真正“搞”懂http协议01—背景故事
Posted Zaking
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了真正“搞”懂http协议01—背景故事相关的知识,希望对你有一定的参考价值。
去年读了《图解HTTP》、《图解TCP/IP》以及《图解网络硬件》但是读了之后并没有什么深刻的印象,只是有了一层模糊的脉络,刚好最近又接触了一些有关http的相关内容。所以,就打算把它写成一个系列,一方面可以让自己对http的理解更为深入。也可以为不懂不会http的同学在学习的路上先把荆棘剔除,以便学习的路更加的快速顺畅。
http是前后端沟通的桥梁,无论是前端还是后端,都是极为重要的基础知识。大多数前端开发只关注页面布局好不好,css简不简洁,js的可读性可复用性是不是还行,框架用的熟不熟练。但是我觉得像http这种基础知识是十分重要的。也是程序员生涯中无法回避的问题。
一、http含义
http的大名叫做超文本传输协议(HyperText Transfer Protocol),那么什么是超文本传输协议呢?我们先从字面意思来理解,就是传输“超文本”的协议。比方说A和B两个人,每个人手里都有一份文件叫做“超文本”,A按照“协议”把“超文本”文件“递给(传输)”B。这就是超文本传输协议的一个比较形象的说明。那么,A按照协议传递给B的是超文本,协议我们比较容易理解,就是一种规则嘛...我们在A和B之间传递“超文本”的时候要遵守这种规则。就像是你开车不能喝酒,酒驾被抓轻则扣分重则拘留。所以大家一定要注意开酒不喝车,喝车不开酒,至理名言啊。那么协议我们理解了,那什么是超文本呢?超文本就是超级文本!说的真有道理....哎呦...住手..不对...住脚...轻点踢...哎呦...确实是这样的。文本我们知道,可以解释为有图文内容的文件。那么超级文本(Hypertext)是啥子呢?嘿...这个就比较有意思了。超文本简单来说就是文本内容中有超链接(Hyperlink)的文本,你点击超链接就可以跳转到其它内容。这就是超文本了。超文本的格式有很多,目前最常用的就是超文本标记语言。唉?超文本标记语言?听着有点耳熟啊?超文本标记语言(HyperText Markup Language)。卧槽,就是html嘛?是的...没错。我们走了一小圈,绕到了这里。用一句话来解释HTTP就是,用来在网页(小A和小B)间传递(传输)HTML(超文本)的一种规则(协议)。
二、http从出生到现在
我们了解了http的名字是什么含义,就像是张全蛋、王二嘎这种名字也都是父母在起名时赋有深刻寓意在里面的。所以我们了解人家名字的含义更有助于我们了解其本身,还是十分必要的。那么我们再来看看http从出生到成长的人生历程。
1991年我们的http0.9版本终于诞生(发布),当然,在发布之前还必须“怀胎十月”,但是我们不去纠结人家是怎么怀上的,我们来纠结一下生下来之后都发生了什么。刚出生的http还比较年幼,好吧,废话了,谁出生的时候不年幼...所以它的能力还并不是很强。只有一个get技能,并且还只能传递html格式的字符串,比如今天的JSON啊,XML啊,TXT啊什么的。想都别想。毕竟我年纪还小啊。。。要求这么多。。。真是的。并且在0.9版本,每个http请求都是短链接(后面会具体介绍什么是短链接)。
时间飞逝,我们来到了1996年,此时在5年的时间中,http一边工作,一边成长,终于,http1.0版本产生了,我们的小朋友也长大了,有了更多的社会阅历和见解,随之而来的,它的能力也提升了不少。此时的http拥有了更多的技能,POST和HEAD。拥有了更多的功能,包括我们现在耳熟能详的状态码(status code)、缓存(cache)、重定向(redirect)、权限(authorization)等等一大堆的内容。此时的HTTP可以说成长为了一个可以支撑起一片天地的一家之主了。
时间继续慢慢悠悠的走,此时大概过了半年左右,http的成长极为迅速。在1997年初,http1.1发布了,此时的http技能更加的多,比如像OPTIONS,PUT, DELETE, TRACE, CONNECT等方法。要知道,http1.1是我们目前最为常用的http版本。
再简单说一下http2和https吧,其实大家可以发现,现在普遍的浏览器域名地址前的http都已经变为了https,简单来说,https就是http的安全版本,其实https就是加密数据过后的http,使网络传输的数据更加安全,而加密的过程实际上就是在七层网络模型中的表示层和会话层来完成的,而http2其实是为了适应当代浏览器及网络发展速度而产生的一个各方面性能都更好的http版本。
三、网络模型
我们的目的不是搞懂整个互联网络模型,而是在学习http前极为必要的“背景故事”之一,所以,我会简单介绍一下互联网络模型。咱们先来看张图:

图中左边的是五层网络模型,中间是七层网络模型,最右边是每一层的作用。实际上,七层网络模型不过是在应用层中又细分出了表示层和会话层。如果大家想要深入了解整个互联网模型的过程及具体的内容,大家可以去看一下阮一峰老师的互联网协议入门(一)。也可以自己取查找资料。这不是本系列的重点。要知道这是一个庞大的知识体系。
我们每一次发送的网络请求在客户端都是从上至下,到了服务器端再从下至上的一个过程。当然,从服务器返回到客户端的响应也是在服务器端从上至下,到客户端再从下至上的获取到。也就是说,哪里传输出去的,就是从应用层直到物理层,哪里接收的,就是从物理层直到应用层。
四、三次握手
在客户端与服务器发送http请求及返回响应的过程中,我们需要创建一个确保http可以传递的通道,也就是传输层所建立起来的tcp connection。在连接已经建立之后,我们才可以完成http的请求与响应。那么如何才能确定tcp connection已经创建了呢?那么就需要通过三次握手,来确定连接已经建立。我们来看张图,了解一下三次握手是如何工作的:
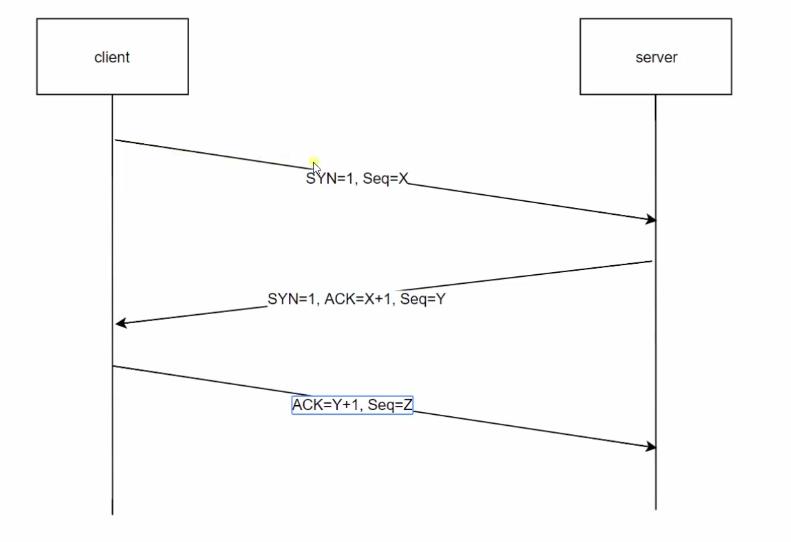
首先客户端发送一个数据包,包的内容是一个标志位syn和一个随机数seq,然后发送给服务器。这时候服务器知道了,噢这个客户端想要请求连接,那么就会返回一个新的数据包,同样的包括syn,并且再返回一个ack标志位,并在接收到的seq基础上+1作为ack的值返回,重新生成一个新的随机数seq传递给客户端,意思是我确实收到了这个请求。客户端此时收到了第二次返回的数据包,于是再告诉服务器我收到了你得信息,把计算后的ack和新生成的seq再传递给服务器。至此,三次握手完成,可以进行http请求了。
五、URI—URL、URN
在开始http真正的内容之前,我们还需要了解一下什么是uri、url以及urn。因为我们几乎所有的http请求都是通过url来完成的。所以我们有必要了解一下url相关的知识。
URI统一资源标志符(Uniform Resource Identifier),是一个用于标识某一互联网资源名称的字符串。
URL统一资源定位符(Uniform Resource Locator),如同在网络上的门牌,是因特网上标准的资源的地址。
URN统一资源名称(Uniform Resource Name),期望为资源提供持久的、位置无关的标识方式,并允许简单地将多个命名空间映射到单个URN命名空间。
其实URL和URN是URI的子集,我们看一张图,图片来源维基百科相关条目:

URN我们并不常见,做个了解就行了。
六、报文格式
我们先来看一张图,这张图是我在网上随便找的一个http请求的截图:
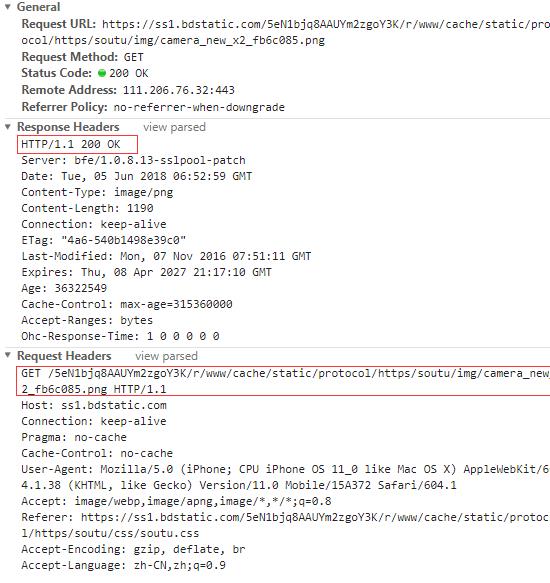
大家可以自己打开浏览器的f12,在netwrok随便找一个请求看一下, 那么这是所有的“请求”信息。包括通用信息(general)以及请求头(request header)和响应头(response header)。但是可能你看到的跟我截图中的不一样。这是因为浏览器为我们做了格式化,让我们可以更快速的获取到想要的信息。你点一下下图中的按钮,就可以看到source信息,而不是parsed后的信息了。

第一张图中的红框部分,就是我们的起始行,在view parsed的时候,我们的浏览器把起始行省略掉了,只留下了报文首部,也就是红框外的其它部分。除了起始行和首部外还有一个主体,就是我们服务器返回的响应的内容,我们可以在preview中查看格式化后的主体内容。

上面的内容讲解的都十分基础,没有深入的去探索,但是对于我们接下来学习http是足够且必要的前提。如果大家想要深入了解其中的每一项内容,可以自行查找资料。网络上有关的内容还是相当多的。那么,本文到这里就结束了,下面会开始http的正式内容。还望大家准时搬好小板凳,不要迟到噢。
最后,由于本人水平有限,能力与大神仍相差甚远,若有错误或不明之处,还望大家不吝赐教指正。非常感谢!
以上是关于真正“搞”懂http协议01—背景故事的主要内容,如果未能解决你的问题,请参考以下文章