Python实战爬取豆瓣排行榜电影数据(含GUI界面版)
Posted 日常分享Python
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python实战爬取豆瓣排行榜电影数据(含GUI界面版)相关的知识,希望对你有一定的参考价值。
项目简介
这个项目源于大三某课程设计。平常经常需要搜索一些电影,但是不知道哪些评分高且评价人数多的电影。为了方便使用,就将原来的项目重新改写了。当做是对爬虫技术、可视化技术的实践了。主要是通过从排行榜和从影片关键词两种方式爬取电影数据。
配置说明
-
打开http://chromedriver.storage.googleapis.com/index.html,根据自己的操作系统下载对应的chromedriver
-
打开当前面目录下的getMovieInRankingList.py,定位到第59行,将
executable_path=/Users/bird/Desktop/chromedriver.exe修改成你自己的chromedriver路径 -
打开pycharm,依次安装以下包
-
pip install Pillow
-
pip install selenium
功能截图
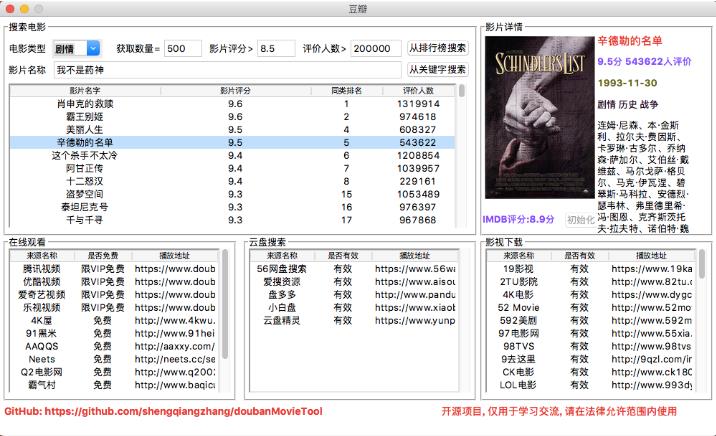
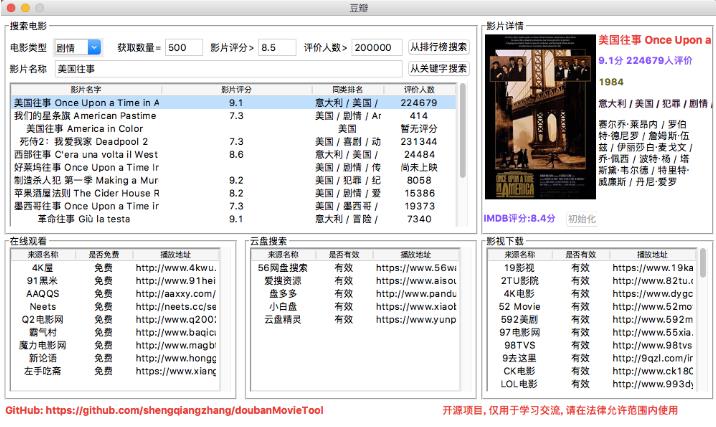
包含功能
- 根据关键字搜索电影
- 根据排行榜(TOP250)搜索电影
- 显示IMDB评分及其他基本信息
- 提供多个在线视频站点,无需vip
- 提供多个云盘站点搜索该视频,以便保存到云盘
- 提供多个站点下载该视频
- 等待更新
存在问题
目前没有加入反爬虫策略,如果运行出现403 forbidden提示,则说明暂时被禁止,解决方式如下:
-
加入cookies
-
采用随机延时方式
-
采用IP代理池方式(较不稳定)


代码:
# -*- coding:utf-8 -*-
from uiObject import uiObject
# main入口
if __name__ == '__main__':
ui = uiObject()
ui.ui_process()
# -*- coding:utf-8 -*-
from ssl import _create_unverified_context
from json import loads
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import tkinter.messagebox
import urllib.request
import urllib.parse
movieData = ' [' \\
'{"title":"纪录片", "type":"1", "interval_id":"100:90"}, ' \\
' {"title":"传记", "type":"2", "interval_id":"100:90"}, ' \\
' {"title":"犯罪", "type":"3", "interval_id":"100:90"}, ' \\
' {"title":"历史", "type":"4", "interval_id":"100:90"}, ' \\
' {"title":"动作", "type":"5", "interval_id":"100:90"}, ' \\
' {"title":"情色", "type":"6", "interval_id":"100:90"}, ' \\
' {"title":"歌舞", "type":"7", "interval_id":"100:90"}, ' \\
' {"title":"儿童", "type":"8", "interval_id":"100:90"}, ' \\
' {"title":"悬疑", "type":"10", "interval_id":"100:90"}, ' \\
' {"title":"剧情", "type":"11", "interval_id":"100:90"}, ' \\
' {"title":"灾难", "type":"12", "interval_id":"100:90"}, ' \\
' {"title":"爱情", "type":"13", "interval_id":"100:90"}, ' \\
' {"title":"音乐", "type":"14", "interval_id":"100:90"}, ' \\
' {"title":"冒险", "type":"15", "interval_id":"100:90"}, ' \\
' {"title":"奇幻", "type":"16", "interval_id":"100:90"}, ' \\
' {"title":"科幻", "type":"17", "interval_id":"100:90"}, ' \\
' {"title":"运动", "type":"18", "interval_id":"100:90"}, ' \\
' {"title":"惊悚", "type":"19", "interval_id":"100:90"}, ' \\
' {"title":"恐怖", "type":"20", "interval_id":"100:90"}, ' \\
' {"title":"战争", "type":"22", "interval_id":"100:90"}, ' \\
' {"title":"短片", "type":"23", "interval_id":"100:90"}, ' \\
' {"title":"喜剧", "type":"24", "interval_id":"100:90"}, ' \\
' {"title":"动画", "type":"25", "interval_id":"100:90"}, ' \\
' {"title":"同性", "type":"26", "interval_id":"100:90"}, ' \\
' {"title":"西部", "type":"27", "interval_id":"100:90"}, ' \\
' {"title":"家庭", "type":"28", "interval_id":"100:90"}, ' \\
' {"title":"武侠", "type":"29", "interval_id":"100:90"}, ' \\
' {"title":"古装", "type":"30", "interval_id":"100:90"}, ' \\
' {"title":"黑色电影", "type":"31", "interval_id":"100:90"}' \\
']'
class getMovieInRankingList:
# typeId 电影类型, movie_count 欲获取的该电影类型的数量, rating 电影的评分, vote_count 电影的评价人数
def __init__(self):
chrome_options = Options()
chrome_options.add_argument('--headless') # 设置为无头模式,即不显示浏览器
chrome_options.add_argument(
'user-agent="Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (Khtml, like Gecko) Chrome/72.0.3626.121 Safari/537.36"') # 设置user=agent
chrome_options.add_experimental_option('excludeSwitches',['enable-automation']) # 此步骤很重要,设置为开发者模式,防止被各大网站识别出来使用了Selenium
chrome_options.add_experimental_option("prefs",{"profile.managed_default_content_settings.images": 2}) # 不加载图片,加快访问速度
try:
self.browser = webdriver.Chrome(executable_path='/Users/bird/Desktop/chromedriver.exe',chrome_options=chrome_options) # 设置chromedriver路径
self.wait = WebDriverWait(self.browser, 10) # 超时时长为10s
except:
print("chromedriver.exe出错,请检查是否与你的chrome浏览器版本相匹配\\n缺失chromedriver.exe不会导致从排行榜搜索功能失效,但会导致从关键字搜索功能失效")
# 从排行榜中获取电影数据
def get_url_data_in_ranking_list(self, typeId, movie_count, rating, vote_count):
context = _create_unverified_context() # 屏蔽ssl证书
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36', }
url = 'https://movie.douban.com/j/chart/top_list?type=' + str(
typeId) + '&interval_id=100:90&action=unwatched&start=0&limit=' + str(movie_count)
req = urllib.request.Request(url=url, headers=headers)
f = urllib.request.urlopen(req, context=context)
response = f.read()
jsonData = loads(response) # 将json转为python对象
list = []
for subData in jsonData: # 依次对每部电影进行操作
if ((float(subData['rating'][0]) >= float(rating)) and (float(subData['vote_count']) >= float(vote_count))):
subList = []
subList.append(subData['title'])
subList.append(subData['rating'][0])
subList.append(subData['rank'])
subList.append(subData['vote_count'])
list.append(subList)
for data in list:
print(data)
return list, jsonData
# 从关键字获取电影数据
def get_url_data_in_keyWord(self, key_word):
# 浏览网页
self.browser.get('https://movie.douban.com/subject_search?search_text=' + urllib.parse.quote(
key_word) + '&cat=1002') # get方式获取返回数据
# js动态渲染的网页,必须等到搜索结果元素(DIV中class=root)出来后,才可以停止加载网页
# 等待DIV中class=root的元素出现
self.wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, '.root')))
dr = self.browser.find_elements_by_xpath("//div[@class='item-root']") # 获取class为item-root的DIV(因为有多个结果)
jsonData = []
list = []
for son in dr:
movieData = {'rating': ['', 'null'], 'cover_url': '', 'types': '', 'title': '', 'url': '',
'release_date': '', 'vote_count': '', 'actors': ''}
subList = ['', '', '', '']
url_element = son.find_elements_by_xpath(".//a") # 获取第一个a标签的url(因为有多个结果)
if (url_element):
movieData['url'] = (url_element[0].get_attribute("href"))
img_url_element = url_element[0].find_elements_by_xpath(".//img") # 获取影片海报图片地址
if (img_url_element):
movieData['cover_url'] = (img_url_element[0].get_attribute("src"))
title_element = son.find_elements_by_xpath(".//div[@class='title']") # 获取标题
if (title_element):
temp_title = (title_element[0].text)
movieData['title'] = (temp_title.split('('))[0]
movieData['release_date'] = temp_title[temp_title.find('(') + 1:temp_title.find(')')]
subList[0] = movieData['title']
rating_element = son.find_elements_by_xpath(".//span[@class='rating_nums']") # 获取评分
if (rating_element):
movieData['rating'][0] = (rating_element[0].text)
subList[1] = movieData['rating'][0]
vote_element = son.find_elements_by_xpath(".//span[@class='pl']") # 获取数量
if (vote_element):
movieData['vote_count'] = (vote_element[0].text).replace('(', '').replace(')', '').replace('人评价', '')
subList[3] = movieData['vote_count']
type_element = son.find_elements_by_xpath(".//div[@class='meta abstract']") # 获取类型
if (type_element):
movieData['types'] = (type_element[0].text)
subList[2] = movieData['types']
actors_element = son.find_elements_by_xpath(".//div[@class='meta abstract_2']") # 获取演员
if (actors_element):
movieData['actors'] = (actors_element[0].text)
jsonData.append(movieData)
list.append(subList)
# 关闭浏览器
self.browser.quit()
for data in list:
print(data)
return list, jsonData
全部源码:
# -*- coding:utf-8 -*-
from PIL import Image, ImageTk
from getMovieInRankingList import *
from tkinter import Tk
from tkinter import ttk
from tkinter import font
from tkinter import LabelFrame
from tkinter import Label
from tkinter import StringVar
from tkinter import Entry
from tkinter import END
from tkinter import Button
from tkinter import Frame
from tkinter import RIGHT
from tkinter import NSEW
from tkinter import NS
from tkinter import NW
from tkinter import N
from tkinter import Y
from tkinter import DISABLED
from tkinter import NORMAL
from re import findall
from json import loads
from threading import Thread
from urllib.parse import quote
from webbrowser import open
import os
import ssl
ssl._create_default_https_context = ssl._create_unverified_context #关闭SSL证书验证
def thread_it(func, *args):
'''
将函数打包进线程
'''
# 创建
t = Thread(target=func, args=args)
# 守护
t.setDaemon(True)
# 启动
t.start()
def handlerAdaptor(fun, **kwds):
'''事件处理函数的适配器,相当于中介,那个event是从那里来的呢,我也纳闷,这也许就是python的伟大之处吧'''
return lambda event, fun=fun, kwds=kwds: fun(event, **kwds)
def save_img(img_url, file_name, file_path):
"""
下载指定url的图片,并保存运行目录下的img文件夹
:param img_url: 图片地址
:param file_name: 图片名字
:param file_path: 存储目录
:return:
"""
#保存图片到磁盘文件夹 file_path中,默认为当前脚本运行目录下的img文件夹
try:
#判断文件夹是否已经存在
if not os.path.exists(file_path):
print('文件夹',file_path,'不存在,重新建立')
os.makedirs(file_path)
#获得图片后缀
file_suffix = os.path.splitext(img_url)[1]
#拼接图片名(包含路径)
filename = '{}{}{}{}'.format(file_path,os.sep,file_name,file_suffix)
#判断文件是否已经存在
if not os.path.exists(filename):
print('文件', filename, '不存在,重新建立')
# 下载图片,并保存到文件夹中
urllib.request.urlretrieve(img_url, filename=filename)
return filename
except IOError as e:
print('下载图片操作失败',e)
except Exception as e:
print('错误:',e)
def resize(w_box, h_box, pil_image):
"""
等比例缩放图片,并且限制在指定方框内
:param w_box,h_box: 指定方框的宽度和高度
:param pil_image: 原始图片
:return:
"""
f1 = 1.0 * w_box / pil_image.size[0] # 1.0 forces float division in Python2
f2 = 1.0 * h_box / pil_image.size[1]
factor = min([f1, f2])
# print(f1, f2, factor) # test
# use best down-sizing filter
width = int(pil_image.size[0] * factor)
height = int(pil_image.size[1] * factor)
return pil_image.resize((width, height), Image.ANTIALIAS)
def get_mid_str(content,startStr,endStr):
startIndex = content.index(startStr)
if startIndex>=0:
startIndex += len(startStr)
endIndex = content.index(endStr)
return content[startIndex:endIndex]
class uiObject:
def __init__(self):
self.jsonData = ""
self.jsonData_keyword = ""
def show_GUI_movie_detail(self):
'''
显示 影片详情 界面GUI
'''
self.label_img['state'] = NORMAL
self.label_movie_name['state'] = NORMAL
self.label_movie_rating['state'] = NORMAL
self.label_movie_time['state'] = NORMAL
self.label_movie_type['state'] = NORMAL
self.label_movie_actor['state'] = NORMAL
def hidden_GUI_movie_detail(self):
'''
显示 影片详情 界面GUI
'''
self.label_img['state'] = DISABLED
self.label_movie_name['state'] = DISABLED
self.label_movie_rating['state'] = DISABLED
self.label_movie_time['state'] = DISABLED
self.label_movie_type['state'] = DISABLED
self.label_movie_actor['state'] = DISABLED
def show_IDMB_rating(self):
'''
显示IDM评分
'''
self.label_movie_rating_imdb.config(text='正在加载IMDB评分')
self.B_0_imdb['state'] = DISABLED
rating_imdb = '未知'
item = self.treeview.selection()
if(item):
item_text = self.treeview.item(item, "values")
movieName = item_text[0] # 输出电影名
for movie in self.jsonData:
if(movie['title'] == movieName):
f = urllib.request.urlopen(movie['url'])
response = (f.read()).decode()
url_imdb = get_mid_str(response, 'IMDb链接:</span> <a href=\\"', '\\" target=\\"_blank\\" rel=\\"nofollow\\">')
f = urllib.request.urlopen(url_imdb)
data_imdb = (f.read()).decode()
rating_imdb = get_mid_str(data_imdb, '<span class=\\"rating">', '<span class=\\"ofTen\\">')
self.clear_tree(self.treeview_play_online)
s = response
name = findall(r"<a class=\\"playBtn\\" data-cn=\\"(.*?)\\" href=\\"", s)
down_url = findall(r"data-cn=\\".*?\\" href=\\"(.*?)\\" target=", s)
real_movie_name = get_mid_str(s, "<title>", "</title>").replace(" ","").replace("\\n","").replace("(豆瓣)","")
print(real_movie_name)
list = []
for i in range(len(name)):
list.append([name[i], "限VIP免费", down_url[i]])
list.append(["4K屋", "免费", "http://www.4kwu.cc/?m=vod-search&wd=" + quote(real_movie_name)])
list.append(["91黑米", "免费", "http://www.91heimi.com/index.php/vod/search.html?wd=" + quote(real_movie_name)])
list.append(["AAQQS", "免费", "http://aaxxy.com/vod-search-pg-1-wd-" + quote(real_movie_name) + ".html"])
list.append(["Neets", "免费", "http://neets.cc/search?key=" + quote(real_movie_name)])
list.append(["Q2电影网", "免费", "http://www.q2002.com/search?wd=" + quote(real_movie_name)])
list.append(["霸气村", "免费", "http://www.baqicun.co/search.php?searchword=" + quote(real_movie_name)])
list.append(["魔力电影网", "免费", "http://www.magbt.net/search.php?searchword=" + quote(real_movie_name)])
list.append(["新论语", "免费", "http://www.honggujiu.net/index.php?m=vod-search&wd=" + quote(real_movie_name)])
list.append(["左手吃斋", "免费", "https://www.xiangkanju.com/index.php?m=vod-search&wd=" + quote(real_movie_name)])
self.add_tree(list, self.treeview_play_online)
self.clear_tree(self.treeview_save_cloud_disk)
list = []
list.append(["56网盘搜索", "有效", "https://www.56wangpan.com/search/o2kw" + quote(real_movie_name)])
list.append(["爱搜资源", "有效", "https://www.aisouziyuan.com/?name=" + quote(real_movie_name) + "&page=1"])
list.append(["盘多多", "有效", "http://www.panduoduo.net/s/comb/n-" + quote(real_movie_name) + "&f-f4"])
list.append(["小白盘", "有效", "https://www.xiaobaipan.com/list-" + quote(real_movie_name) + "-1.html" ])
list.append(["云盘精灵", "有效", "https://www.yunpanjingling.com/search/" + quote(real_movie_name) + "?sort=size.desc"])
self.add_tree(list, self.treeview_save_cloud_disk)
self.clear_tree(self.treeview_bt_download)
list = []
list.append( ['19影视', '有效', 'https://www.19kan.com/vodsearch.html?wd=' + quote(real_movie_name) ])
list.append( ['2TU影院', '有效', 'http://www.82tu.cc/search.php?submit=%E6%90%9C+%E7%B4%A2&searchword=' + quote(real_movie_name) ])
list.append( ['4K电影', '有效', 'https://www.dygc.org/?s=' + quote(real_movie_name) ])
list.append( ['52 Movie', '有效', 'http://www.52movieba.com/search.htm?keyword=' + quote(real_movie_name) ])
list.append( ['592美剧', '有效', 'http://www.592meiju.com/search/?wd=' + quote(real_movie_name) ])
list.append( ['97电影网', '有效', 'http://www.55xia.com/search?q=' + quote(real_movie_name) ])
list.append( ['98TVS', '有效', 'http://www.98tvs.com/?s=' + quote(real_movie_name) ])
list.append( ['9去这里', '有效', 'http://9qzl.com/index.php?s=/video/search/wd/' + quote(real_movie_name) ])
list.append( ['CK电影', '有效', 'http://www.ck180.net/search.html?q=' + quote(real_movie_name) ])
list.append( ['LOL电影', '有效', 'http://www.993dy.com/index.php?m=vod-search&wd=' + quote(real_movie_name) ])
list.append( ['MP4Vv', '有效', 'http://www.mp4pa.com/search.php?searchword=' + quote(real_movie_name) ])
list.append( ['MP4电影', '有效', 'http://www.domp4.com/search/' + quote(real_movie_name) + '-1.html'])
list.append( ['TL95', '有效', 'http://www.tl95.com/?s=' + quote(real_movie_name) ])
list.append( ['比特大雄', '有效', 'https://www.btdx8.com/?s=' + quote(real_movie_name) ])
list.append( ['比特影视', '有效', 'https://www.bteye.com/search/' + quote(real_movie_name) ])
list.append( ['春晓影视', '有效', 'http://search.chunxiao.tv/?keyword=' + quote(real_movie_name) ])
list.append( ['第一电影网', '有效', 'https://www.001d.com/?s=' + quote(real_movie_name) ])
list.append( ['电影日志', '有效', 'http://www.dyrizhi.com/search?s=' + quote(real_movie_name) ])
list.append( ['高清888', '有效', 'https://www.gaoqing888.com/search?kw=' + quote(real_movie_name) ])
list.append( ['高清MP4', '有效', 'http://www.mp4ba.com/index.php?m=vod-search&wd=' + quote(real_movie_name) ])
list.append( ['高清电台', '有效', 'https://gaoqing.fm/s.php?q=' + quote(real_movie_name) ])
list.append( ['高清控', '有效', 'http://www.gaoqingkong.com/?s=' + quote(real_movie_name) ])
list.append( ['界绍部', '有效', 'http://www.jsb456.com/?s=' + quote(real_movie_name) ])
list.append( ['看美剧', '有效', 'http://www.kanmeiju.net/index.php?s=/video/search/wd/' + quote(real_movie_name) ])
list.append( ['蓝光网', '有效', 'http://www.languang.co/?s=' + quote(real_movie_name) ])
list.append( ['老司机电影', '有效', 'http://www.lsjdyw.net/search/?s=' + quote(real_movie_name) ])
list.append( ["乐赏电影", '有效', 'http://www.gscq.me/search.htm?keyword=' + quote(real_movie_name) ])
list.append( ["美剧汇", '有效', 'http://www.meijuhui.net/search.php?q=' + quote(real_movie_name) ])
list.append( ['美剧鸟', '有效', 'http://www.meijuniao.com/index.php?s=vod-search-wd-' + quote(real_movie_name) ])
list.append( ['迷你MP4', '有效', 'http://www.minimp4.com/search?q=' + quote(real_movie_name) ])
list.append( ['泡饭影视', '有效', 'http://www.chapaofan.com/search/' + quote(real_movie_name) ])
list.append( ['片吧', '有效', 'http://so.pianbar.com/search.aspx?q=' + quote(real_movie_name) ])
list.append( ['片源网', '有效', 'http://pianyuan.net/search?q=' + quote(real_movie_name) ])
list.append( ['飘花资源网', '有效', 'https://www.piaohua.com/plus/search.php?kwtype=0&keyword=' + quote(real_movie_name) ])
list.append( ['趣味源', '有效', 'http://quweiyuan.cc/?s=' + quote(real_movie_name) ])
list.append( ['人生05', '有效', 'http://www.rs05.com/search.php?s=' + quote(real_movie_name) ])
list.append( ['贪玩影视', '有效', 'http://www.tanwanyingshi.com/movie/search?keyword=' + quote(real_movie_name) ])
list.append( ['新片网', '有效', 'http://www.91xinpian.com/index.php?m=vod-search&wd=' + quote(real_movie_name) ])
list.append( ['迅雷影天堂', '有效', 'https://www.xl720.com/?s=' + quote(real_movie_name) ])
list.append( ['迅影网', '有效', 'http://www.xunyingwang.com/search?q=' + quote(real_movie_name) ])
list.append( ['一只大榴莲', '有效', 'http://www.llduang.com/?s=' + quote(real_movie_name) ])
list.append( ['音范丝', '有效', 'http://www.yinfans.com/?s=' + quote(real_movie_name) ])
list.append( ['影海', '有效', 'http://www.yinghub.com/search/list.html?keyword=' + quote(real_movie_name) ])
list.append( ['影视看看', '有效', 'http://www.yskk.tv/index.php?m=vod-search&wd=' + quote(real_movie_name) ])
list.append( ['云播网', '有效', 'http://www.yunbowang.cn/index.php?m=vod-search&wd=' + quote(real_movie_name) ])
list.append( ['中国高清网', '有效', 'http://gaoqing.la/?s=' + quote(real_movie_name) ])
list.append( ['最新影视站', '有效', 'http://www.zxysz.com/?s=' + quote(real_movie_name) ])
self.add_tree(list, self.treeview_bt_download)
break;
self.label_movie_rating_imdb.config(text='IMDB评分:' + rating_imdb + '分')
def project_statement_show(self, event):
open("https://github.com/shengqiangzhang/examples-of-web-crawlers")
def project_statement_get_focus(self, event):
self.project_statement.config(fg="blue", cursor="hand1")
def project_statement_lose_focus(self, event):
self.project_statement.config(fg="#FF0000")
def show_movie_data(self, event):
'''
显示某个被选择的电影的详情信息
'''
# self.hidden_GUI_movie_detail()
self.B_0_imdb['state'] = NORMAL
self.label_movie_rating_imdb.config(text = 'IMDB评分')
self.clear_tree(self.treeview_play_online)
self.clear_tree(self.treeview_save_cloud_disk)
self.clear_tree(self.treeview_bt_download)
item = self.treeview.selection()
if(item):
item_text = self.treeview.item(item, "values")
movieName = item_text[0] # 输出电影名
for movie in self.jsonData:
if(movie['title'] == movieName):
img_url = movie['cover_url']
movie_name = movie['title']
file_name = save_img(img_url, movie_name, 'img') #下载网络图片
self.show_movie_img(file_name)
self.label_movie_name.config(text=movie['title'])
if(isinstance(movie['actors'],list)):
string_actors = "、".join(movie['actors'])
else:
string_actors = movie['actors']
self.label_movie_actor.config(text=string_actors)
self.label_movie_rating.config(text=str(movie['rating'][0]) + '分 ' + str(movie['vote_count']) + '人评价')
self.label_movie_time.config(text=movie['release_date'])
self.label_movie_type.config(text=movie['types'])
break
# self.show_GUI_movie_detail()
def show_movie_img(self, file_name):
'''
更新图片GUI
:param file_name: 图片路径
:return:
'''
img_open = Image.open(file_name) #读取本地图片
pil_image_resized = resize(160, 230, img_open) #等比例缩放本地图片
img = ImageTk.PhotoImage(pil_image_resized) #读入图片
self.label_img.config(image=img, width = pil_image_resized.size[0], height = pil_image_resized.size[1])
self.label_img.image = img
def center_window(self, root, w, h):
"""
窗口居于屏幕中央
:param root: root
:param w: 窗口宽度
:param h: 窗口高度
:return:
"""
# 获取屏幕 宽、高
ws = root.winfo_screenwidth()
hs = root.winfo_screenheight()
# 计算 x, y 位置
x = (ws/2) - (w/2)
y = (hs/2) - (h/2)
root.geometry('%dx%d+%d+%d' % (w, h, x, y))
def clear_tree(self, tree):
'''
清空表格
'''
x = tree.get_children()
for item in x:
tree.delete(item)
def add_tree(self,list, tree):
'''
新增数据到表格
'''
i = 0
for subList in list:
tree.insert('', 'end', values=subList)
i = i + 1
tree.grid()
def searh_movie_in_rating(self):
"""
从排行榜中搜索符合条件的影片信息
"""
# 按钮设置为灰色状态
self.clear_tree(self.treeview) # 清空表格
self.B_0['state'] = DISABLED
self.C_type['state'] = DISABLED
self.T_count['state'] = DISABLED
self.T_rating['state'] = DISABLED
self.T_vote['state'] = DISABLED
self.B_0_keyword['state'] = DISABLED
self.T_vote_keyword['state'] = DISABLED
self.B_0['text'] = '正在努力搜索'
self.jsonData = ""
jsonMovieData = loads(movieData)
for subMovieData in jsonMovieData:
if(subMovieData['title'] == self.C_type.get()):
movieObject = getMovieInRankingList() #创建对象
list,jsonData = movieObject.get_url_data_in_ranking_list(subMovieData['type'], self.T_count.get(), self.T_rating.get(), self.T_vote.get()) # 返回符合条件的电影信息
self.jsonData = jsonData
self.add_tree(list, self.treeview) # 将数据添加到tree中
break
# 按钮设置为正常状态
self.B_0['state'] = NORMAL
self.C_type['state'] = 'readonly'
self.T_count['state'] = NORMAL
self.T_rating['state'] = NORMAL
self.T_vote['state'] = NORMAL
self.B_0_keyword['state'] = NORMAL
self.T_vote_keyword['state'] = NORMAL
self.B_0['text'] = '从排行榜搜索'
def keyboard_T_vote_keyword(self, event):
thread_it(self.searh_movie_in_keyword)
def searh_movie_in_keyword(self):
"""
从关键字中搜索符合条件的影片信息
"""
# 按钮设置为灰色状态
self.clear_tree(self.treeview) # 清空表格
self.B_0['state'] = DISABLED
self.C_type['state'] = DISABLED
self.T_count['state'] = DISABLED
self.T_rating['state'] = DISABLED
self.T_vote['state'] = DISABLED
self.B_0_keyword['state'] = DISABLED
self.T_vote_keyword['state'] = DISABLED
self.B_0_keyword['text'] = '正在努力搜索'
self.jsonData = ""
movieObject = getMovieInRankingList(); #创建对象
list,jsonData = movieObject.get_url_data_in_keyWord(self.T_vote_keyword.get())
self.jsonData = jsonData
self.add_tree(list, self.treeview) # 将数据添加到tree中
# 按钮设置为正常状态
self.B_0['state'] = NORMAL
self.C_type['state'] = 'readonly'
self.T_count['state'] = NORMAL
self.T_rating['state'] = NORMAL
self.T_vote['state'] = NORMAL
self.B_0_keyword['state'] = NORMAL
self.T_vote_keyword['state'] = NORMAL
self.B_0_keyword['text'] = '从关键字搜索'
def open_in_browser_douban_url(self, event):
"""
从浏览器中打开指定网页
:param
:return:
"""
item = self.treeview.selection()
if(item):
item_text = self.treeview.item(item, "values")
movieName = item_text[0]
for movie in self.jsonData:
if(movie['title'] == movieName):
open(movie['url'])
def open_in_browser(self, event):
"""
从浏览器中打开指定网页
:param
:return:
"""
item = self.treeview_play_online.selection()
if(item):
item_text = self.treeview_play_online.item(item, "values")
url = item_text[2]
open(url)
def open_in_browser_cloud_disk(self, event):
"""
从浏览器中打开指定网页
:param
:return:
"""
item = self.treeview_save_cloud_disk.selection()
if(item):
item_text = self.treeview_save_cloud_disk.item(item, "values")
url = item_text[2]
open(url)
def open_in_browser_bt_download(self, event):
"""
从浏览器中打开指定网页
:param
:return:
"""
item = self.treeview_bt_download.selection()
if(item):
item_text = self.treeview_bt_download.item(item, "values")
url = item_text[2]
open(url)
def ui_process(self):
"""
Ui主程序
:param
:return:
"""
root = Tk()
self.root = root
# 设置窗口位置
root.title("豆瓣电影小助手(可筛选、下载自定义电影)----吾爱破解论坛 www.52pojie.cn")
self.center_window(root, 1000, 565)
root.resizable(0, 0) # 框体大小可调性,分别表示x,y方向的可变性
# 从排行榜 电影搜索布局开始
# 容器控件
labelframe = LabelFrame(root, width=660, height=300, text="搜索电影")
labelframe.place(x=5, y=5)
self.labelframe = labelframe
# 电影类型
L_typeId = Label(labelframe, text='电影类型')
L_typeId.place(x=0, y=10)
self.L_typeId = L_typeId
#下拉列表框
comvalue = StringVar()
C_type = ttk.Combobox(labelframe, width=5, textvariable=comvalue, state='readonly')
# 将影片类型输入到下拉列表框中
jsonMovieData = loads(movieData) #json数据
movieList = []
for subMovieData in jsonMovieData: #对每一种类的电影题材进行操作
movieList.append(subMovieData['title'])
C_type["values"] = movieList #初始化
C_type.current(9) # 选择第一个
C_type.place(x=65, y=8)
self.C_type = C_type
# 欲获取的电影数量
L_count = Label(labelframe, text='获取数量=')
L_count.place(x=150, y=10)
self.L_count = L_count
# 文本框
T_count = Entry(labelframe, width=5)
T_count.delete(0, END)
T_count.insert(0, '500')
T_count.place(x=220, y=7)
self.T_count = T_count
# 评分
L_rating = Label(labelframe, text='影片评分>')
L_rating.place(x=280, y=10)
self.L_rating = L_rating
# 文本框
T_rating = Entry(labelframe, width=5)
T_rating.delete(0, END)
T_rating.insert(0, '8.0')
T_rating.place(x=350, y=7)
self.T_rating = T_rating
# 评价人数
L_vote = Label(labelframe, text='评价人数>')
L_vote.place(x=410, y=10)
self.L_vote = L_vote
# 文本框
T_vote = Entry(labelframe, width=7)
T_vote.delete(0, END)
T_vote.insert(0, '100000')
T_vote.place(x=480, y=7)
self.T_vote = T_vote
# 查询按钮
#lambda表示绑定的函数需要带参数,请勿删除lambda,否则会出现异常
#thread_it表示新开启一个线程执行这个函数,防止GUI界面假死无响应
B_0 = Button(labelframe, text="从排行榜搜索")
B_0.place(x=560, y=10)
self.B_0 = B_0
# 框架布局,承载多个控件
frame_root = Frame(labelframe, width=400)
frame_l = Frame(frame_root)
frame_r = Frame(frame_root)
self.frame_root = frame_root
self.frame_l = frame_l
self.frame_r = frame_r
# 表格
columns = ("影片名字", "影片评分", "同类排名", "评价人数")
treeview = ttk.Treeview(frame_l, height=10, show="headings", columns=columns)
treeview.column("影片名字", width=210, anchor='center') # 表示列,不显示
treeview.column("影片评分", width=210, anchor='center')
treeview.column("同类排名", width=100, anchor='center')
treeview.column("评价人数", width=100, anchor='center')
treeview.heading("影片名字", text="影片名字") # 显示表头
treeview.heading("影片评分", text="影片评分")
treeview.heading("同类排名", text="同类排名")
treeview.heading("评价人数", text="评价人数")
#垂直滚动条
vbar = ttk.Scrollbar(frame_r, command=treeview.yview)
treeview.configure(yscrollcommand=vbar.set)
treeview.pack()
self.treeview = treeview
vbar.pack(side=RIGHT, fill=Y)
self.vbar = vbar
# 框架的位置布局
frame_l.grid(row=0, column=0, sticky=NSEW)
frame_r.grid(row=0, column=1, sticky=NS)
frame_root.place(x=5, y=70)
# 从排行榜 电影搜索布局结束
# 输入关键字 电影搜索布局开始
# 影片名称
L_vote_keyword = Label(labelframe, text='影片名称')
L_vote_keyword.place(x=0, y=40)
#L_vote_keyword.grid(row=0,column=0)
self.L_vote_keyword = L_vote_keyword
# 文本框
T_vote_keyword = Entry(labelframe, width=53)
T_vote_keyword.delete(0, END)
T_vote_keyword.insert(0, '我不是药神')
T_vote_keyword.place(x=66, y=37)
self.T_vote_keyword = T_vote_keyword
# 查询按钮
#lambda表示绑定的函数需要带参数,请勿删除lambda,否则会出现异常
#thread_it表示新开启一个线程执行这个函数,防止GUI界面假死无响应
B_0_keyword = Button(labelframe, text="从关键字搜索")
B_0_keyword.place(x=560, y=40)
self.B_0_keyword = B_0_keyword
# 输入关键字 电影搜索布局结束
# 电影详情布局开始
# 容器控件
labelframe_movie_detail = LabelFrame(root, text="影片详情")
labelframe_movie_detail.place(x=670, y=5)
self.labelframe_movie_detail = labelframe_movie_detail
# 框架布局,承载多个控件
frame_left_movie_detail = Frame(labelframe_movie_detail, width=160,height=280)
frame_left_movie_detail.grid(row=0, column=0)
self.frame_left_movie_detail = frame_left_movie_detail
frame_right_movie_detail = Frame(labelframe_movie_detail, width=160,height=280)
frame_right_movie_detail.grid(row=0, column=1)
self.frame_right_movie_detail = frame_right_movie_detail
#影片图片
label_img = Label(frame_left_movie_detail, text="", anchor=N)
label_img.place(x=0,y=0) #布局
self.label_img = label_img
# IMDB评分
ft_rating_imdb = font.Font(weight=font.BOLD)
label_movie_rating_imdb = Label(frame_left_movie_detail, text="IMDB评分", fg='#7F00FF', font=ft_rating_imdb, anchor=NW)
label_movie_rating_imdb.place(x=0, y=250)
self.label_movie_rating_imdb = label_movie_rating_imdb
# 查询按钮
B_0_imdb = Button(frame_left_movie_detail, text="初始化")
B_0_imdb.place(x=115, y=250)
self.B_0_imdb = B_0_imdb
#影片名字
ft = font.Font(size=15, weight=font.BOLD)
label_movie_name = Label(frame_right_movie_detail, text="影片名字", fg='#FF0000', font=ft,anchor=NW)
label_movie_name.place(x=0, y=0)
self.label_movie_name = label_movie_name
#影片评分
ft_rating = font.Font(weight=font.BOLD)
label_movie_rating = Label(frame_right_movie_detail, text="影片评价", fg='#7F00FF', font=ft_rating, anchor=NW)
label_movie_rating.place(x=0, y=30)
self.label_movie_rating = label_movie_rating
#影片年代
ft_time = font.Font(weight=font.BOLD)
label_movie_time = Label(frame_right_movie_detail, text="影片日期", fg='#666600', font=ft_time, anchor=NW)
label_movie_time.place(x=0, y=60)
self.label_movie_time = label_movie_time
#影片类型
ft_type = font.Font(weight=font.BOLD)
label_movie_type = Label(frame_right_movie_detail, text="影片类型", fg='#330033', font=ft_type, anchor=NW)
label_movie_type.place(x=0, y=90)
self.label_movie_type = label_movie_type
#影片演员
label_movie_actor = Label(frame_right_movie_detail, text="影片演员", wraplength=135, justify = 'left', anchor=NW)
label_movie_actor.place(x=0, y=120)
self.label_movie_actor = label_movie_actor
# 电影详情布局结束
# 在线播放布局开始
labelframe_movie_play_online = LabelFrame(root, width=324, height=230, text="在线观看")
labelframe_movie_play_online.place(x=5, y=305)
self.labelframe_movie_play_online = labelframe_movie_play_online
# 框架布局,承载多个控件
frame_root_play_online = Frame(labelframe_movie_play_online, width=324)
frame_l_play_online = Frame(frame_root_play_online)
frame_r_play_online = Frame(frame_root_play_online)
self.frame_root_play_online = frame_root_play_online
self.frame_l_play_online = frame_l_play_online
self.frame_r_play_online = frame_r_play_online
# 表格
columns_play_online = ("来源名称", "是否免费","播放地址")
treeview_play_online = ttk.Treeview(frame_l_play_online, height=10, show="headings", columns=columns_play_online)
treeview_play_online.column("来源名称", width=90, anchor='center')
treeview_play_online.column("是否免费", width=80, anchor='center')
treeview_play_online.column("播放地址", width=120, anchor='center')
treeview_play_online.heading("来源名称", text="来源名称")
treeview_play_online.heading("是否免费", text="是否免费")
treeview_play_online.heading("播放地址", text="播放地址")
#垂直滚动条
vbar_play_online = ttk.Scrollbar(frame_r_play_online, command=treeview_play_online.yview)
treeview_play_online.configure(yscrollcommand=vbar_play_online.set)
treeview_play_online.pack()
self.treeview_play_online = treeview_play_online
vbar_play_online.pack(side=RIGHT, fill=Y)
self.vbar_play_online = vbar_play_online
# 框架的位置布局
frame_l_play_online.grid(row=0, column=0, sticky=NSEW)
frame_r_play_online.grid(row=0, column=1, sticky=NS)
frame_root_play_online.place(x=5, y=0)
# 在线播放布局结束
# 保存到云盘布局开始
labelframe_movie_save_cloud_disk = LabelFrame(root, width=324, height=230, text="云盘搜索")
labelframe_movie_save_cloud_disk.place(x=340, y=305)
self.labelframe_movie_save_cloud_disk = labelframe_movie_save_cloud_disk
# 框架布局,承载多个控件
frame_root_save_cloud_disk = Frame(labelframe_movie_save_cloud_disk, width=324)
frame_l_save_cloud_disk = Frame(frame_root_save_cloud_disk)
frame_r_save_cloud_disk = Frame(frame_root_save_cloud_disk)
self.frame_root_save_cloud_disk = frame_root_save_cloud_disk
self.frame_l_save_cloud_disk = frame_l_save_cloud_disk
self.frame_r_save_cloud_disk = frame_r_save_cloud_disk
# 表格
columns_save_cloud_disk = ("来源名称", "是否有效","播放地址")
treeview_save_cloud_disk = ttk.Treeview(frame_l_save_cloud_disk, height=10, show="headings", columns=columns_save_cloud_disk)
treeview_save_cloud_disk.column("来源名称", width=90, anchor='center')
treeview_save_cloud_disk.column("是否有效", width=80, anchor='center')
treeview_save_cloud_disk.column("播放地址", width=120, anchor='center')
treeview_save_cloud_disk.heading("来源名称", text="来源名称")
treeview_save_cloud_disk.heading("是否有效", text="是否有效")
treeview_save_cloud_disk.heading("播放地址", text="播放地址")
#垂直滚动条
vbar_save_cloud_disk = ttk.Scrollbar(frame_r_save_cloud_disk, command=treeview_save_cloud_disk.yview)
treeview_save_cloud_disk.configure(yscrollcommand=vbar_save_cloud_disk.set)
treeview_save_cloud_disk.pack()
self.treeview_save_cloud_disk = treeview_save_cloud_disk
vbar_save_cloud_disk.pack(side=RIGHT, fill=Y)
self.vbar_save_cloud_disk = vbar_save_cloud_disk
# 框架的位置布局
frame_l_save_cloud_disk.grid(row=0, column=0, sticky=NSEW)
frame_r_save_cloud_disk.grid(row=0, column=1, sticky=NS)
frame_root_save_cloud_disk.place(x=5, y=0)
# 保存到云盘布局结束
# BT下载布局开始
labelframe_movie_bt_download = LabelFrame(root, width=324, height=230, text="影视下载")
labelframe_movie_bt_download.place(x=670, y=305)
self.labelframe_movie_bt_download = labelframe_movie_bt_download
# 框架布局,承载多个控件
frame_root_bt_download = Frame(labelframe_movie_bt_download, width=324)
frame_l_bt_download = Frame(frame_root_bt_download)
frame_r_bt_download = Frame(frame_root_bt_download)
self.frame_root_bt_download = frame_root_bt_download
self.frame_l_bt_download = frame_l_bt_download
self.frame_r_bt_download = frame_r_bt_download
# 表格
columns_bt_download = ("来源名称", "是否有效","播放地址")
treeview_bt_download = ttk.Treeview(frame_l_bt_download, height=10, show="headings", columns=columns_bt_download)
treeview_bt_download.column("来源名称", width=90, anchor='center')
treeview_bt_download.column("是否有效", width=80, anchor='center')
treeview_bt_download.column("播放地址", width=120, anchor='center')
treeview_bt_download.heading("来源名称", text="来源名称")
treeview_bt_download.heading("是否有效", text="是否有效")
treeview_bt_download.heading("播放地址", text="播放地址")
#垂直滚动条
vbar_bt_download = ttk.Scrollbar(frame_r_bt_download, command=treeview_bt_download.yview)
treeview_bt_download.configure(yscrollcommand=vbar_bt_download.set)
treeview_bt_download.pack()
self.treeview_bt_download = treeview_bt_download
vbar_bt_download.pack(side=RIGHT, fill=Y)
self.vbar_bt_download = vbar_bt_download
# 框架的位置布局
frame_l_bt_download.grid(row=0, column=0, sticky=NSEW)
frame_r_bt_download.grid(row=0, column=1, sticky=NS)
frame_root_bt_download.place(x=5, y=0)
# BT下载布局结束
#项目的一些信息
ft = font.Font(size=14, weight=font.BOLD)
project_statement = Label(root, text="豆瓣电影小助手(可筛选、下载自定义电影)----吾爱破解论坛 www.52pojie.cn", fg='#FF0000', font=ft,anchor=NW)
project_statement.place(x=5, y=540)
self.project_statement = project_statement
#绑定事件
treeview.bind('<<TreeviewSelect>>', self.show_movie_data) # 表格绑定选择事件
treeview.bind('<Double-1>', self.open_in_browser_douban_url) # 表格绑定鼠标左键事件
treeview_play_online.bind('<Double-1>', self.open_in_browser) # 表格绑定左键双击事件
treeview_save_cloud_disk.bind('<Double-1>', self.open_in_browser_cloud_disk) # 表格绑定左键双击事件
treeview_bt_download.bind('<Double-1>', self.open_in_browser_bt_download) # 表格绑定左键双击事件
B_0.configure(command=lambda:thread_it(self.searh_movie_in_rating)) #按钮绑定单击事件
B_0_keyword.configure(command=lambda:thread_it(self.searh_movie_in_keyword)) #按钮绑定单击事件
B_0_imdb.configure(command=lambda: thread_it(self.show_IDMB_rating)) # 按钮绑定单击事件
T_vote_keyword.bind('<Return>', handlerAdaptor(self.keyboard_T_vote_keyword)) # 文本框绑定选择事件
project_statement.bind('<ButtonPress-1>', self.project_statement_show) # 标签绑定鼠标单击事件
project_statement.bind('<Enter>', self.project_statement_get_focus) # 标签绑定获得焦点事件
project_statement.bind('<Leave>', self.project_statement_lose_focus) # 标签绑定失去焦点事件
root.mainloop()
以上是关于Python实战爬取豆瓣排行榜电影数据(含GUI界面版)的主要内容,如果未能解决你的问题,请参考以下文章
Python爬虫编程思想(87):项目实战--抓取豆瓣电影排行榜
Python 从底层结构聊 Beautiful Soup 4(内置豆瓣最新电影排行榜爬取案例)!
Python爬虫实战(1)requests爬取豆瓣电影TOP250