阿里云服务器定时在线运行python爬虫代码
Posted 神的孩子都在歌唱
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了阿里云服务器定时在线运行python爬虫代码相关的知识,希望对你有一定的参考价值。
前言
这是我听老师讲课做的笔记
作者:神的孩子都在跳舞
关注我的csdn博客,更多python知识还在更新
前言:
为了参加计算机设计大赛,我和我的团队做了个数据分析项目,由于涉及到数据的爬取,实时更新等,所以有了这一篇文章
思路:
其实定时爬取并不难,无非就是在linux上跑程序,加上一个时间给它,如果你学过linux那么一定听说过这个cron服务,接下来我们就用它弄个定时任务就可以了
服务器:centos
任务管理:cron服务
环境:python3.7
对于cron服务不了解的可以看我这篇文章cron服务——Linux计划任务管理
使用xshell连接服务器
- 我们先查看crontab服务是否开启
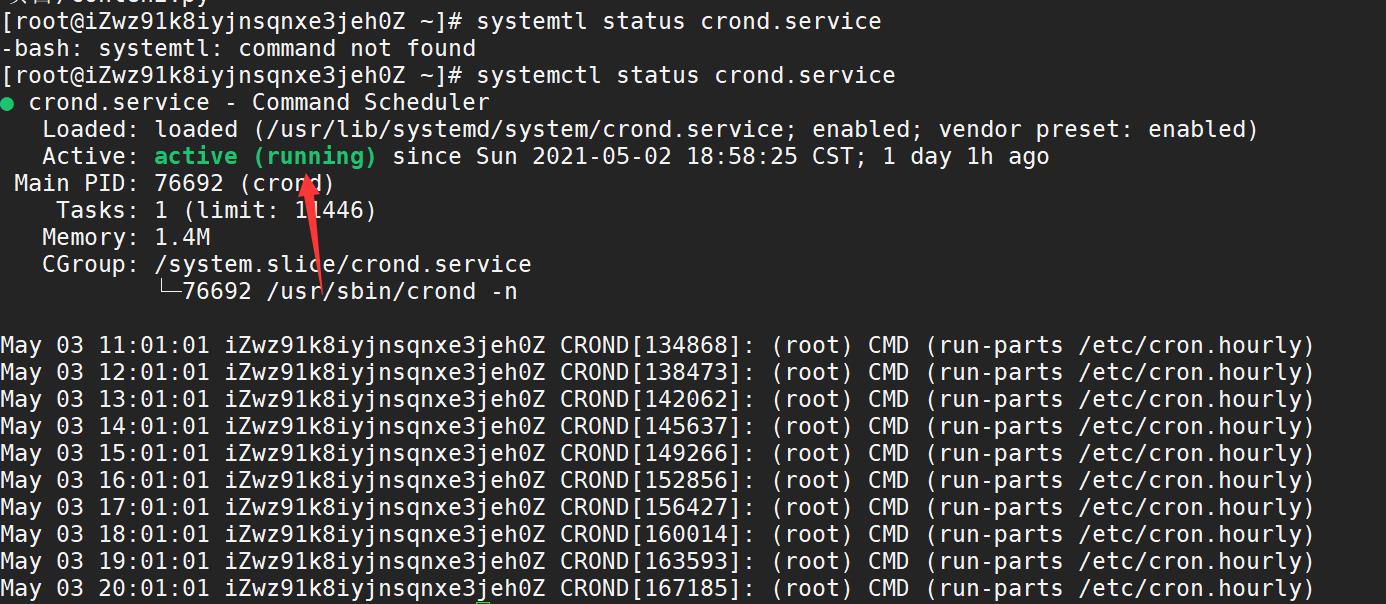
如果是active说明开启了否则需要start启动
- 调用文本编辑器对cron任务进行编辑
crontab -e
定时运行python爬虫文件的设置命令是这样的
分钟 小时 天数 月份 星期 python 运行文件名
由于我的项目已经在服务器上部署好了,项目运行是在虚拟环境下面的,所以我需要进入指定目录和环境
0 0 * * 7 cd /www/wwwroot/RecruitDataVsible-master1 && source ./ccccc_venv/bin/activate && python dataView/数据爬取/总的爬取项目/conten2.py
我这里的意思是每个星期天0点0分(就是晚上12点整)cd进入项目文件,source启动进入环境,使用python命令运行conten2.py这个文件
具体的修改查看命令可以看上面的文章
目前我的项目是这样子的,总共有九个类别的数据
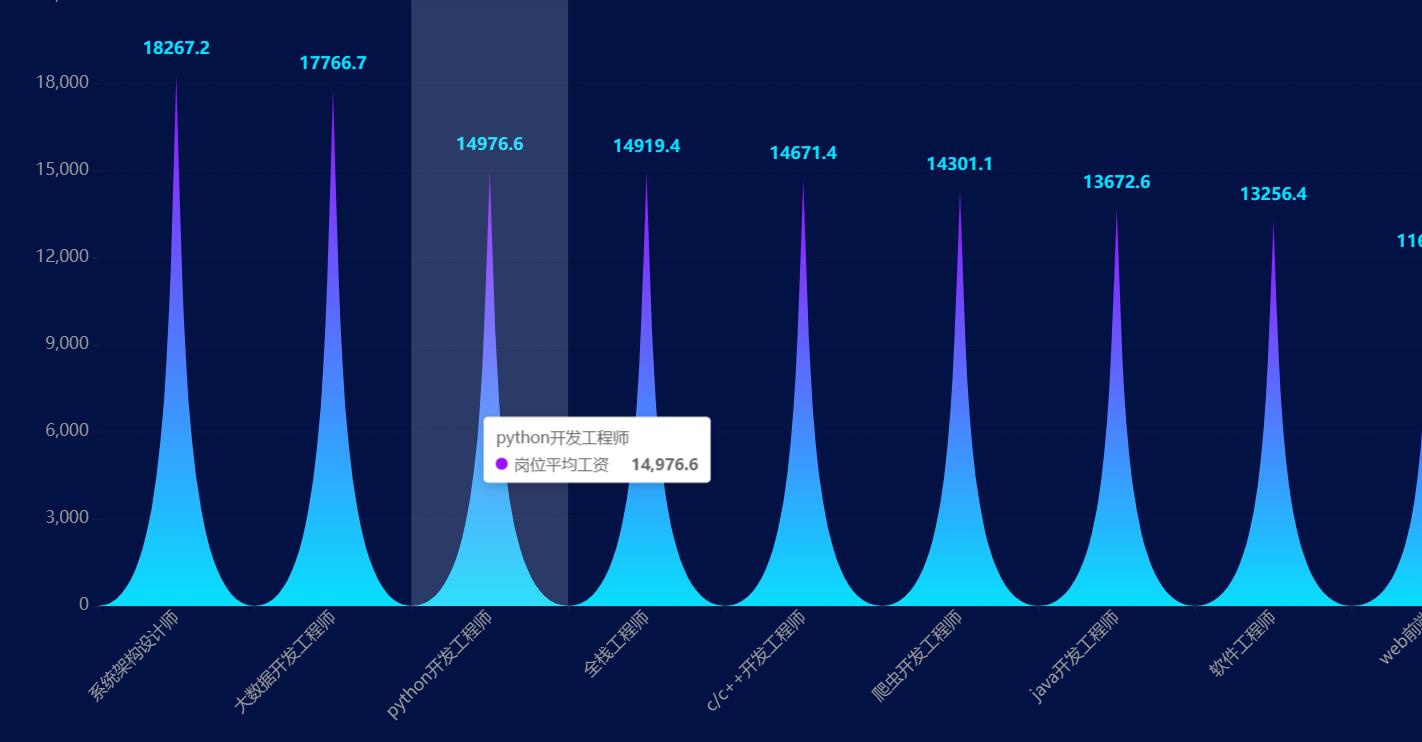
现在我们让它爬取两个类别,看看设定定时任务后能否自动爬取,然后存入数据库,自行展示

为了方便演示我这里设定了每分钟爬一次,’/'就是每的意思
*/1 * * * *

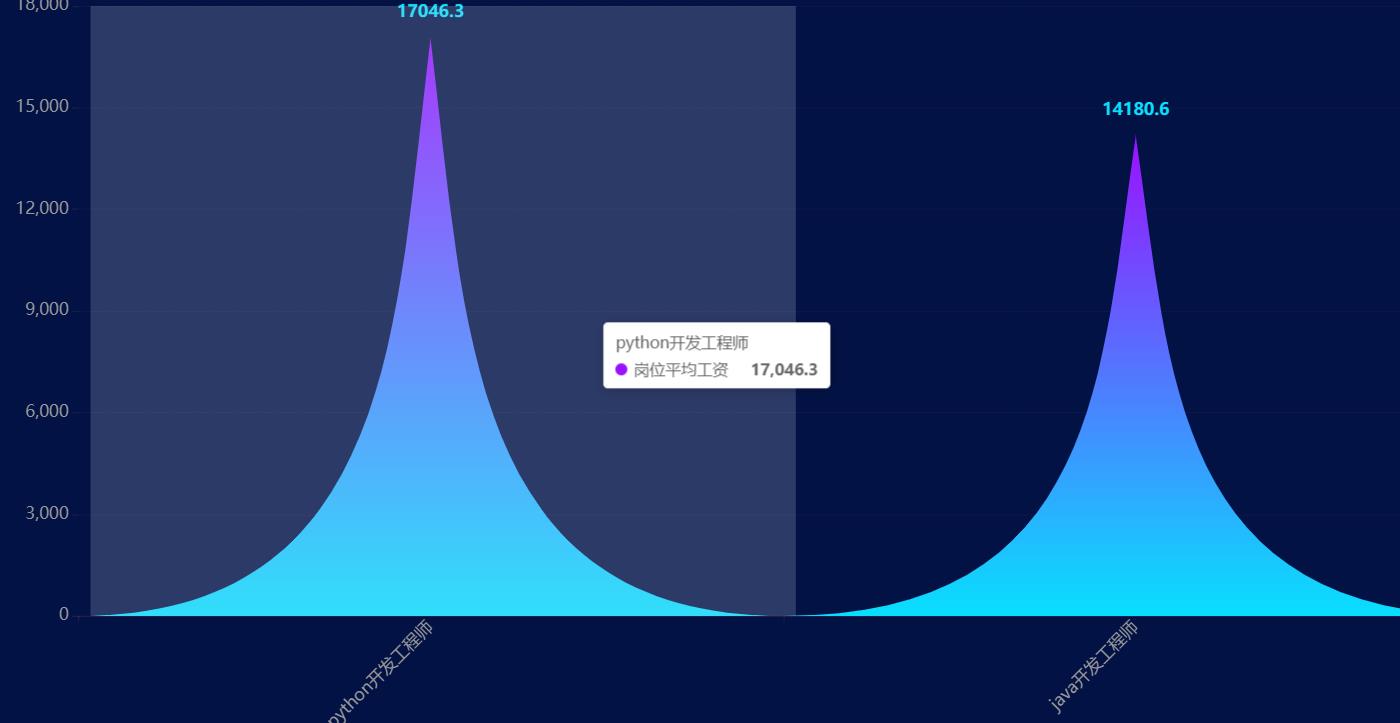
然后我们等一分钟,在我们没有做任何操作的情况下数据发生了改变,之前的数据被替换了,这就起到了定时爬取页面展示的效果
也可以手动运行代码
本人博客:https://blog.csdn.net/weixin_46654114
本人b站求关注:https://space.bilibili.com/391105864
转载说明:跟我说明,务必注明来源,附带本人博客连接。
请给我点个赞鼓励我吧

以上是关于阿里云服务器定时在线运行python爬虫代码的主要内容,如果未能解决你的问题,请参考以下文章
java sql 编辑器 数据库备份还原 quartz 定时任务调度 自定义表单 java 图片爬虫 集成代码生成器
java sql编辑器 数据库备份还原 quartz定时任务调度 自定义表单 java图片爬虫 java代码生成器
阿里云WindowsServer部署python scrapy爬虫