技术内参-搜索部分
Posted bohu83
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了技术内参-搜索部分相关的知识,希望对你有一定的参考价值。
一序
本文从极客时间的AI技术内参上,试读了几节。整理下学习笔记,我的感受就是洪亮劼老师,会引导你思考一些问题,不仅仅算法怎么实现。
二 如何搭建数据团队
这篇给我触动较大,改变了我之前的一些看法。
数据大致分为两个方向:数据分析、算法模型。每个方向对于人的要求是不一样的。
如果是基于现有数据,不管是hive\\spark那种导数据多一些,还是偏向于数据分析。如果是通过算法改善产品,提供支撑,还是算法模型的更合适 。
团队规模:
这个基本上跟公司的规模有关,大厂,业务多复杂,有大团队,就是每个方向细分。也有相应的数据资源来提供。就是”专才“
小公司,那就是相反了,啥都得干。就这么几个人,还得玩得转。所以数据采集,平台搭建,你也不能闷头做这一块,还得跟产品其它开发一起,看看怎么配合做支持需求。
不要复杂的算法,也没有那么多数据支持,快速识别需求背后如何实现快速落地更重要。就是”通才“。业务发展起来了,就需要”专才“来支撑。
有一点:从”通才“到”专才“需要长时间的训练,短期内不可逾越。这个积累的过程是少不了的。
我自己体会很深,因为平时大家都要做业务,去搬砖。不忙了才有时间去看看,再说这个机器学习无论是数学还是算法都难理解。
就算算法有,如何跟业务结合起来,自己去哪里爬取数据啊,来写的demo验证想法,都需要时间。而且不像是Java,遇到问题没人会跟你讨论。
三 数据驱动
闭环,先收集数据。
数据驱动:应该是一种意识,根据数据找原因,ABtest等。
四 评估体系
”如果你没法衡量它,你就没办法改善它‘。这里也是需要“指标”“评估”
指标:如产品的经济收益。
层次话评估体系:从某个模块、某个页面到用户这个层级。
用户下单的过程,链路较长,需要结合复杂的用户轨迹,去综合分析。
从单个用户到多个用户,从用户到产品的长期指标。
五 优化长期目标
要有长期目标,还要建立短期目标与长期目标的联系,优化短期目标间接优化于长期目标。
就是结合上面的层次话评估体系,如何从能直接影响用户的一二层级来影响高层级的指标。
还有用数据来验证,低层次指标跟高层次指标之间的关系。
六 BM25算法
现代 BM25 算法是用来计算某一个目标文档(Document)相对于一个查询关键字(Query)的“相关性”(Relevance)的流程。通常情况下,BM25 是“非监督学习”排序算法中的一个典型代表。
这里的“非监督”是指所有的文档相对于某一个查询关键字是否相关,这个信息是算法不知道的。也就是说,算法本身无法简单地从数据中学习到相关性,而是根据某种经验法则来“猜测”相关的文档都有什么特质。
BM25的公式主要由三个部分组成:
- query中每个单词t与文档d之间的相关性
- 单词t与query之间的相似性
- 每个单词的权重
主要思想:对Query进行语素解析,生成语素qi;然后,对于每个搜索结果D,计算每个语素qi与D的相关性得分,最后,将qi相对于D的相关性得分进行加权求和,从而得到Query与D的相关性得分。
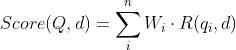
Q表示Query,qi表示Q解析之后的一个语素,d表示一个搜索结果文档;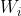 表示语素qi的权重;R(qi,d)表示语素qi与文档d的相关性得分。
表示语素qi的权重;R(qi,d)表示语素qi与文档d的相关性得分。
判断一个词与一个文档的相关性的权重常用的是IDF.
单词与文档的相关性:
BM25的设计依据一个重要的发现:词频和相关性之间的关系是非线性的,也就是说,每个词对于文档的相关性分数不会超过一个特定的阈值,当词出现的次数达到一个阈值后,其影响就不在线性增加了,而这个阈值会跟文档本身有关.
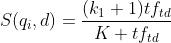
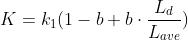
其中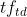 是单词t在文档d中的词频,
是单词t在文档d中的词频,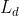 是文档d的长度,
是文档d的长度,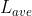 是所有文档的平均长度,
是所有文档的平均长度,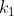 是一个正的参数,用来标准化文章词频的范围,b是另一个可调参数(0-1)他是用决定使用文档长度来表示信息量的范围:当b为1,是完全使用文档长度来权衡词的权重,当b为0表示不使用文档长度。
是一个正的参数,用来标准化文章词频的范围,b是另一个可调参数(0-1)他是用决定使用文档长度来表示信息量的范围:当b为1,是完全使用文档长度来权衡词的权重,当b为0表示不使用文档长度。
单词与query的相关性:
当query很长时,我们还需要刻画单词与query的之间的权重
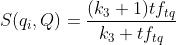
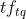 表示单词t在query中的词频,
表示单词t在query中的词频,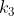 是一个可调正参数,来矫正query中的词频范围。
是一个可调正参数,来矫正query中的词频范围。
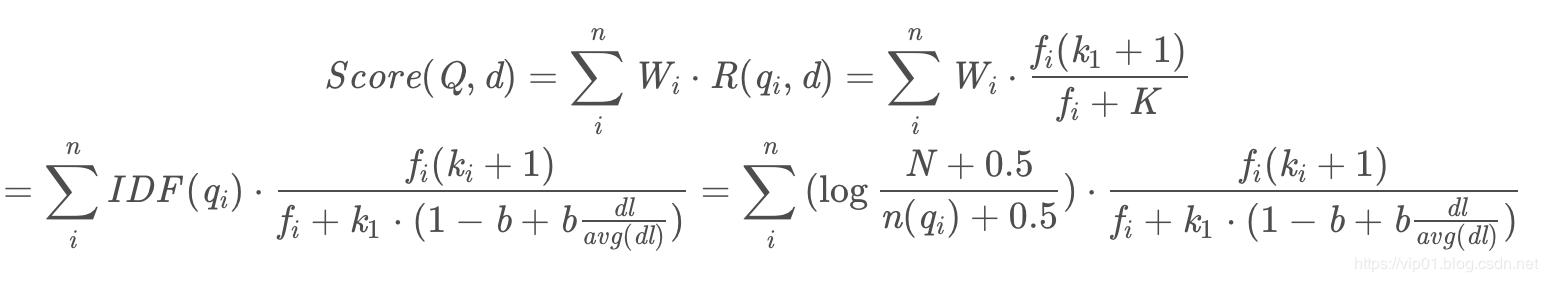
BM25 其实是一个经验公式。这里面的每一个成分都是经过很多研究者的迭代而逐步发现的。很多研究在理论上对 BM25 进行了建模,从“概率相关模型”(Probabilistic Relevance Model)入手,推导出 BM25 其实是对某一类概率相关模型的逼近,BM25 虽然是经验公式,但是在实际使用中经常表现出惊人的好效果。
七 查询关键字理解
查询关键字理解,我们希望通过查询关键字来了解用户背后的目的。
一 基本步骤是给查询关键字分类,看这些关键字有什么用户意图。举例是比较粗的三类:信息意图、交易意图、导航意图。
关键字解析:
这就是可以理解为中文的分词,如何切分更准确。(方法:N元语法、互信息、条件随机场)
关键字标注:就是词性标注。
查询关键字扩展(Query Expansion)
主要目的不仅仅是希望能够对用户输入的关键字进行理解,还希望能够补充用户输入的信息,从而达到丰富查询结果的效果。
对“精度”和“召回”的平衡,成了查询关键字扩展的一个重要的权衡点。查询关键字扩展的另外一个重要应用就是对同义词和缩写的处理。
查询关键字扩展的技术
核心就是找到搜索结果意义上的“同义词”。
第一种思路,是通过用户的交互数据来产生一个图,并且利用图挖掘技术来得到查询关键字之间的关系;
另外一个就是通过产生词汇的嵌入向量从而得到同义词。这个就是比较流行的word2vec.
把文字找到数值表达,就是嵌入,再通过文字周围的“上下文信息”(Contextual)来对单词本身的“嵌入向量”进行学习可以有效地学习到单词的语义。
以上是关于技术内参-搜索部分的主要内容,如果未能解决你的问题,请参考以下文章