我现在有一套在网站上爬取数据的程序(用python写的)如何在服务器运行
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了我现在有一套在网站上爬取数据的程序(用python写的)如何在服务器运行相关的知识,希望对你有一定的参考价值。
我现在有一套在网站上爬取数据的程序(用python写的)分为脚本版和服务器版,我租用了一个阿里云的服务器,如何把这一套程序上传并且使之运行。急急急!
用xshell之类的软件连接到服务器上,然后用其带的比如xftp工具将代码传上去,在服务器上安装python之后再去跑代码就行了追问我是直接将文件从我的计算机复制到服务器的,但是服务器貌似搜索不了东西
参考技术A 首先要配置服务器的运行环境,如:nginx、PYTHON、mysql,然后用FTP工具把程序上传到服务器上运行。爬虫大作业
1.选一个自己感兴趣的主题(所有人不能雷同)。
因为不能雷同,所以就找了没人做的,找了一个小说网站。
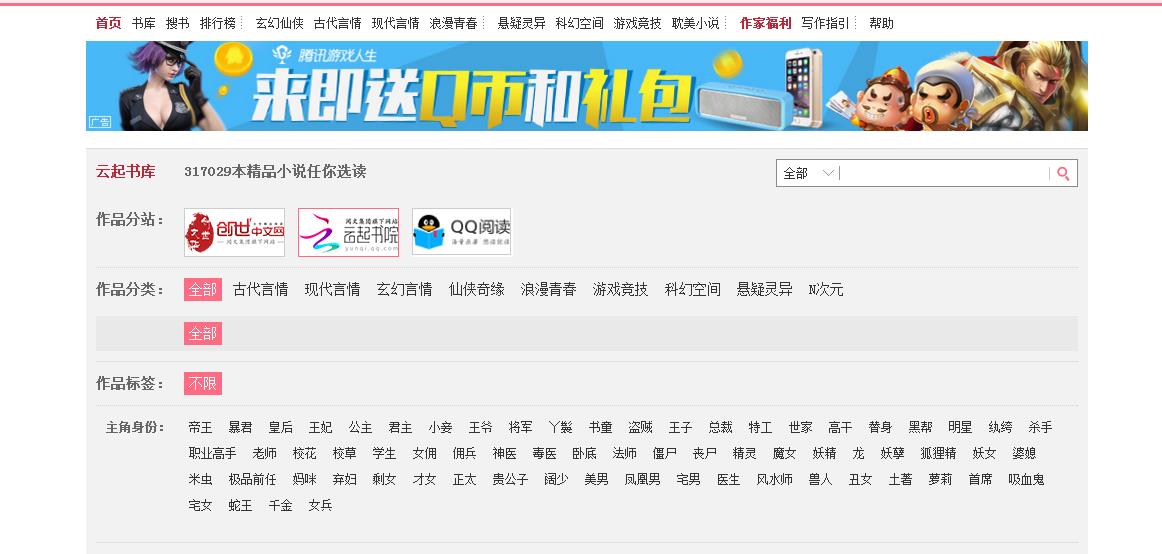
2.用python 编写爬虫程序,从网络上爬取相关主题的数据。
导入相关类
import requests from bs4 import BeautifulSoup import jieba
获取详细页面的标题和介绍
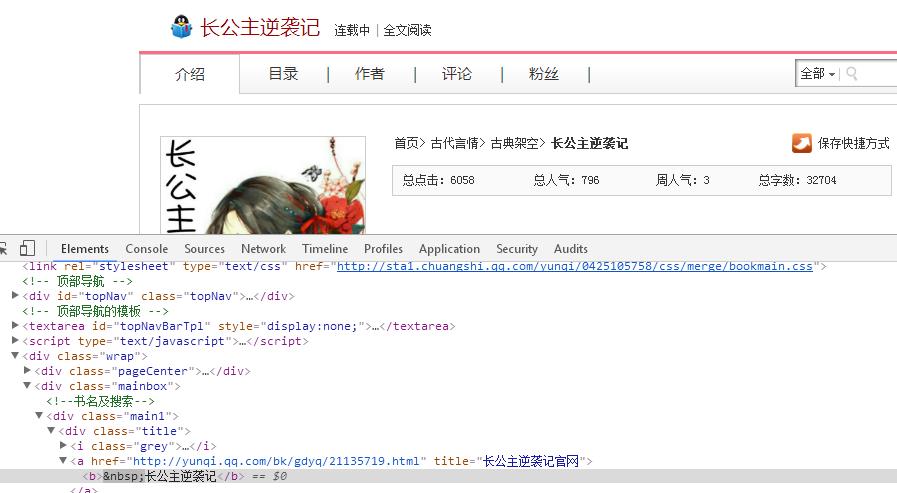
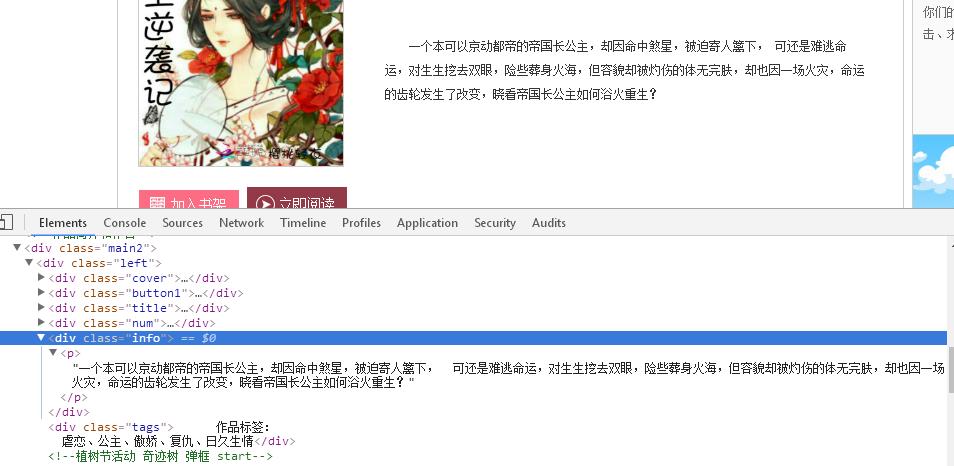
def getNewDetail(novelUrl): #获取详细页面方法
novelDetail = {}
res = requests.get(novelUrl)
res.encoding = \'utf-8\'
soup = BeautifulSoup(res.text, \'html.parser\')
novelDetail[\'title\'] = soup.select(".title")[0].select("a")[0].text #小说名
novelDetail[\'intro\'] = soup.select(".info")[0].text #小说介绍
num = soup.select(".num")[0].text #小说数量统计
novelDetail[\'hit\'] = num[num.find(\'总点击:\'):num.find(\'总人气:\')].lstrip(\'总点击:\') #总点击次数
# print(novelDetail[\'title\'])
return novelDetail
获取一个页面的所有列表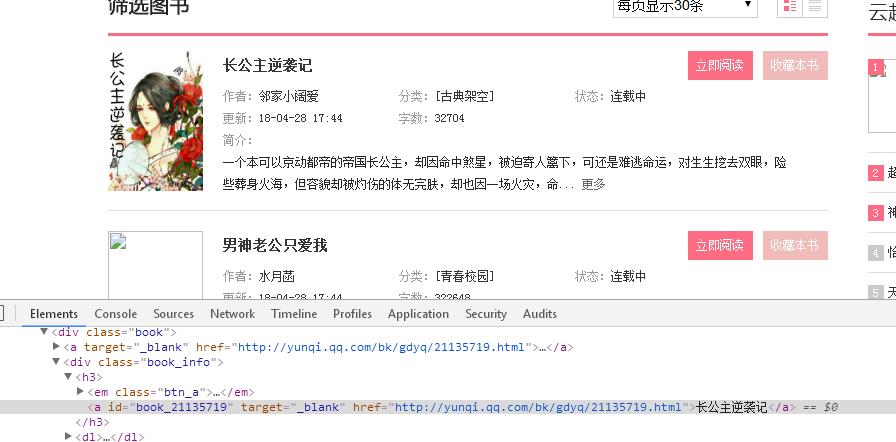
def getListPage(pageUrl): #获取一个页面的所有小说列表
novelList = []
res = requests.get(pageUrl)
res.encoding = \'utf-8\'
soup = BeautifulSoup(res.text, \'html.parser\')
for novel in soup.select(\'.book\'):
# if len(novel.select(\'.news-list-title\')) > 0:
novelUrl = novel.select(\'a\')[0].attrs[\'href\'] # URL
novelList.append(getNewDetail(novelUrl))
return novelList
计算网站的小说总数
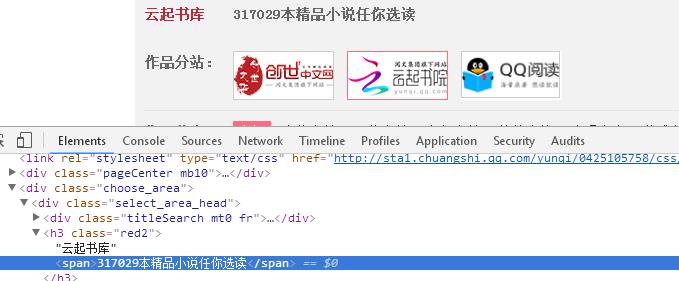
def getPageN(url): #计算网站的小说总数
res = requests.get(url)
res.encoding = \'utf-8\'
soup = BeautifulSoup(res.text, \'html.parser\')
num = soup.select(".red2")[2].text
n = int(num[num.find(\'云起书库\'):num.find(\'本\')].lstrip(\'云起书库\'))//30+1
return n
获取所有数据并分别写入TXT,title.txt和intro.txt
网站的第一页通常都是分开的网址,所以要分开爬数据



url = \'http://yunqi.qq.com/bk/so2/n30p\'
novelTotal = []
novelTotal.extend(getListPage(url))
n = getPageN(url)
for i in range(2, 3):
pageUrl = \'http://yunqi.qq.com/bk/so2/n30p{}.html\'.format(i)
novelTotal.extend(getListPage(pageUrl))
writeFile("title.txt",novelTotal,"title")
writeFile("intro.txt",novelTotal,"intro")
3.对爬了的数据进行文本分析,生成词云。
file=open(\'intro.txt\',\'r\',encoding=\'utf-8\')
text=file.read()
file.close()
p = {",","。",":","“","”","?"," ",";","!",":","*","、",")","的","她","了","他","是","\\n","我","你","不","人","也","】","…","啊","就","在","要","都","和","【","被","却","把","说","男","对","小","好","一个","着","有","吗","什么","上","又","还","自己","个","中","到","前","大"}
# for i in p:
# text = text.replace(i, " ")
t = list(jieba.cut_for_search(text))
count = {}
wl = (set(t) - p)
# print(wl)
for i in wl:
count[i] = t.count(i)
# print(count)
cl = list(count.items())
cl.sort(key=lambda x: x[1], reverse=True)
print(cl)
f = open(\'wordCount.txt\', \'a\',encoding="utf-8")
for i in range(20):
f.write(cl[i][0] + \'\' + str(cl[i][1]) + \'\\n\')
f.close()
from PIL import Image, ImageSequence
import numpy as np
import matplotlib.pyplot as plt
from wordcloud import WordCloud, ImageColorGenerator
font = r\'C:\\Windows\\Fonts\\simhei.TTF\' # 引入字体
# 读取背景图片
image = Image.open(\'./labixiaoxin.jpg\')
i = np.array(image)
wc = WordCloud(font_path=font, # 设置字体
background_color=\'White\',
mask=i, # 设置背景图片,背景是蜡笔小新
max_words=200)
wc.generate_from_frequencies(count)
image_color = ImageColorGenerator(i) # 绘制词云图
plt.imshow(wc)
plt.axis("off")
plt.show()


4.对文本分析结果进行解释说明。
由于是小说,所以当下小说见得多的都是一些仙侠或者言情小说,例如什么霸道总裁什么的,所以描述的都一般是男人女人的,由此也可见大家都小说的爱好偏向以及作者创作的类型,选对读者的兴趣的话就能更受欢迎
5.写一篇完整的博客,描述上述实现过程、遇到的问题及解决办法、数据分析思想及结论。
遇到的问题及解决方案
1.对网站的规律以及元素审阅的分析
一般是先有开发者工具审阅元素的class,有时候会有一些元素是不能直接获取的,这时候就需要用老师讲过的刷新查看网站发出的请求,通常一些元素是在script里显示的,
这时候就可以查看请求script得到网页不能直接获取的那些信息。
2.在导入wordcloud这个包的时候,会遇到很多问题
首先通过使用pip install wordcloud这个方法在全局进行包的下载,可是最后会报错误error: Microsoft Visual C++ 14.0 is required. Get it with “Microsoft Visual C++ Build Tools”: http://landinghub.visualstudio.com/visual-cpp-build-tools
这需要我们去下载VS2017中的工具包,但是网上说文件较大,所以放弃。
之后尝试去https://www.lfd.uci.edu/~gohlke/pythonlibs/#wordcloud下载whl文件,然后安装。
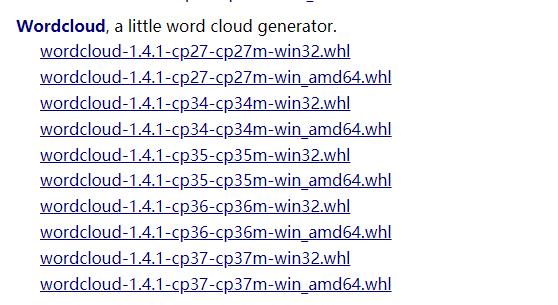
下载对应的python版本进行安装,如我的就下载wordcloud-1.4.1-cp36-cp36m-win32.whl,wordcloud-1.4.1-cp36-cp36m-win_amd64
两个文件都放到项目目录中,两种文件都尝试安装
通过cd到这个文件的目录中,通过pip install wordcloud-1.4.1-cp36-cp36m-win_amd64,进行导入
但是两个尝试后只有win32的能导入,64位的不支持,所以最后只能将下好的wordcloud放到项目lib中,在Pycharm中import wordcloud,最后成功
6.最后提交爬取的全部数据、爬虫及数据分析源代码。
以下是完整的代码
import requests
from bs4 import BeautifulSoup
import jieba
def getNewDetail(novelUrl): #获取详细页面方法
novelDetail = {}
res = requests.get(novelUrl)
res.encoding = \'utf-8\'
soup = BeautifulSoup(res.text, \'html.parser\')
novelDetail[\'title\'] = soup.select(".title")[0].select("a")[0].text #小说名
novelDetail[\'intro\'] = soup.select(".info")[0].text #小说介绍
num = soup.select(".num")[0].text #小说数量统计
novelDetail[\'hit\'] = num[num.find(\'总点击:\'):num.find(\'总人气:\')].lstrip(\'总点击:\') #总点击次数
# print(novelDetail[\'title\'])
return novelDetail
def getListPage(pageUrl): #获取一个页面的所有小说列表
novelList = []
res = requests.get(pageUrl)
res.encoding = \'utf-8\'
soup = BeautifulSoup(res.text, \'html.parser\')
for novel in soup.select(\'.book\'):
# if len(novel.select(\'.news-list-title\')) > 0:
novelUrl = novel.select(\'a\')[0].attrs[\'href\'] # URL
novelList.append(getNewDetail(novelUrl))
return novelList
def getPageN(url): #计算网站的小说总数
res = requests.get(url)
res.encoding = \'utf-8\'
soup = BeautifulSoup(res.text, \'html.parser\')
num = soup.select(".red2")[2].text
n = int(num[num.find(\'云起书库\'):num.find(\'本\')].lstrip(\'云起书库\'))//30+1
return n
def writeFile(file,novelTotal,key): #将数据写入txt
f = open(file, "a", encoding="utf-8")
for i in novelTotal:
f.write(str(i[key])+"\\n")
f.close()
# newsUrl = \'\'\'http://yunqi.qq.com/bk/so2/n30p\'\'\'
# getListPage(newsUrl)
url = \'http://yunqi.qq.com/bk/so2/n30p\'
novelTotal = []
novelTotal.extend(getListPage(url))
n = getPageN(url)
for i in range(2, 3):
pageUrl = \'http://yunqi.qq.com/bk/so2/n30p{}.html\'.format(i)
novelTotal.extend(getListPage(pageUrl))
writeFile("title.txt",novelTotal,"title")
writeFile("intro.txt",novelTotal,"intro")
file=open(\'intro.txt\',\'r\',encoding=\'utf-8\')
text=file.read()
file.close()
p = {",","。",":","“","”","?"," ",";","!",":","*","、",")","的","她","了","他","是","\\n","我","你","不","人","也","】","…","啊","就","在","要","都","和","【","被","却","把","说","男","对","小","好","一个","着","有","吗","什么","上","又","还","自己","个","中","到","前","大"}
# for i in p:
# text = text.replace(i, " ")
t = list(jieba.cut_for_search(text))
count = {}
wl = (set(t) - p)
# print(wl)
for i in wl:
count[i] = t.count(i)
# print(count)
cl = list(count.items())
cl.sort(key=lambda x: x[1], reverse=True)
print(cl)
f = open(\'wordCount.txt\', \'a\',encoding="utf-8")
for i in range(20):
f.write(cl[i][0] + \'\' + str(cl[i][1]) + \'\\n\')
f.close()
from PIL import Image, ImageSequence
import numpy as np
import matplotlib.pyplot as plt
from wordcloud import WordCloud, ImageColorGenerator
font = r\'C:\\Windows\\Fonts\\simhei.TTF\' # 引入字体
# 读取背景图片
image = Image.open(\'./labixiaoxin.jpg\')
i = np.array(image)
wc = WordCloud(font_path=font, # 设置字体
background_color=\'White\',
mask=i, # 设置背景图片,背景是树叶
max_words=200)
wc.generate_from_frequencies(count)
image_color = ImageColorGenerator(i) # 绘制词云图
plt.imshow(wc)
plt.axis("off")
plt.show()
以上是关于我现在有一套在网站上爬取数据的程序(用python写的)如何在服务器运行的主要内容,如果未能解决你的问题,请参考以下文章