unicode编码详解,一看就懂
Posted hahlzj
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了unicode编码详解,一看就懂相关的知识,希望对你有一定的参考价值。
一、Unicode编码
1 UTF-8 -16 -32编码和Unicode编码
Unicode编码是一种计算机字符编码标准,其实个人认为叫字符集更为准确;而我们熟悉的UTF-8 UTF-16 UTF-32是Unicode的具体实现(怎么存储在计算机)。
1)Unicode编码规范制定标准:
把世界上所有能出现的字符,都为其分配一个数字来表示,比如,数字U+7F57被分配给了汉字中的"罗"字。Unicode编码的标准里字符数量一直实在新增(包括一些稀有字符,当然emoji表情字符也属于unicode编码哈哈),19年3月刚发布了Unicode12.0版本,比之前的版本新增了一些字符,现在在标准中的字符一共有137929个,而Unicode编码目前规划了U+0000至U+10FFFF为unicode编码(以世界上字符的数量应该是很久不会考虑扩展的),算一下目前还剩下976183(1114112-137929)个代码点,这976183个代码点是规划在unicode中的数字,但是还没被分配对应的字符。
2)UTF-8编码:
UTF-8可以说是当前互联网最常用的编码格式了,它基于Unicode字符集进行编码设计。它最大的特点是变长字节的编码设计,一个字符最长4个字节,最少1个字节,大部分的中文字符占3个字节。
编码规则如下:
1.用一个字节表示的字符,第一位设为 0,后面的 7 位对应这个字符的 Unicode 码点。由于这128个字符的unicode完全对照ASCII码,可以说完全向下兼容ASCII码。即ASCII编码的文件可以用UTF-8打开而不乱码;
2.用一个字节以上表示的字符,假设是N个字节表示这个字符:则该字符第一个字节的前N位都为1,第N+1位为0,剩下的N-1个字节的前两位都设为10,剩下没有主动设值的位置则使用这个字符的Unicode二进制代码点从低位到高位填充,不够用0补足。
编码对照表如下:
| Unicode字符集范围(十六进制) | UTF-8编码(二进制) |
| 0000 0000 - 0000 007F | 0xxxxxxx |
| 0000 0080 - 0000 07FF | 110xxxxx 10xxxxxx |
| 0000 0800 - 0000 FFFF | 1110xxxx 10xxxxxx 10xxxxxx |
| 0001 0000 - 0010 FFFF | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx |
结合编码规则和编码对照表,讲解汉字“罗”是如何编码和解码的:
编码(encode): 字符“罗”所对应的unicode代码点由以上规则转化为UTF-8所对应的二进制数字,则称为编码。可以理解为使字符成为代码的意思,而解码就是代码成为字符。
首先“罗”对应了unicode中的U+7F57,对应编码表中第三行,也就是用3个字节来表示的字符,把7F57的二进制111 1111 0101 0111?从低位对应补足到1110xxxx 10xxxxxx 10xxxxxx(从低位) 如下图所示:
最后成为11100111 10111101 10010111即十六进制E7BD97。
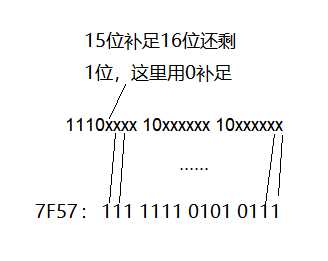
解码(decode): UTF-8所对应的二进制数字由以上规则转化为unicode码再对应到具体字符,则称为编码。
如11100111 10111101 10010111这段二进制编码,第一个字节是111,对应编码对照表则这段编码表示的字符由3个字节组成,用1110xxxx 10xxxxxx 10xxxxxx规则剔除出x对应的数为111 1111 0101 0111,即7F57,该数字对应unicode字符集中的字符“罗”。
3)UTF-32编码:
同理和UTF-8基于unicode字符集。UTF-32编码为固定长度4个字节。因为unicode范围为00FFFF-10FFFF,4个字节表示的范围为00000000-FFFFFFFF,能直接表示所有unicode编码,不需要进行转换编码转换。以空间换时间。
3)UTF-16编码:
UTF-16以2或者4个字节编码表示unicode字符:
unicode字符集中,000000-00FFFF表示的字符,在UTF-16中用2字节直接编码表示,不需要编码转换,这点和UTF-32一样(这里有点需要说明一下, U+D800 到 U+DFFF 是一个空段,即这些码点不对应任何字符,4字节需要用到)
?unicode字符集中,010000-10FFFF表示的字符,在UTF-16中用4字节编码表示,但是需要进行编码转换。比如010000-10FFFF中的某个字符X的uicode编码为AAAA AAAA AABB BBBB BBBB,分为高10位和低10位,高10位加上高位代理位D8(110110),低10位加上低位代理位DF(110111),即组成字符X的UTF-16编码110110AAAAAAAAAAA 110111BBBBBBBBBB。
二、java中的char类型
java中char类型是2个字节长度,一个char在java中称作一个代码单元,而unicode的字符编码叫做代码点。
也就是说utf-16编码中的0000-FFFF的范围可以用一个char表示,10000-10FFFF就需要用两个char来表示。
以上是关于unicode编码详解,一看就懂的主要内容,如果未能解决你的问题,请参考以下文章