MapReduce之WordCount实战——统计某电商网站买家收藏商品数量
Posted Leokadia Rothschild
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MapReduce之WordCount实战——统计某电商网站买家收藏商品数量相关的知识,希望对你有一定的参考价值。
MapReduce之WordCount实战——统计某电商网站买家收藏商品数量
文章目录
预习内容:
一、实验目的和要求∶
了解基本的MapReduce程序结构
二、实验任务∶
现有某电商网站用户对商品的收藏数据,记录了用户收藏的商品id以及收藏日期,名为buyer_favorite1。
buyer_favorite1包含:买家id,商品id,收藏日期这三个字段,数据以“\\t”分割。
数据样例与格式如下:
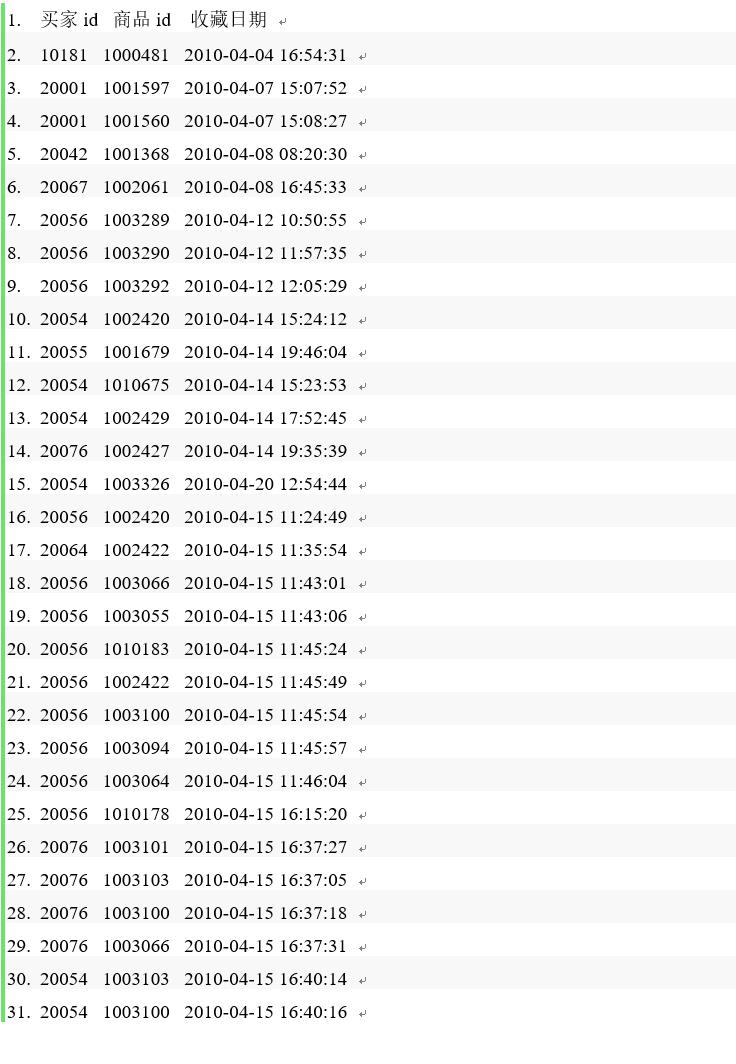
要求编写MapReduce程序,统计每个买家收藏商品数量,并撰写实验报告。
三、实验准备方案,包括以下内容:
(硬件类实验:实验原理、实验线路、设计方案等)
(软件类实验:所采用的系统、组件、工具、核心方法、框架或流程图、程序清单等)
- 设备:一台windows10宿主机,三台linux(centos8)虚拟机
- 节点:hadoop102,hadoop103,hadoop104
- 模板机::hadoop100
- 文件传输软件: Xftp6
- 开发平台:hadoop-3.1.3
- 集成开发环境:XSHELL,IDEA
实验内容
一、 实验用仪器、设备:
宿主机配置如下:
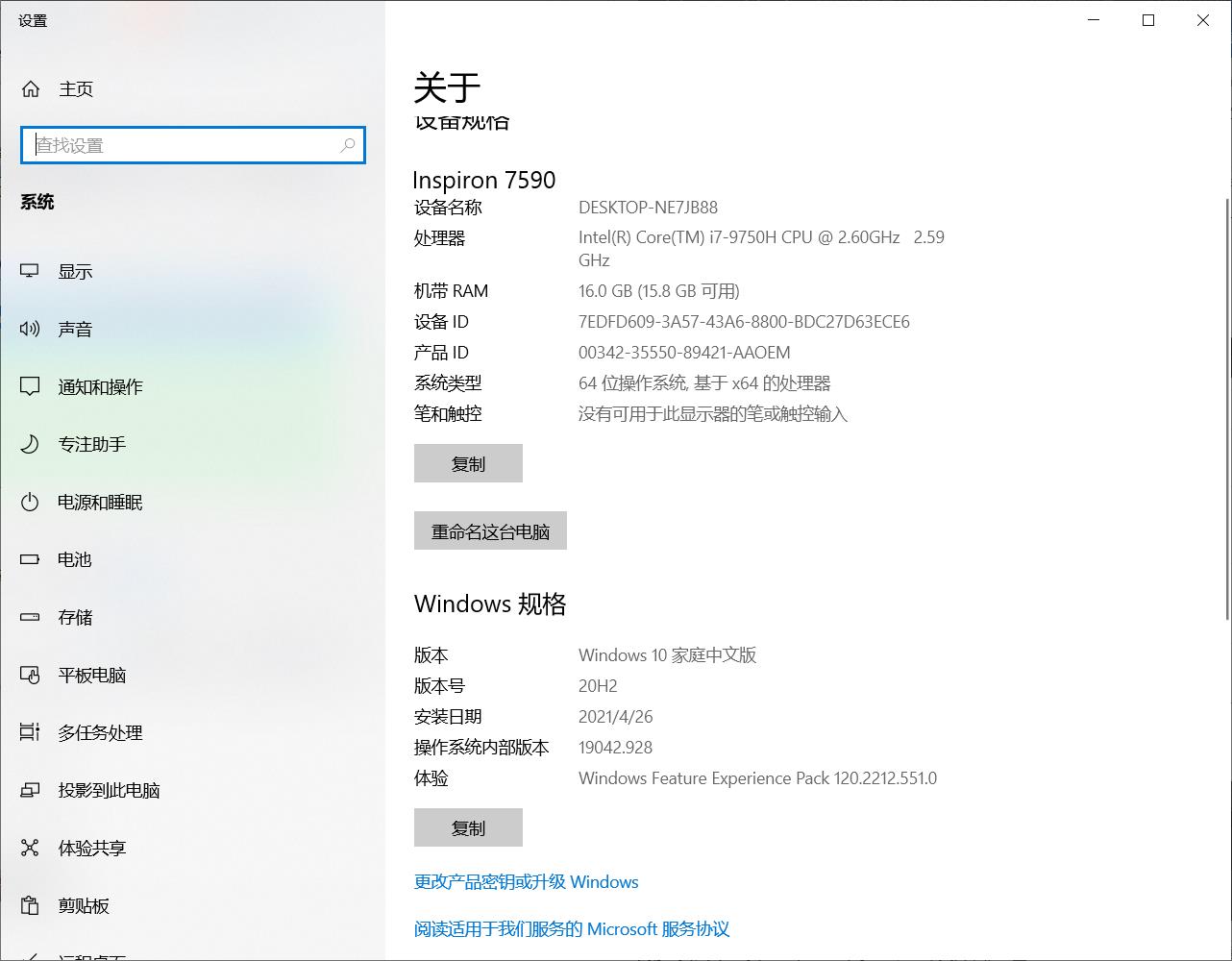
三台虚拟机配置如下:
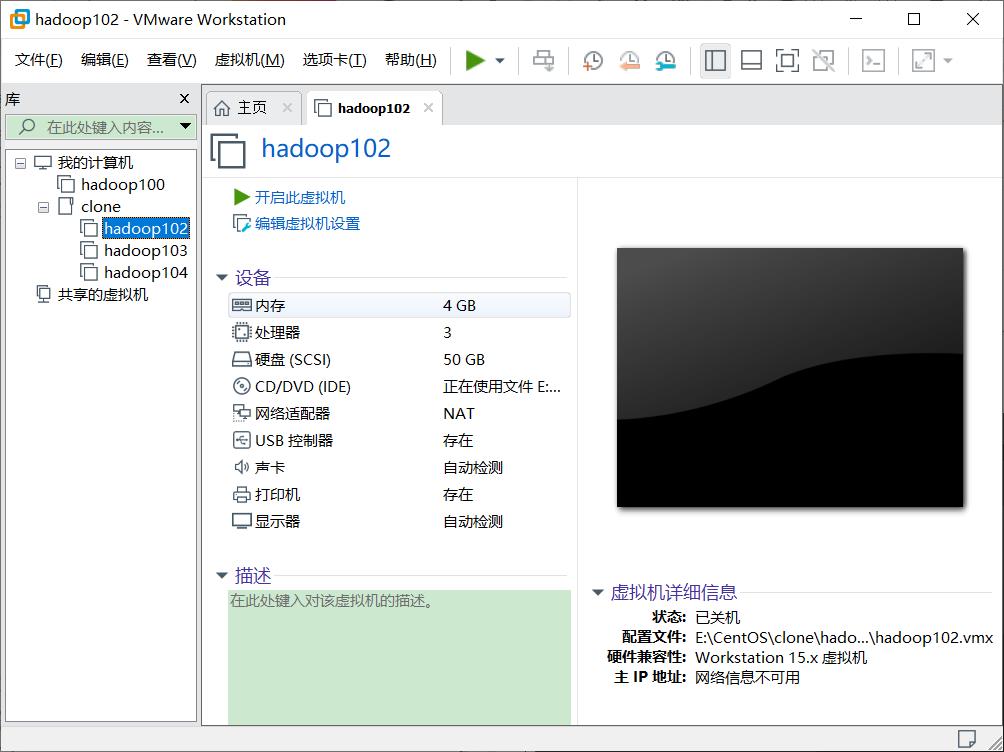
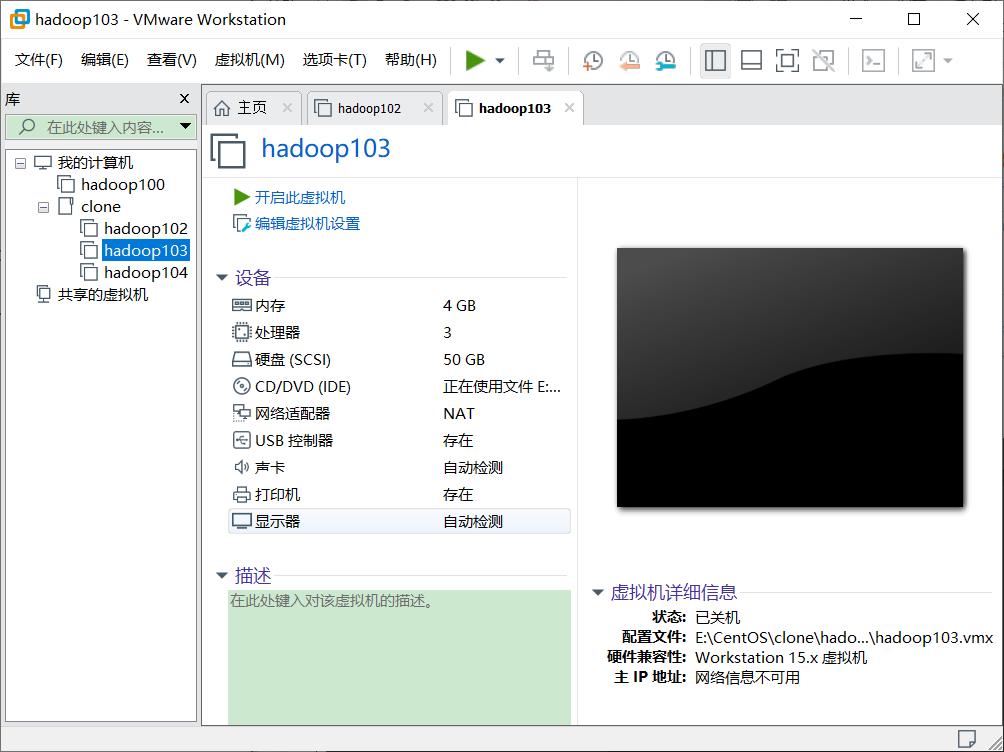
二、实验内容与步骤(过程及数据记录):
1. 前置的输入数据准备
首先创建数据文件shop.txt:
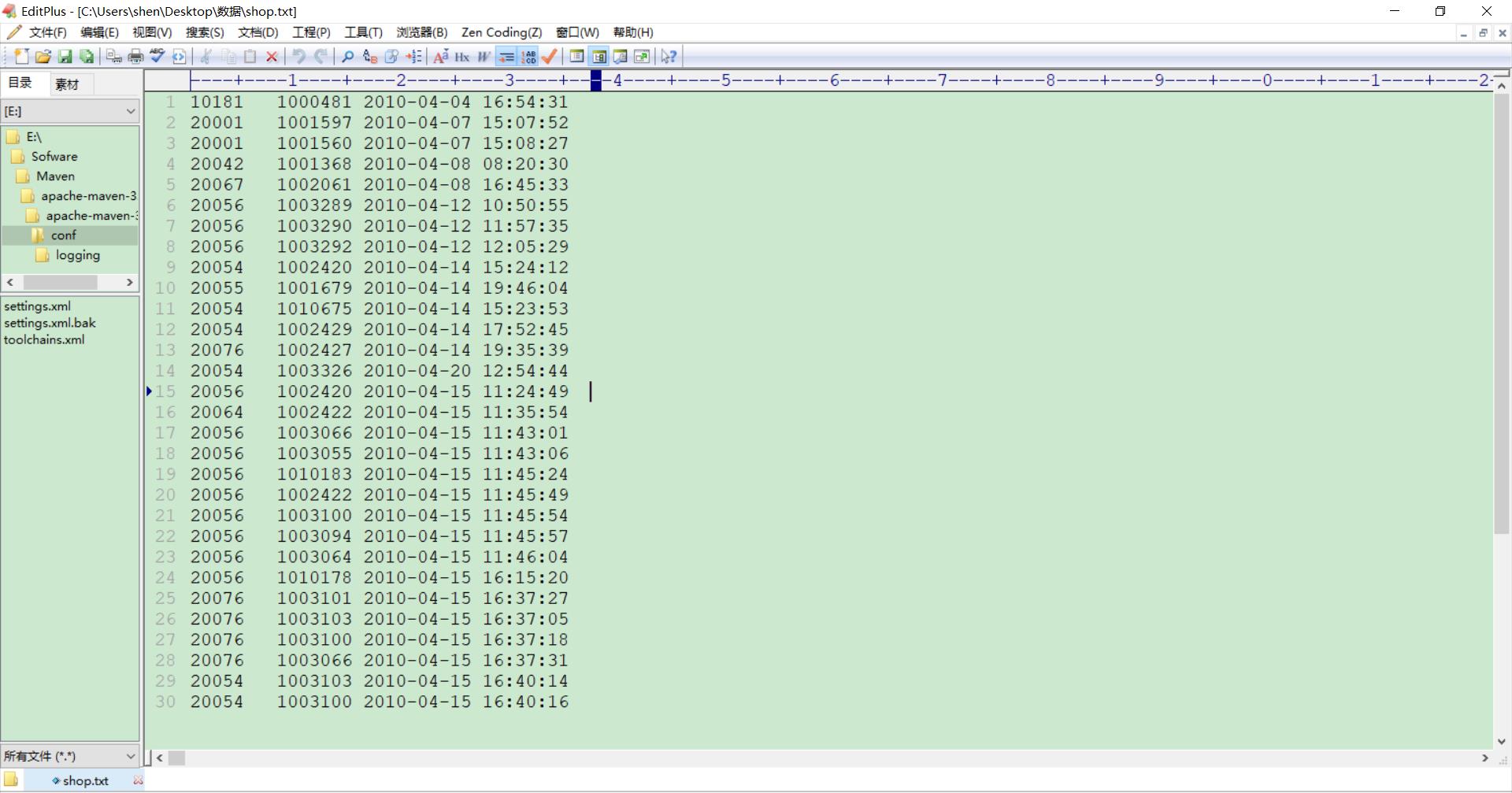
在hadoop-3.1.3目录下创建一个文件夹装数据,具体步骤如下:
[leokadia@hadoop102 ~]$ cd $HADOOP_HOME
[leokadia@hadoop102 hadoop-3.1.3]$ mkdir shopData
然后进入创建好的装数据的文件夹shopData
[leokadia@hadoop102 hadoop-3.1.3]$ cd shopData/
将刚刚创建的shop.txt直接拖拽到里面
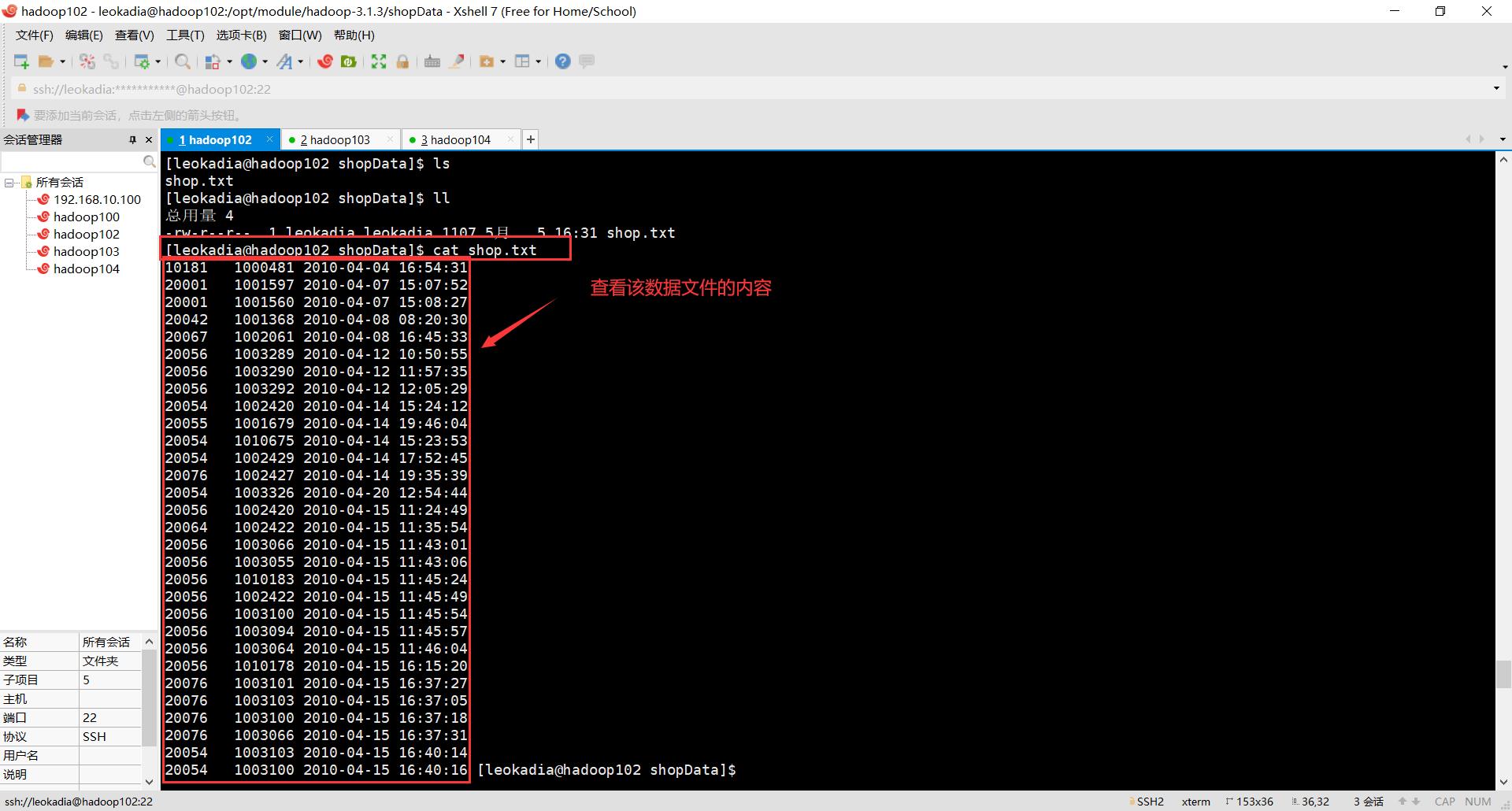
然后可以查看一下(检查一下我们导入的数据是不是我们刚刚设置的数据)
[leokadia@hadoop102 shopData]$ cat shop.txt
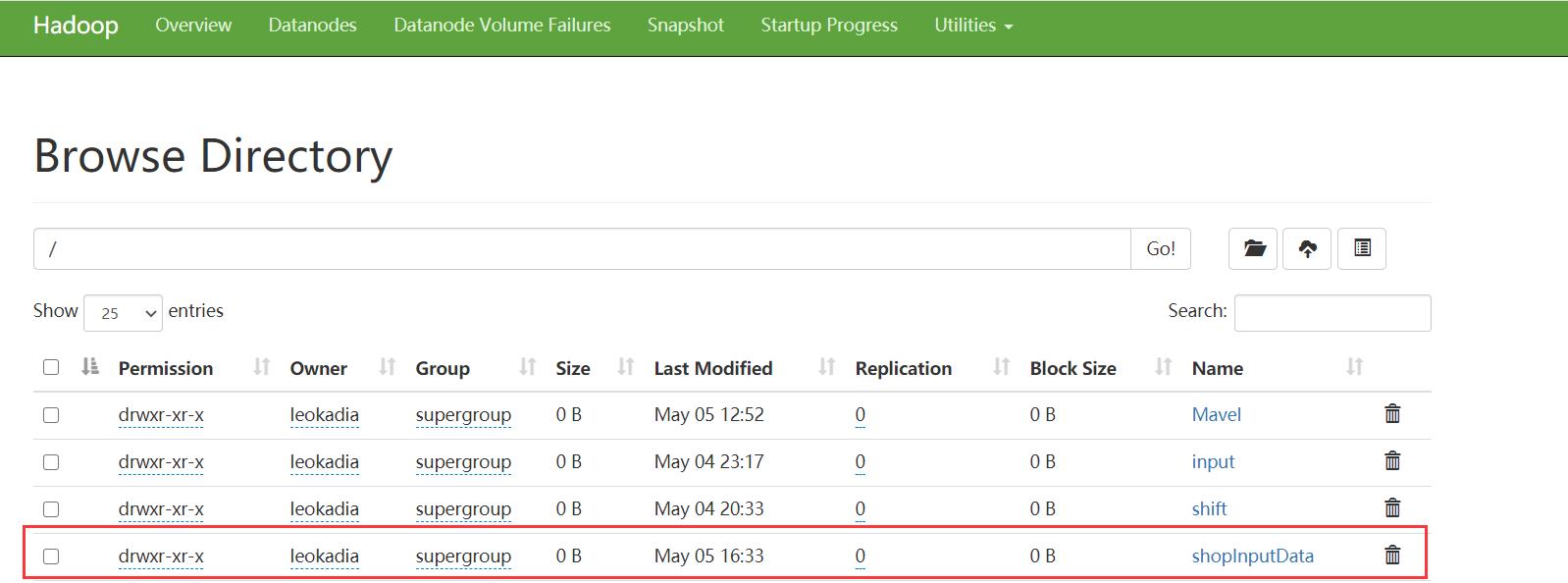
在HDFS根目录下建立一个文件夹shoplnputData
[leokadia@hadoop102 shopData]$ hadoop fs -mkdir /shopInputData
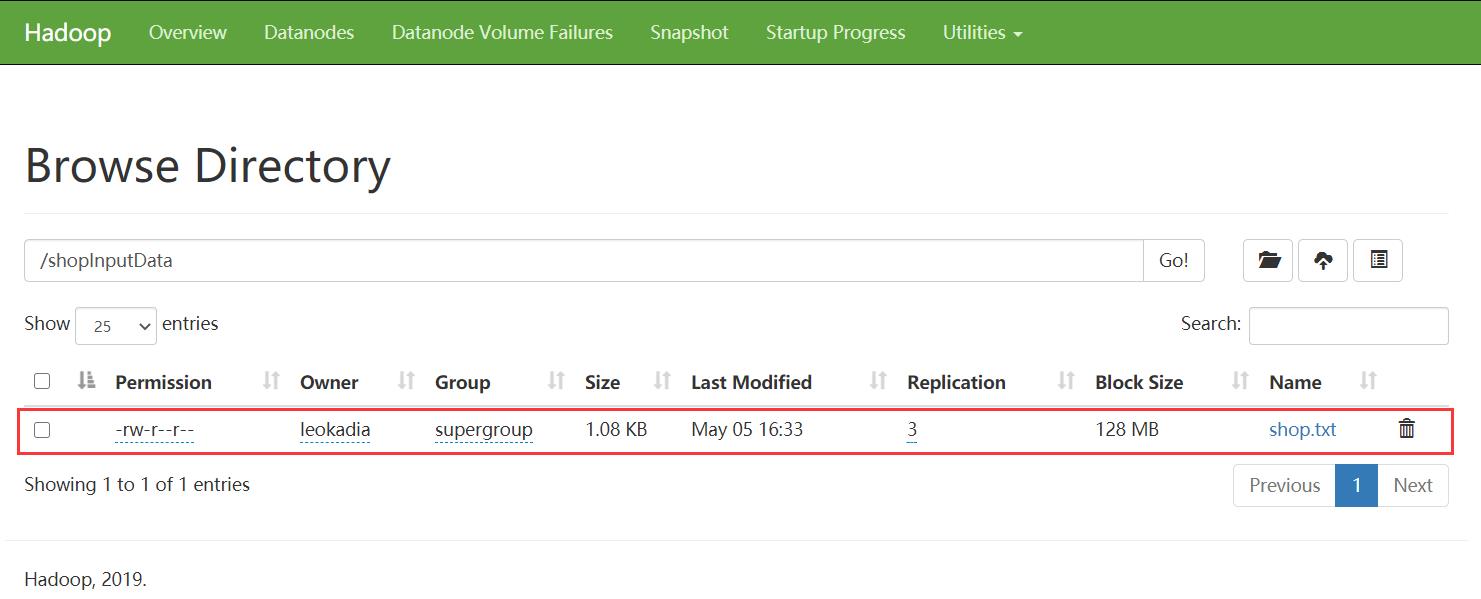
从本地拷贝数据文件shop.txt到刚刚HDFS中刚刚新建的shoplnputData文
[leokadia@hadoop102 shopData]$ hadoop fs -put shop.txt /shopInputData

2. 开始编写任务程序
1 )环境准备
(1)创建 maven 工程,MapReduceDemo
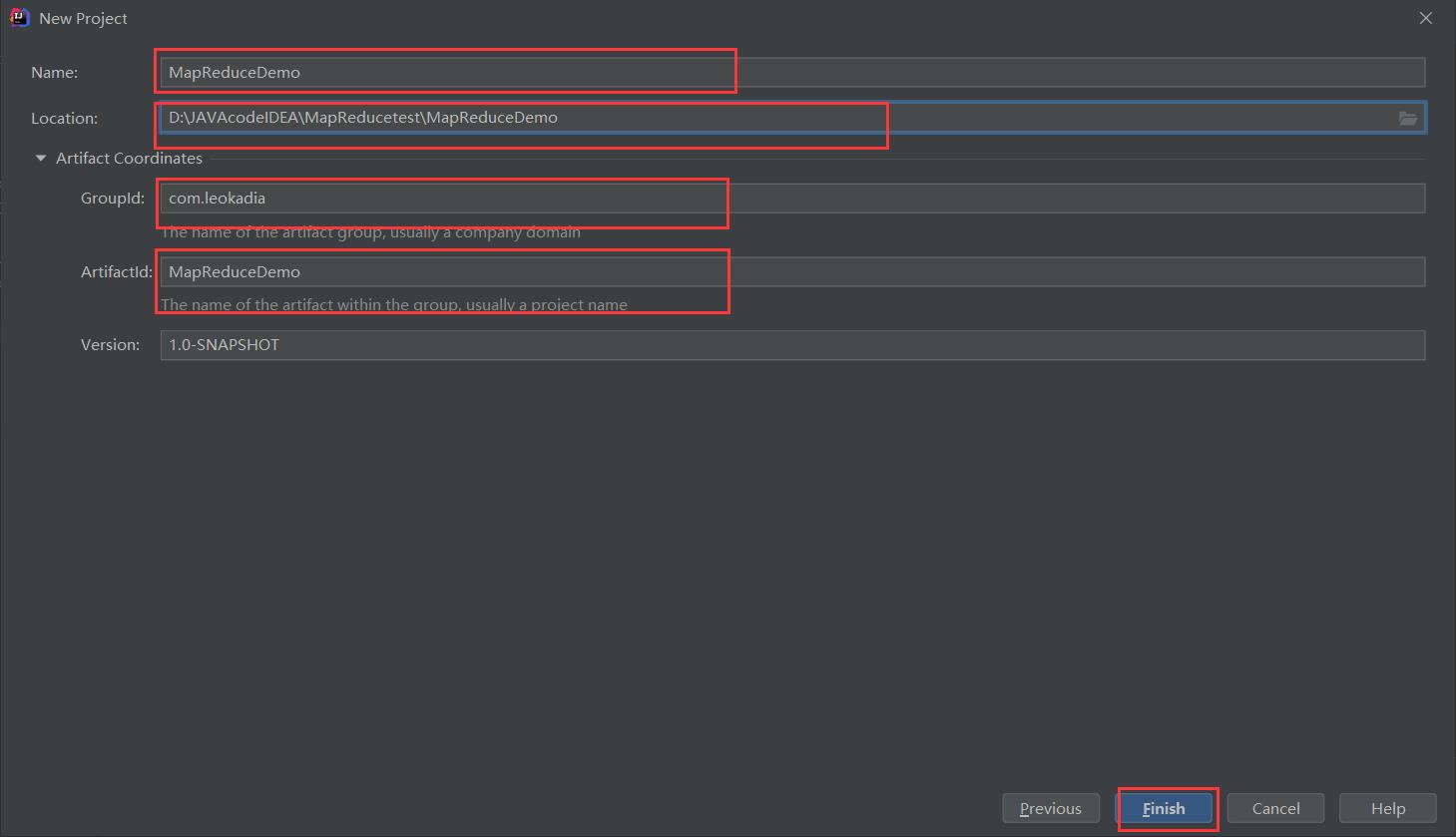
按照之前的修改成自己的Maven仓库,相关内容可参考:
HDFS的API环境准备小知识——Maven 安装与配置
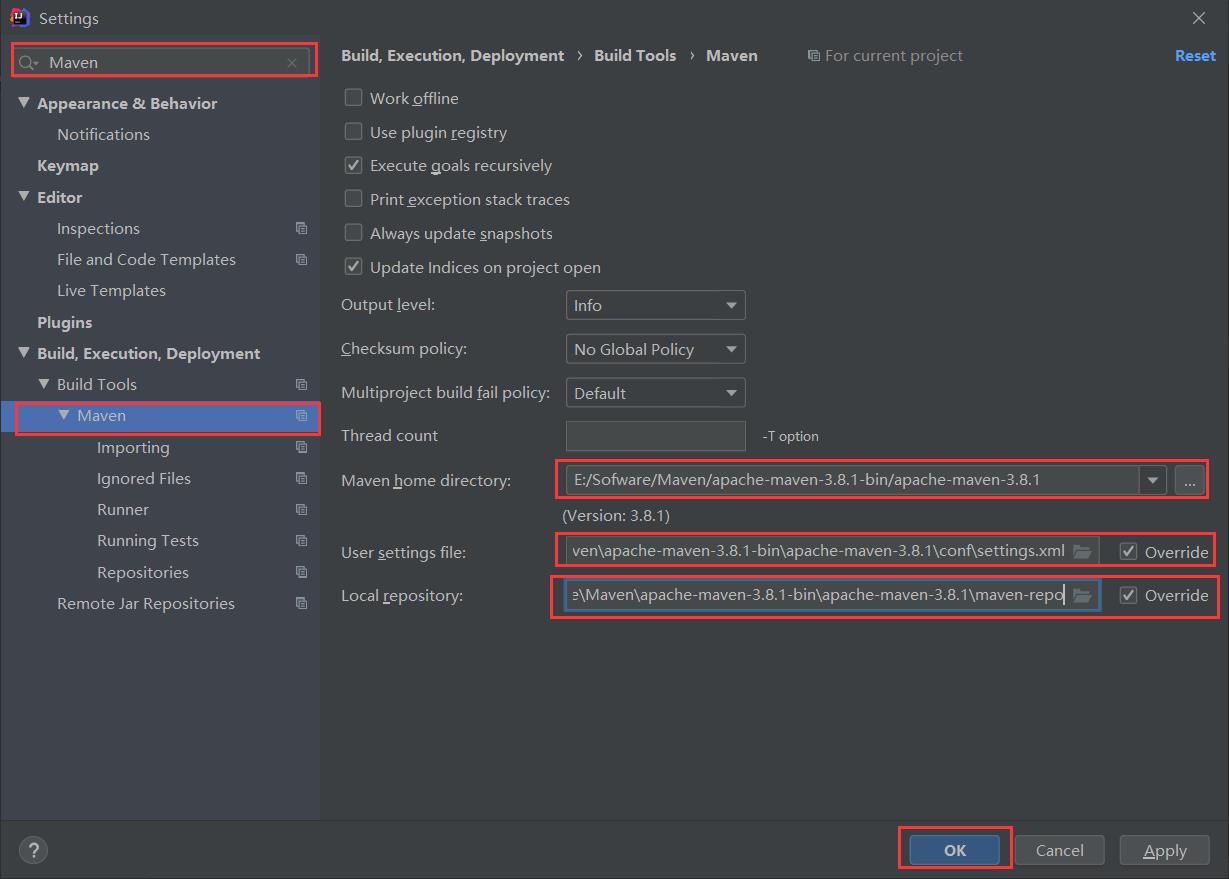
然后将相关java编译器配成自己的版本
注意:由于hadoop3.x支支持JDK8,建议所有的环境都配成8
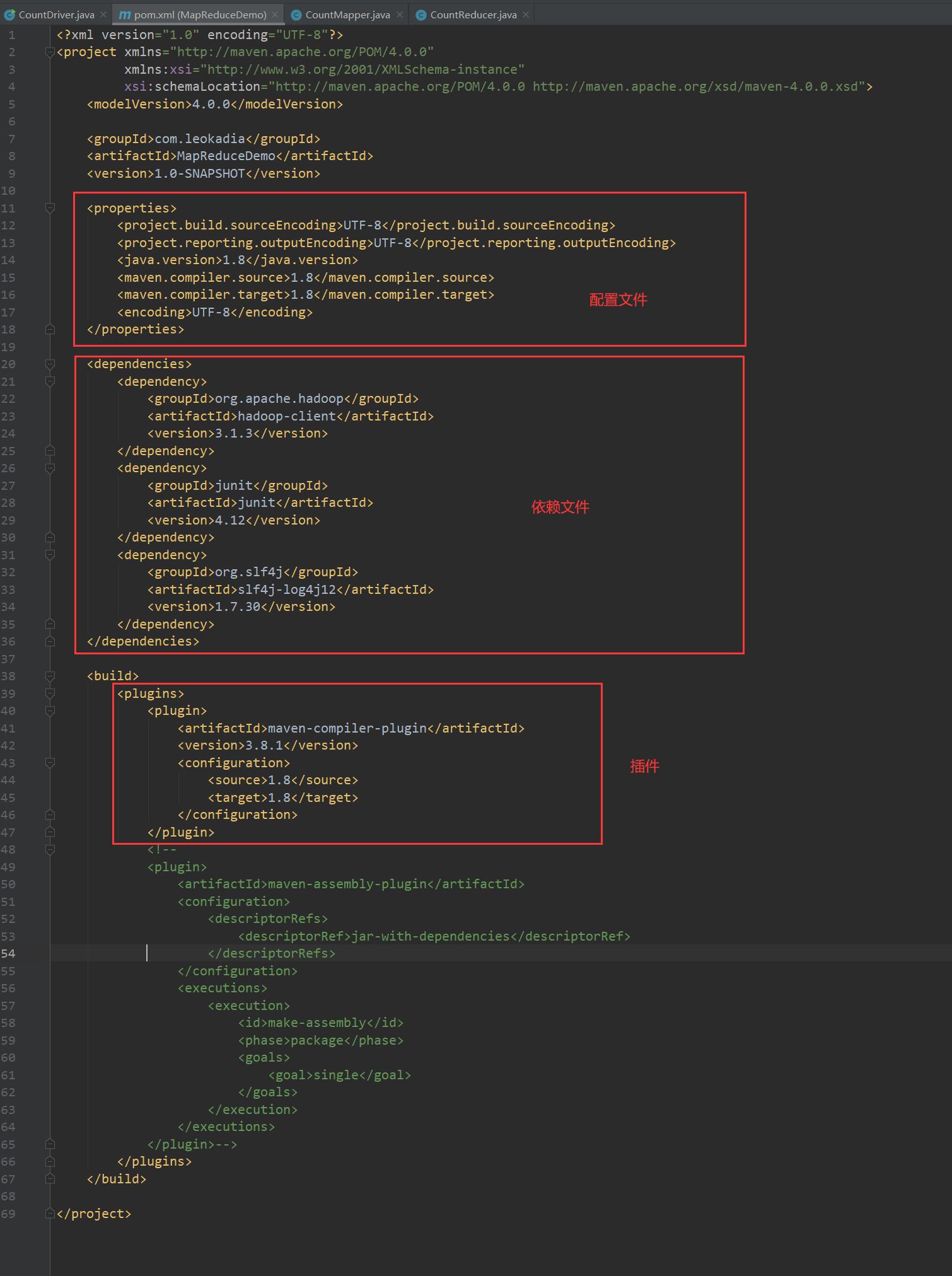
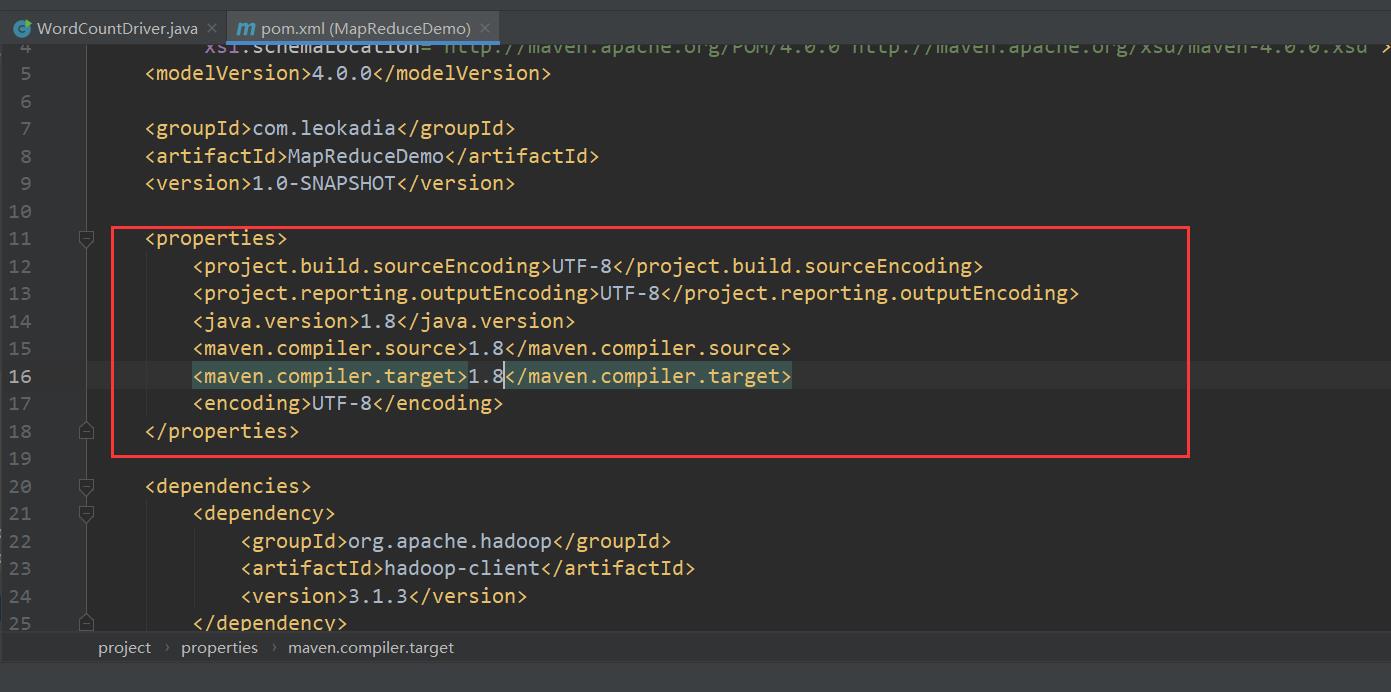
(2)在 pom.xml 文件中添加版本信息以及相关依赖
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding>
<java.version>1.8</java.version>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
<encoding>UTF-8</encoding>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.1.3</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>1.7.30</version>
</dependency>
</dependencies>
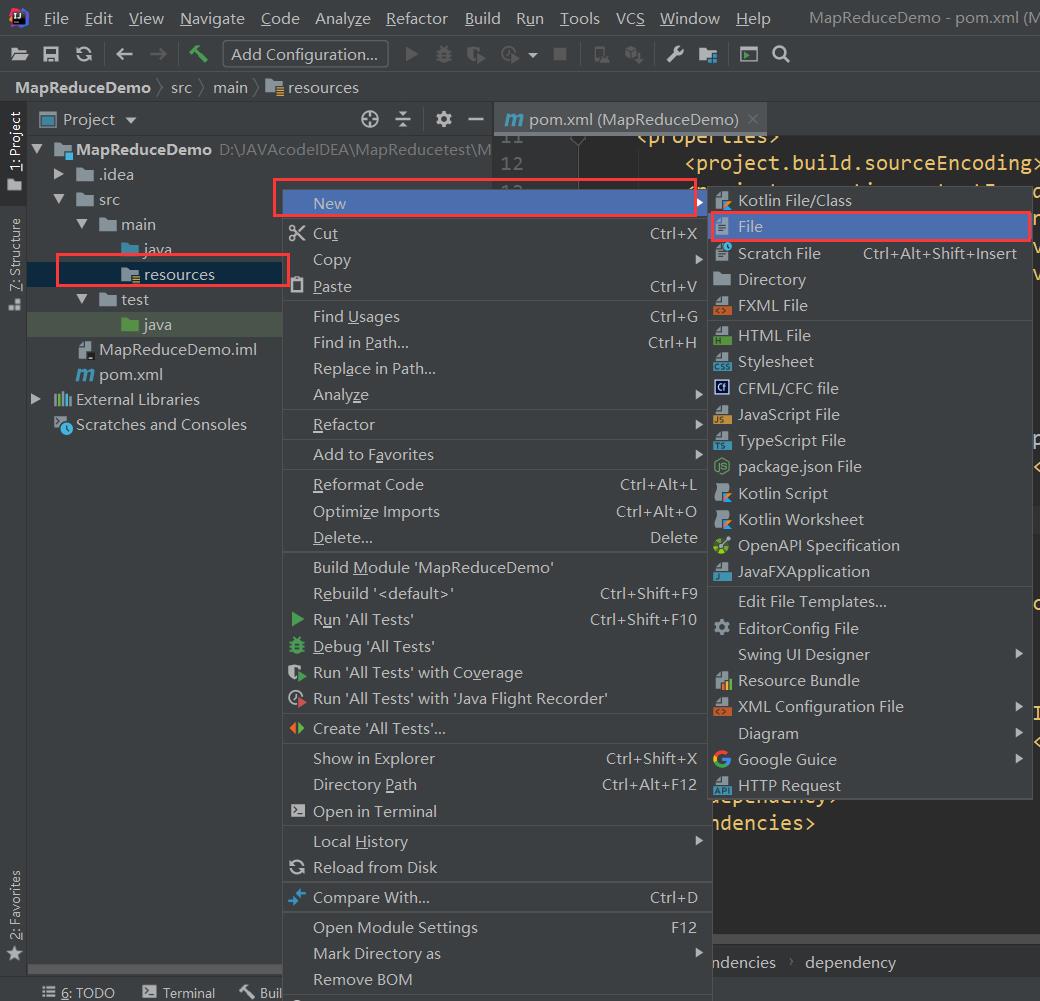
(3)在项目的 src/main/resources 目录下,新建一个文件,命名为“log4j.properties”(打印相关日志)

在文件中填入:
log4j.rootLogger=INFO, stdout
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d %p [%c] - %m%n
log4j.appender.logfile=org.apache.log4j.FileAppender
log4j.appender.logfile.File=target/spring.log
log4j.appender.logfile.layout=org.apache.log4j.PatternLayout
log4j.appender.logfile.layout.ConversionPattern=%d %p [%c] - %m%n
(4)创建包名:com.leokadia.count
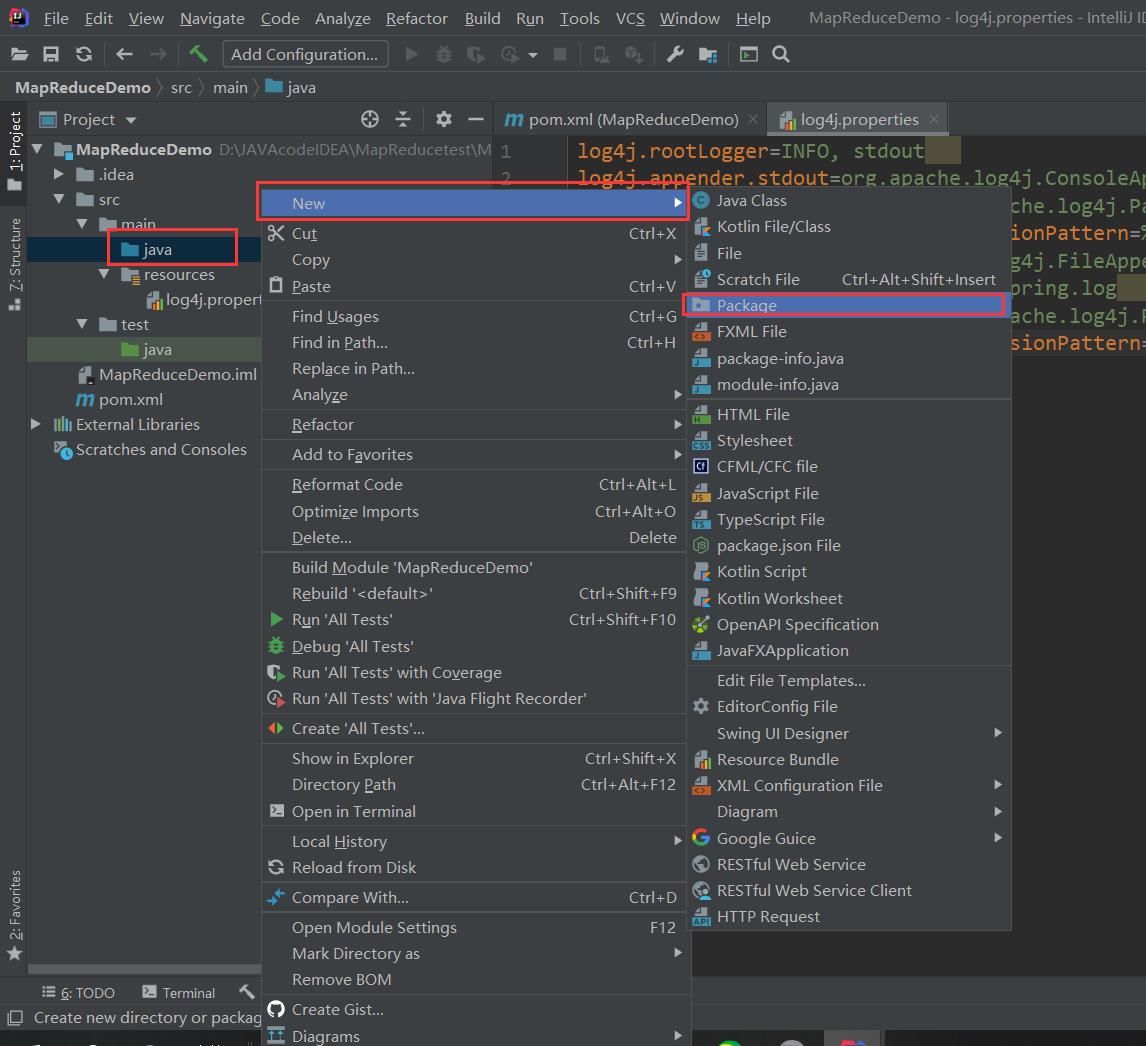
并在包下创建三个java类:
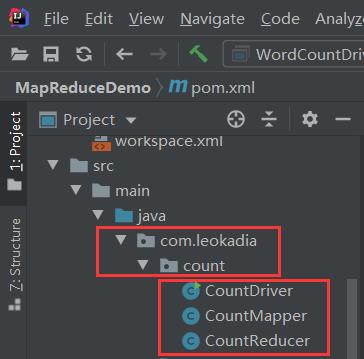
2 ) 编写程序
(1)编写 Mapper 类
package com.leokadia.count;
/**
* @author sa
* @create 2021-04-25 16:51
*/
import java.io.IOException;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class CountMapper extends Mapper<LongWritable, Text, Text, Text>
{
private Text outK = new Text();
private Text outV = new Text();
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, Text>.Context context)
throws IOException, InterruptedException
{
String[] split = value.toString().split("\\t");
this.outK.set(split[0]);
this.outV.set(split[1]);
context.write(this.outK, this.outV);
}
}
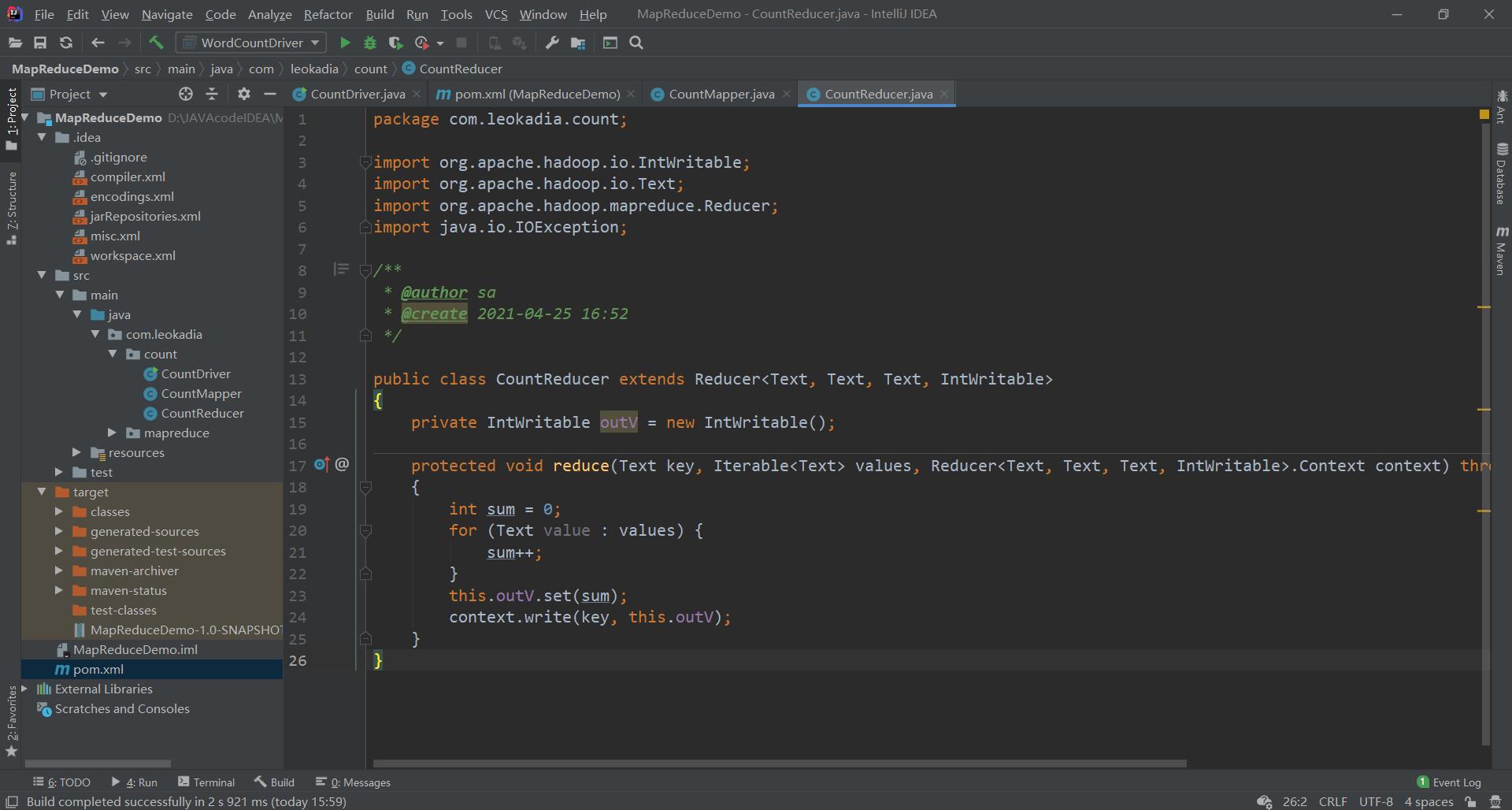
(2)编写 Reducer 类
package com.leokadia.count;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
/**
* @author sa
* @create 2021-04-25 16:52
*/
public class CountReducer extends Reducer<Text, Text, Text, IntWritable>
{
private IntWritable outV = new IntWritable();
protected void reduce(Text key, Iterable<Text> values, Reducer<Text, Text, Text, IntWritable>.Context context) throws IOException, InterruptedException
{
int sum = 0;
for (Text value : values) {
sum++;
}
this.outV.set(sum);
context.write(key, this.outV);
}
}
(3)编写 Driver 驱动类
package com.leokadia.count;
/**
* @author sa
* @create 2021-04-25 16:51
*/
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
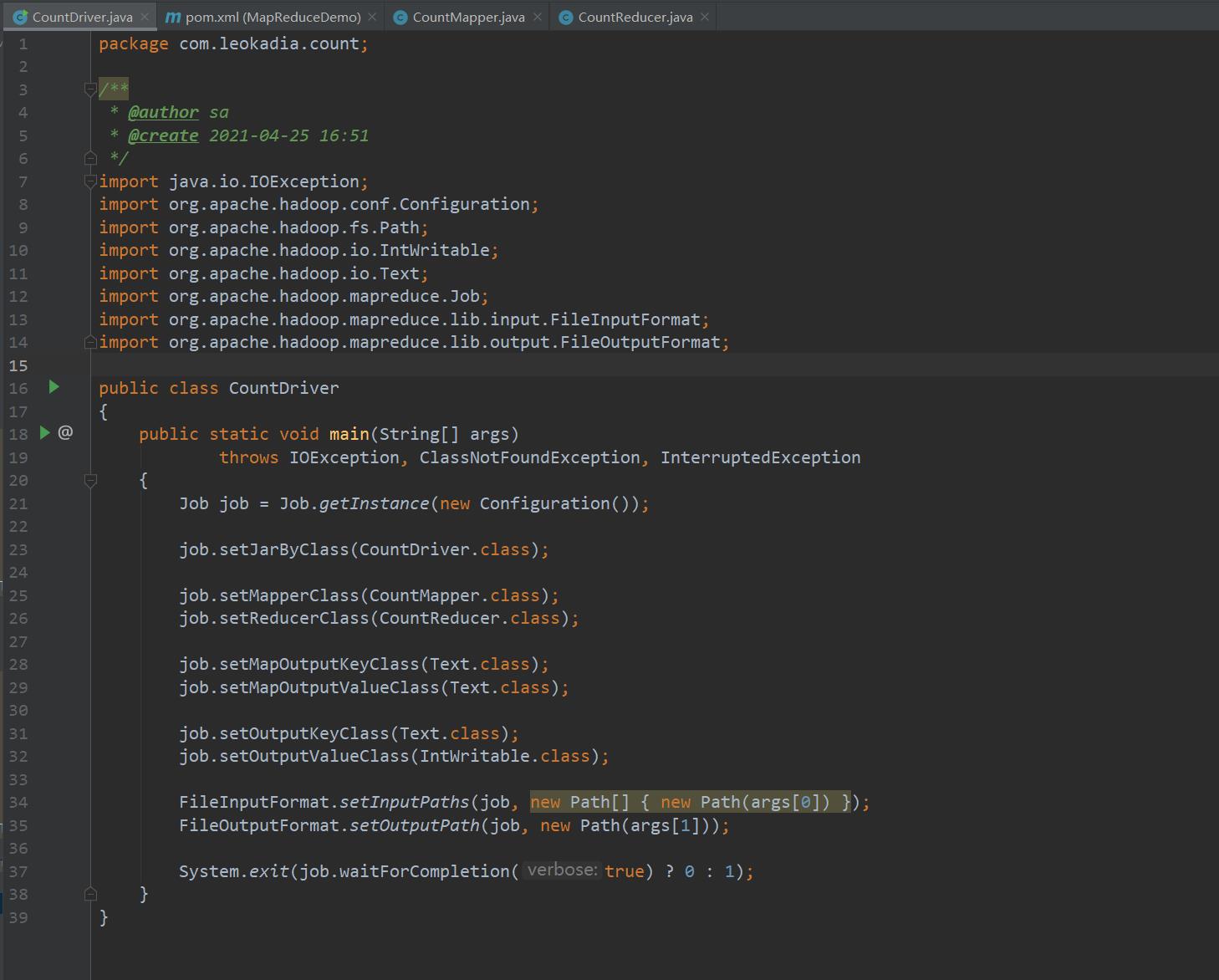
public class CountDriver
{
public static void main(String[] args)
throws IOException, ClassNotFoundException, InterruptedException
{
Job job = Job.getInstance(new Configuration());
job.setJarByClass(CountDriver.class);
job.setMapperClass(CountMapper.class);
job.setReducerClass(CountReducer.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.setInputPaths(job, new Path[] { new Path(args[0]) });
FileOutputFormat.setOutputPath(job, new Path(args[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
3 ) 提交到集群测试
在linux虚拟机上去运行
集群上测试
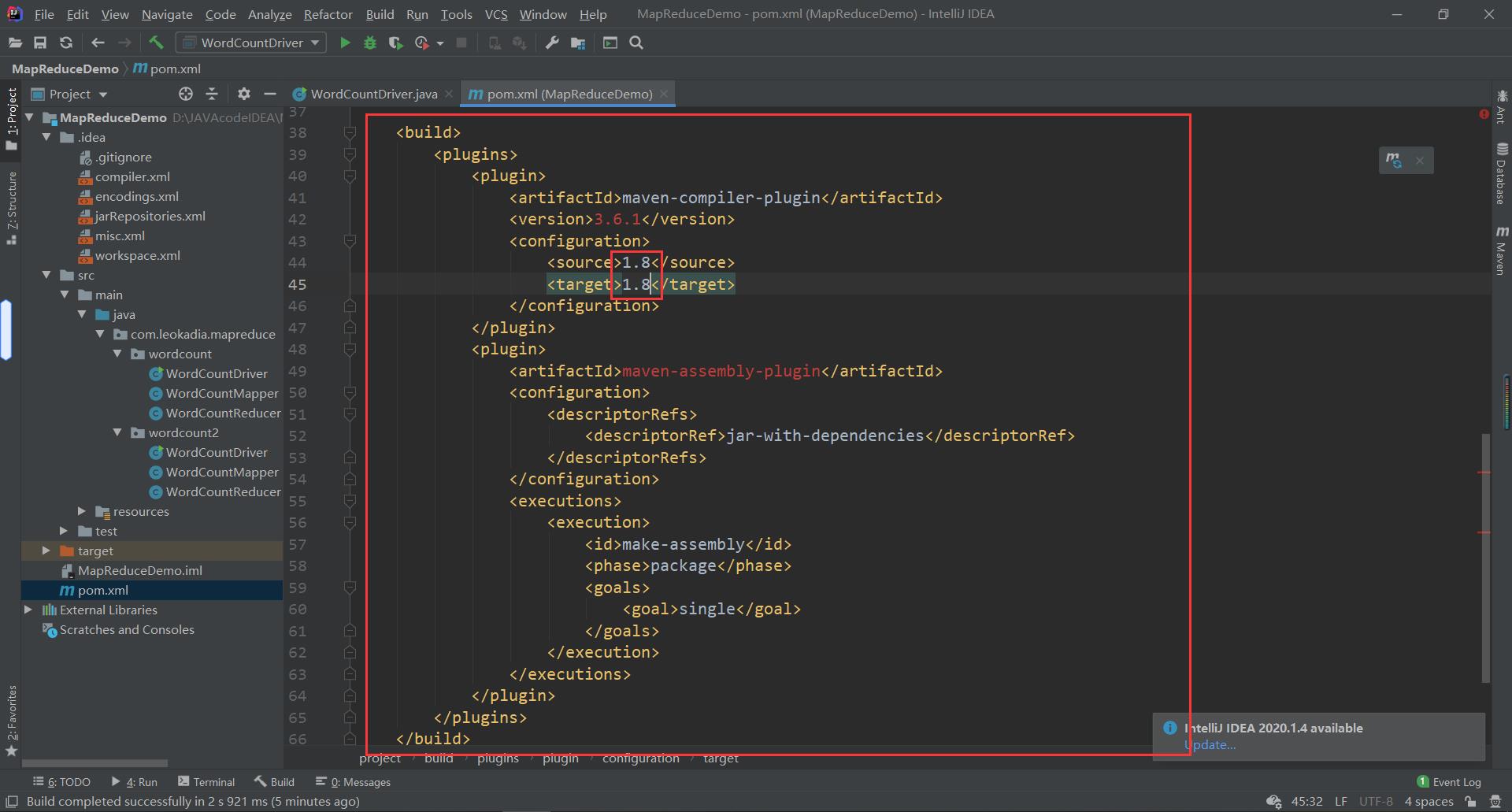
(1)用 maven 打 jar 包,需要添加的打包插件依赖
将下面的代码放在之前配置的依赖后面
<build>
<plugins>
<plugin>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.8.1</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
<plugin>
<artifactId>maven-assembly-plugin</artifactId>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
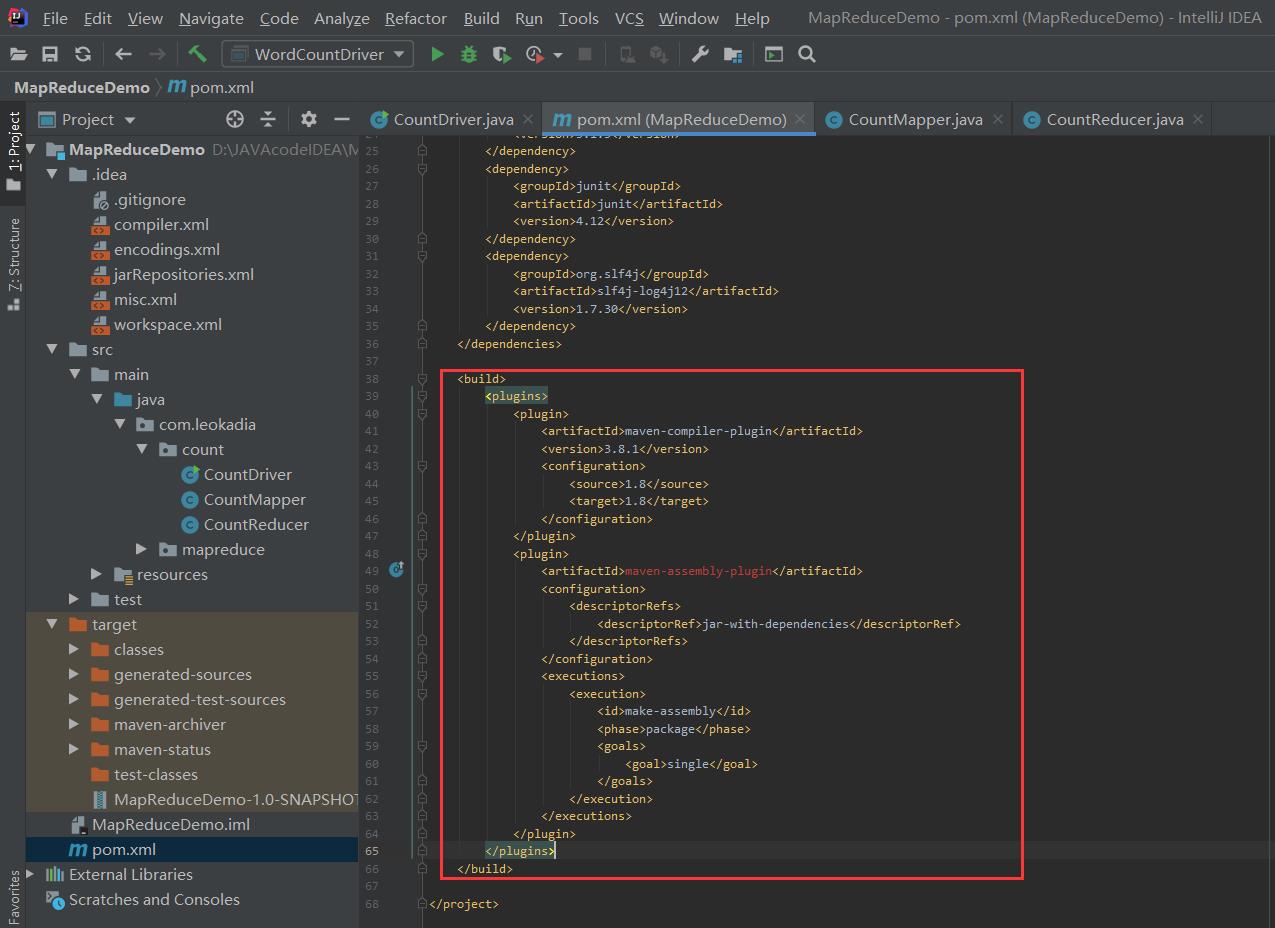
注意:如果工程上显示红叉。在项目上右键->maven->Reimport 刷新即可。
(2)将程序打包成 jar 包
点击右边Maven,先点击clean再点击package打包
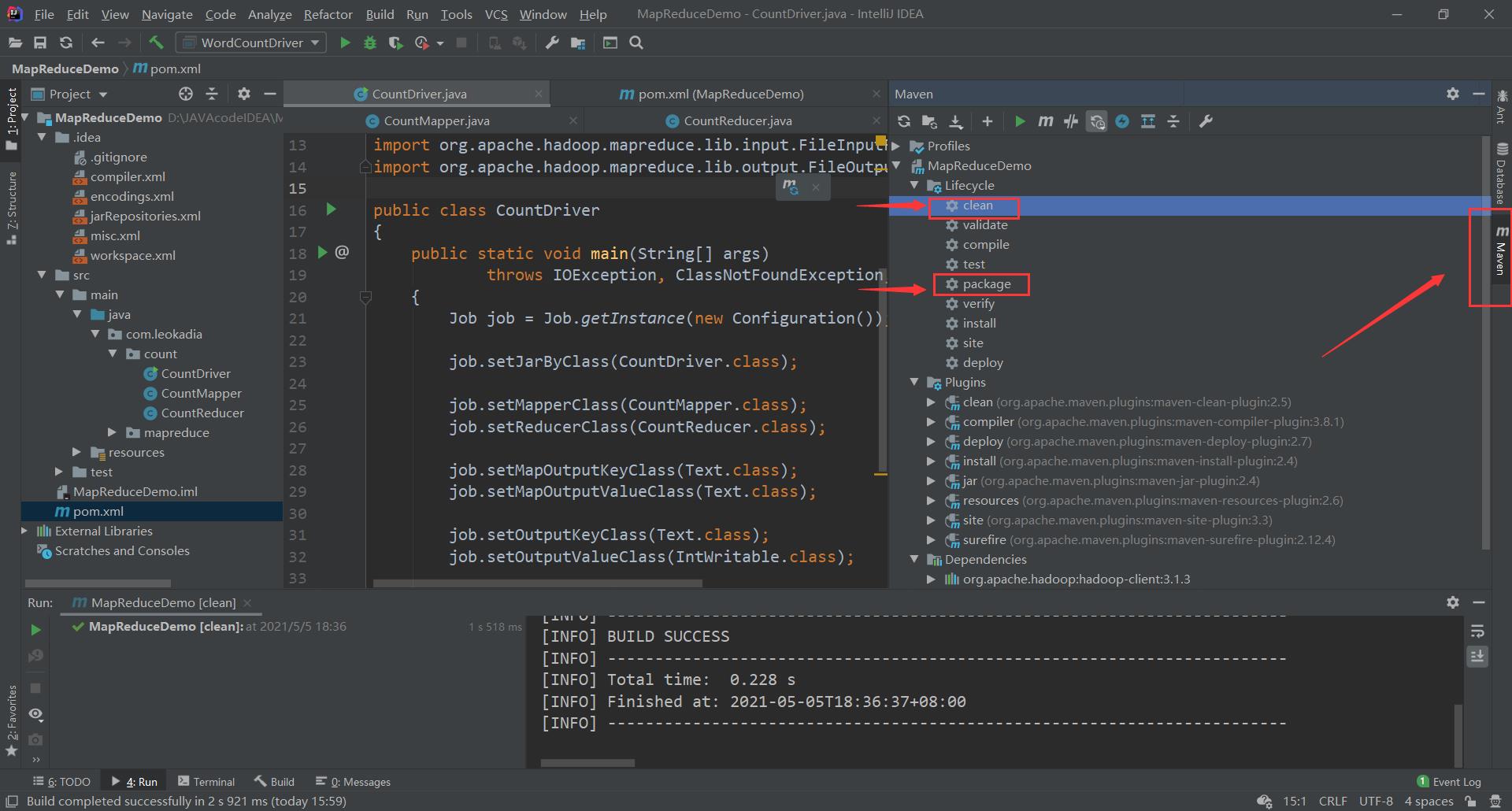
左边出现jar包,上面的是不带依赖的,下面的是带依赖的,由于我们的hadoop集群中已经配置了相关文件,所以用上面的即可。
在文件夹中查看它
从文件夹中复制到桌面,并更名pCount.jar

(3)将jar包导入到hadoop集群中
将其拖拽到hadoop中
使shopData中有pCount.jar
然后运行
(4)执行程序
[leokadia@hadoop102 shopData]$ hadoop jar pCount.jar com.leokadia.count.CountDriver /shopInputData /shopOutputData
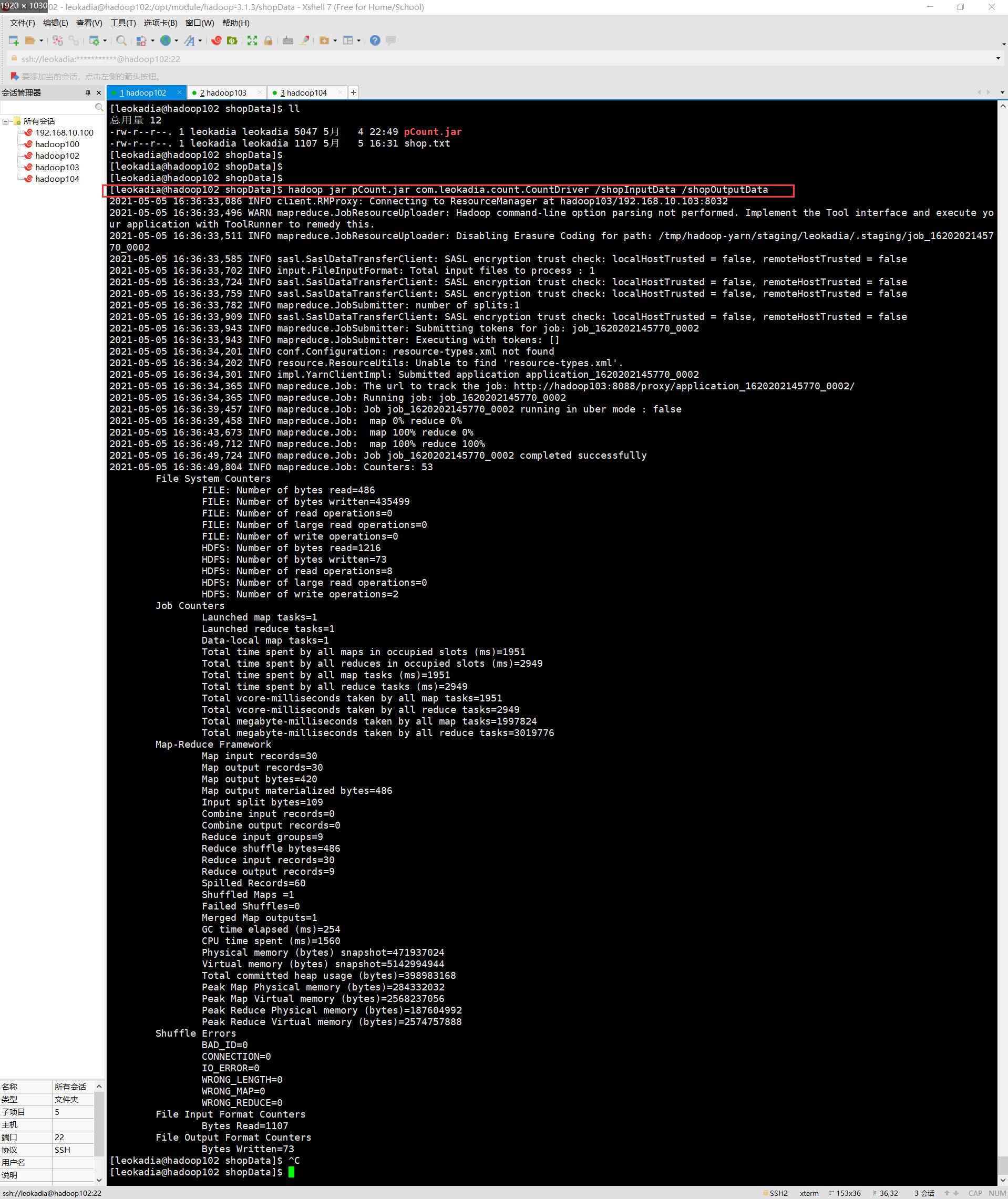
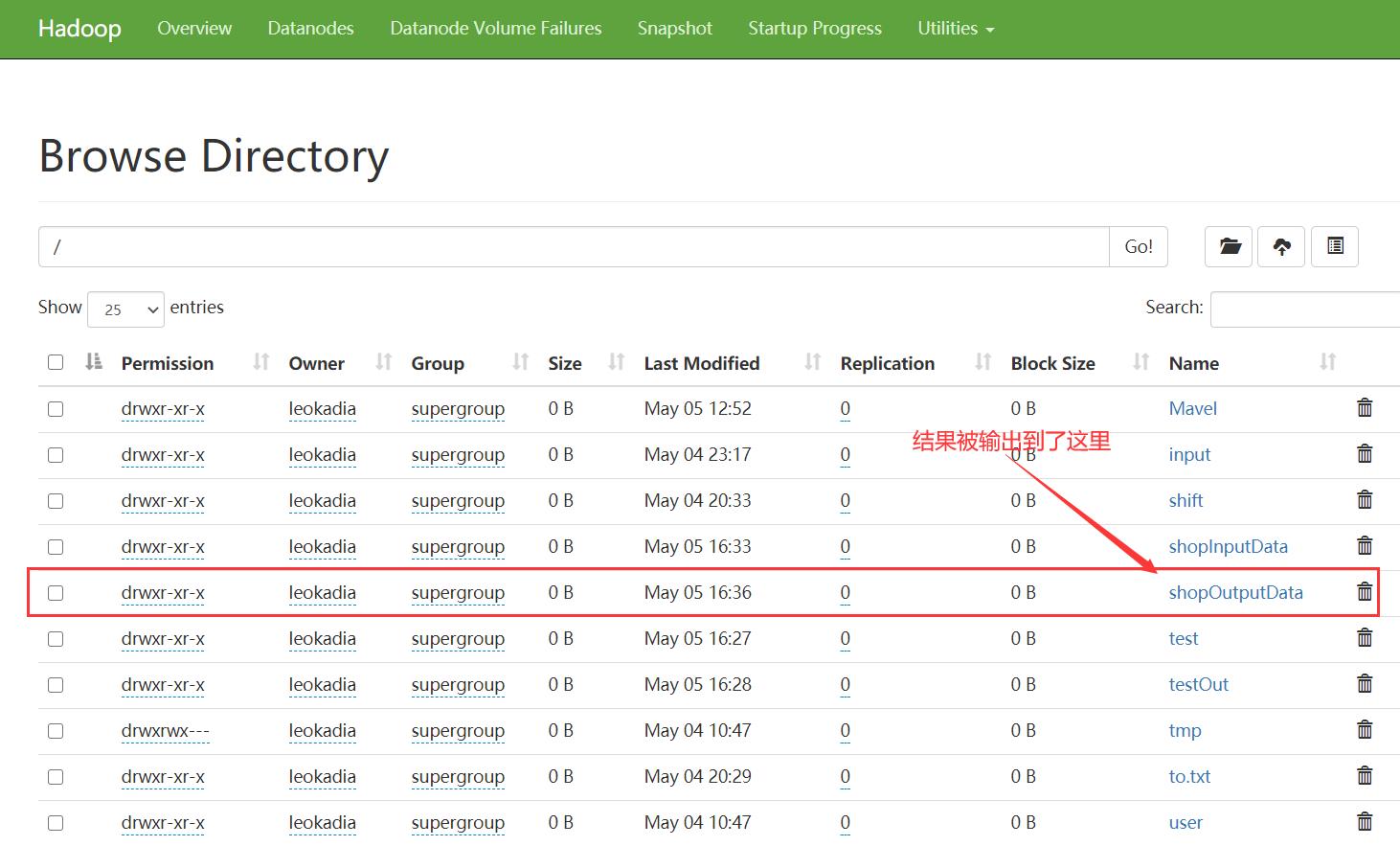
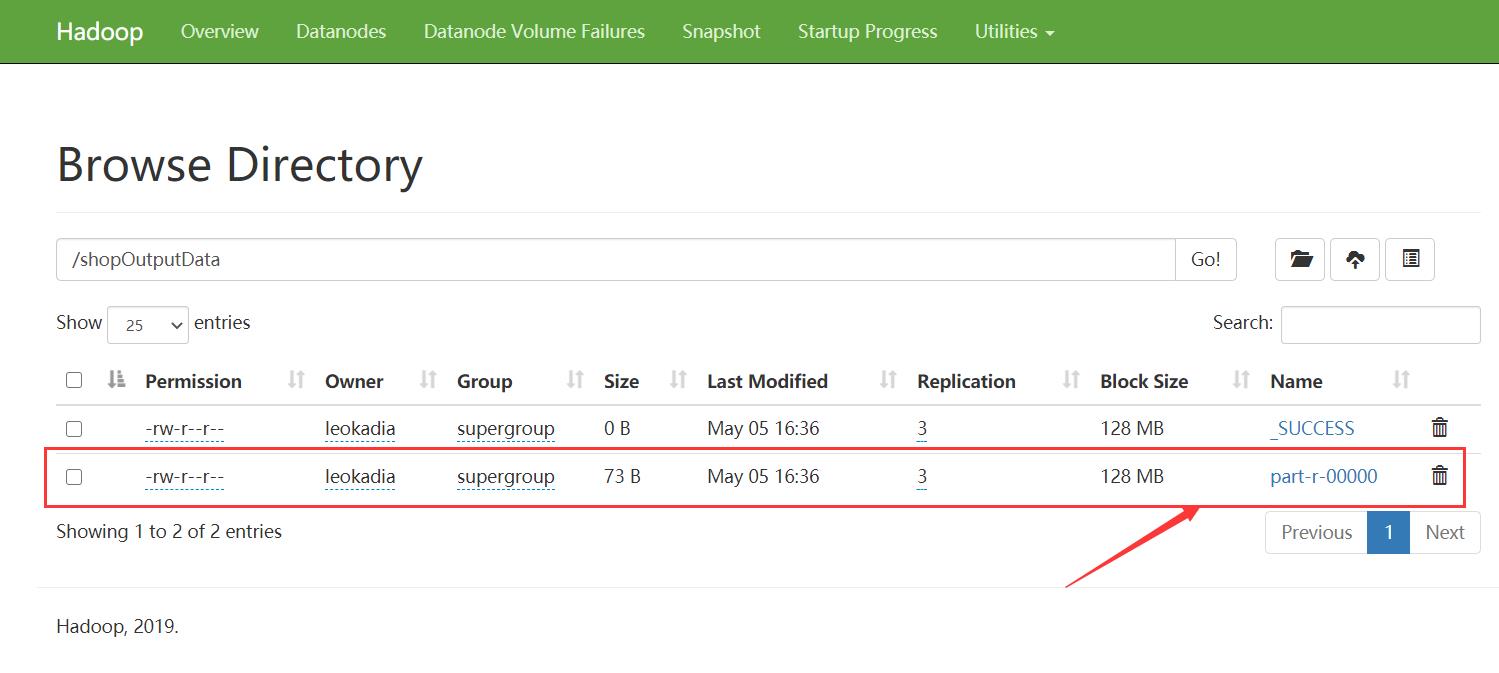
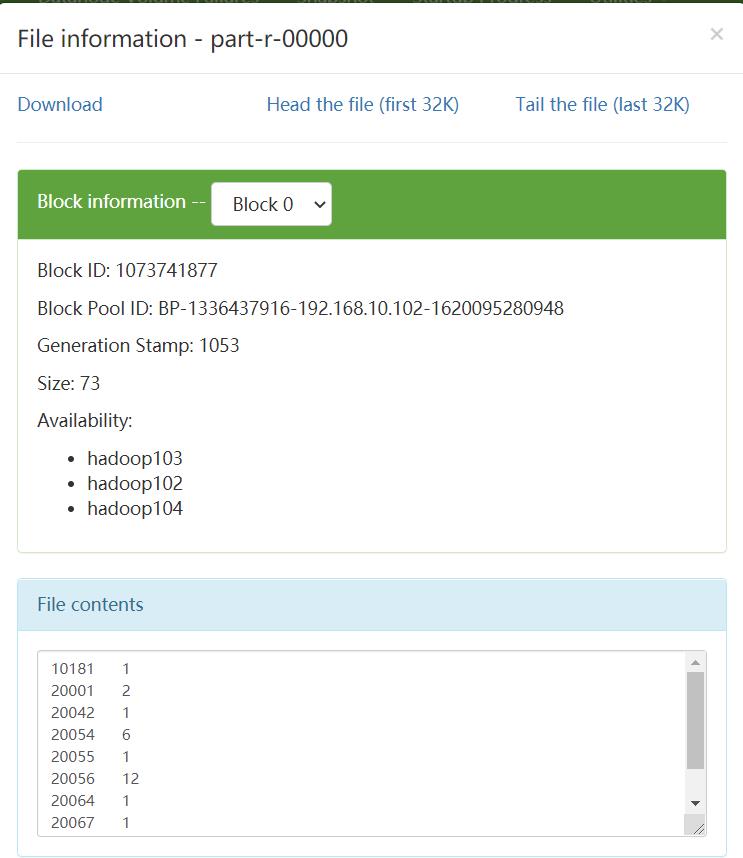
结果示例:

三、感想、体会、建议∶
在执行wordcount程序时
[leokadia@hadoop102 hadoop-3.1.3]$ hadoop jar wc.jar com.leokadia.mapreduce.wordcount2.WordCountDriver /user/leokadia/Marvel /user/leokadia/output
我本以为最后一步就大功告成了,但报出以下错误
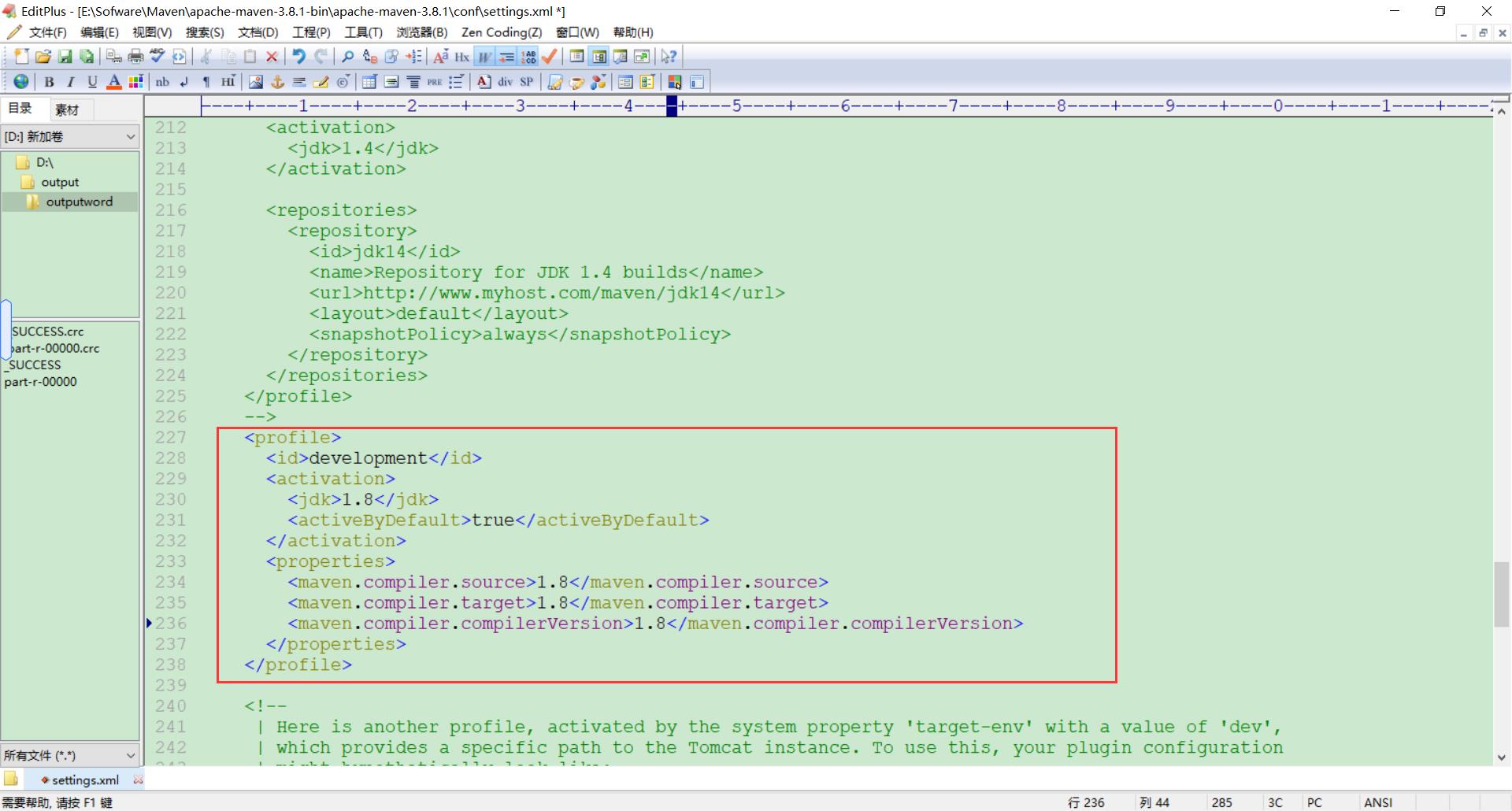
原来java本地版本与hadoop的版本不兼容
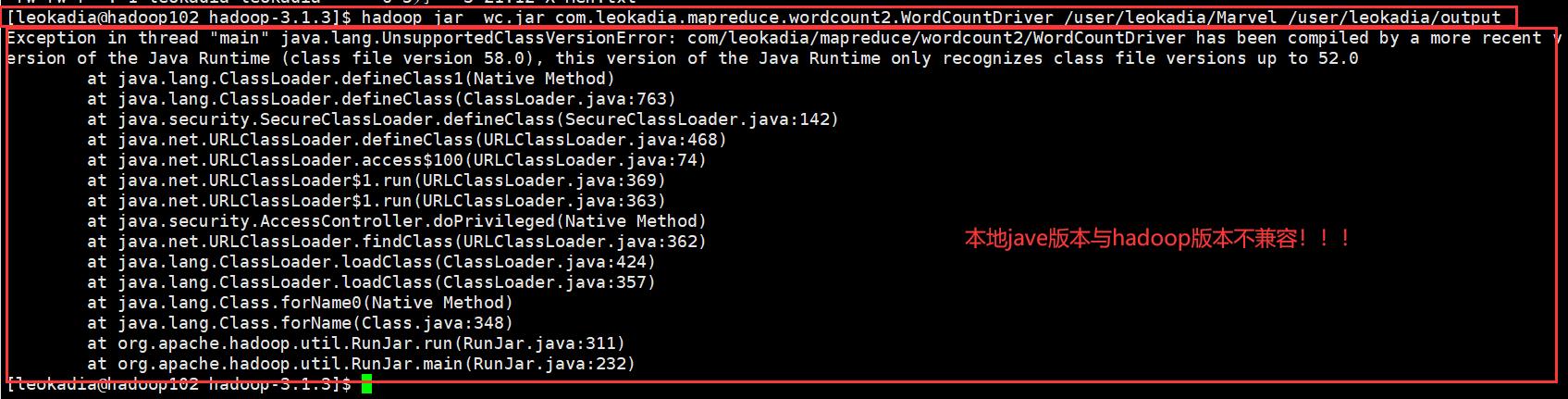
我在本地装的14,当时在hadoop里面配置的8
本地的java版本
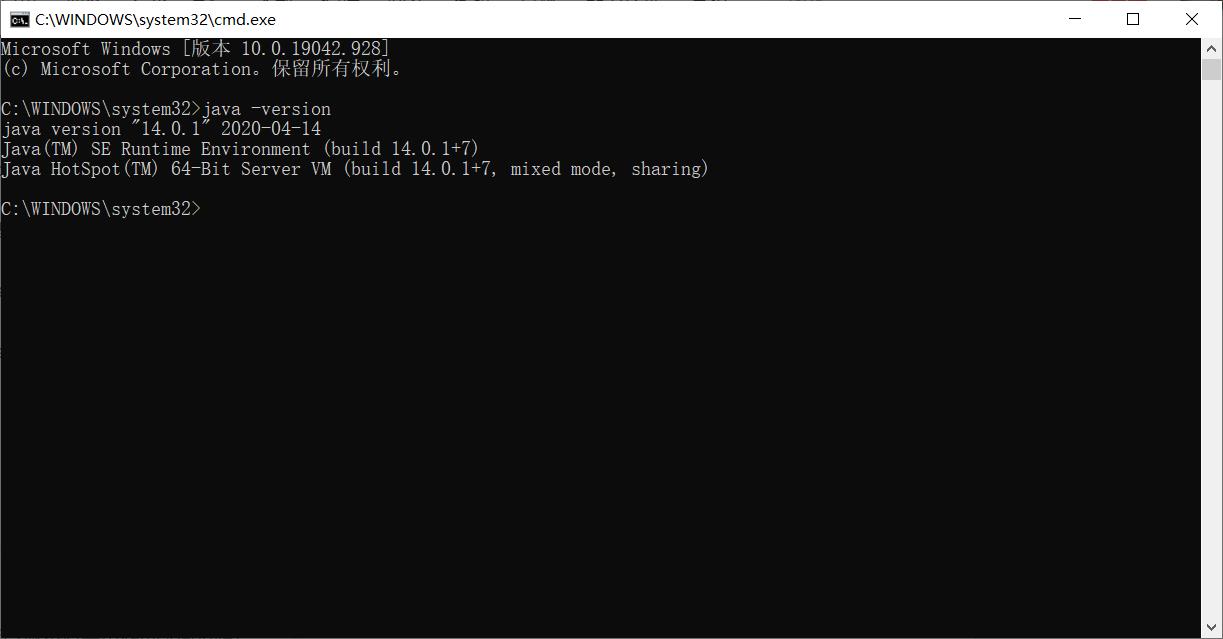
hadoop里面装的java版本

于是,然后经过查证,hadoop3.x目前只支持jdk1.8
只好将本地的jdk版本改成8
因此我专门将我的JDK14卸干净,回去重新下载了一遍JDK8,并重新配置
具体如何卸载和安装我专门又写了篇博客
JDK的卸载与安装(慎重下载高版本JDK!强烈建议要安装就安装JDK8)
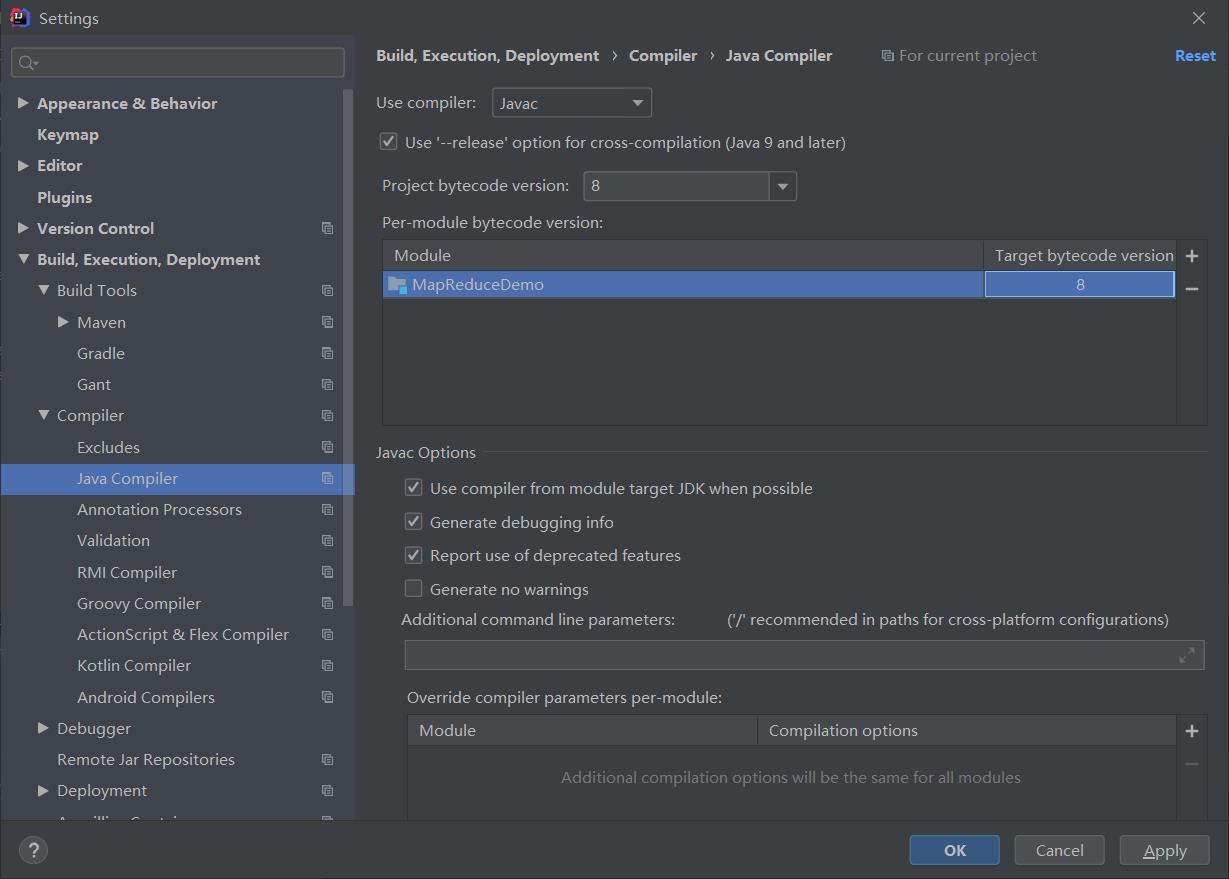
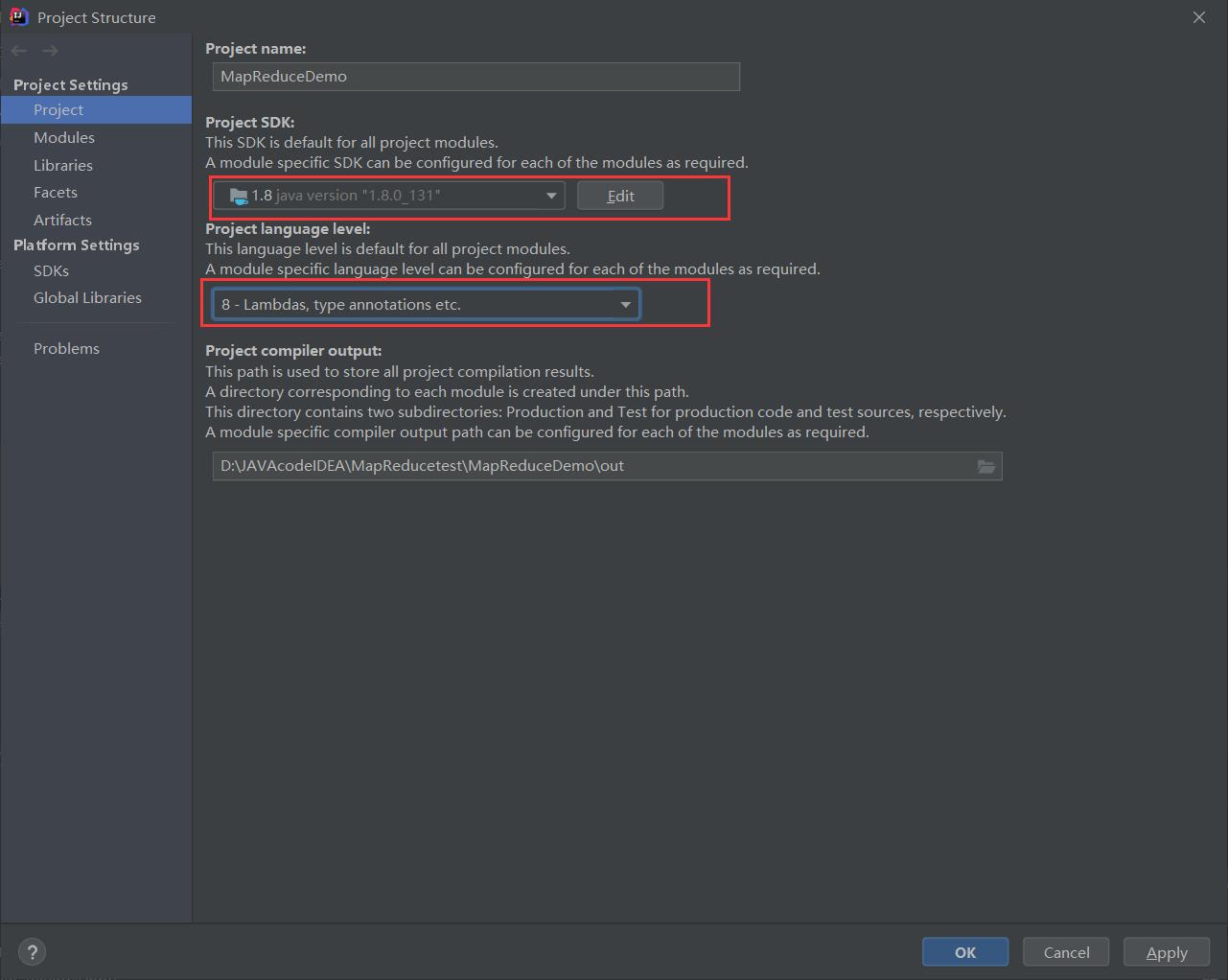
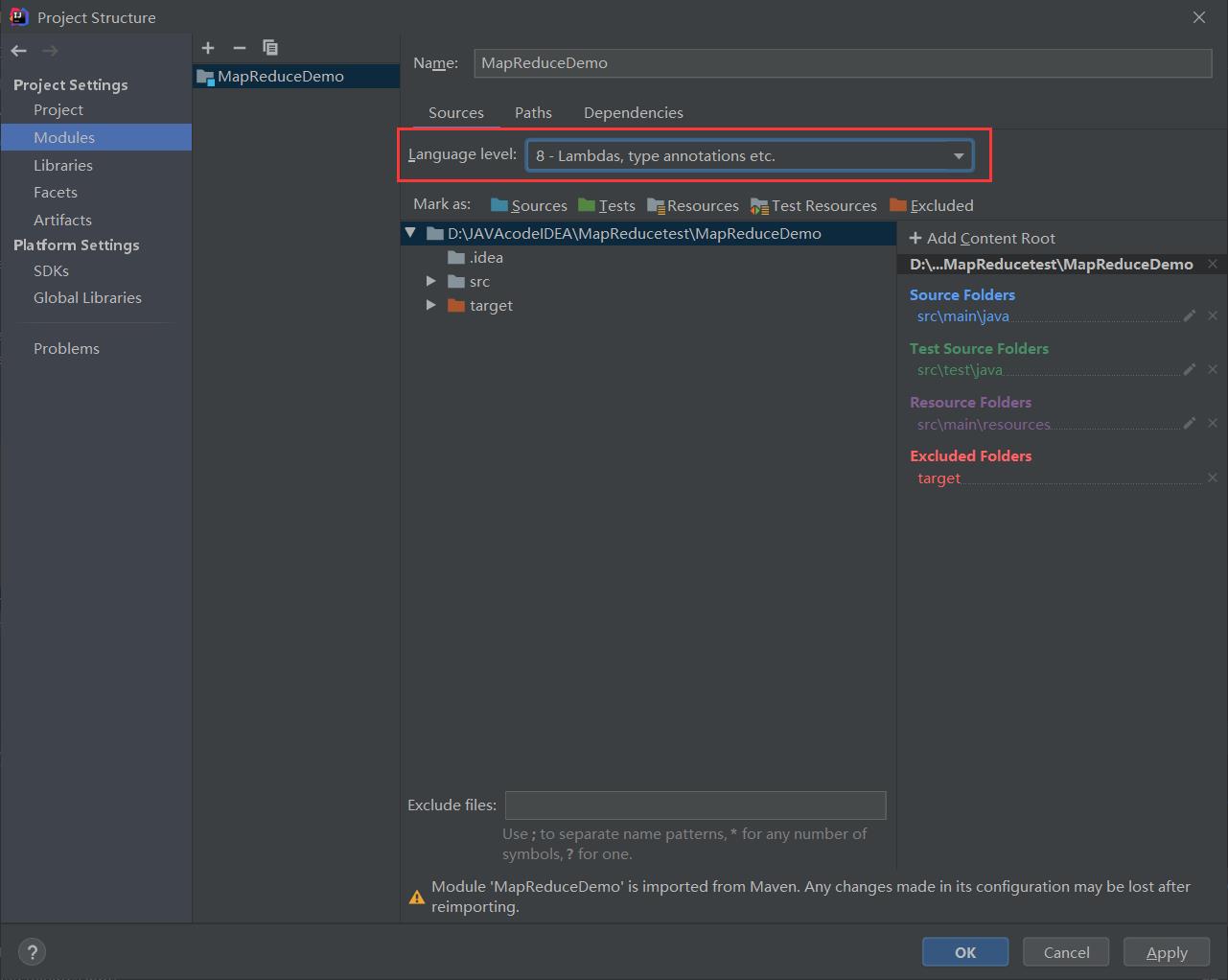
修改配置后,删除原来的jar包,再重新生成即可。
期间还遇到
【Maven报错】Error:java: 不再支持源选项 5。请使用 6 或更高版本。
这个错误,最后尝试了许多方法也成功解决。具体的,我也写了篇博客论述相关解决办法。
在这几个月的大数据学习过程中我写了30篇左右关于大数据的博客,博客浏览量达到近4万,帮助了许多同学以及陌生人,收益匪浅。
以上是关于MapReduce之WordCount实战——统计某电商网站买家收藏商品数量的主要内容,如果未能解决你的问题,请参考以下文章
Hadoop世界中的HelloWorld之WordCount具体分析