Day14:项目需求与技术架构
Posted 保护胖丁
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Day14:项目需求与技术架构相关的知识,希望对你有一定的参考价值。
知识点01:回顾
-
case when函数的功能及语法?
- 功能:实现多条件的判断逻辑
- 语法
- case col when ……
- case when col = value
- if(条件,true的结果,false的结果):单条件的判断
- 多条件:if(条件1,if(条件2,true,false),false)
-
concat与concat_ws函数的功能与语法?
- 功能:实现字符串拼接
- 语法
- concat(str1,str2……)
- concat_ws(分隔符,str1,str2……)
-
collect_set与collect_list的功能与语法?
- 功能:将某一列的多行的内容合并为一行
- 语法
- collect_set(colname)
- collect_list (colname)
-
Json处理的函数有哪些?
- 方式一:函数
- get_json_object:用于取某一个JSON字符串中的某一个元素,$.元素名
- json_tuple:一次性取多个元素
- 方式二:JSONSerde
- 方式一:函数
-
窗口函数的语法及关键字的含义是什么?
-
语法
funName(参数) over (partition by col [order by col ] [window_size]) -
关键字
- partition by:分区,将相同分区的数据放在一起
- order by:排序,基于每个分区内部的排序
- window_size:指定计算的窗口
- 指定了分区和排序:默认窗口为从第一行到当前行
- 指定了分区:默认窗口从第一行到最后一行
-
窗口聚合函数:sum/count/min/max/avg
-
-
first_value和last_value的功能及语法?
- first_value(col):用于取分区内部的第一条数据
- last_value(col):用于取分区内部的最后一条数据
- 注意使用的默认窗口
-
lag和lead的功能及语法?
- lag(colName,N,default):向前偏移
- lead(colName,N,default):向后偏移
-
MapReduce可以做哪些优化?Hive中可以做哪些参数优化?
- MapReduce优化
- 推测执行
- JVM重用
- Hive中优化
- Fetch Task
- 严格模式
- 并行执行
- 压缩
- MapReduce优化
-
常见的文件格式有哪些?列式存储的优点是什么?
- 文件格式
- 默认:textfile
- 二进制:SequenceFile
- 列式存储:rcfile、orc、parquet
- 优点
- 占用的存储空间更小
- 对列的处理,性能更好
- 构建文件索引
- 文件格式
-
数据倾斜的现象和原因是什么,哪些场景下会产生数据倾斜以及怎么解决?
- 现象:一个程序,有个别的Task一直在运行,其他的Task都运行结束了,任务进度卡在99或者100%出现了数据倾斜
- 原因:这个Task的负载比较高,数据分配不均衡,分配规则的问题
- 场景:group by / join
- 解决
- group by
- 开启Combiner
- 构建随机分区
- 自动:开启skewindata参数
- 手动:distribute by rand()
- join
- 避免产生Reduce Join
- group by
知识点02:目标
- 整体内容
- 大数据业务
- 大数据的实际应用场景:大数据在各行各业中解决了什么问题?
- 大数据平台的业务流程:数据从产生到应用要经过哪些流程?
- 大数据平台的技术架构:大数据的技术有哪些?大数据平台架是什么样的?
- 了解大数据平台部署方案
- 手动分发安装
- 集群管理工具安装
- 集群管理工具怎么使用
- 大数据业务
- 重点内容
- 掌握在线教育平台的大数据业务需求
- 掌握在线教育平台的大数据技术架构
- 项目环境测试
- 掌握常见的数据源以及用户行为日志的生成过程、数据的内容
知识点03:大数据业务需求
-
目标:了解常见大数据平台的业务需求
-
实施
- 大数据业务需求本质
- 本质:利用大数据软件工具对数据进行处理,从数据中挖掘价值,让公司挣更多的钱
- 功能:辅助发现公司、产品或者运营层面存在的问题,解析问题,提高服务质量,促进决策
- 使用:运营人员、决策人员
- 大数据开发工程师:处理数据
- 流程
- 分析数据,发现问题,解决问题,提供更好的服务
- 实现
- 大公司:一般会自动搭建平台
- 小公司:商业化大数据平台
- 百度统计
- 友盟
- 神策
- 易分析
- 数据分析:基于公司的所有数据,对数据的内容进行分析,发现问题,提供决策性的支持
- 运营分析:分析广告投放效果,决定下次投放比例
- 订单分析:分析订单总成交额、订单笔数,分析订单的产生情况
- 用户分析:分析新增用户、总用户、留存用户、流失用户、活跃用户
- 分析用户属性:性别、年龄、收入、家庭成员、家庭住址
- 商品分析:分析热门商品、访问量Top10、商品地区分布、商品库存分配
- 访问分析:分析用户访问分类、访问商品
- 来源分析:分析用户来源:搜索引擎、输入网址、广告
- 转化分析:用户的每个步骤的转化率
- 访问
- 搜索
- 浏览
- 添加购物车
- 下订单
- 支付
- 推荐系统:基于用户分析构建用户画像,实现精准推荐
- 商品推荐:根据用户的喜好,主送为用户推荐适合于这个用户的商品
- 视频推荐:根据用户的习惯、用户的属性来推荐合适的视频
- 广告推荐:精准广告营销
- 风控系统
- 金融风控:征信风控,避免坏账
- 系统风控:用于监控一些恶意网站攻击,及时发现以及屏蔽IP
- 刷单风控:分析整个订单的流程是否是刷单流程
- 机器学习
- 人脸识别
- 无人驾驶
- 智能设备
- 大数据业务需求本质
-
小结
- 了解常见的大数据平台业务需求
知识点04:在线教育项目需求
-
目标:掌握在线教育项目需求
-
实施
-
行业:线上教育行业
-
产品:课程
-
目标:实现用户的转化运营分析,提高转化率,实现用户的学习管理分析,提高学习效率
- 让更多人买产品
- 让用户得到好的结果
-
业务流程
- 访问咨询课程、购买课程、学习课程
- step1:采集所有用户产生的数据
- step2:分析每一步用户的访问、咨询、报名的情况、学员的考勤、考试情况
- step3:通过分析的结果来反映产品的好坏,发现产品的问题,发现管理中的问题
- step4:解决这些问题,提高报名率,加强学员学习效果
-
整体需求
- step1:访问
- 访问官网,了解公司、课程和产品的信息
- step2:咨询
- 详细了解课程信息,留下联系方式
- 分析为什么咨询率比较低
- 网站本身的问题:产品的介绍不吸引人、网站看着不可靠
- step3:意向
- 销售会联系用户,明确报名的意向
- step4:报名
- 最终转化为一个报名用户
- 分析为什么报名率比较低
- 产品的内容不符合
- 价格定位太高
- 销售转化的问题
- step5:学习
- 考勤管理
- 考试管理
- ……
- step1:访问
-
项目需求
- 需求1:实现不同维度下的用户转化率分析
- 访问转咨询率 = 咨询人数 / 访问人数
- 意向转报名率 = 报名人数 / 意向人数
- 需求2:实现不同维度下的学员考勤指标分析
- 出勤率、迟到率、请假率、旷课率
- 需求1:实现不同维度下的用户转化率分析
-
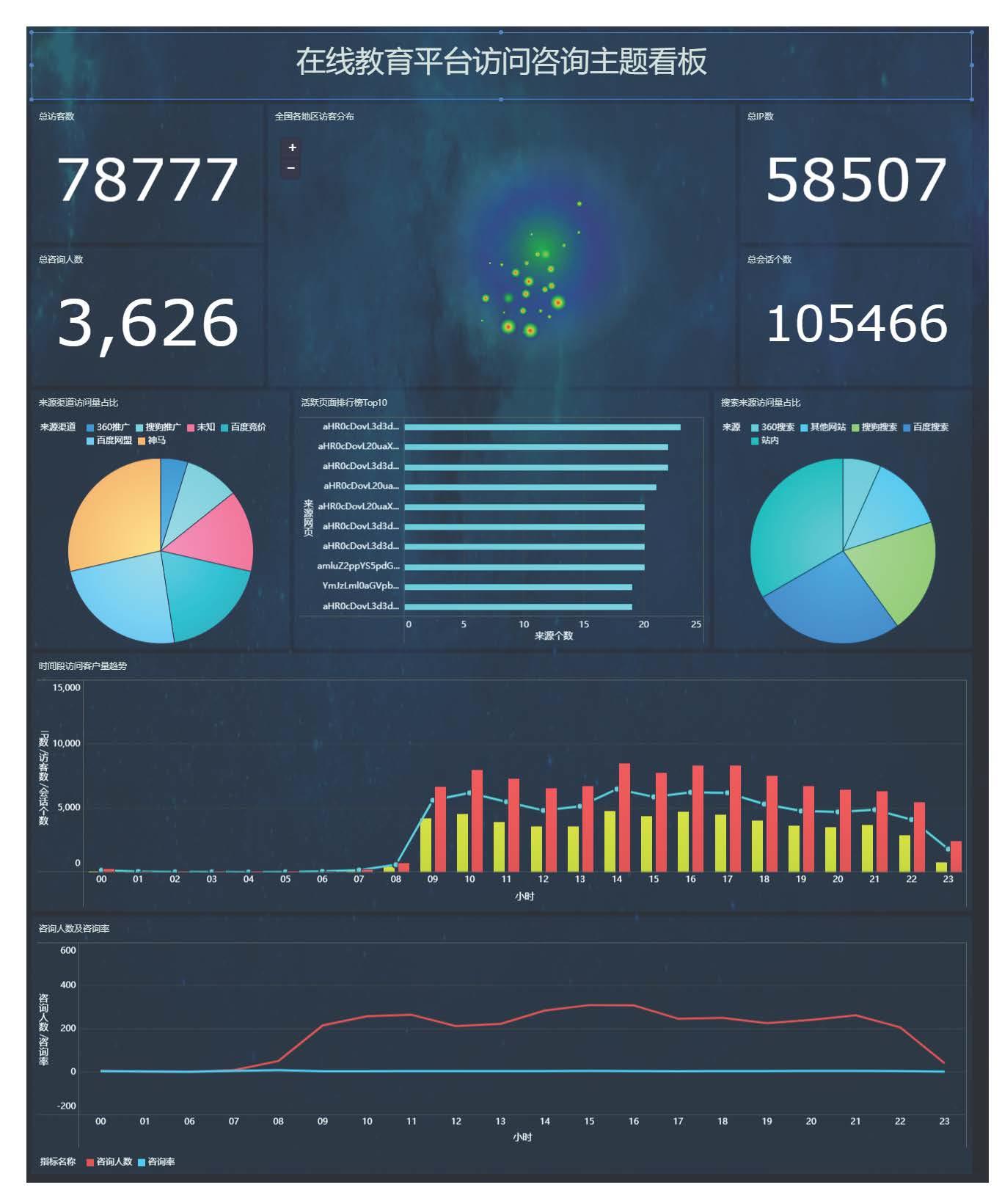
项目看板模块
- 访问咨询模块:访问人数、访问IP数、咨询人数、咨询IP数、咨询率
- 意向分析模块:意向人数
- 报名分析模块:报名人数
- 学员考勤模块:出勤率、迟到率
-
项目效果
-
-
小结
- 在线教育项目中的需求和模块是什么?
- 需求
- step1:统计不同维度下的转化率分析
- 访问转咨询率
- 意向转报名率
- step2:统计不同维度下的考勤分析
- 出勤率、迟到率、请假率、旷课率
- 模块
- 访问与咨询
- 意向分析
- 报名分析
- 考勤分析
- step1:统计不同维度下的转化率分析
知识点05:业务流程:数据来源
-
目标:了解常见的数据来源
-
实施
- 业务数据
- 由业务系统生成的数据:存储在业务数据库中
- 用户数据、商品数据、订单数据
- 用户行为数据
- 用户在网站上所有的操作记录下的数据信息
- 注册、登陆、访问页面、收藏、提交订单、添加购物车、支付、搜索
- 爬虫数据
- 根据需求爬取互联网上与实际分析业务相关的数据
- 运维日志
- 机器、程序运行日志,辅助运维做分析的
- 第三方数据
- 合作方的数据
- 购买的数据
- 业务数据
-
小结
- 了解常见的数据来源即可
知识点06:业务流程:数据采集及存储
-
目标:了解数据采集及数据的存储过程
-
实施
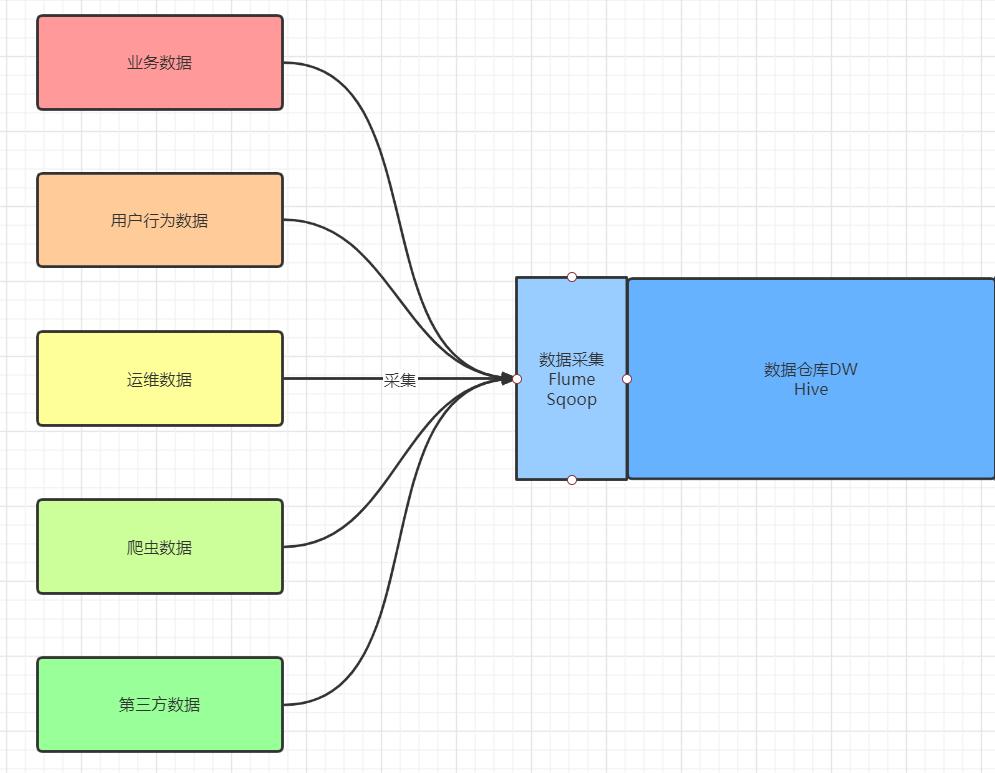
- 数据采集
- 本质:将各种各样的数据源统一的采集到大数据存储平台
- 实现:通过不同的工具对不同的数据源进行采集
- 工具:Flume、Sqoop
- 模式
- 全量:每次采集所有数据
- 增量:每次采集更新数据
- 数据存储
- 本质:将各种各样的数据源进行统一化的存储:数据仓库
- 实现:通过数据仓库来统一化存储和转换,提供应用
- 工具:Hive
- 数据采集
-
小结
- 了解数据采集及数据的存储过程
知识点07:业务流程:数据处理及应用
-
目标:了解数据处理及数据的应用过程
-
实施
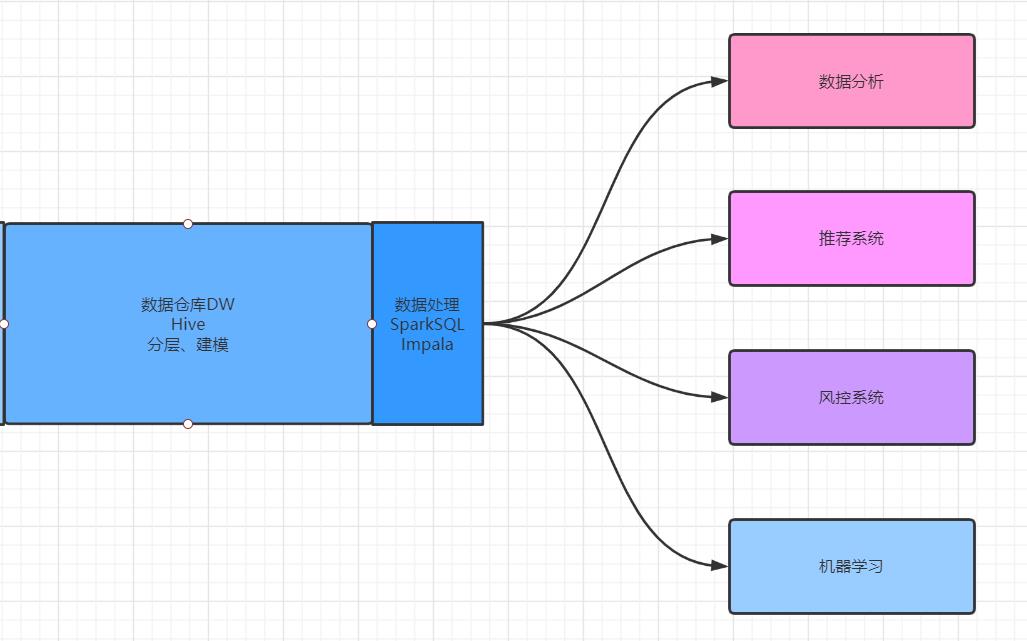
- 数据处理
- 本质:基于不同的数据对数据仓库中的数据进行处理分析,得到处理的结果
- 实现:通过分布式计算来读取数据仓库中的数据进行处理、
- 工具:Hive、Impala、SparkSQL
- 流程
- 分层
- 建模
- 计算
- 数据应用
- 本质:将计算好的结果应用在实际的业务需求中
- 实现
- 数据分析报表、用户画像、推荐系统、风控系统
- 数据处理
-
整体流程
- 数据生成:由应用层开发者实现
- 数据采集
- 数据存储:数据仓库
- 数据处理
- 数据应用
-
小结
- 了解数据处理及数据的应用过程
知识点08:技术架构:常用技术选型
-
目标:了解大数据平台的常用技术选型
-
实施
- 数据采集
- Flume、Sqoop、Logstash、Beats、Canal
- 每种数据源的存储不一样:数据库、文件
- 每种工具的应用场景不一样:实时采集、离线采集
- 数据存储
- HDFS:分布式大数据离线文件系统
- Hbase:分布式大数据实时NoSQL数据库【内存+HDFS】
- Kafka:分布式大数据实时消息队列系统
- Redis:分布式基于内存NoSQL数据库
- ElasticSearch:分布式全文索引工具
- mysql:关系统数据库,一般存储分析处理的结果
- 数据处理
- MapReduce:离线的分布式批处理
- Spark:全场景的分布式计算平台
- SparkCore:离线批处理
- SparkSQL:基于SQL批处理
- SparkStreaming / StructStreaming :实时计算
- Spark MLlib:机器学习库
- Flink:实时计算平台
- 实时计算:Java、Scala、SQL
- 用实时代替离线
- Impala、Kylin、Drill
- 其他工具
- 分布式协调服务:Zookeeper
- 分布式调度工具:Oozie、Azkaban、AirFlow、Zeus
- 可视化交互客户端:Hue
- 集群管理平台:ClouderaManager
- 可视化报表平台:FineBi
- 数据采集
-
小结
- 了解大数据平台的常用技术选型
知识点09:技术架构:基础平台架构
-
目标:了解大数据的基础平台架构
-
实施
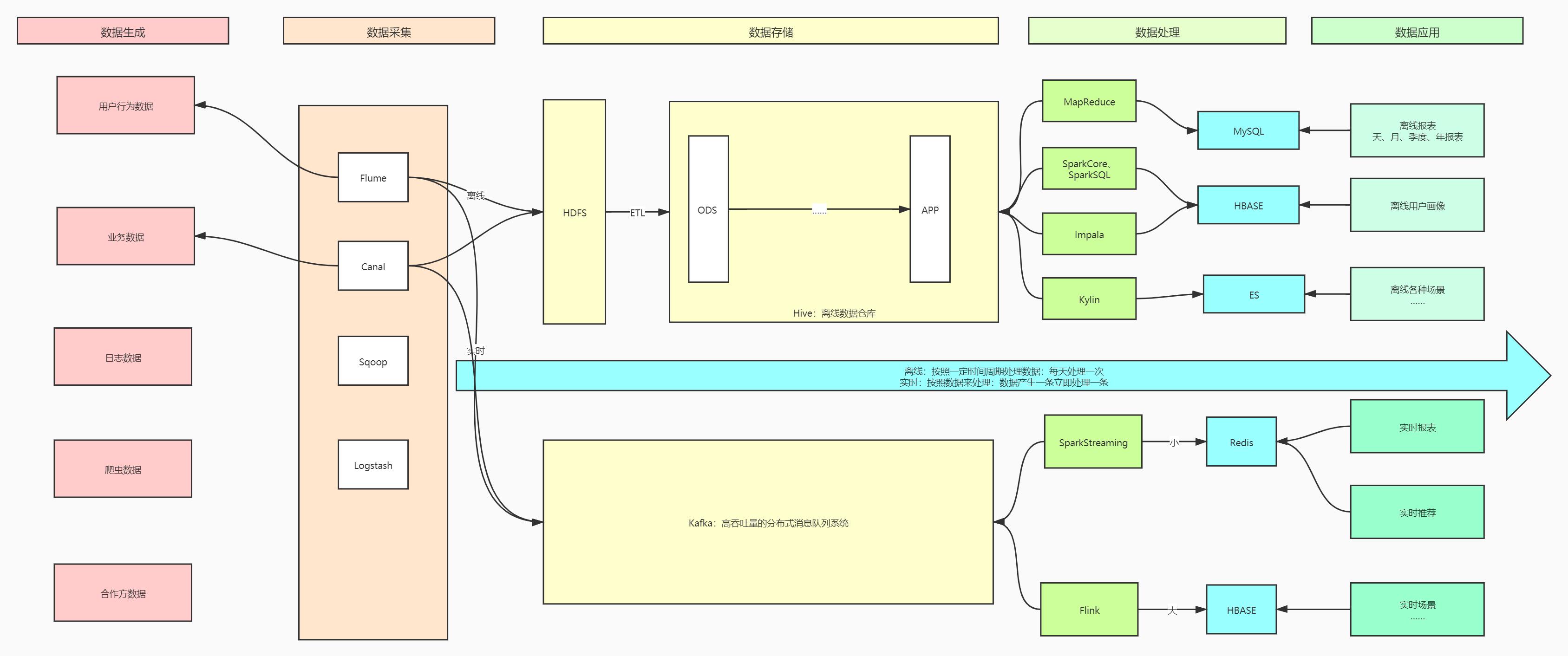
- Lambda架构:离线和实时是两套架构
-
Kappa架构:只有一套实时架构,用实时代替离线
-
小结
- 了解大数据的基础平台架构
知识点10:技术架构:在线教育项目架构
-
目标:掌握在线教育项目架构
-
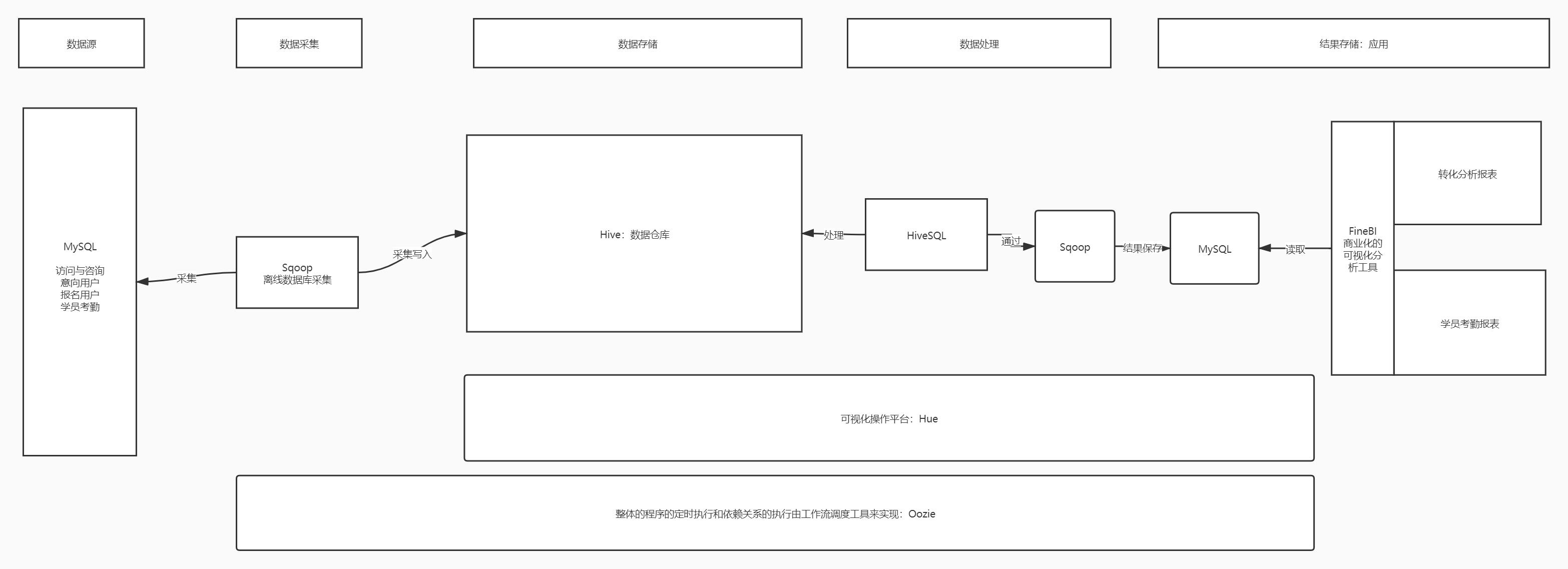
实施
- 要求:必须要自己画出项目架构图
- 数据生成:业务系统
- 用户访问与咨询数据:客服系统:数据库
- 意向与报名数据:CRM系统:数据库
- 学员考勤数据:学员管理系统:数据库
- MySQL
- 数据采集
- Sqoop:基于MapReduce的一个数据采集的工具
- 实现将MySQL数据库的数据与HDFS之间的数据实现导入与导出
- Sqoop:基于MapReduce的一个数据采集的工具
- 数据存储
- Hive数据仓库:存储HDFS
- 数据处理
- 分析处理:HiveSQL:MapReduce
- 结果保存:MySQL
- 数据应用
- 报表:FineBI
- 任务调度
- Oozie:实现所有程序自动化运行
- 可视化交互
- Hue:可视化开发Hive、O瓯子额
- 集群管理
- Cloudera Manager
- 讲解这个东西的功能和基本的使用:项目中我们不用
-
小结
- 整个项目架构中使用到了哪些技术?
- 数据生成:MySQL
- 数据采集:Sqoop
- 数据存储:HIve
- 数据计算:Hive:MapReduce
- 数据应用
- 结果:MySQL
- 报表:FineBi
- 可视化开发:Hue
- 调度工具:Oozie
- 集群管理:Cloudera Manager
知识点11:平台搭建:命令行部署
-
目标:了解大数据平台命令行部署方式的优缺点
-
实施
- 过程
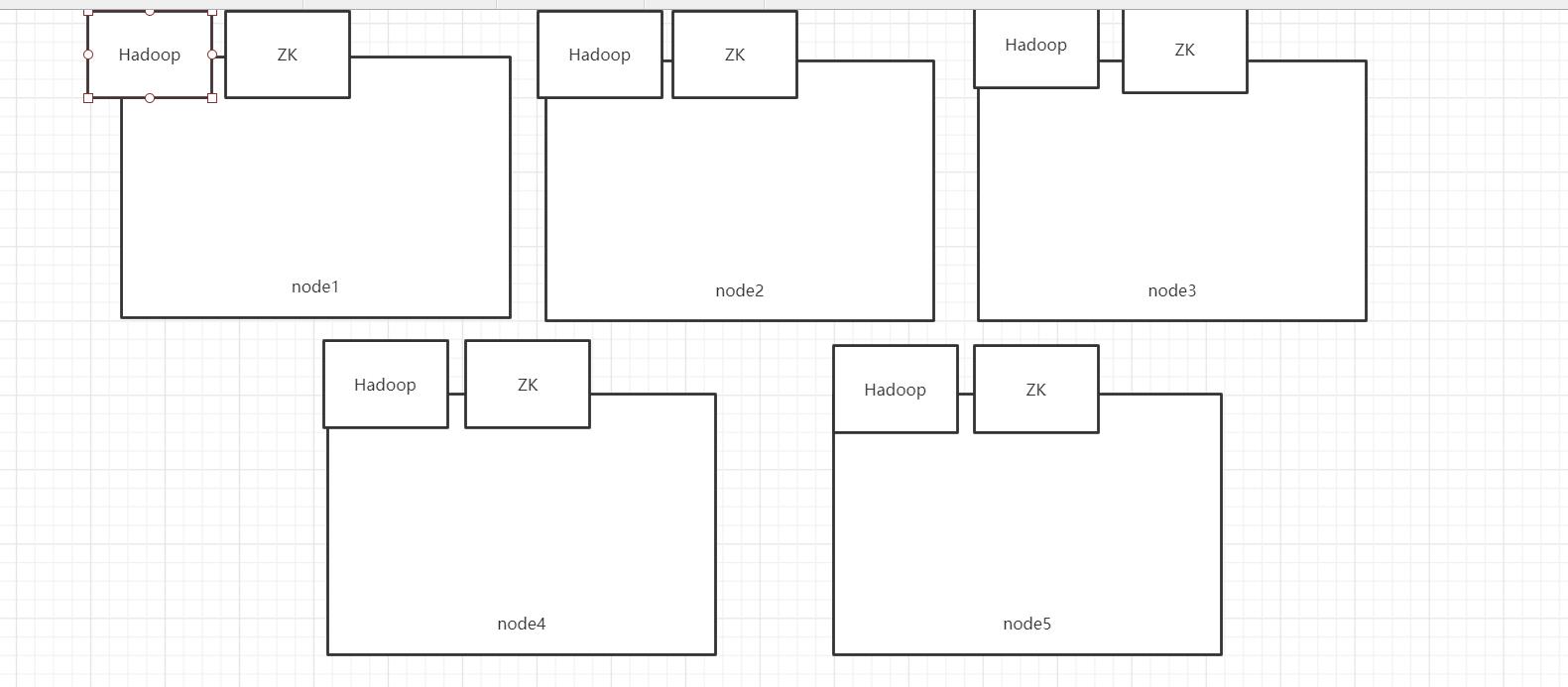
-
优点
- 灵活性和安全性、自定义的程度最高
-
缺点
- 如果集群的机器比较多,安装和管理就比较麻烦
- 如果有一台的配置改变了,其他的都要手动同步
-
小结
- 了解大数据平台命令行部署方式的优缺点
知识点12:平台搭建:集群管理工具部署
-
目标:掌握集群管理工具部署方式的原理及优缺点
-
实施
-
工具
- Cloudera Manager:Cloudera 公司研发的产品
- Ambari:Apache社区的开源集群管理工具
-
过程
- step1:准备好所有软件安装包:Hadoop、Spark、Flink、Hbase……
- step2:先手动安装CM【分布式架构】
- 主:CM-server
- 从:CM-agent
- step3:可以通过CM来管理所有机器上所有软件的安装
- 提供一个管理界面:所有机器节点、所有软件
- 可以自由的选择每个软件安装在哪些机器上
-
原理
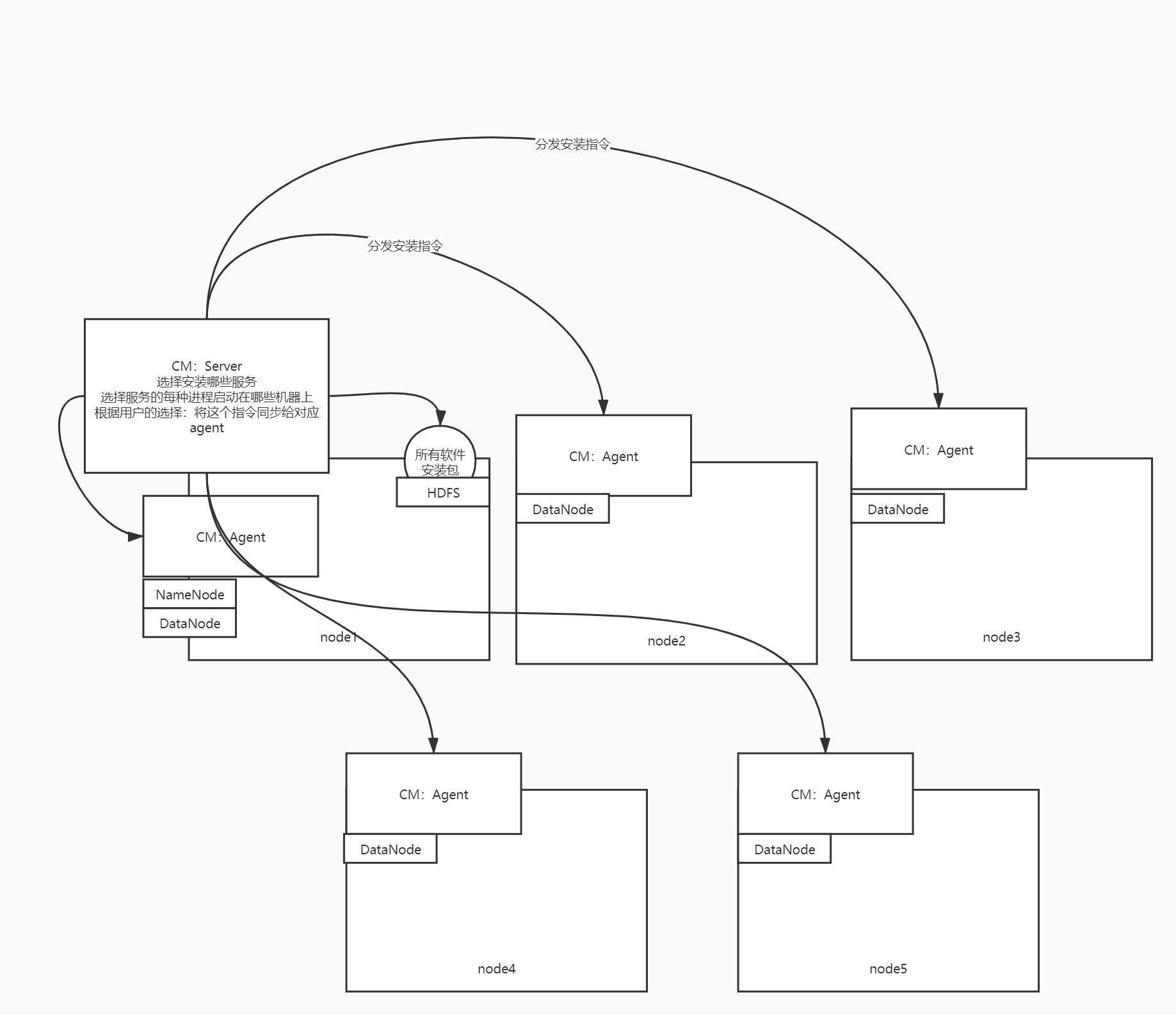
-
优点
- 由管理工具来实现批量化的同步操作:安装、配置
- 有监控管理:进程监控、资源监控
- 可以所有程序管理:不需要命令行,通过可视化界面来管理所有进程
-
缺点
- Cloudera Manager:对很多非Cloudera公司的产品不兼容
- Ambari:Bug比较多,兼容性较差
-
-
小结
- 了解常用的集群管理工具的基本原理
知识点13:Cloudera Manager平台使用
-
目标:了解CM平台的基本使用
-
实施
-
step1:启动虚拟机
-
Linux用户名:root 密码:123456
-
IP地址及主机名,配置Windows映射
192.168.88.150 hadoop01 192.168.88.151 hadoop02
-
-
-
step2:访问CM管理界面
-
注意:虚拟机启动以后,等待一会,才能访问,如果等待一会还不行,就再等一会
-
管理界面
hadoop01:7180 或者 192.168.88.150:7180 CM用户名:admin 密码:admin
-
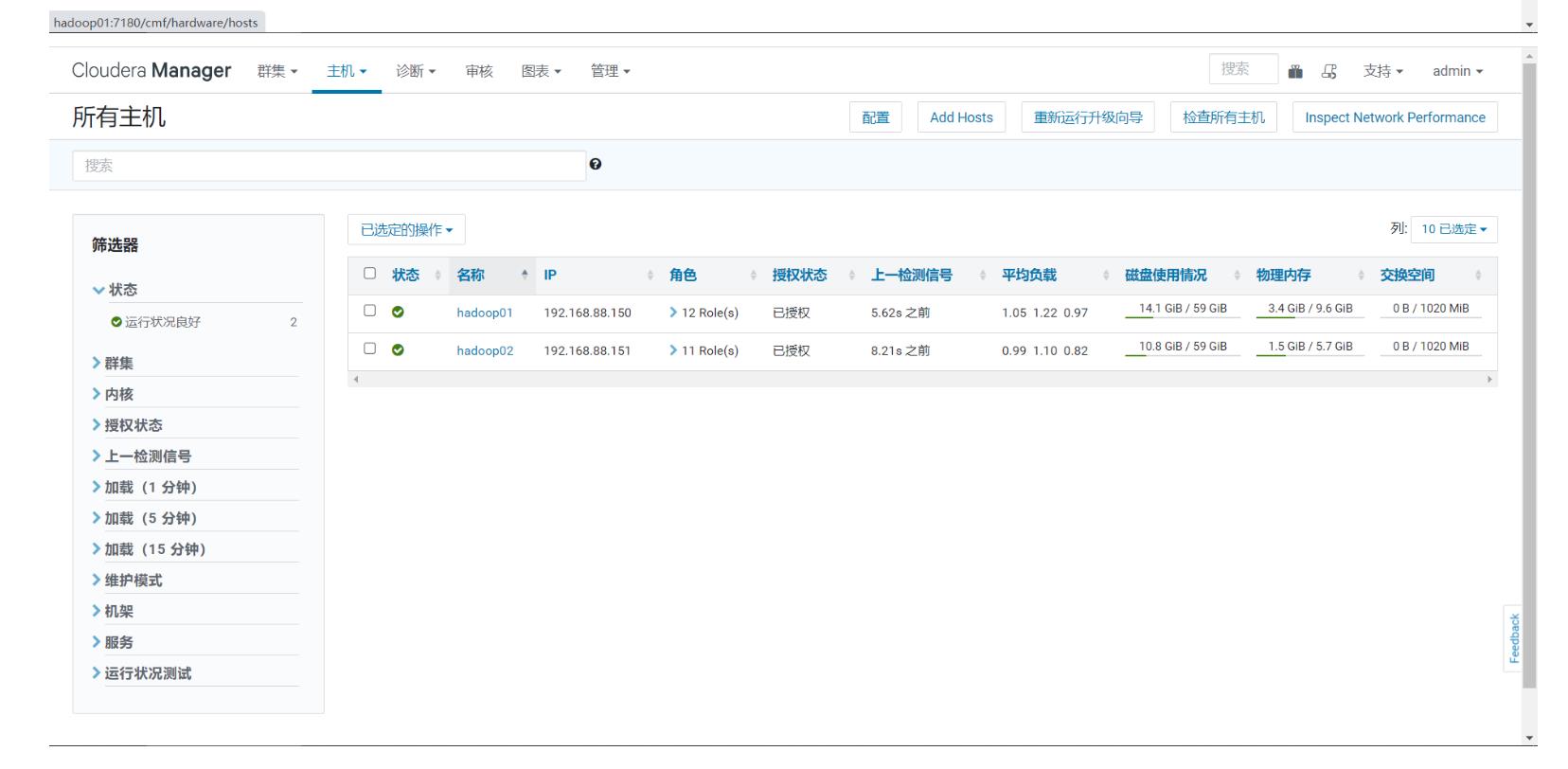
- step3:管理主机,查看主机状态
在这里插入图片描述
- step4:启动管理服务
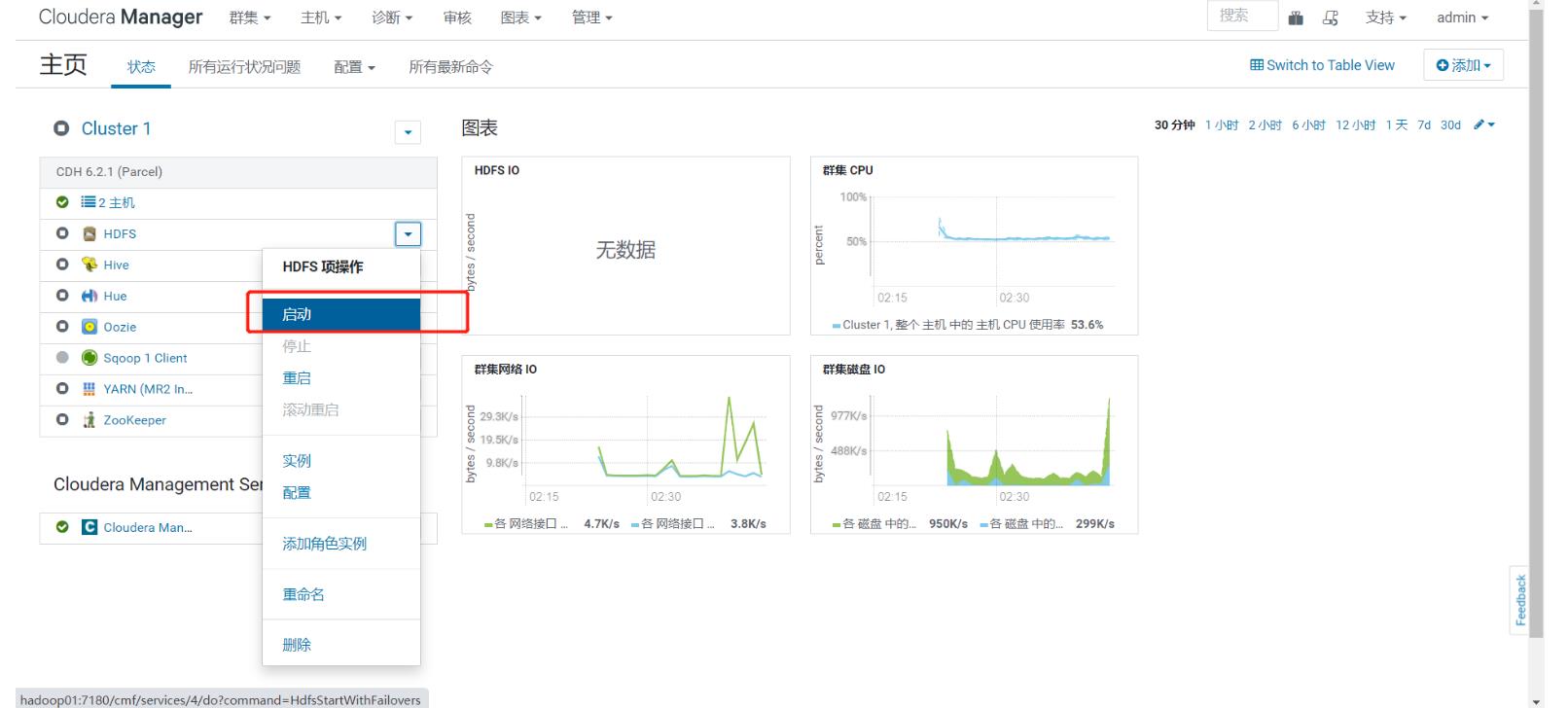
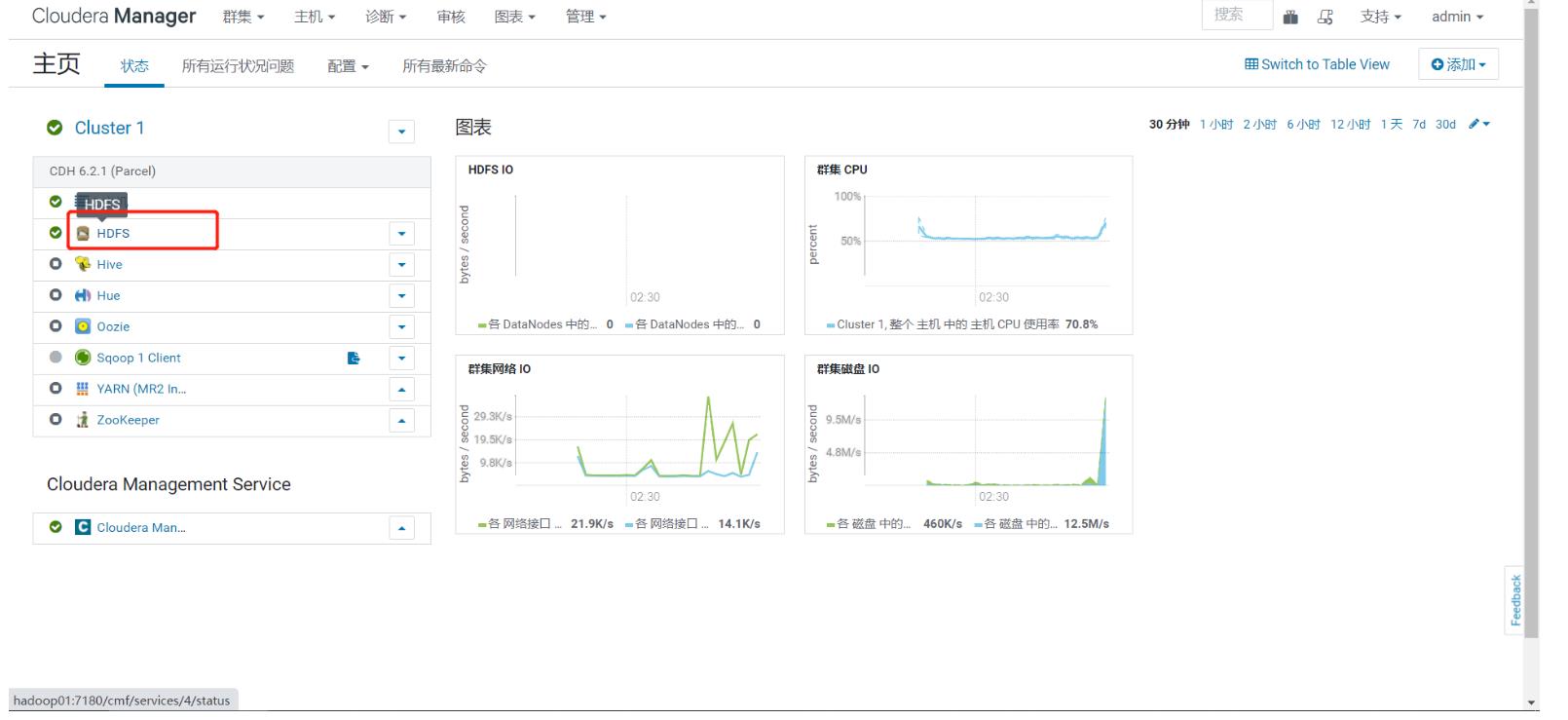
- step5:查看服务状态、进程、配置
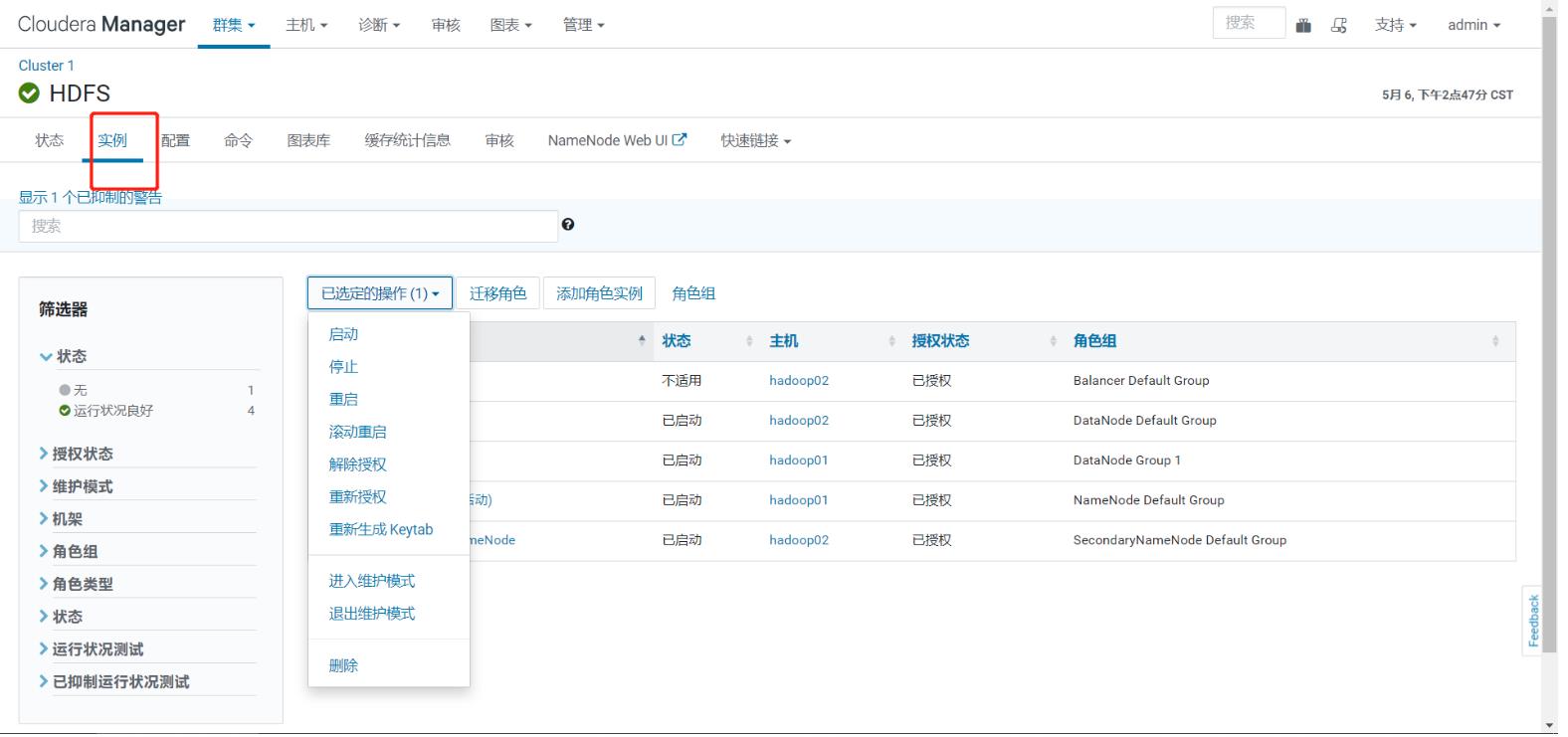
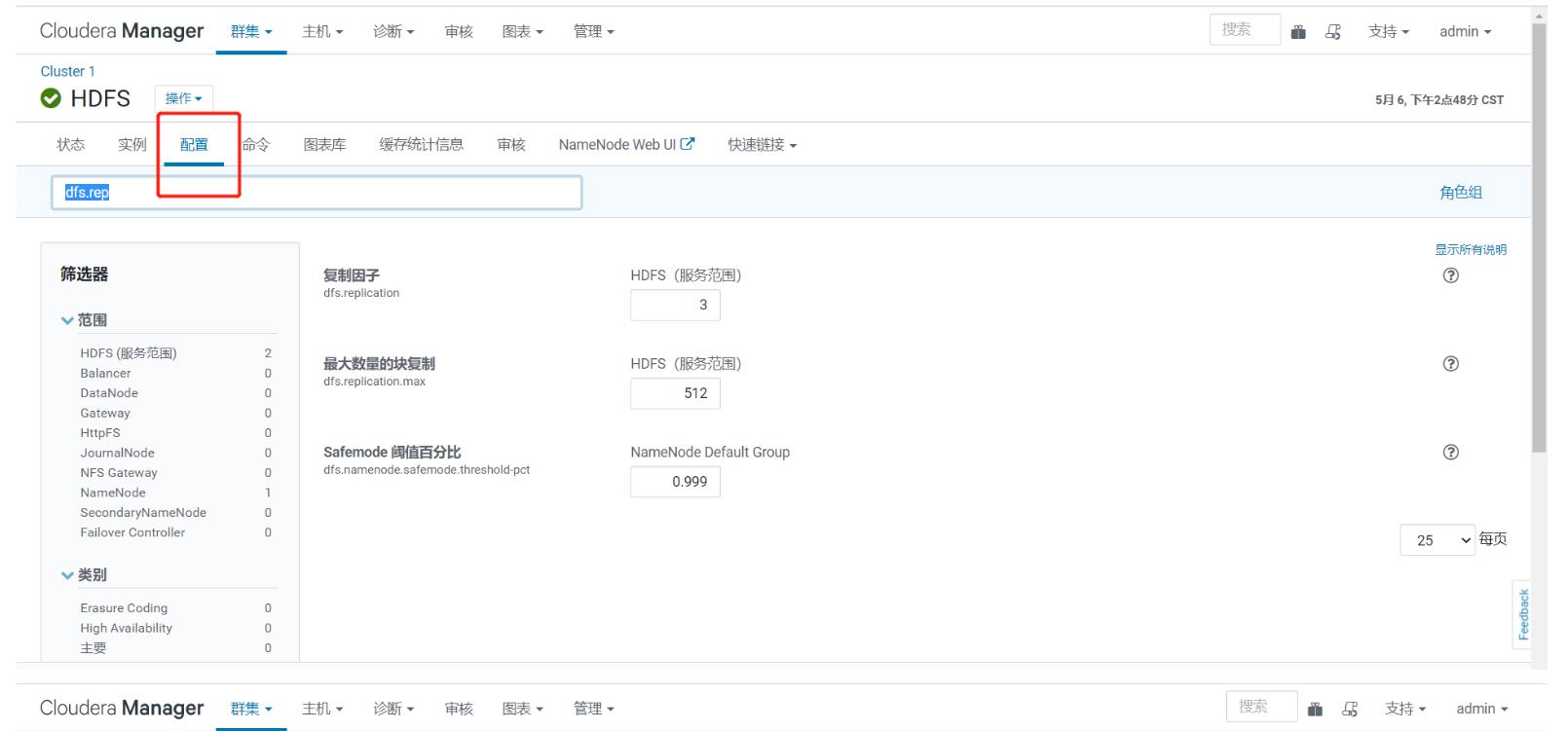
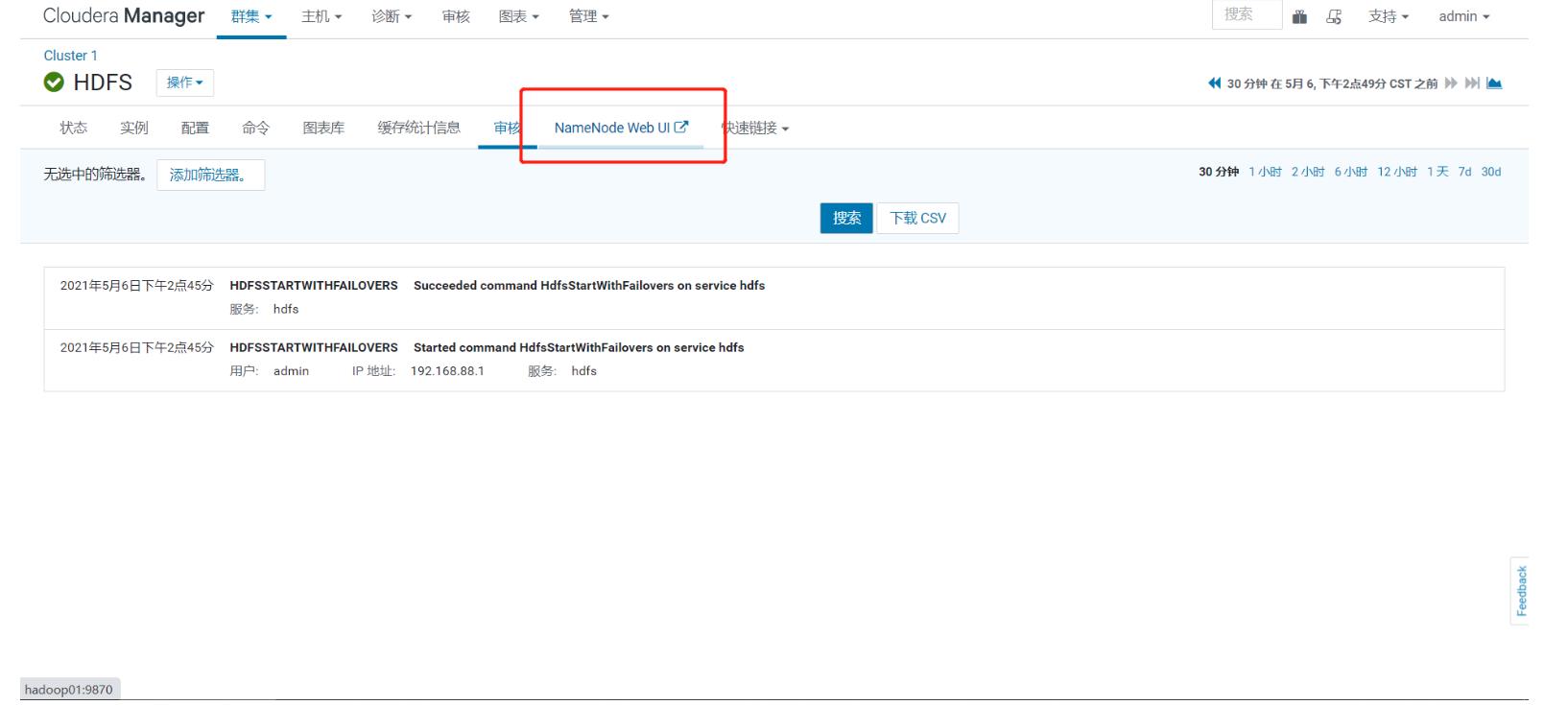
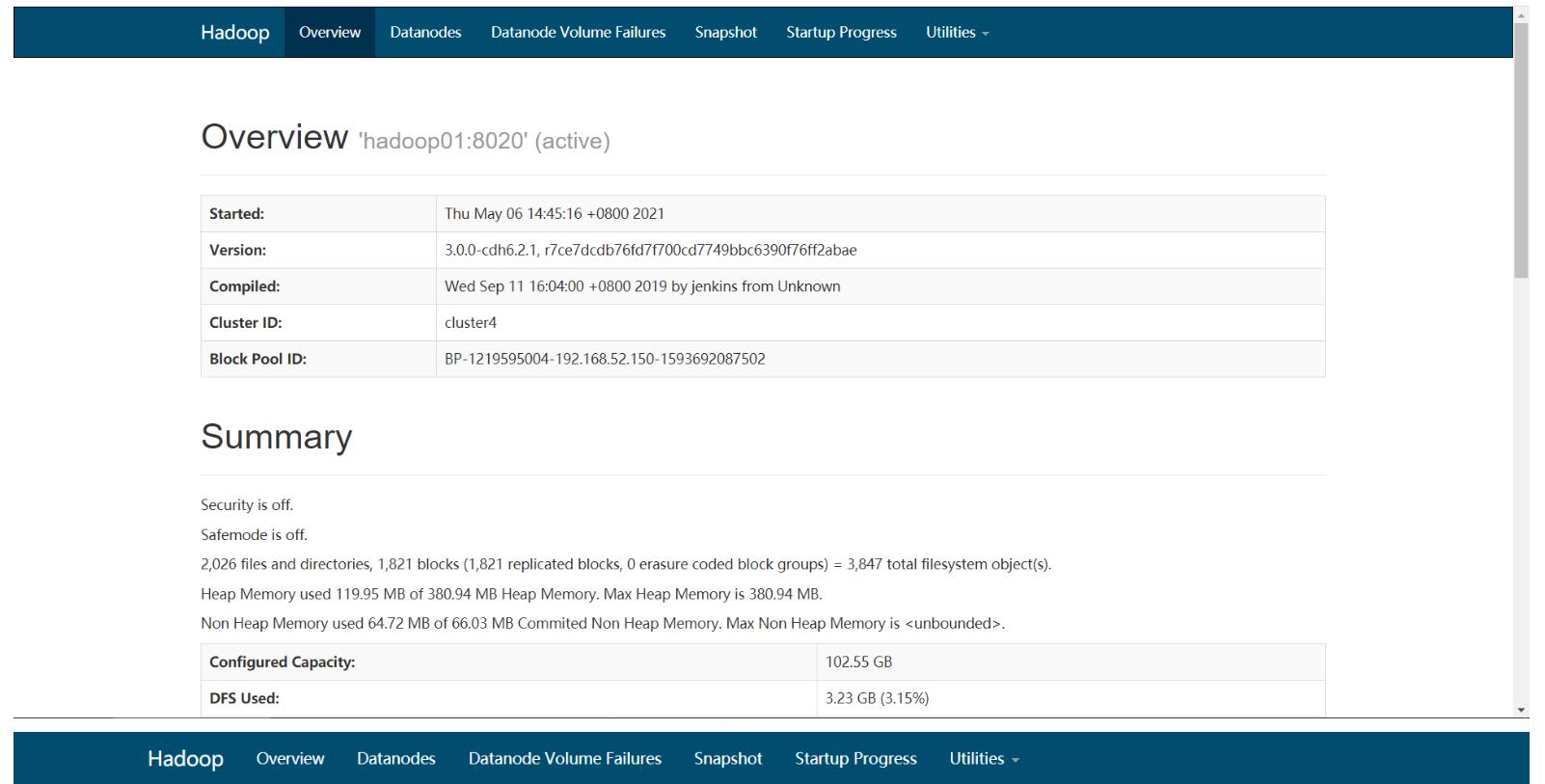
-
step6:使用Hue
Hue的用户名:hue Hue的密 码:hue-
Hue是一个统一化的客户端工具
- 访问HDFS、YARN、Hive、MySQL
-
进入Hue
-
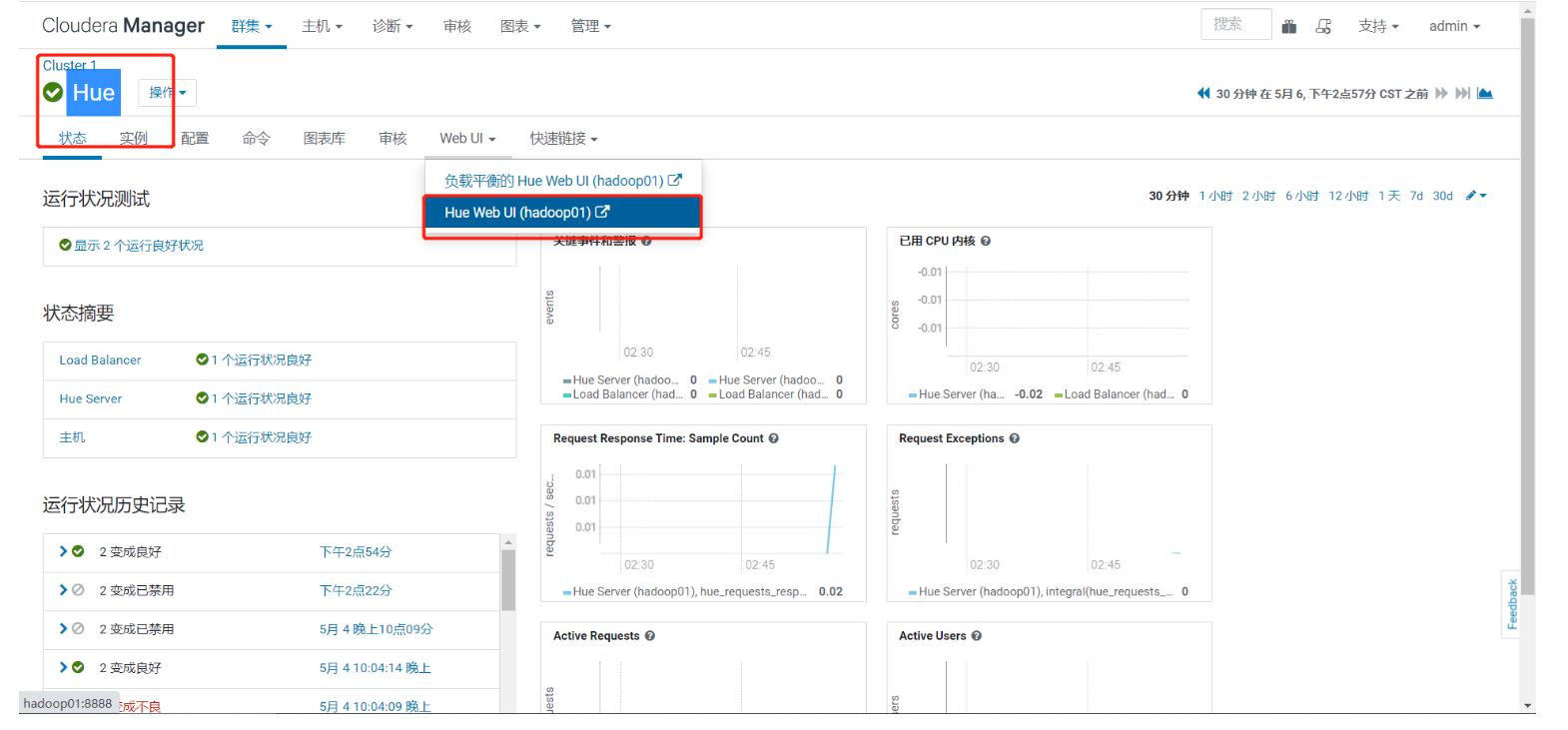
- HDFS
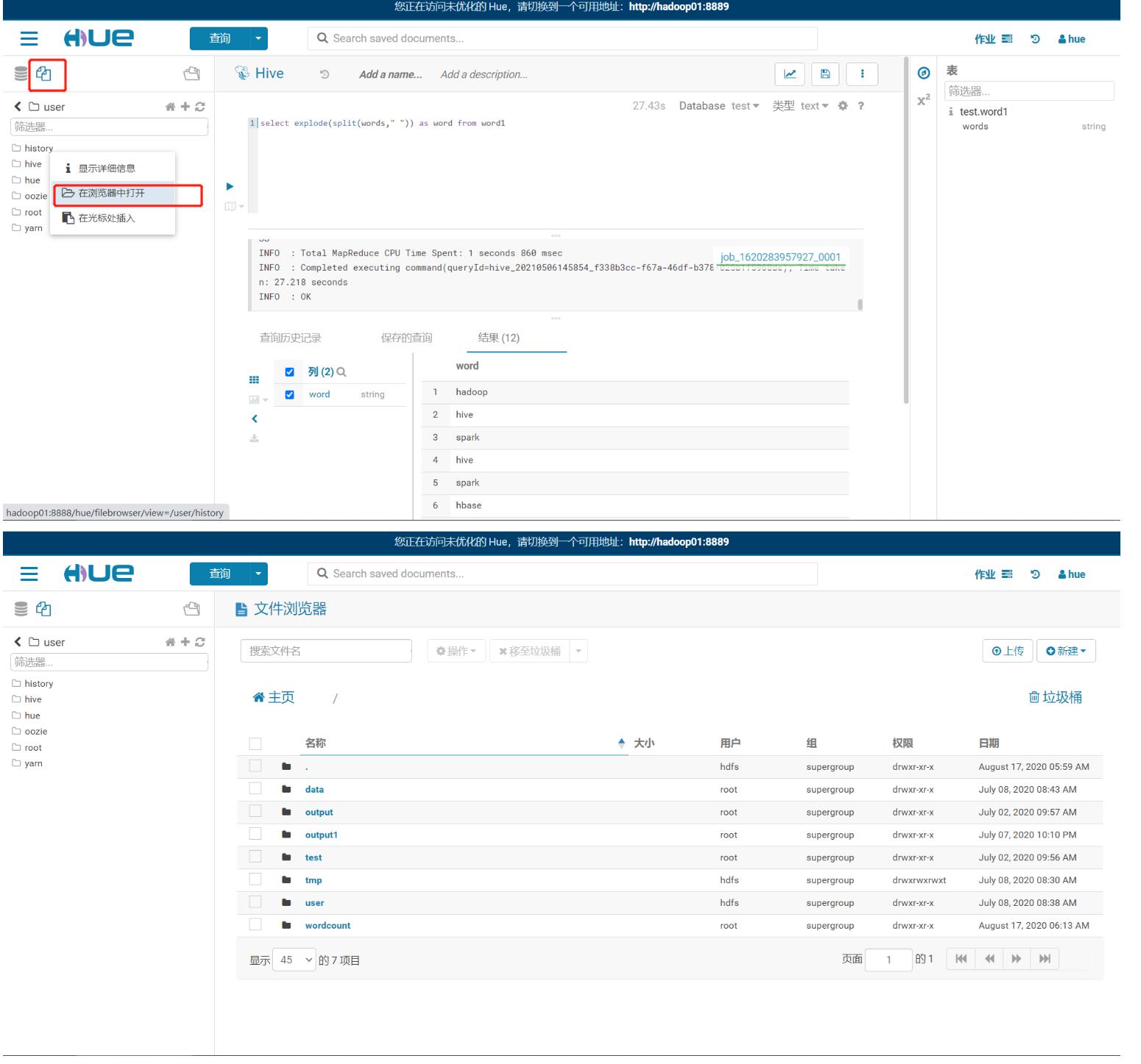
- YARN

- Hive

-
小结
- 了解CM平台的使用即可
知识点14:项目虚拟机环境
-
目标:实现配置启动项目使用的虚拟机环境
-
实施
-
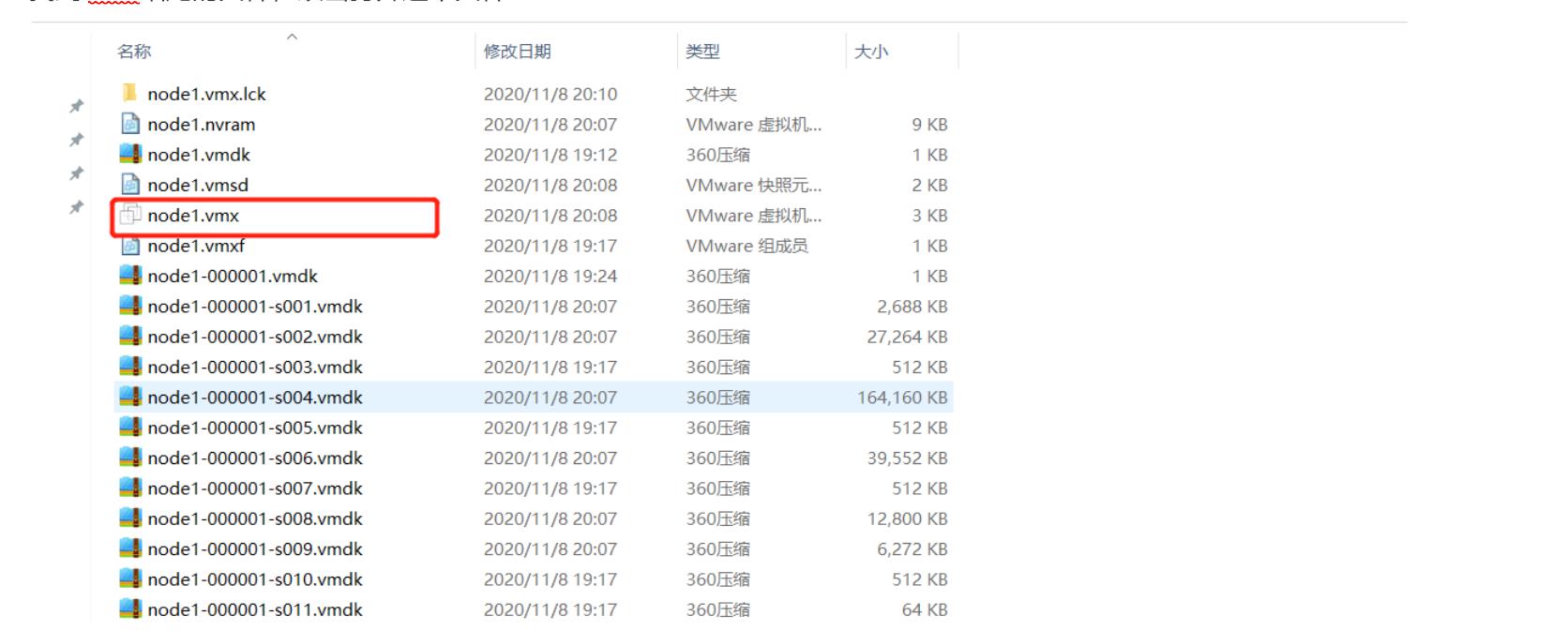
step1:安装虚拟机
-
以第一台为例
- 找到.vmx结尾的文件,双击打开这个文件
-
-
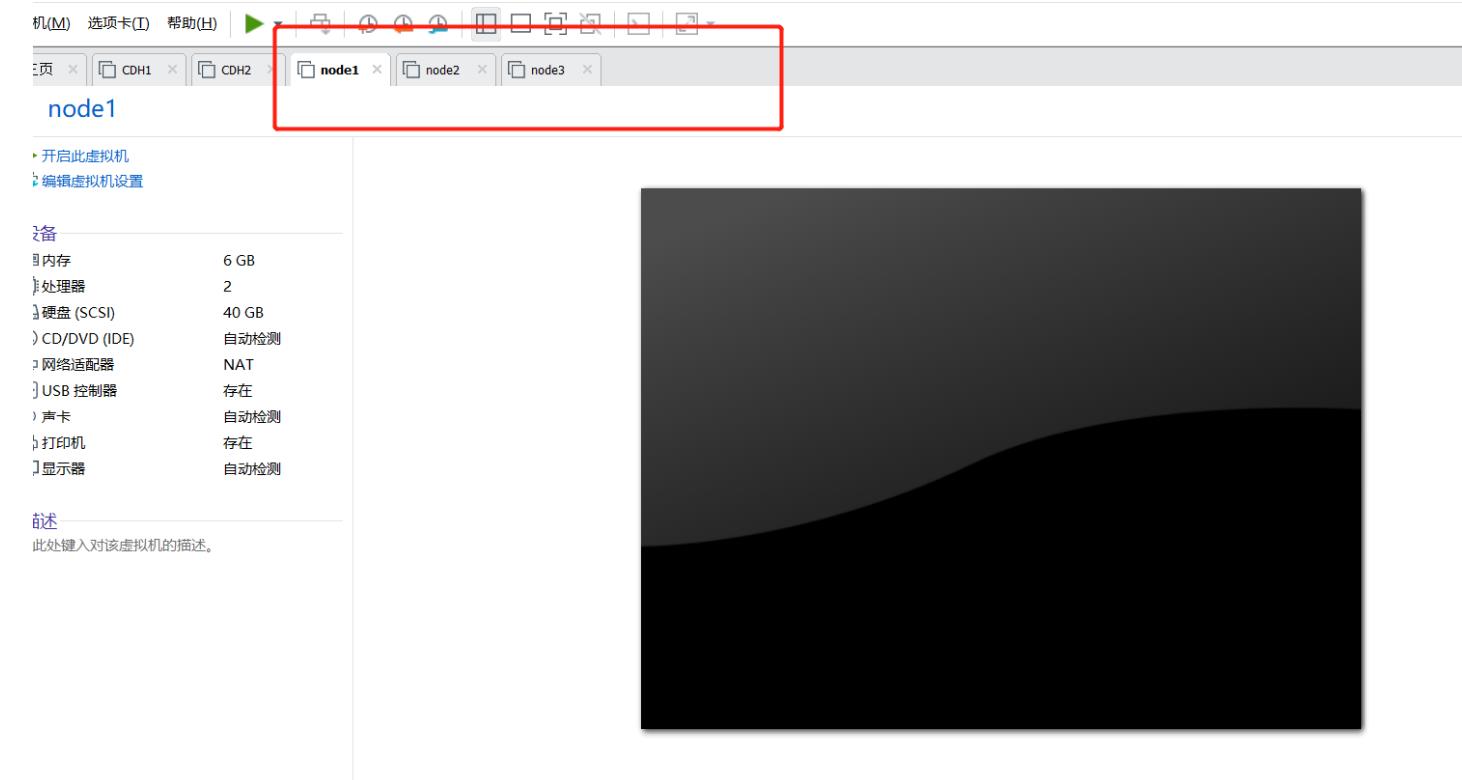
- 如果提示用哪个软件打开,选择VMware WorkStation打开
-
修改资源配置:自己合理的调整机器资源
-
16GB内存:6-4-6 或者 4-4-4
-
启动三台机器
-
-
step2:启动环境测试
-
构建CRT远程连接
三台机器的地址 192.168.88.221 node1 192.168.88.222 node2 192.168.88.223 node3 用户名和密码 root 123456 -
每台机器安装软件
软件/机器 node1 node2 node3 Hadoop * * * Hive * Sqoop * Flume * Oozie * Hue * -
启动Hadoop
- 第一台机器:start-dfs.sh
- 第二台机器: mr-jobhistory-daemon.sh start historyserver
- 第三台机器:start-yarn.sh
-
启动Hive
- 第三台机器
- start-metastore.sh
- start-hiveserver2.sh
- start-beeline.sh
-
启动oozie
- 第一台机器:start-oozie.sh
-
- 启动Hue
- 第一台机器:start-hue.sh
- 关闭
- 第一台机器
- stop-dfs.sh
- stop-oozie.sh
- 第二台机器
- mr-jobhistory-daemon.sh stop historyserver
- 第三台机器
- stop-yarn.sh
-
小结
- 实现启动测试即可
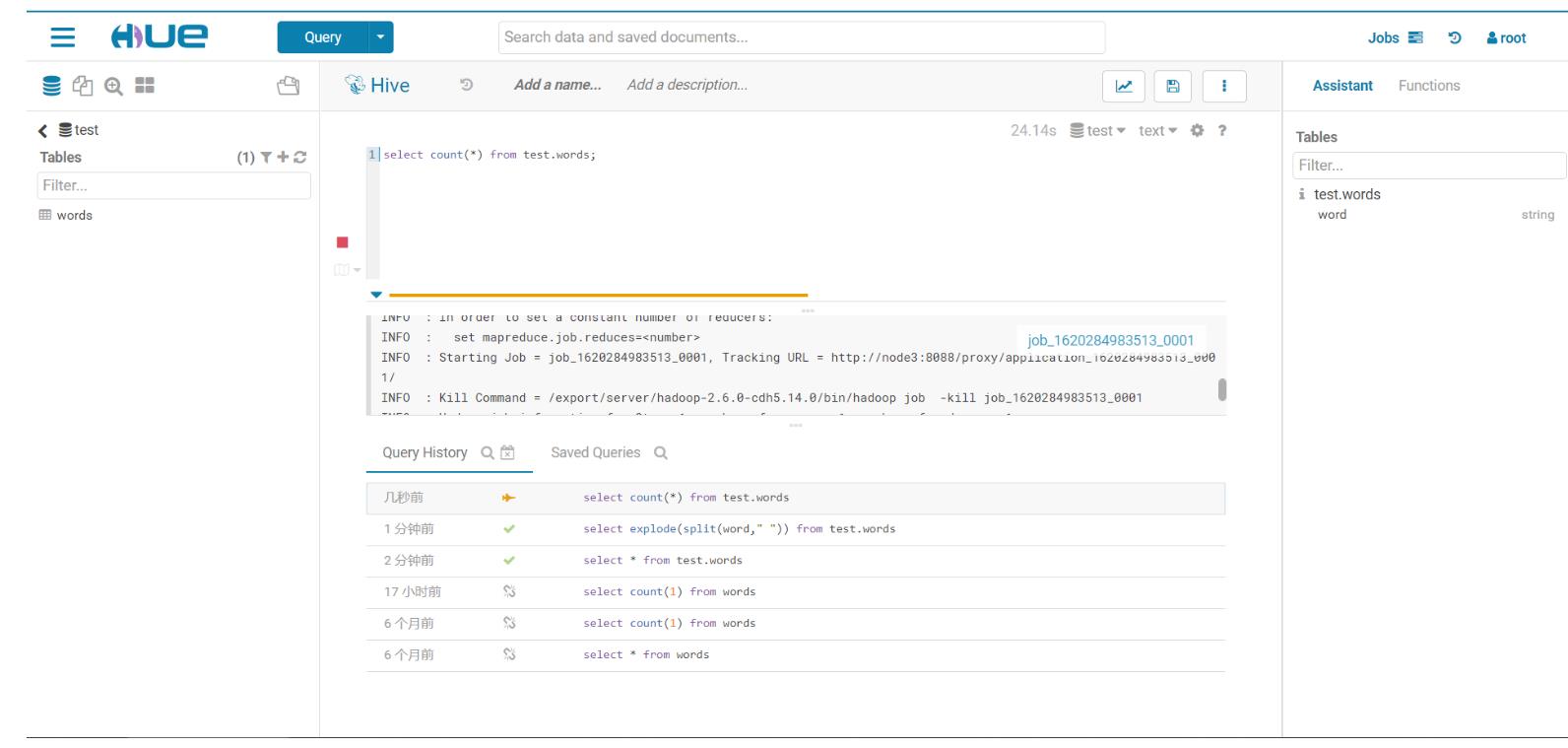
知识点15:Hue的使用
-
目标:了解Hue的基本使用
-
实施
- 启动
-
启动:start-hue.sh
-
访问:node1:8888
- 192.168.88.221:8888
-
登录
- hue用户:root
- hue密码:123456
-
- 启动
- HDFS
- YARN
- Hive
-
小结
- 了解Hue的基本使用
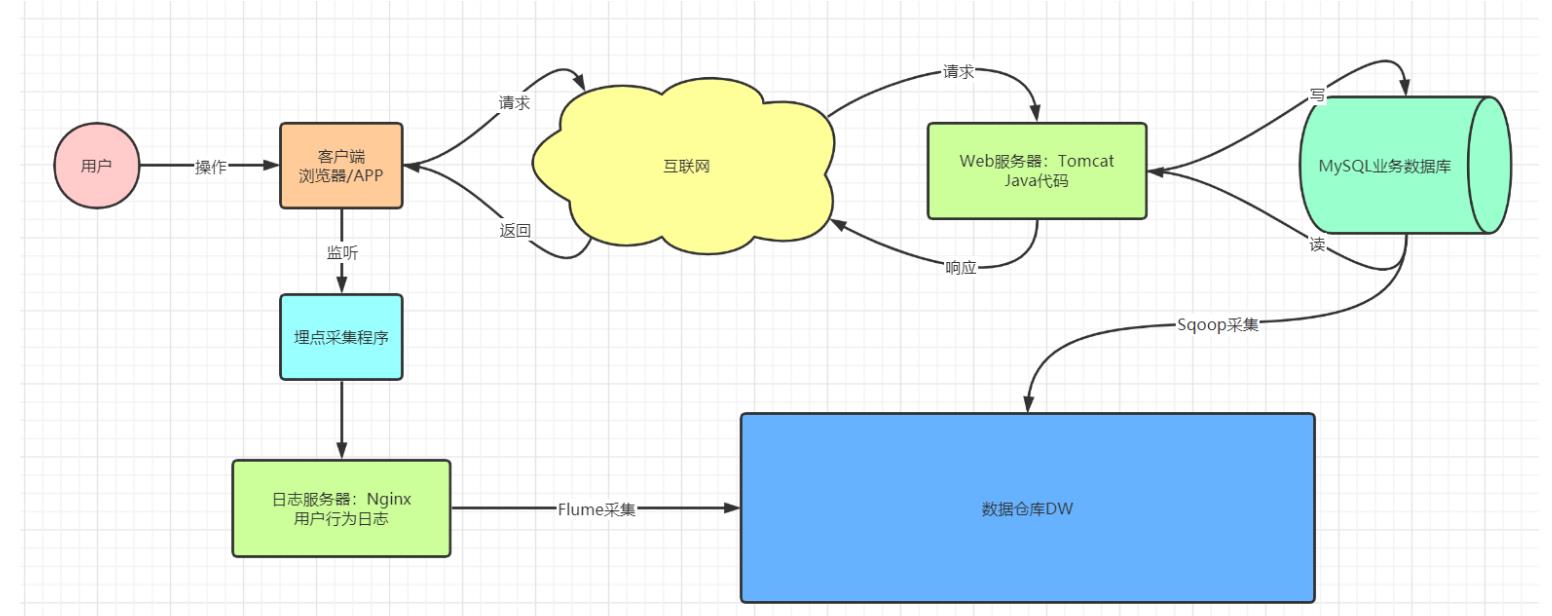
知识点16:数据生成:数据源
-
目标:了解业务数据与用户行为数据的生成
-
实施
-
业务数据
- 存储:数据库
- 目的:为了满足业务需求而实现的业务存储
- 例如:电商:注册登录、浏览商品、下订单、查询订单
- 常见:用户数据、商品数据、订单数据
-

-
用户行为数据
-
存储:日志文件
-
目的:用于记录用户在网站或者APP上的所有的操作行为
-
例如:用户浏览、搜索、支付
-
常见:用户操作的行为数据
-
-
小结
- 了解业务数据与用户行为数据的生成
知识点17:数据生成:用户行为数据演示
-
目标:了解用户行为数据的生成
-
实施
- 用户访问网页
- 埋点收集数据

- 发送给日志服务器
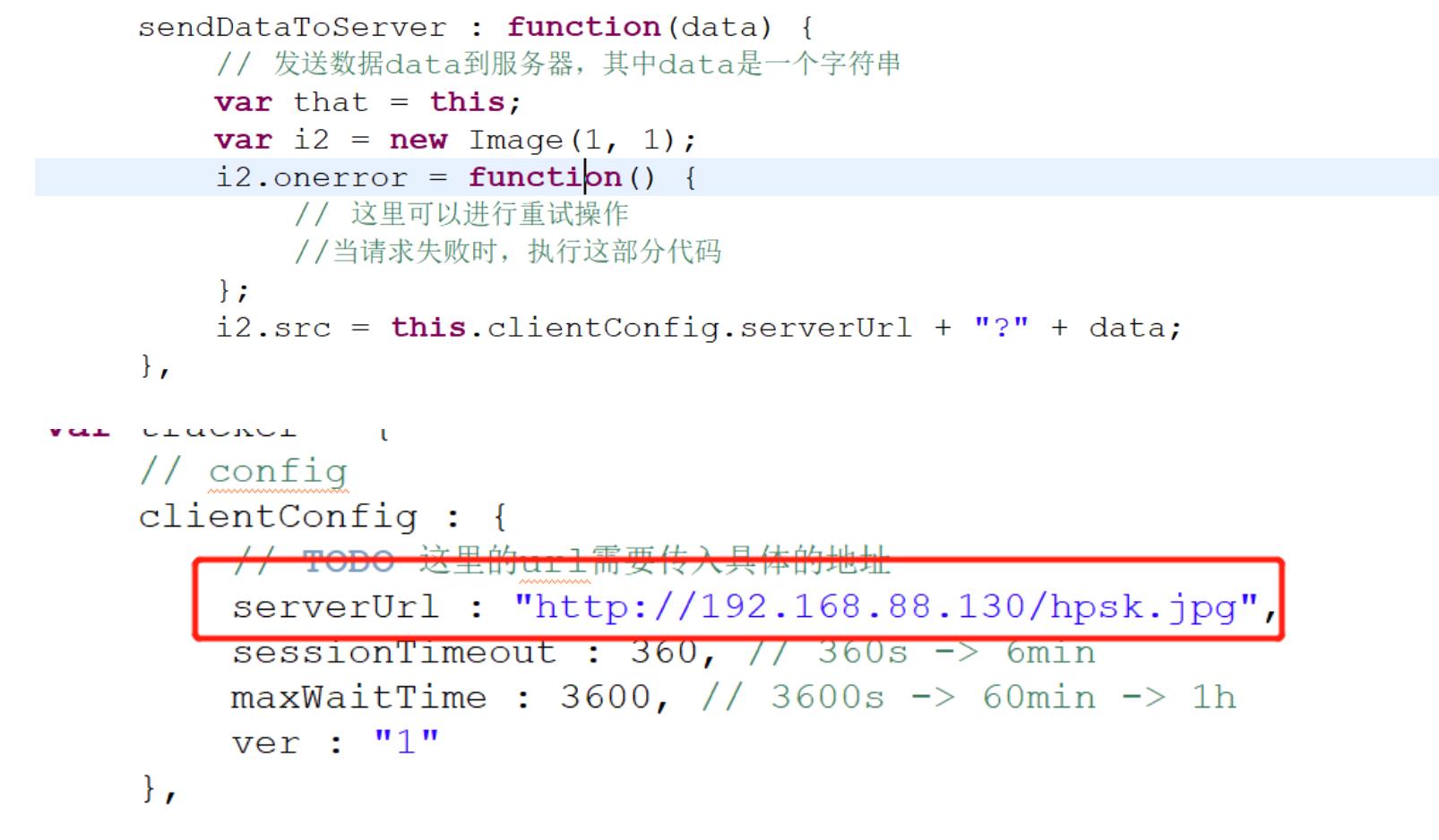
- 日志服务器记录用户行为日志

-
小结
- 了解用户行为数据的生成
知识点18:数据生成:数据内容
-
目标:了解常见数据中的字段内容
-
实施
192.168.88.1^A
1620287034.261^A
192.168.88.130^A
/hpsk.jpg?en=e_l&ver=1&pl=website&sdk=js&u_ud=784160D6-69DB-4E59-8D33-5AD84CD5C97C&u_sd=63DCC8C7-9D2F-4156-A7C9-DFFDEC8E1D55&c_time=1620287034238&l=zh-CN&b_iev=Mozilla%2F5.0%20(Windows%20NT%2010.0%3B%20Win64%3B%20x64)%20AppleWebKit%2F537.36%20(Khtml%2C%20like%20Gecko)%20Chrome%2F90.0.4430.93%20Safari%2F537.36&b_rst=1536*864
192.168.88.1A1620287034.262A192.168.88.130^A/hpsk.jpg?en=e_pv&p_url=http%3A%2F%2Flocalhost%3A8080%2Fhpsk_sdk%2Fdemo.html&p_ref=http%3A%2F%2Flocalhost%3A8080%2Fhpsk_sdk%2Findex.html&tt=%E6%B5%8B%E8%AF%95%E9%A1%B5%E9%9D%A21&ver=1&pl=website&sdk=js&u_ud=784160D6-69DB-4E59-8D33-5AD84CD5C97C&u_sd=63DCC8C7-9D2F-4156-A7C9-DFFDEC8E1D55&c_time=1620287034239&l=zh-CN&b_iev=Mozilla%2F5.0%20(Windows%20NT%2010.0%3B%20Win64%3B%20x64)%20AppleWebKit%2F537.36%20(KHTML%2C%20like%20Gecko)%20Chrome%2F90.0.4430.93%20Safari%2F537.36&b_rst=1536*864
-
用户IP地址:一般用于统计用户的地区分布
-
服务端时间:用于标记数据的时间
-
请求服务端地址
-
URI:包含采集到的用户的数据,page?key=value&key=value
/hpsk.jpg?:访问页面 en=e_l&:事件类型:用户做了什么事情产生的数据 ver=1&:版本 pl=website&:平台 sdk=js&:JS埋点采集的 u_ud=784160D6-69DB-4E59-8D33-5AD84CD5C97C& :访客id u_sd=63DCC8C7-9D2F-4156-A7C9-DFFDEC8E1D55& :会话id c_time=1620287034238& :客户端时间 l=zh-CN& :客户端语言 b_iev=Mozilla%2F5.0%20(Windows%20NT%2010.0%3B%20Win64%3B%20x64)%20AppleWebKit%2F537.36%20(KHTML%2C%20like%20Gecko)%20Chrome%2F90.0.4430.93%20Safari%2F537.36 :客户端的操作系统和浏览器信息 &b_rst=1536*864 :客户端分辨率- en=e_l:表示这个用户是第一次访问
- 自动创建一个用户id写入客户端的cookie中
- 下一次再访问,已经有用户id,就不会再出发这个e_l的记录
en=e_pv& p_url=http%3A%2F%2Flocalhost%3A8080%2Fhpsk_sdk%2Fdemo.html& 当前正在访问的页面 p_ref=http%3A%2F%2Flocalhost%3A8080%2Fhpsk_sdk%2Findex.html& 从哪个页面过来的 tt=%E6%B5%8B%E8%AF%95%E9%A1%B5%E9%9D%A21& 当前页面的标题 ver=1& pl=website& sdk=js& u_ud=784160D6-69DB-4E59-8D33-5AD84CD5C97C& u_sd=63DCC8C7-9D2F-4156-A7C9-DFFDEC8E1D55& c_time=1620287034239& l=zh-CN& b_iev=Mozilla%2F5.0%20(Windows%20NT%2010.0%3B%20Win64%3B%20x64)%20AppleWebKit%2F537.36%20(KHTML%2C%20like%20Gecko)%20Chrome%2F90.0.4430.93%20Safari%2F537.36& b_rst=1536*864- en=e_pv:page view :表示用户正在浏览页面
- en=e_crt:用户提交订单
- 订单id
- 商品id
- 商品价格
- en=e_pay:支付操作
- price
- paytype
- ……
- en=e_l:表示这个用户是第一次访问
-
小结
- 了解常见数据中的字段内容
以上是关于Day14:项目需求与技术架构的主要内容,如果未能解决你的问题,请参考以下文章