,这里就不多赘述了。感兴趣的请看之前的文章《图解Linux网络包接收过程》。我们今天直接从 tcp 协议的接收函数 tcp_v4_rcv 看起。

软中断(也就是 Linux 里的 ksoftirqd 进程)里收到数据包以后,发现是 tcp 的包的话就会执行到 tcp_v4_rcv 函数。接着走,如果是 ESTABLISH 状态下的数据包,则最终会把数据拆出来放到对应 socket 的接收队列中。然后调用 sk_data_ready 来唤醒用户进程。
我们看更详细一点的代码:
// file: net/ipv4/tcp_ipv4.c
int tcp_v4_rcv(struct sk_buff *skb)
{
......
th = tcp_hdr(skb); //获取tcp header
iph = ip_hdr(skb); //获取ip header
//根据数据包 header 中的 ip、端口信息查找到对应的socket
sk = __inet_lookup_skb(&tcp_hashinfo, skb, th->source, th->dest);
......
//socket 未被用户锁定
if (!sock_owned_by_user(sk)) {
{
if (!tcp_prequeue(sk, skb))
ret = tcp_v4_do_rcv(sk, skb);
}
}
}
在 tcp_v4_rcv 中首先根据收到的网络包的 header 里的 source 和 dest 信息来在本机上查询对应的 socket。找到以后,我们直接进入接收的主体函数 tcp_v4_do_rcv 来看。
//file: net/ipv4/tcp_ipv4.c
int tcp_v4_do_rcv(struct sock *sk, struct sk_buff *skb)
{
if (sk->sk_state == TCP_ESTABLISHED) {
//执行连接状态下的数据处理
if (tcp_rcv_established(sk, skb, tcp_hdr(skb), skb->len)) {
rsk = sk;
goto reset;
}
return 0;
}
//其它非 ESTABLISH 状态的数据包处理
......
}
我们假设处理的是 ESTABLISH 状态下的包,这样就又进入 tcp_rcv_established 函数中进行处理。
//file: net/ipv4/tcp_input.c
int tcp_rcv_established(struct sock *sk, struct sk_buff *skb,
const struct tcphdr *th, unsigned int len)
{
......
//接收数据到队列中
eaten = tcp_queue_rcv(sk, skb, tcp_header_len,
&fragstolen);
//数据 ready,唤醒 socket 上阻塞掉的进程
sk->sk_data_ready(sk, 0);
在 tcp_rcv_established 中通过调用 tcp_queue_rcv 函数中完成了将接收数据放到 socket 的接收队列上。

如下源码所示
//file: net/ipv4/tcp_input.c
static int __must_check tcp_queue_rcv(struct sock *sk, struct sk_buff *skb, int hdrlen,
bool *fragstolen)
{
//把接收到的数据放到 socket 的接收队列的尾部
if (!eaten) {
__skb_queue_tail(&sk->sk_receive_queue, skb);
skb_set_owner_r(skb, sk);
}
return eaten;
}
调用 tcp_queue_rcv 接收完成之后,接着再调用 sk_data_ready 来唤醒在socket上等待的用户进程。 这又是一个函数指针。回想上面我们在 创建 socket 流程里执行到的 sock_init_data 函数,在这个函数里已经把 sk_data_ready 设置成 sock_def_readable 函数了(可以ctrl + f 搜索前文)。它是默认的数据就绪处理函数。
//file: net/core/sock.c
static void sock_def_readable(struct sock *sk, int len)
{
struct socket_wq *wq;
rcu_read_lock();
wq = rcu_dereference(sk->sk_wq);
//有进程在此 socket 的等待队列
if (wq_has_sleeper(wq))
//唤醒等待队列上的进程
wake_up_interruptible_sync_poll(&wq->wait, POLLIN | POLLPRI |
POLLRDNORM | POLLRDBAND);
sk_wake_async(sk, SOCK_WAKE_WAITD, POLL_IN);
rcu_read_unlock();
}
在 sock_def_readable 中再一次访问到了 sock->sk_wq 下的wait。回忆下我们前面调用 recvfrom 执行的最后,通过 DEFINE_WAIT(wait) 将当前进程关联的等待队列添加到 sock->sk_wq 下的 wait 里了。
那接下来就是调用 wake_up_interruptible_sync_poll 来唤醒在 socket 上因为等待数据而被阻塞掉的进程了。

//file: include/linux/wait.h
#define wake_up_interruptible_sync_poll(x, m) \\
__wake_up_sync_key((x), TASK_INTERRUPTIBLE, 1, (void *) (m))
//file: kernel/sched/core.c
void __wake_up_sync_key(wait_queue_head_t *q, unsigned int mode,
int nr_exclusive, void *key)
{
unsigned long flags;
int wake_flags = WF_SYNC;
if (unlikely(!q))
return;
if (unlikely(!nr_exclusive))
wake_flags = 0;
spin_lock_irqsave(&q->lock, flags);
__wake_up_common(q, mode, nr_exclusive, wake_flags, key);
spin_unlock_irqrestore(&q->lock, flags);
}
__wake_up_common 实现唤醒。这里注意下, 该函数调用是参数 nr_exclusive 传入的是 1,这里指的是即使是有多个进程都阻塞在同一个 socket 上,也只唤醒 1 个进程。其作用是为了避免惊群。
//file: kernel/sched/core.c
static void __wake_up_common(wait_queue_head_t *q, unsigned int mode,
int nr_exclusive, int wake_flags, void *key)
{
wait_queue_t *curr, *next;
list_for_each_entry_safe(curr, next, &q->task_list, task_list) {
unsigned flags = curr->flags;
if (curr->func(curr, mode, wake_flags, key) &&
(flags & WQ_FLAG_EXCLUSIVE) && !--nr_exclusive)
break;
}
}
在 __wake_up_common 中找出一个等待队列项 curr,然后调用其 curr->func。回忆我们前面在 recv 函数执行的时候,使用 DEFINE_WAIT() 定义等待队列项的细节,内核把 curr->func 设置成了 autoremove_wake_function。
//file: include/linux/wait.h
#define DEFINE_WAIT(name) DEFINE_WAIT_FUNC(name, autoremove_wake_function)
#define DEFINE_WAIT_FUNC(name, function) \\
wait_queue_t name = { \\
.private = current, \\
.func = function, \\
.task_list = LIST_HEAD_INIT((name).task_list), \\
}
在 autoremove_wake_function 中,调用了 default_wake_function。
//file: kernel/sched/core.c
int default_wake_function(wait_queue_t *curr, unsigned mode, int wake_flags,
void *key)
{
return try_to_wake_up(curr->private, mode, wake_flags);
}
调用 try_to_wake_up 时传入的 task_struct 是 curr->private。这个就是当时因为等待而被阻塞的进程项。当这个函数执行完的时候,在 socket 上等待而被阻塞的进程就被推入到可运行队列里了,这又将是一次进程上下文切换的开销。
小结
好了,我们把上面的流程总结一下。内核在通知网络包的运行环境分两部分:
第一部分是我们自己代码所在的进程,我们调用的 socket() 函数会进入内核态创建必要内核对象。recv() 函数在进入内核态以后负责查看接收队列,以及在没有数据可处理的时候把当前进程阻塞掉,让出 CPU。
第二部分是硬中断、软中断上下文(系统进程 ksoftirqd)。在这些组件中,将包处理完后会放到 socket 的接收队列中。然后再根据 socket 内核对象找到其等待队列中正在因为等待而被阻塞掉的进程,然后把它唤醒。

每次一个进程专门为了等一个 socket 上的数据就得被从 CPU 上拿下来。然后再换上另一个进程。等到数据 ready 了,睡眠的进程又会被唤醒。总共两次进程上下文切换开销,根据之前的测试来看,每一次切换大约是 3-5 us(微秒)左右。如果是网络 IO 密集型的应用的话,CPU 就不停地做进程切换这种无用功。
在服务端角色上,这种模式完全没办法使用。因为这种简单模型里的 socket 和进程是一对一的。我们现在要在单台机器上承载成千上万,甚至十几、上百万的用户连接请求。如果用上面的方式,那就得为每个用户请求都创建一个进程。相信你在无论多原始的服务器网络编程里,都没见过有人这么干吧。
如果让我给它起一个名字的话,它就叫单路不复用(飞哥自创名词)。那么有没有更高效的网络 IO 模型呢?当然有,那就是你所熟知的 select、poll 和 epoll了。下次飞哥再开始拆解 epoll 的实现源码,敬请期待!
这种模式在客户端角色上,现在还存在使用的情形。因为你的进程可能确实得等 mysql 的数据返回成功之后,才能渲染页面返回给用户,否则啥也干不了。
注意一下,我说的是角色,不是具体的机器。例如对于你的 php/java/golang 接口机,你接收用户请求的时候,你是服务端角色。但当你再请求 redis 的时候,就变为客户端角色了。
不过现在有一些封装的很好的网络框架例如 Sogou Workflow,Golang 的 net 包等在网络客户端角色上也早已摒弃了这种低效的模式!

以上是关于图解 | 深入理解高性能网络开发路上的绊脚石 - 同步阻塞网络 IO的主要内容,如果未能解决你的问题,请参考以下文章