浅谈K8s的扩展体系
Posted 萌大统领
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了浅谈K8s的扩展体系相关的知识,希望对你有一定的参考价值。
前言
K8s 设计了很多扩展点,当其原生的特性不满足用户需求时,用户可在不改变 K8s源码的情况下,通过这些扩展机制来达到目的。
总的来说,K8s的扩展点可分为应用访问层扩展和基础设施层扩展两大类:
一、应用访问层扩展
1. webhook
是什么
WebHook是一种HTTP回调,一般是用于设定在某些条件下触发的 HTTP POST请求,用于发送消息给特定的URL。
与控制器的区别
可以自定义一个控制器来实现与WebHook类似的功能,但是控制器需要被编译进Api Server,并且只能在 Api Server启动时启动。而WebHook可以独立存在于K8s之外,只要是一个有监听端口、能处理http请求的进程即可作为WebHook的回调处理,更具灵活性。
适用场景
适用于不想局限于K8s ApiServer,而是想由K8s外部的服务(如用户自己的服务)来处理资源的场景。由于webhook可以不依赖于api server,对任何资源的创建、更新、删除提供了很大的自由和灵活度,比如
在创建资源前做些更改。istio是个非常典型的例子,在目标pod中注入envoy sidecar容器,实现流量管理和规则执行
自动配置StorageClass。监听PVC资源,并按照事先定好的规则自动的为之增添对应的 StorageClass,使用者无需关心 StorageClass 的创建
验证复杂的自定义资源。确保只有其被定义后且所有的依赖项都创建好并可用,自定义资源才可以创建
目前webhook在K8s内部也已有不少应用场景,典型的如:
身份认证
Webhook身份认证是一种用来验证持有者令牌的回调机制,详见Webhook令牌身份认证。
鉴权
当在判断用户权限时,Webhook模式会使Kubernetes查询外部的Http REST服务。
动态准入
准入Webhook是一种用于接收准入请求并对其进行处理的HTTP回调机制。
2. operator
是什么
Operator有时也被称为CRD机制:
狭义上来说,operator = CRD + 自定义Controller
简单理解,就是:通过自定义的Controller监听CRD对象实例的增删改事件,然后执行相应的业务逻辑。
广义上来说,operator = CRD + 自定义Controller + WebHook
即在前者的基础上,还可以在CRD对象的生命周期里设置相关的事件回调(WebHook),回调程序一般为外部自定义的一个HTTP URL。
CRD(Custom Resource Definition)本身只是一段声明,用于定义用户自定义的资源对象。但仅有CRD的定义并没有实际作用,用户还需要提供管理CRD对象的CRD控制器(一般是自定义的控制器),才能实现对CRD对象的管理。
Operator极大扩展了K8s的能力,使用户像操Pod一样操作自定义的各种资源对象。
适用场景
Operator适用于创建、配置和管理复杂的有状态应用,如数据库、缓存和监控系统。
Operator的初衷是,开发者将运维能力固化在代码中,让运维更容易,核心在于对领域能力的实现和封装。
对于无状态应用的部署和管理,K8s内置的Depolyment已能满足需要,但对于状态应用,K8s支持的还是比较有限。虽然 K8s内置了StatefulSet这种工作负载来运行有状态的应用服务,但SetfulSet对Pod没有任何洞察,也不可观测。所以,这样的运维是很粗糙的,即便身份标识唯一、部署启动顺序可被定义,但它不能处理特殊状况,比如没法识别复制状态、集群状态等,也无法在这些状态的基础上作进一步的处理。而Operator可以很好的解决这些问题。
业内应用
Operator目前已经在一些基于K8s的第三方开源项目中得到广泛应用,包括CSI存储插件、Device Plugin(如GPU驱动程序)、Istio(Service Mesh管理)等,已经逐渐成为扩展K8s能力的标准。
腾讯云TKE的一些扩展插件也是基于Operator机制实现的,典型的如:
TApp:类似于K8s内置的Deployment、StatefulSet等,TApp是TKE自定义的一种新的工作负载类型,主要是通过自定义的控制器实现(TappController)。TApp支持有/无状态的应用类型,可进行Pod级别的指定删除、原地升级、挂载独立数据盘等操作
LBCF:是TKE自定义的一种负载均衡组件,主要由6个自定义控制器+4个CRD对象+8种WebHook组成。LBCF旨在降低容器对接负载均衡的实现难度,并提供强大的扩展能力以满足业务方在使用负载均衡时的个性化需求。
StatefulSetPlus:在继承了StatefulSet的基础上,新增支持了弹性伸缩、扩缩容/漂移后容器IP能保持不变、支持应用的多批次灰度更新等新特性。(K8s原生的workload中,StatefulSet并不支持HPA-弹性伸缩,只有Deployment才支持HPA)
GameDeployment 和GameStatefulSet:支持镜像预拉取、镜像热更新、支持智能式分步骤灰度发布,可在灰度发布步骤中加入 hook 校验等新特性。(K8s原生的Deployment和StatefulSet均不支持镜像预拉取/热更新)
Operator与Conroller区别
Operator是一种特别的 Controller,也即本质上 Operator 和 Controller 都是基于K8s的资源和控制器概念之上构建,但是不同之处在于,Operator 包含了应用程序特定的领域知识,其实也可以说是封装了运维人员对于特定应用程序的运维经验。
例如通过定义一个CRD来定义nginx的配置不算Operator,顶多算Controller;但是,如何让Nginx保持高可用的Controller,这就是个 Operator,因为它包含了保证 Nginx 高可用的业务逻辑,这封装了运维经验。此外,比较常见的还有管理应用状态的 Operator,例如 prometheus operator,它既要管理 promehteus 的配置,还需要管理 prometheus 自身的运行以及存储等。
落地实践
Operator一般通过Go语言实现,并需要遵循K8s的控制器开发规范,基于客户端库client-go进行开发,需要实现Informer、ResourceEventHandler、Workqueue等组件具体的功能处理逻辑。
可通过第三方开源框架来快速开发Operator:
KubeBuilder
在没有KubeBuilder之前,为了实现一个 Operator,用户需要完全实现从 K8s Client 的创建开始,到监听 K8s API Server 的请求,再到请求的队列化,以及后面的业务逻辑一整套的逻辑。在整个过程中,有一些逻辑是所有的 Operator 在实现的时候都需要的。因此 kubebuilder 将其进行了封装和抽象成了公共的库(controller-runtime)和公共的工具(controller-tools)。随后在开发Operator的时候,只需要通过KubeBuilder生成一些脚手架代码,用户不再需要关心K8s API Server发来的请求是怎样进入请求队列,然后被依次执行的,只需要关心要如何处理当前的请求即可。其他的事情会由KubeBuilder代码中用到的controller-runtime等库来帮助开发者处理。
KUDO
KUDO是Kubernetes Universal Declarative Operator的简称,指K8s通用声明性框架Operator。KUDO是K8s Operator的开发工具和运行时,经过几行YAML的声明性方式,取代了数万行的复杂代码库,使编写操做变得高效和简单。
Operator Framework
Operator Framework是一个用于快速开发维护Operator的工具包,该框架包含三个项目:
Operator SDK: 无需了解复杂的K8s API特性即可快速构建一个Operator应用。
OLM:帮助安装、更新和管理跨集群的运行中的所有 Operator
Operator Metering: 收集 operator metric 信息,并生成报告
3. aggregator
是什么
也被称为"Aggregation Layer"(聚合层)或“apiserver-aggregation”(API Server聚合),本文统称为“聚合机制“。聚合机制是K8s 1.7版本引入的特性,方便用户开发自己的 API server 集成进来,即可以通过额外的API扩展 K8s,而不局限于K8s 核心API提供的功能,且不用直接修改K8s官方仓库的代码。
与Operator的区别
Operator依旧是复用K8s的API Server,无须编写额外的API Server。用户只需要定义CRD,并且提供一个CRD控制器,就能通过K8s的API管理自定义资源对象了。而聚合机制下,用户需要编写额外的API Server,可以对资源进行更细粒度的控制,且用户需要自行处理对多个API版本的支持。
目标初衷
聚合机制的目标是提供集中的API发现机制和安全的代理功能,将开发人员的新API动态地、无缝地注册到Kubernetes API Server中进行测试和使用。
增加API的扩展性:使得开发人员可以编写自己的API Server来发布他们的API,而无须对K8s核心代码进行任何修改
无须等待K8s核心团队的繁杂审查:允许开发人员将其API作为单独的API Server发布,使集群管理员不用对K8s核心代码进行修改就能使用新的API,也就无须等待社区繁杂的审查了
支持实验性新特性API开发:可以在独立的API聚合服务中开发新的API,不影响系统现有的功能
确保新的API遵循K8s的规范:如果没有API聚合机制,开发人员就可能会被迫推出自己的设计,可能不遵循K8s规范
4. 容器探针
是什么
简单理解,容器探针就是指kubelet对容器执行的定期诊断,k8s只是定义了探针的规范,并未给出具体的实现,具体的诊断实现逻辑是开放给开发者的,由开发者自定义。
与webhook的异同
容器探针与webhook有些类似,本质上都是一种回调,与webhook只能用http回调不同,容器探针支持更多通信方式,除了可以是一个http请求外,也可以是一个tcp请求,还可以是bash命令
探针分类
目前K8s提供如下3种容器探针:
存活探针
存活探针用于确定何时重启容器。如果你希望容器在探测失败时被杀死并重新启动,可以指定一个存活态探针。
就绪探针
就绪探针用于确定容器是否已准备好接受请求流量了,一般是指容器已完成了所有的初始化工作,可随时准备处理新流量请求时。
启动探针
启动探针适用于需要较长时间才能启动就绪的Pod,可以控制容器在启动成功后再进行存活性和就绪检查,确保这些存活、就绪探针不会影响应用程序的启动,以避免慢启动容器在启动运行之前因存活探测失败而被杀掉。
5. 启停回调
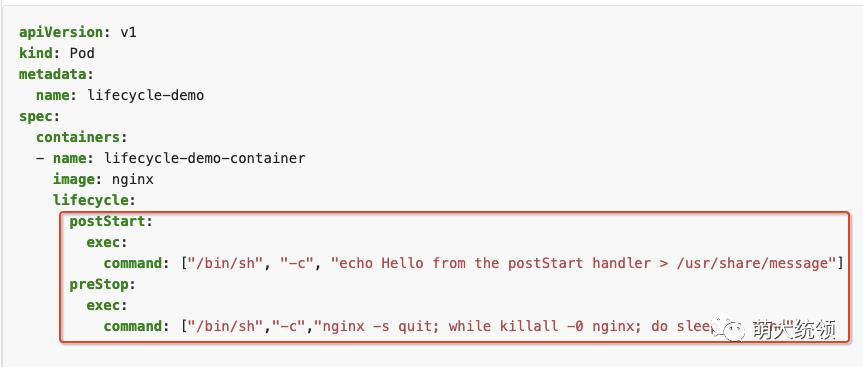
指K8s对容器的启停事件回调 (postStart和preStop事件)。当一个容器启动后,K8s 将立即发送 postStart 事件;在容器被终结之前, Kubernetes 将发送一个 preStop 事件。容器可以为每个事件指定一个自定义的处理程序。在设置具体的回调处理程序时,除了可以使用bash命令,也可以指定一个http url。
示例:
6. kubectl插件
是什么
kubectl的插件机制允许开发者以独立的二进制形式发布自定义的kubectl子命令。
kubectl插件可以使用任意语言开发,可以是一个bash、python的脚本,也可以是其他语言开发编译的二进制可执行文件,只要最终将脚本或二进制可执行文件以kubectl-的前缀放到PATH中即可。使用kubectl plugin list可以在PATH中查看有哪些插件。
适用场景
当用户(主要是k8s管理员、运维人员)的管理需求并不单一时,例如需要结合多个原生命令做特定的运维管理工作,则kubectl的原生接口是满足不了你的需求的,此时可以考虑使用kubectl插件。
你也可以把常用的一些运维操作,封装为一个kubectl插件,集成到 kubectl客户端的命令中,或者也可以使用Krew来发现和安装社区的开源kubectl插件。
使用限制
自定义的子命令不能与现有kubectl命令相同,例如,创建一个插件 kubectl-version 将导致该插件永远不会被执行,因为现有的 kubectl version 命令总是优先于它执行。
不能使用插件将新的子命令添加到现有的kubectl命令中,如通过将插件命名为 kubectl-create-foo 来添加子命令 kubectl create foo 将导致该插件被忽略,因为kubectl create是现有的命令,不可包含在新的子命令中
二、基础设施层扩展
1. 调度器扩展
是什么
K8s 自带了一个默认调度器(即kube-scheduler),主要负责整个集群资源的调度功能,根据特定的调度算法和策略,将Pod 调度到最优的工作节点上面去,从而更加合理、更加充分的利用集群的资源。
默认情况下,kube-scheduler 提供的默认调度器能够满足我们绝大多数的要求,一般使用默认的策略,都可以保证我们的 Pod 可以被分配到资源充足的节点上运行。
适用场景
调度器也是一种特殊的控制器,如果默认调度器不适合你的需求,你可以实现自己的调度器,你也可以和默认调度器一起同时运行多个调度器,并告诉 K8s 为每个Pod使用哪个调度器。但在大部分情况下,是不需要修改调度器的。
调度器也支持一种 Webhook, 允许使用某种 Webhook 后端(调度器扩展)来为 Pod可选的节点执行过滤和优先排序操作。
如何扩展
一般有4种扩展K8s调度器的方法:
一种方法就是直接clone官方的 kube-scheduler 源代码,在合适的位置直接修改代码,然后重新编译运行修改后的程序,当然这种方法是最不建议使用的,也不实用,因为需要花费大量额外的精力来和上游的调度程序更改保持一致。
第二种方法就是和默认的调度程序一起运行独立的调度程序,默认的调度器和我们自定义的调度器可以通过Pod的 spec.schedulerName 来覆盖各自的 Pod,默认是使用K8s内置的调度器,但是多个调度程序共存的情况下也比较麻烦,比如当多个调度器将 Pod 调度到同一个节点的时候,可能会遇到一些问题,因为很有可能两个调度器都同时将两个 Pod 调度到同一个节点上去,但是很有可能其中一个 Pod 运行后其实资源就消耗完了,并且维护一个高质量的自定义调度程序也不是很容易的,因为我们需要全面了解默认的调度程序,整体 Kubernetes 的架构知识以及各种 Kubernetes API 对象的各种关系或限制。
第三种方法是调度器扩展程序,这个方案目前是一个可行的方案,可以和上游调度程序兼容,所谓的调度器扩展程序其实就是一个可配置的 Webhook 而已,里面包含 过滤器 和 优先级 两个端点,分别对应调度周期中的两个主要阶段(过滤和打分)。
第四种方法是通过调度框架(Scheduling Framework),Kubernetes v1.15 版本中引入了可插拔架构的调度框架,使得定制调度器这个任务变得更加的容易。调库框架向现有的调度器中添加了一组插件化的 API,该 API 在保持调度程序“核心”简单且易于维护的同时,使得大部分的调度功能以插件的形式存在,而且在现在的 v1.16 版本中上面的 调度器扩展程序也已经被废弃了,所以以后调度框架才是自定义调度器的核心方式。
2. 存储插件
是什么
K8s 已经提供丰富的 Volume 和 Persistent Volume 插件,可以根据需要使用这些插件给容器提供持久化存储。如果内置的这些 Volume 还不满足要求,K8s支持使用 FlexVolume 或者 容器存储接口CSI 来扩展实现自己的存储插件:
FlexVolume:是 Kubernetes v1.8+支持的一种存储插件扩展方式。类似于 CNI 插件,它需要外部插件将二进制文件放到预先配置的路径中,并需要在系统中安装好所有需要的依赖。这是一种out-tree的扩展方式,可以让用户挂载无需内建支持的卷类型,不需要新增加一种存储插件,也无需去更改k8s的源码。
CSI:Container Storage Interface是从 v1.9 引入的容器存储接口,实际上 CSI 是整个容器生态的标准存储接口,同样适用于 Mesos、Swarm 、Cloud Foundry 等其他的容器集群编排系统。CSI是通过CRD的形式(Operator)实现的。
有了Flexvolume,为何还要 CSI 呢?
Flexvolume 只是给 k8s 这一个编排系统来使用的,而CSI可以满足不同编排系统的需求,比如 Mesos,Swarm。
其次CSI是容器化部署,可以减少环境依赖,增强安全性,丰富插件的功能。Flexvolume 是在 host 空间一个二进制文件,执行 Flexvolum 时相当于执行了本地的一个 shell 命令,这使得我们在安装 Flexvolume 的时候需要同时安装某些依赖,而这些依赖可能会对客户的应用产生一些影响。因此在安全性上、环境依赖上,就会有一个不好的影响。
同时对于丰富插件功能这一点,在K8s生态中实现operator的时候,经常会通过 RBAC 这种方式去调用 K8s 的一些接口来实现某些功能,而这些功能必须要在容器内部实现,因此像 Flexvolume 这种环境,由于它是 host 空间中的二进制程序,就没法实现这些功能。而 CSI 这种容器化部署的方式则没有这个问题。
3. 网络插件
是什么
K8s通过CNI(Container Network Interface),即容器网络接口来调用不同的网络插件以实现不同的网络配置方式,实现了这个接口的就是CNI插件,常见的 CNI 插件包括 Calico、flannel、Terway、Weave Net 以及 Contiv。
分类
CNI插件可以分为下面三类:
Main插件
用来创建具体的网络设备的二进制文件,包括:
bridge:在宿主机上创建网桥然后通过veth pair的方式连接到容器
loopback:lo设备(将回环接口设置成up)
ptp:Veth Pair设备
vlan:分配vlan设备
host-device:移动宿主上已经存在的设备到容器中
IPAM插件
dhcp:宿主机上运行的守护进程,代表容器发出DHCP请求
Meta插件
指由CNI社区维护的内部插件,包括:
flannel: 专门为Flannel项目提供的插件
Calico:功能更全面,不仅提供主机与Pod之间的网络连接,还涉及网络安全和管理
Canal:试图将 Flannel 提供的网络层与 Calico 的网络策略功能集成在一起
Weave:在集群的每个节点之间创建网状overlay网络,参与者之间可灵活路由
AWS VPC CNI:为 Kubernetes 集群提供了集成的 AWS 虚拟私有云(VPC)网络
Azure CNI:将 Kubernetes Pods 和 Azure 虚拟网络集成在一起
华为CNI-Genie:可让K8s在运行时使用不同的网络模型的实现同时被访问。
CNI原理
CNI的思想就是在kubelet启动infra容器后,就可以直接调用CNI插件为这个infra容器的Network Namespace配置符合预期的网络栈。
4. 设备插件
是什么
K8s从v1.8开始引入了Device插件(即设备插件),用来支持GPU、FPGA、高性能 NIC、InfiniBand等各种设备。这样设备厂商只需要根据Device Plugin 的接口实现一个特定设备的插件,而不需要修改K8s核心代码,就可以将厂商自己生产的设备资源让kubelet使用。
目标设备包括GPU、高性能NIC(网络接口卡)、FPGA、InfiniBand以及其他类似的需要厂商指定初始化和安装的计算资源。
Device插件一般推荐使用DaemonSet的方式部署,并将/var/lib/kubelet/device-plugins以Volume的形式挂载到容器中。
设备插件原理
Device插件实际上是一个gPRC接口,需要实现 ListAndWatch()和Allocate()等方法:
插件示例
下面是一些设备插件实现的示例:
AMD GPU 设备插件
Intel 设备插件 支持 Intel GPU、FPGA 和 QuickAssist 设备
KubeVirt 设备插件用于硬件辅助的虚拟化
NVIDIA GPU 设备插件
RDMA 设备插件
Solarflare 设备插件
SR-IOV 网络设备插件
Xilinx FPGA 设备插件
三、结语
K8s灵活丰富的扩展机制为其提供了强大的扩展能力,能让业务方在不修改K8s源码的情况下,以非侵入的方式扩展实现自己在容器编排方面的个性化需求。其中,Operator是目前业内使用最广泛的一种扩展方式,应重点掌握。
以上是关于浅谈K8s的扩展体系的主要内容,如果未能解决你的问题,请参考以下文章