计算机编码详解_什么是计算机编码?计算机编码的起源与操作系统是如何解码的。
Posted 17岁boy想当攻城狮
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了计算机编码详解_什么是计算机编码?计算机编码的起源与操作系统是如何解码的。相关的知识,希望对你有一定的参考价值。
目录
前言
你是否有过这样的疑惑?
- 1.我的代码里面中文注释在自己电脑上是可以正常显示的,但是换了别的电脑出现了乱码。
- 2.想写跨平台程序,但是在Windows上明明正常的,到了Linux下源代码全变乱码,甚至编译都过不去还会出现一些乱七八糟的错误。
- 3.不知什么是wchar、utf-8和utf-16的区别,更不知什么是gbk2312。
- 4.看到别人代码里有针对wchar和char两种字符集写法,不知为何这样做
- 5.完全不知何时用宽字符和单字符
- 6.不知道计算机是如何显示编码的
- 7.分不清unicode和utf-8的区别
如果想成为资深程序员编码是必须要走的路,因为资深程序员的代码都较为严谨,写出来的程序能应对不同平台,不同的情况。
你是否发现自己的程序健壮性始终不如别人?这是因为别人比你考虑得多且思路清晰。
考虑得多得前提下是你要对这个行业里得规则,也就是原理了解得透彻才能在这基础之上去加入你自己得想法。
当然衡量程序健壮性得因素有很多,编码几乎算不上,但是如果想要让你得程序适应性更强,那么编码少不了。
不然可能会出现你得程序在当前系统下运行好好的,换了个系统有些字就变成了乱码,这种情况就代表你得程序适应性很差。
本篇文章的代码以C/C++的语法编写
编码是什么?
在介绍编码之前先说一下操作系统是如何显示我们平时所看见的字符的
屏幕对于操作系统来说就是一个二维数组,也就是一个像素点阵,有宽和高,那么计算机如果想在这个2X2的像素点阵里显示一个字符是也很简单
举个简单的列子:
如果想要在像素点阵里显示一个1,那么操作系统需要根据预设x和y的坐标来确定像素位置,然后在这个位置开始绘制1,同时要确定1的大小,占多少像素范围,那么操作系统会在本地建立一个表,就像列表一样的东西,里面存储不同的字符如何绘制的,比如1应该在每行中点亮哪些像素点,而2应该在每行中点亮哪些像素点,这个表就叫字符集,而这个方式就叫编码。
人们把不同的字符写入到字符集里,明确规定计算机应该怎样绘制不同的字符,这个过程就叫编码。
操作系统是如何绘制编码的
如简单的一个江字
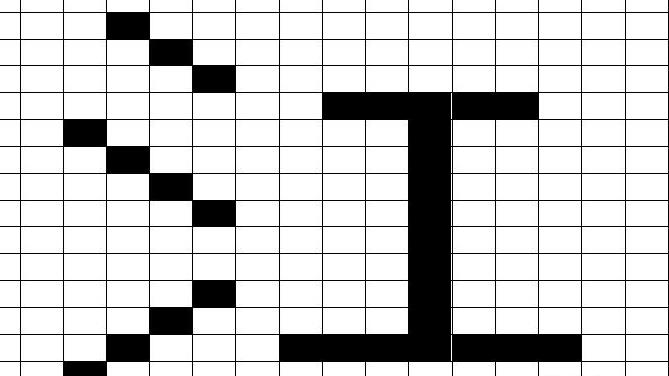
可以把上面的格子看成数组,每个白格代表一个元素,然后告诉计算机每行哪个元素应该被绘制,这样计算机就会在每行里绘制一个点,点的颜色根据用户的设置来决定,当点密集起来就会让你感觉它像一个字。
所以字符集里存储的都是数,比如{23,76,88},23的二进制代表10111,那么计算机就会根据10111为规则,在第一行里第一个元素绘制一个点,第二个元素不绘制,凡是BIT为1的都依次绘制点,然后依次类推下一行,就组成了一个字。
其实下面一张图可以很好的解释我上面的解释

这张图我相信学过自制操作系统的或者上过操作系统课的同学一定不陌生,我就是从操作系统原理上学到计算机是如何显示字符的。
简单点来说:
编码就是制作字符集时的规则,字符集里包含了一个字符的绘制方法,方法都是以十六进制数存储的,操作系统到时候会解出这个数的BIT位,然后在每行的像素矩阵里如果BIT位为1的绘制一个点,为0则不绘制。
字符集需要规定字符站的宽度,高度,这些都是需要来控制,所以一般我们叫编码规则,编码规则只是规范一个编码的显示方式。
通常情况下一个字是有锯齿的因为像素点本身就是紧凑一起的,不是一条线直连的。

之所以我们平时看不到锯齿是因为像素比较高,你把屏幕像素改低点你就能看见字符变得锯齿明显,不美观。
现代计算机一般会用模糊的方式来消除锯齿,就是模糊算法将锯齿边缘使用模糊算法模糊掉,也就是平滑操作,使其看起来更美观,消除锯齿,就跟PS的羽化功能一样。
编码的起源
最初设计编码是为了让计算机能显示更多的东西,因为一开始计算机只能处理数字,且自认0101,后来人们发现计算机性能逐渐强大,不光只能用于计算还能用来做别的事情。
但是计算机那个年代又被限制死了,只认0101所以就需要操作系统来帮忙解决这一问题,人们把不同的字符转化成0101,然后计算机根据0101通过编码表解码出来,就是想要的信息了,就如我上面说的一样。
最初的编码EBCDIC是IBM在1963年制定的,在1964年完善的,最开始每个操作系统内部都带了这种编码规则的字符集用来显示字符。
到后来计算机逐渐广泛,应用于世界各地,人们需要更大的编码表来显示不同国家的语言,所以就横空出世了许多的编码规则
如:
ASCII
GBK
Unicode
CCCII
等等,这些编码都是针对不同国家语言诞生的,同时Unicode和GBK是目前最广泛的编码,其背后是不同的操作系统在支持。
Unicode是Linux默认编码,GBK是Windows。
Unicode和Utf-8的区别
Unicode是编码规则
utf-8是字符集
utf-8是根据Unicode的编码规则来指定的字符集。
什么是抽象码?它与编码的区别
如一个字符集里的A是这样的:
{53,66,77,12,64,18,23}
里面的数字就代表抽象码
抽象即与目标有联系,有本质的相同点但又不能代表目标,但是可以被抽象出来为目标。
但是如何知道这段抽象码代表谁?
答:
编码就像数据库的key一样,一个key对应一段数据,通过key找到这段数据。
Utf-8与Utf-16
utf-8和utf-16的区别就是一个是占8位一个是占16位,占16位的编码意味着可以存储更大更繁琐的字,如中文,所以Utf-8一般用来显示英文,但是现在Utf-8已经能够显示中文了,但是不能显示较为复杂的文字,比如象形文字。
目前是谁在维护编码统一性?
ISO/IEC组织标准组织,为了防止编码乱七八糟,它们指定了一个规则,如果你想发明新的字符集需要根据它们的规定来,否则你的编码无法在别的机器上跑起来,除非你自己编写操作系统,不去符合POSIX标准。
宽字符与窄字符的区别
1.窄字符
窄字符就是char类型,char为1字节大小,也就是8bit,最大只能表示ASCII码表里的256个基础字符与符号,它只能用于ASCII码表,若您的计算机不支持ASCII码表,那么你的程序里用char存储的字符都无法正常显示,但是现在基本上不存在这种情况,现代计算机全部都支持ASCII码。
为什么说它只能用于ASCII码呢?因为只有ASCII的编码支持1字节大小的抽象码。
当你用char存储一个汉字,是无法正常打印的
如:
char f = '喊';
printf("%c\\n", f);打印结果:

这里来说一下当你是窄字符并且使用utf-8编码时为什么可以打印,明明窄字符是1字节
答:字符集里不同的字符有不同的复杂程度,同时也有不同大小的描述
比如当你使用的是UTF-8编码,而你个char里只写了一个简单的字符‘A’,在UTF-8编码里,A只占了一个字节,可以轻松描述。
大部分中文占用两个字节,所以utf-8也一样可以表示,所以你也无需担心使用UTF-16会不会让程序体积增加这样的情况产生。
实际的ASCII码也会转换成utf-8编码
| Unicode/UCS-4 | bit数 | UTF-8 | byte数 | 备注 |
| 0000 ~ 007F | 0~7 | 0XXX XXXX | 1 | |
| 0080 ~ 07FF | 8~11 | 110X XXXX 10XX XXXX | 2 | |
| 0800 ~ FFFF | 12~16 | 1110 XXXX 10XX XXXX 10XX XXXX | 3 | 基本定义范围:0~FFFF |
| 1 0000 ~ 1F FFFF | 17~21 | 1111 0XXX 10XX XXXX 10XX XXXX 10XX XXXX | 4 | Unicode6.1定义范围:0~10 FFFF |
| 20 0000 ~ 3FF FFFF | 22~26 | 1111 10XX 10XX XXXX 10XX XXXX 10XX XXXX 10XX XXXX | 5 | 说明:此非unicode编码范围,属于UCS-4 编码 早期的规范UTF-8可以到达6字节序列,可以覆盖到31位元(通用字符集原来的极限)。尽管如此,2003年11月UTF-8 被 RFC 3629 重新规范,只能使用原来Unicode定义的区域, U+0000到U+10FFFF。根据规范,这些字节值将无法出现在合法 UTF-8序列中 |
| 400 0000 ~ 7FFF FFFF | 27~31 | 1111 110X 10XX XXXX 10XX XXXX 10XX XXXX 10XX XXXX 10XX XXXX | 6 |
在说一个小插曲:
同时ASCII码其实是七位bit的,而char是八位bit的,最高位是为了表示符号位用的,很多人都说char能表示8^2次方这么多字符,其实这一点是有误的。
char是最大也只用到了7位bit,同时ASCII码最大也只能存储7^2次方个字符,还有一位是用来表示大小写的,这是ASCII码的规范。
2.宽字符
宽字符即多个字节表示一个字符,一般应用于unicode、gbk等等国际编码。
在编程语言中用wchar_t来表示宽字符,一般是16位即utf-16,同时编译器还提供了许多针对宽字符操作的API,如最经典的WindowsAPI就提供了两套API实现函数,一种是普通的ASCII码的,一种是unicode编码的。
如:
SetWindowsA 这个是ASCII码的
SetWindowsW 这个是宽字符的
一般来说使用char类型的都为ASCII码的API函数。
在宽字符里它可以存储更复杂的编码,通常情况下跨国际开发都会采用wchar_t.,微软会比较推wchart_t,这个原因大概就是微软是跨国企业。
unicode编码是推荐大家使用的,因为现在操作系统包括windows xp这种老系统都默认支持unicode编码,所以当你的程序是使用unicode编码时编译发布到世界任何一台电脑上都不会出现乱码这种糟糕的情况产生。
多字节字符
多字节字符就是char*,它是由多个char窄字符组成的一连串字符集,当你使用这种类型的变量时,它就可以存储宽字符也可以存储窄字符,具体大小由你的多字节字符控制。
通常情况下只要你的多字节字符集够大,就能存储编码里的所有字符,也不需要宽字符来处理更复杂的编码,但是坏处在于,你无法确定它究竟有多大。
比如char* ff = "你好“
你想取出这个里面有多少个汉字。
你使用strlen函数却发现返回的是4
这是因为中文在utf-8里占两个字节,而strlen是以char为单位来遍历,直到找到\\0为结尾。
而当ff=”ab“的时候你使用strlen就返回了2,这是因为不同的编码,utf-8编码表里所占的字节不同,越简单的字符越容易描述,所以占用字节就越少。
所以通常在未知的情况下,你无法确定utf-8这种可变长字符究竟有多大,你也无法知道用户输入的是中文还是英文,还是中英夹杂的字符。
文件编码与程序编码
文件编码是你当前在编辑源代码时,代码里的字符串是以什么样的编码存储,这也是为什么很多人在windows上写的代码到linux下进行编译就会出现乱码以及编译器无法解析的字符串,一些莫名其妙的问题。
程序编码是程序运行之后在处理字符串时所使用的编码。
如何设置你的程序编码
在Linux环境下,若用户不去指定你编码格式则默认是UTF-8,在Windows环境下则默认是GBK2312。
在Linux环境下使用GCC编译器可以使用-fexec-charset参数来指定应用程序采用的编码。
当然你也可以指定GCC使用什么样的编码去解析你的源代码,比如你在Windows上使用了GBK的编码来编辑你的源代码,那么在Linux下难免不会出现报无法识别的编码之类的问题,你可以在Linux下装上与Windows端对应的编码
然后使用-finput-charset参数来指定。
示列:
gcc test.c -fexec-charset=utf-8 -finput-charset=gbk2312可以写一个简单的程序验证一下
下面代码会打印出每个字符的16进制码
#include <stdio.h>
int main(int argc, char **argv)
{
int i = 0;
unsigned char *str = "1234中";
while(str[i])
{
printf("%02x ",str[i]);
i++;
}
printf("\\n");
return 0;
} 输出:
31 32 33 34 e4 b8 ad
根据这些输出可以在utf-8码表里去看一下
| 字符 | 编码10进制 | 编码16进制 | Unicode编码10进制 | Unicode编码16进制 |
| 中 | 14989485 | E4B8AD | 20013 | 4E2D |
可以看到验证是正确的。
那么在Windows环境下如何指定呢?
如果你想设置当前源代码文件中char使用的字符集可以使用如下编译器命令:
#if _MSC_VER >= 1600
#pragma execution_character_set("utf-8")
#endif需要你的msvc编译器大于1600
当然如果你想设置当前解决方案上的所有源文件使用统一编码,在visual studio上你可以这样做
在项目的属性页里设置

第一种方法只是针对于某个单一文件,通常情况下我们是将这个代码写成一个头文件,然后让每个源文件都包含它,来指定编码,但是visual studio这个方法会更加便捷。
visual studio无法主动设置文件编码,这里推荐一个方法,如果你发现使用visual studio打开文件乱码,可以使用记事本先打开然后另存时选择你的编码就可以了。
在程序运行过程中,是谁来将二进制编码转换成字符集的?
当源代码编译成可执行程序后,里面的字符都会被编译器翻译成当前环境使用的编码对应的十六进制数。
但是当你的程序运行时不是由编译器给你写代码来去当前操作系统里的编码表里转换的,而是操作系统。
如printf这个函数,它其实调用的是操作系统内核提供的打印输出函数,编译器只负责根据当前使用的字符集,来将你的字符串转换成对应的编码,最后的解析是由你调用了的那些打印输出函数或者显示函数来完成转换。
所以准确一点来说是由操作系统内核来完成这系列工作的。
如何解码?
通过前面的知识,我们知道了是谁来生成字符集的编码,谁来处理它们,如我们前面说的,utf-8编码是可变长不规则的编码,它的大小不定,那么在一连串的编码里是如何识别出来它的呢?
比如:
1234中,这样的字符串,当编译之后就是31 32 33 34 e4 b8 ad
那么printf实际在处理时看到的是31323334e4b8ad这样的字符集,它怎么知道谁是谁的呢?
比如1占两个字节,而中占四个字节它是如何区分的呢?
其实很简单
utf-8编码在开始时,是有开始位和结束位,开始一般是:
111这样的bit位,比如:
10 这样的开始位就代表这个占一个字节,那么printf取一个字节然后转换成16进制的编码去utf字符集里去找就可以了。
如果是110则代表两个字节,前面有多少个1代表这个编码占多少个字节。0对于utf就是分隔符的意义。
其中还有一些其它的特点,比如当这个编码占4个字节的时候,utf要求第4个字节的开始位设置为10,剩下的6个bit位才能使用。
utf是没有结束位的,一般通过最开始的1确认几个字节之后在以当前为第一个字节往后读,然后在以utf特定的算法转去除标志位然后在转为16进制的编码去字符集里去找就可以了。
c语言如何控制编码
在c语言独写文件时候必不可少的是fopen,其实fopen是可以用来控制编码的
fopen("newfile.txt", "rw, ccs=<encoding>");把里面的encoding替换成你对应的编码就可以了。
如:unicode,utf-8,utf16-le
不同编码的处理速度
刚刚说到utf-8编码是比较快的编码,它是可变长的编码不像有些编码是固定长度的,所以当有些字符比较小的时候一个字节就能表示时,有些固定编码的字符集就要求多个字节,然后多的字节则填0,这就很占strcpy或者printf处理的时间,包括传输上也是。
字节越少就越快,所以一般情况下大家都会选择这种可变长的unicode编码。
以上是关于计算机编码详解_什么是计算机编码?计算机编码的起源与操作系统是如何解码的。的主要内容,如果未能解决你的问题,请参考以下文章