递归分类最佳实践:如何在强化学习中用示例代替奖励
Posted TensorFlow 社区
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了递归分类最佳实践:如何在强化学习中用示例代替奖励相关的知识,希望对你有一定的参考价值。

发布人:Google Research 学生研究员 Benjamin Eysenbach
机器人研究的总体目标是设计出这样的系统:能够协助人类完成各种可以改善日常生活的任务。大多数用于教导智能体执行新任务的强化学习算法都需要使用奖励函数 (Reward Function)。该函数在智能体采取的行动可以带来良好结果时,会向智能体提供正向反馈。
然而,在实际当中,这些奖励函数的指定过程相当繁琐,并且在没有明确目标的情况下非常难以定义,例如房间是否干净或门是否关得够严实。即使是容易描述的任务,要去实际衡量其完成情况也很困难,可能需要在机器人环境中添加许多传感器。
另一种做法是使用示例训练模型,即所谓的基于示例的控制 (Example-Based Control),这种方法有可能克服依赖传统奖励函数之方法的局限性。这一新问题的陈述与之前基于“成功检测器”的方法最为相似,非专业用户即使不具备编码专业知识、不了解奖励函数设计或未安装环境传感器,也可利用基于示例控制的高效算法,教会机器人执行新任务。
在《用示例代替奖励:通过递归分类实现基于示例的策略搜索》(Replacing Rewards with Examples: Example-Based Policy Search via Recursive Classification) 一文中,我们提出一种机器学习算法,通过提供成功示例,教导智能体如何完成新任务(例如,如果“成功”示例显示钉子嵌入墙内,则智能体将学会拿起锤子将钉子敲进墙内)。这种算法,即递归示例分类 (Recursive Classification of Examples, RCE),不依赖于手动创建的奖励函数、距离函数或特征,而是直接从数据中学习完成任务,这就要求智能体在无需任何中间状态示例的情况下,学习如何独立完成整个任务。RCE 使用的是时序差分学习版本(与 Q-learning 类似,但仅使用成功示例,以代替典型的奖励函数项),在模拟机器人任务方面的表现优于之前基于模仿学习的方法。再加上与基于奖励的学习方法相似的理论保证,我们所提出的方法为教导机器人执行新任务提供了一种方便用户使用的替代选择。
-
用示例代替奖励:通过递归分类实现基于示例的策略搜索
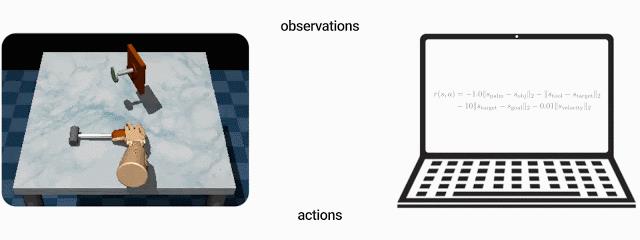
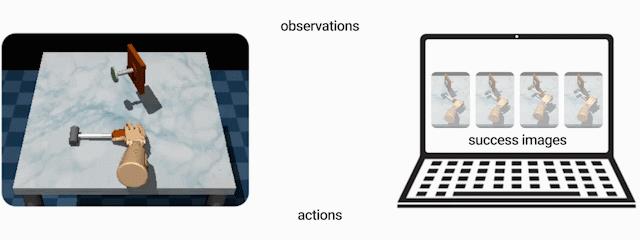
上图:为了教机器人将钉子敲进墙内,大多数强化学习算法都需要用户定义奖励函数。下图:基于示例的控制方法使用完成任务后的情况示例(例如,已将钉子敲进墙内的示例)来教机器人完成任务
基于示例的控制对比模仿学习
虽然基于示例的控制方法与模仿学习类似,但两者之间有一个重要区别,即前者无需专家演示。事实上,只要用户事后回顾,挑出碰巧完成任务的一小部分状态,就会发现其实自己执行任务时的表现相当糟糕。
此外,先前的研究采用的是阶段性方法,即模型首先使用成功示例学习奖励函数,然后使用现成的强化学习算法应用该奖励函数,而 RCE 则是直接从示例中学习,跳过了定义奖励函数的中间步骤。这样便可避免潜在的错误,绕过定义与学习奖励函数相关的超参数(如更新奖励函数的频率或正则化奖励函数的方式)的过程,并且在调试时,无需检查与学习奖励函数相关的代码。
递归示例分类
RCE 方法背后的理念很简单:给定当前的环境状况以及智能体正在采取的行动后,模型应能预测到智能体将来能否完成任务。如果有数据可以分别指定会导致将来成功和失败的状态-行动对,则用户可以使用标准的监督式学习解决此问题。然而,当仅有的可用数据包含成功示例时,系统就无从分辨导致成功的状态和行动,虽然系统也有与环境交互的经验,但这种经验并未被标记为能否带来成功。
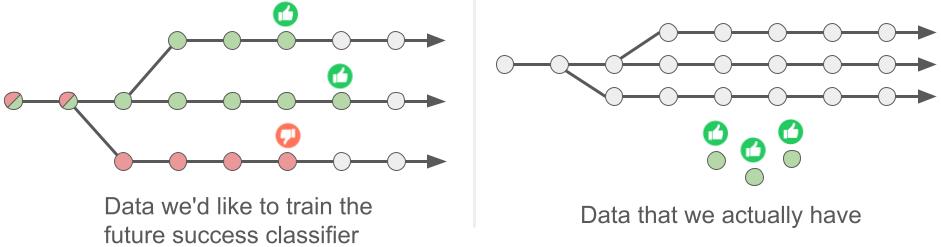
左图:关键理念是学习将来成功与否的分类器,针对轨迹中的每一种状态(圆圈),预测将来完成任务的成(拇指向上)与败(拇指向下)。右图:在基于示例的控制方法中,我们仅为模型提供了未标记的经验(灰色圆圈)和成功示例(绿色圆圈),因此用户无法应用标准监督式学习。相反,模型会使用成功示例来自动标记未标记的经验
尽管如此,如果有数据的话,用户可以拼凑出这些数据的样貌。首先,根据定义,成功的示例必须能够完成给定任务。其次,即使不知道任意一个状态-行动对能否成功完成任务,但如果智能体从下一个状态开始执行任务,则有可能预估完成任务的可能性。如果下一个状态有可能导致将来的成功,则可以假设当前状态也有可能导致将来的成功。实际上,这就是递归分类(Recursive Classification),即根据下一个时间步长的预测来推断标记。
使用模型对将来时间步长的预测作为当前时间步长的标记这一基本算法理念与现有的时序差分方法(如 Q-learning 和后继特征)非常相似。主要区别在于,此处介绍的方法无需使用奖励函数。尽管如此,我们证明了该方法会延续许多与时序差分方法相同的理论收敛性保证。在实践中,如想实现 RCE,只需更改现有 Q-learning 实现中的几行代码即可。
评估
我们针对一系列具有挑战性的机器人操作任务评估了 RCE 方法。例如,在一项任务中,我们要求机械手拿起锤子,将钉子敲进木板。针对该任务的先前研究[1、2] 使用了复杂的奖励函数(手与锤子之间的距离、锤子与钉子之间的距离,以及钉子是否已敲入木板都有对应的项)。相比之下,RCE 方法仅需要观察将钉子敲进木板后的情况。
我们将 RCE 与之前的一些方法(包括那些学习明确奖励函数的方法和基于模仿学习的方法,所有这些方法都难以完成该任务)在性能方面进行了比较。该实验重点介绍了用户如何利用基于示例的控制轻松指定任务,哪怕是复杂的任务,并证明了递归分类可以成功完成此类任务。
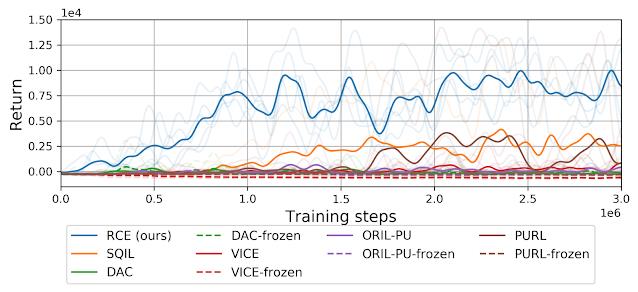
与之前的方法相比,RCE 方法比基于模仿学习的方法 [SQIL、DAC] 和学习明确奖励函数的方法 [VICE、ORIL、PURL] 更可靠地完成了将钉子敲进木板的任务
-
VICE
-
ORIL
-
PURL
结论
我们提供了一种方法,通过向自主智能体提供成功示例,教导其执行任务,而非精心设计奖励函数或收集第一人称演示。本文所讨论的基于示例控制的一个重要方面就是系统针对不同用户的能力所作的假设。设计出对用户能力差异具有鲁棒性的 RCE 变体,对于现实世界机器人技术的应用可能很重要。本研究代码可供下载,项目网站也将提供有关所学行为的其他视频。
-
第一人称演示
https://sites.google.com/corp/view/efficient-robotic-manipulation
-
本研究代码可供下载
https://github.com/google-research/google-research/tree/master/rce
-
项目网站
致谢
本研究系与 Ruslan Salakhutdinov 和 Sergey Levine 合作完成,在此表示感谢。此外,我们还要感谢 Surya Bhupatiraju、Kamyar Ghasemipour、Max Igl 和 Harini Kannan 对本文提出的反馈意见,以及 Tom Small 对本文图表设计提供的帮助。
想深入了解机器学习算法或更多最新研究,请扫描下方二维码关注 TensorFlow 官方公众号。机器学习路上,我们共同进步。

以上是关于递归分类最佳实践:如何在强化学习中用示例代替奖励的主要内容,如果未能解决你的问题,请参考以下文章
KNN(K Nearest Neighbors)分类是什么学习方法?如何或者最佳的K值?RadiusneighborsClassifer分类器又是什么?KNN进行分类详解及实践