大牛讲堂 | 番外篇——Caffe作者贾扬清教你怎样打造更加优秀的深度学习架构
Posted HorizonRobotics
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大牛讲堂 | 番外篇——Caffe作者贾扬清教你怎样打造更加优秀的深度学习架构相关的知识,希望对你有一定的参考价值。
在深度学习领域,Caffe框架是人们无法绕过的一座山。这不仅是因为它无论在结构、性能上,还是在代码质量上,都称得上一款十分出色的开源框架。更重要的是,它将深度学习的每一个细节都原原本本地展现出来,大大降低了人们学习研究和开发的难度。
这一次,大牛讲堂将Caffe框架的作者贾扬清请到了地平线,他将结合自己在Google、Facebook的工作经历以及Caffe等学习架构的开发经验,为大家分享「怎样打造更加优秀的深度学习架构」。
小编就不耽误时间了
满满干货,双手奉上╮(^-^)╭
深度学习的框架总会不断改变,Caffe也会有被新框架代替的一天。但是在开发Caffe的过程中,贾扬清发现大家喜欢的框架其实有着很多相似的地方,这些闪光点拥有很长的生命周期,发现并掌握人们这些共同偏好将为以后开发新的框架积累经验。他在反复总结之后,认为Caffe之所以广受欢迎可能是因为有以下的四个特点:
1、 稳定的模型架构
Caffe通过Protobuf来定义一个网络的结构,而这个由Google开源的库具有优秀的版本兼容性。随着Caffe的框架源码的不断更新迭代,之前定义的网络结构依然能兼容解析,模型仍然能正确加载运行。
2、较好的设备抽象
合理的设备抽象能够精简代码,提高框架适用性。在这方面Caffe做了比较好的尝试,模型的训练和使用与不同的平台耦合比较低,只要平台能解析网络结构并读取二进制的模型参数,就能运行该模型。这样大大拓展了框架的应用范围,自然更加符合用户的使用需求。
3、清晰的说明教程
如何让首次接触到框架的人通过说明教程就能最快地熟悉运用,这对于一个新面世的框架来说尤为重要。以Caffe为例,用户只需要将官方文档的例子跑一遍,基本就能清楚Caffe的操作过程和细节,这给它的广泛传播提供了最坚实的基础。
4、开放的模型仓库
目前Caffe还维护了一个Model Zoo, 许多论文的作者会将模型发布到这里,其它用户可以利用这些材料轻松地将模型复现,还可以在github上参与开发讨论,从而更深入地学习实践。
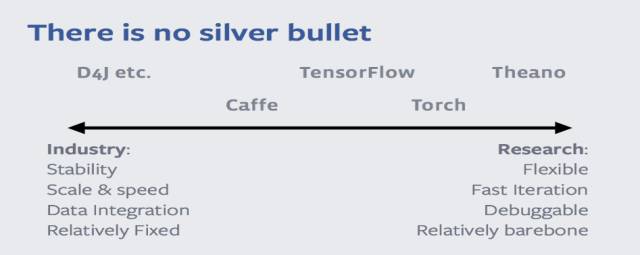
人们的需求多种多样,目前,还没有任何一种深度学习的框架能够满足人们所有的需求。对于工业界而言,从业者看重的是框架的稳定性强、数据量大、速度快、容易进行数据整合等。而对于学术界来说,学者们更希望框架容易调试、灵活性要强、迭代要快。因此,比照现有深度学习框架的特点,Theano、Torch可能会更加适合学术界,而D4J等可能就要更适合工业界一些,至于Caffe、Tensor flow等为代表的框架则是介于二者之间。
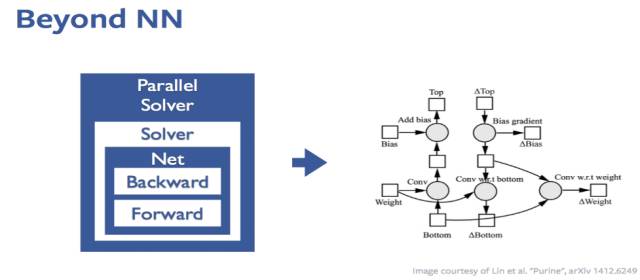
1、使用计算图 (computation graph)
Caffe框架在实现网络的forward, backward, update时,是通过Solver, Net, Layer之间递进地逐步回调对应的forward, backward, update来实现的,在加入并行化之后,为了用计算来覆盖数据传输的时间,这些回调的运用会变得相对复杂。
因此,目前许多框架都在往computation graph的风格上偏移。这种基于computation graph的深度学习框架不仅在网络的更新方面更加直接,而且在并行方面,无论是数据并行方式还是模型并行方式,都能做到接近线性的提速。大家未来也可以在这个方向做些尝试。
2、高效方便地输入数据
对于Caffe用户而言,首要问题便是如何导入数据。尤其是在算法比较简单时,保证数据输入的高效性将成为制约模型的首要因素。之前进行的某个项目里,在8个GPU(Titan X)上训练AlexNet,需要达到每秒钟处理1600张图片(3.14GB/s)的要求。甚至对于另外一些模型而言,还需要更多的吞吐量。如果数据接口没有做好,是绝对无法达到这样的要求的。
3、更快的速度
网络结构实现需要在灵活性和速度上进行权衡,这种权衡可以体现在框架设计的粗细粒度上。例如一个Inception的结构,是做成像Caffe这样通过各个层的累积来形成,还是直接由Conv2D, BiasAdd, Relu这样的基本计算来直接构造一个Inception结构。这样不同粗细粒度的构建方法体现了整个框架对速度或是灵活性的权衡。
另外,对于底层的实现,最好用硬件供应商提供的数值计算库,比如CuDNN, MKL-DNN,Accelerate,Eigen,NNPack等。
4、 可移植性
要提升框架的实用价值,就必须提升其训练出的模型的可移植性。换句话说,也就是要让框架训练出的模型具有平台无关性,包括了系统层面(windows、linux、android、ios、OS X等)及硬件层面(CPU、GPU、FPGA、ARM等)。这就必须使得设计出的模型更加轻量。
以上是关于大牛讲堂 | 番外篇——Caffe作者贾扬清教你怎样打造更加优秀的深度学习架构的主要内容,如果未能解决你的问题,请参考以下文章
有奖提问向贾扬清(阿里巴巴副总裁Caffe作者TensorFlow作者之一ONNX创始人)提问啦