在AWS上使用Presto和Alluxio构建高性能平台以支持实时游戏服务
Posted Alluxio
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了在AWS上使用Presto和Alluxio构建高性能平台以支持实时游戏服务相关的知识,希望对你有一定的参考价值。
概 述
电子艺界(EA)是一家游戏行业的领军企业,为全球数十亿用户提供超过一千种游戏。EA的数据和人工智能部门构建了数百个平台来管理游戏和用户每天生成的PB级数据。这些平台涵盖了大范围的数据分析,从实时数据抽取到ETL流水线过程。企业高管、制作人、产品经理、游戏工程师和设计师广泛使用我们部门产生的格式化数据,以进行营销变现、游戏设计、客户参与度、玩家留存度和最终用户体验等分析。
 EA在线服务的近实时信息对于制定业务决策(例如活动和问题定位)至关重要。这些服务包括但不限于实时数据可视化,仪表板和会话分析。我们的团队正在积极寻求可以支持这些用例的框架。
EA在线服务的近实时信息对于制定业务决策(例如活动和问题定位)至关重要。这些服务包括但不限于实时数据可视化,仪表板和会话分析。我们的团队正在积极寻求可以支持这些用例的框架。
在EA,我们采用了许多数据可视化工具,例如Tableau和Dundas,以支持数据洞察分析。这些工具通常与多个数据源连接,例如mysql DB,AWS S3或HDFS。使用者可以同时从多个端点加载数据以运行计算密集型算法。一个严重的性能瓶颈是数据加载,因为它是I/O密集负载。当需要多次加载相同的数据,则可能会加剧性能瓶颈情况。因此,我们需要一种通过本地缓存数据来减少数据检索开销的解决方案。
仪表展示是另一个常见用例,用以实时跟踪用户参与度,客户满意度或系统状态。在这些情况下,数据量通常约为GB级,但是频繁刷新需要实时处理。目前,我们使用诸如Redshift之类的商业数据库来对时间敏感的数据提供服务,并且我们正在寻找一种能在不损失性能的情况下削减成本的替代方案。
我们最近开发了一个报告机器人,它可以提供游戏内部即时的相关数据,例如实时用户满意度和实时利润分析。该系统的后端使用存储在S3中的PB级数据运行Presto。机器人将用户的问题转换为ANSI SQL,并在Presto集群中运行这些查询。查询通常进行复杂计算,例如跨越数据集搜索后的预测和合并。我们希望找到一种解决方案,该解决方案可以补充基于S3的数据集,从而在不增加额外成本的情况下提高性能。
系统架构
我们将Alluxio评估为存储和数据处理平台之间的数据编排层。Alluxio已被公认为是高性能的数据编排系统,并已在众多数据处理系统中广泛采用。在我们的评估中,我们将前述的Presto在S3生产环境配置的模拟与Alluxio的类似数据栈进行了比较。架构如下所示:
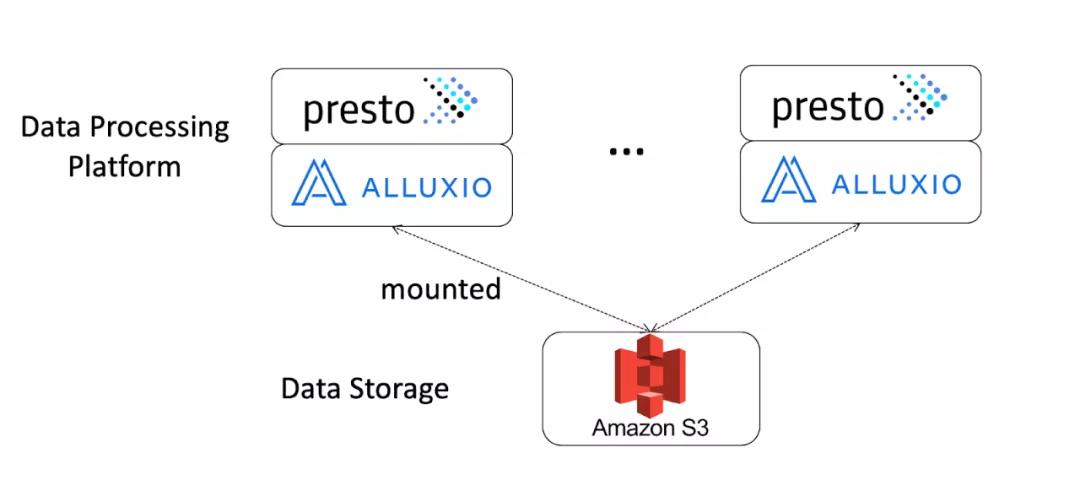
-
每个实例都启动了Presto和Alluxio,这两个服务处于同一位置。
-
对于硬件,我们使用了三个h1.8xlarge的AWS实例,每个实例都挂载有8TB临时磁盘供Alluxio使用,以缓存Presto本地数据。
-
S3被挂载到Alluxio作为基础持久化文件系统。
-
为Presto配置了两个目录;一个连接到我们现有的Hive
Metastore,引用外部存储在S3上的基准数据集,另一个连接到具有在Alluxio中创建的基准表的单独的Hive Metastore。 -
我们在S3上使用了相同的数据集进行性能比较,并使用alluxio fs distributedLoad /
testDB命令将数据预加载到Alluxio中。
使用以下配置启动Alluxio集群:
# Impersonation
alluxio.master.security.impersonation.presto.users=*
alluxio.master.mount.table.root.ufs=<s3://alluxio_path>
alluxio.security.authorization.permission.enabled=false
alluxio.security.authentication.type=SIMPLE
alluxio.security.authorization.permission.supergroup=*
# Alluxio Worker tier configuration
alluxio.worker.block.heartbeat.interval=30sec
# Prevent disk thrashing
alluxio.user.file.passive.cache.enabled=false
# Increase Threadpool concurrency for Presto
alluxio.user.block.master.client.pool.size.max=256
alluxio.user.file.master.client.pool.size.max=256
# Return full list of blocks
alluxio.user.ufs.block.location.all.fallback.enabled=true
# Worker properties
alluxio.worker.tieredstore.levels=1
alluxio.worker.tieredstore.level0.dirs.mediumtype=HDD
alluxio.worker.tieredstore.level0.dirs.path=</path1>
alluxio.worker.tieredstore.level0.dirs.quota=<1000GB>
# file replica
alluxio.user.file.replication.max=3
# User properties
alluxio.user.file.readtype.default=CACHE_PROMOTE
# Writes data only to Alluxio beforereturning a successful write
alluxio.user.file.writetype.default=MUST_CACHE
以上展示了初始的 alluxio-site.properties
我们注意到在处理大量小文件时,Alluxio的表现不如预期。我们启用了元数据缓存来调整性能:
alluxio.user.metadata.cache.enabled=true
alluxio.user.metadata.cache.max.size=100000
alluxio.user.metadata.cache.expiration.time=10min
以上展示了alluxio-site.properties 设置以激活元数据缓存。
基准测试结果
在分别使用Alluxio和不使用Alluxio的情况下,运行四个独立基准来对性能进行基准测试:
测试1:运行我们的内部基准测试,该测试将玩家游戏中事件快照合成。数据集采用ORC格式,总大小为1GB,10GB和100GB。每个数据集都使用相同的DDL创建,包含49个cols,40个varchar,5个布尔值和4个映射。基准查询选择具有一个varchar字段过滤条件的所有列,这是典型的重度I / O负载查询用例。
结果:具有元数据缓存的Alluxio比S3快2到7倍。
测试2:使用游戏元数据和用户参与记录来模拟数据可视化。我们分别选择了Tableau和Dundas中经常使用的两个常用数据集和查询。查询选择所有具有日期过滤条件的列,接着是日期的GROUP BY和ORDER BY。这是一个典型的同时强调CPU和I / O的查询。在此测试中,我们不需要在Alluxio中启用元数据缓存,因为它已经显示出显著的改进。
结果:如果没有元数据缓存,使用Dunuxs数据集的Presto和Alluxio的速度比S3快2.75倍,而使用Tableau数据集的速度则快5.1倍。
测试3:使用包含大量小文件的数据集来模拟我们的仪表板用例。数据集是2MB大小的批文件,共50、500和5000个文件。使用的查询是一个选择查询,聚合每个日期的条目数。
结果:具有元数据缓存的Alluxio比S3快1.2到5.9倍。当没有元数据缓存,Alluxio的速度仅提高1倍至1.35倍。通过存储元数据,识别热数据并增加副本,启用元数据缓存可显著减少执行时间。
测试4:模拟会话机器人。使用的数据集是每日游戏性能的快照。该查询包含多个计算阶段,以模拟CPU密集型查询。它将整数字段转换为HyperLogLog,将其合并,然后选择基数。结果由整数和varchar字段过滤。
结果:没有元数据缓存的Alluxio将时间从85.2秒缩短到3秒,从而将性能提高了27倍。
结 论
这篇博客探索了一个以Presto作为计算引擎,并以Alluxio作为Presto和S3存储之间的数据编排层,以支持在线服务,并在游戏行业内提供即时响应的新平台。我们通过数据可视化,仪表板和对话式聊天机器人的实际工业界用例评估了该平台。我们的初步结果表明,在所有情况下,带有Alluxio的Presto均明显优于S3。特别是具有元数据缓存的Alluxio在处理大量小文件时显示出高达5.9倍的性能提升。Alluxio通过管理分配的临时磁盘来将数据从本地S3缓存到Presto,从而实现存储和计算的分离。先进的缓存管理,以及针对热数据和冷数据的不对称副本数量,能够在我们测试的每种情况下提高性能。
以上是关于在AWS上使用Presto和Alluxio构建高性能平台以支持实时游戏服务的主要内容,如果未能解决你的问题,请参考以下文章
使用 Presto 和 Alluxio 在 AWS 上搭建高性能平台来支持实时游戏服务
金山云团队分享 | 5000字读懂Presto如何与Alluxio搭配