Hadoop世界中的HelloWorld之WordCount具体分析
Posted 小小范同学
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hadoop世界中的HelloWorld之WordCount具体分析相关的知识,希望对你有一定的参考价值。
MapReduce 应用举例:单词计数
WorldCount可以说是MapReduce中的helloworld了,下面来看看hadoop中的例子worldcount对其进行的处理过程,也能对mapreduce的执行过程有一个清晰的认识,特别是对于每一个阶段的函数执行所产生的键值对
单词 计数主要完成的功能是:统计一系列文本文件中每个单词出现的次数,如下图所示。下面将 通过分析源代码帮助读者摸清 MapReduce 程序的基本结构。
图 3-1 单词计数
WordCount 详细的执行步骤如下:
(1) 将文件拆分成 splits,由于测试用的文件较小,所以每个文件为一个 split,并将文件按行分割形成<key, value>对,如图 3-2 所示。这一步由 MapReduce 框架自动完成,其中偏 移量(即 key 值)包括了回车所占的字符数(Windows 和 Linux 环境下会不同)。
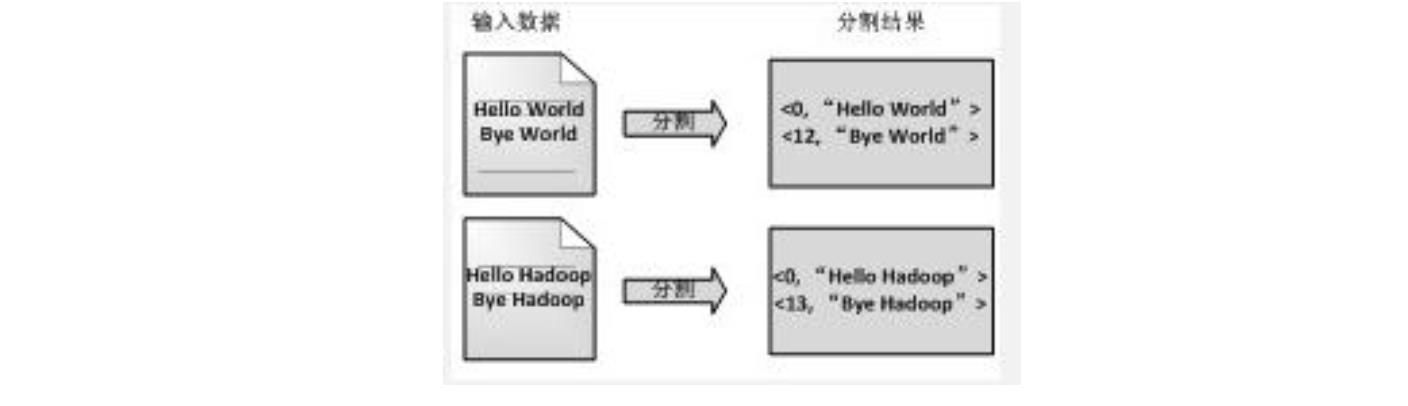
图 3-2 分割过程
(2) 将分割好的<key, value>对交给用户定义的 map 方法进行处理,生成新的<key, value> 对,如图 3-3 所示。

图 3-3 执行 map
(3) 得到 map 方法输出的<key, value>对后,Mapper 会将它们按照 key 值进行排序,并 执行 Combine 过程,将 key 值相同的 value 值累加,得到 Mapper 的最终输出结果。

图 3-4 map 端排序以及 combine 过程
(4) Reducer 先对从 Mapper 接收的数据进行排序,再交由用户自定义的 reduce 方法进行 处理,得到新的<key, value>对,并作为 WordCount 的输出结果,如图 3-5 所示。

图 3-5 reduce 端排序以及输出结果
以上就是wordcount在mapreduce中执行的具体细节,这里面对于中间的键值对产生描述的很详细,这是理解mapreduce很好的资料;
下面来看看hadoop源码中提供的这一源代码:这份代码我的注释很详细,但是运行时需要导入很多包,还要给Eclipse配置hadoop的环境,这里主要是分析worldcount的源码;
19 import java.io.IOException; 20 import java.util.StringTokenizer; 21 22 import org.apache.hadoop.conf.Configuration; 23 24 import org.apache.hadoop.fs.Path; 25 import org.apache.hadoop.io.IntWritable; 26 import org.apache.hadoop.io.Text; 27 import org.apache.hadoop.mapreduce.Job; 28 import org.apache.hadoop.mapreduce.Mapper; 29 import org.apache.hadoop.mapreduce.Reducer; 30 import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; 31 import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; 32 import org.apache.hadoop.util.GenericOptionsParser; 33 34 public class WordCount { 35 36 public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable> { 37 38 private final static IntWritable one = new IntWritable(1);// 初始的单词都是1次,即使重复 39 private Text word = new Text();// word表示单词 40 /* 41 * 重写map方法,读取初试划分的每一个键值对,即行偏移量和一行字符串,key为偏移量,value为该行字符串 42 */ 43 44 public void map(Object key, Text value, Context context) throws IOException, InterruptedException { 45 /* 46 * 因为每一行就是一个spilt,并会为之生成一个mapper,所以我们的参数,key就是偏移量,value就是一行字符串 47 */ 48 StringTokenizer itr = new StringTokenizer(value.toString());// value是一行的字符串,这里将其切割成多个单词 49 while (itr.hasMoreTokens()) {// 多个单词 50 word.set(itr.nextToken());// 每个word 51 context.write(word, one);// one代表1,最开始每个单词都是1次,context直接将<word,1>写到本地磁盘上 52 // write函数直接将两个参数封装成<key,value> 53 } 54 } 55 } 56 57 public static class IntSumReducer extends Reducer<Text, IntWritable, Text, IntWritable> { 58 private IntWritable result = new IntWritable(); 59 60 /* 61 * 重写reduce函数,key为单词,values是reducer从多个mapper中得到数据后进行排序并将相同key组 62 * 合成<key.list<V>>中的list<V>,也就是说明排序这些工作都是mapper和reducer自己去做的, 63 * 我们只需要专注与在map和reduce函数中处理排序处理后的结果 64 */ 65 public void reduce(Text key, Iterable<IntWritable> values, Context context) 66 throws IOException, InterruptedException { 67 /* 68 * 因为在同一个spilt对应的mapper中,会将其进行combine,使得其中单词(key)不重复,然后将这些键值对按照 69 * hash函数分配给对应的reducer,reducer进行排序,和组合成list,然后再调用的用户自定义的这个函数, 70 * 所以有values 71 * 这一Iterable对象,说明,这个reducer排序后有多少个键值对,就会有多少次调用这个算法,每一次都会进行写, 72 * 并且key在整个 并行的多个节点中是唯一的 73 * 74 */ 75 int sum = 0; 76 for (IntWritable val : values) { 77 sum += val.get(); 78 } 79 result.set(sum); 80 context.write(key, result); 81 } 82 } 83 84 public static void main(String[] args) throws Exception { 85 Configuration conf = new Configuration(); 86 String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs(); 87 if (otherArgs.length < 2) { 88 System.err.println("Usage: wordcount <in> [<in>...] <out>"); 89 System.exit(2); 90 } 91 @SuppressWarnings("deprecation") 92 Job job = new Job(conf, "word count"); 93 job.setJarByClass(WordCount.class);// 本次作业的job 94 job.setMapperClass(TokenizerMapper.class);// map函数 95 job.setCombinerClass(IntSumReducer.class);// combine的实现个reduce函数一样,都是将相同的单词组合成一个键值对 96 job.setReducerClass(IntSumReducer.class);// reduce函数 97 job.setOutputKeyClass(Text.class);// 键key的类型, 98 job.setOutputValueClass(IntWritable.class);// value的类型 99 for (int i = 0; i < otherArgs.length - 1; ++i) { 100 FileInputFormat.addInputPath(job, new Path(otherArgs[i]));//输入输出参数的获取,说明可以是多个输入文件 101 } 102 FileOutputFormat.setOutputPath(job, new Path(otherArgs[otherArgs.length - 1]));//参数的最后一个是输出文件 103 System.exit(job.waitForCompletion(true) ? 0 : 1); 104 } 105 }
以上是关于Hadoop世界中的HelloWorld之WordCount具体分析的主要内容,如果未能解决你的问题,请参考以下文章