2021 泰迪杯 C 题
Posted zhuo木鸟
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了2021 泰迪杯 C 题相关的知识,希望对你有一定的参考价值。
2021 泰迪杯数据+代码
谢绝互粉、互赞、互拍马屁。 那些一眼没看就乱吹的,请自觉绕道,本人**不会回粉**的。 本人是学生,请不要用抱团内卷的那一套影响我,谢谢。 有问题请在评论区留言。
如果本篇博文对您有所帮助,请不要吝啬您的点赞 ☺️
思路
https://blog.csdn.net/weixin_42141390/article/details/116422841
第一问
我理解的第一题,热词词云.xlsx 指的是每一个景区而言。以景区为例,A01 20 个热门词,A02 20 个热门词,等等。
所以,这里仅以景区中的 A01 为例,做出 A01 的词云。
条件随机场分词
首先,使用 SigHan05 的开源数据集 MSR 训练一个条件随机场分词模型,下面摘录 MSR 的部分语料库,如下所示:
“ 人们 常 说 生活 是 一 部 教科书 , 而 血 与 火 的 战争 更 是 不可多得 的 教科书 , 她 确实 是 名副其实 的 ‘ 我 的 大学 ’ 。
“ 心 静 渐 知 春 似 海 , 花 深 每 觉 影 生 香 。
“ 吃 屎 的 东西 , 连 一 捆 麦 也 铡 不 动 呀 ?
他 “ 严格要求 自己 , 从 一个 科举 出身 的 进士 成为 一个 伟大 的 民主主义 者 , 进而 成为 一 位 杰出 的 党外 共产主义 战士 , 献身 于 崇高 的 共产主义 事业 。
“ 征 而 未 用 的 耕地 和 有 收益 的 土地 , 不准 荒芜 。
“ 这 首先 是 个 民族 问题 , 民族 的 感情 问题 。
’ 我 扔 了 两颗 手榴弹 , 他 一下子 出 溜 下去 。
“ 废除 先前 存在 的 所有制 关系 , 并不是 共产主义 所 独具 的 特征 。
“ 这个 案子 从 始 至今 我们 都 没有 跟 法官 接触 过 , 也 没有 跟 原告 、 被告 接触 过 。
“ 你 只有 把 事情 做好 , 大伙 才 服 你 。
“ 那阵子 , 条件 虽 艰苦 , 可 大家 热情 高着 呢 , 什么 活 都 抢 着 干 , 谁 都 争 着 多 作 贡献 。
“ 哎呀 , 怎么 也 不 来 告诉 我 一 声 ?
“ 种菜 , 也 有 烦恼 , 那 是 累 的 时候 ; 另外 , 大 棚 菜 在 降价 。
并对附件“景区评论”中的每一天评论内容(仅以 A01 为例),进行分词。以第一条为例:
是亲子游的绝佳场所,门票就是有点贵,不过可以接受,爷爷奶奶不放心小朋友也跟上来了,当天我们十点多就到了,错过了节假日,人也还是多,不过错峰出行我们一天是把动物园逛完了,两种路线都逛完了,早上我们先坐的缆车,缆车人多,排了半小时队,小火车是把步行区转完了去坐的,到了下午四点半刚好小火车到站就下雨了,地铁站到男北门都有接驳车,很方便的,总之这次还算满意,就是有些动物表演没有看到,只看到了大象表演
进行分词后,可得:
[是, 亲子, 游, 的, 绝佳, 场所, ,, 门票, 就, 是, 有点, 贵, ,, 不过, 可以, 接受, ,, 爷爷, 奶奶, 不, 放心, 小朋友, 也, 跟, 上来, 了, ,, 当天, 我们, 十点, 多, 就, 到, 了, ,, 错过, 了, 节假日, ,, 人, 也, 还是, 多, ,, 不过, 错峰, 出行, 我们, 一天, 是, 把, 动物园, 逛, 完, 了, ,, 两种, 路线, 都, 逛, 完, 了, ,, 早上, 我们, 先, 坐, 的, 缆车, ,, 缆车, 人, 多, ,, 排, 了, 半小时, 队, ,, 小, 火车, 是, 把, 步行, 区, 转, 完, 了, 去, 坐, 的, ,, 到, 了, 下午四点半, 刚, 好, 小, 火车, 到站, 就, 下雨, 了, ,, 地铁, 站, 到, 男, 北门, 都, 有, 接驳, 车, ,, 很, 方便, 的, ,, 总之, 这次, 还, 算, 满意, ,, 就, 是, 有些, 动物, 表演, 没有, 看到, ,, 只, 看到, 了, 大象, 表演]
停用词过滤
因为,热门词不应该是 “我”、“你” 一些常见的代词,或者是“是”、“即便如此” 这样的意义不大的停用词。当然,也不能是“有点”、“一些” 这样的修饰副词,所以,这里将上述种种归为停用词,并添加到停用词字典中。
然后,用 DAT(双数组字典树)存储停用词词典,以双向匹配的方法,对分词中的所有停用词进行过滤,以第一条为例,过滤后可得:
[‘亲子’, ‘游’, ‘绝佳’, ‘场所’, ‘门票’, ‘贵’, ‘接受’, ‘爷爷’, ‘奶奶’, ‘放心’, ‘小朋友’, ‘上来’, ‘当天’, ‘十点’, ‘错过’, ‘节假日’, ‘错峰’, ‘出行’, ‘一天’, ‘动物园’, ‘逛’, ‘完’, ‘两种’, ‘路线’, ‘逛’, ‘完’, ‘早上’, ‘先’, ‘坐’, ‘缆车’, ‘缆车’, ‘排’, ‘半小时’, ‘队’, ‘火车’, ‘步行’, ‘区’, ‘转’, ‘完’, ‘坐’, ‘下午四点半’, ‘刚’, ‘火车’, ‘到站’, ‘下雨’, ‘地铁’, ‘站’, ‘北门’, ‘接驳’, ‘车’, ‘方便’, ‘算’, ‘满意’, ‘动物’, ‘表演’, ‘没有’, ‘看到’, ‘看到’, ‘大象’, ‘表演’]
停用词词典长这样:
一
不只
不外乎不若
不论
不过
不问
为着
乃
乃至
…
热词判断
何谓热词?
我觉得词分三种:
- 高频词:这可以由词频求出。但不一定是热词,比如“你”、“我” 这种,虽然它们大多被过滤,但不排除还有一些类似的,跟主题无关的词。
- 特色词:这可以由各条评论内容的 TF-IDF 求出,但特色词可能不具备高频词的特点,而且只能反映某条评论的中心内容。并且,若以 TF-IDF 来判断,反而会忽略主题词。比如评论以下棋为题,则下棋并非特色词。
- 关键词:关键词以信息量衡量。关键词通俗地解释,是指那些左右搭配较多的词,一般反映了某个文档的核心内容,是一个“概要”。
所以,综上,要作为热词,首先要成为关键词。然后,结合词频(高频词)和 TF-IDF(特色词),来判断一个词是否属于热词。
我的算法是这样的,若某词不属于关键词(可用 TextRank 算法,求每一个词的 BM25),则直接过滤。也即,将那些关键词提取出来,然后,计算热度:
h
=
T
F
+
T
F
−
I
D
F
h = TF + TF-IDF
h=TF+TF−IDF
再根据热度,提取出前 20 个热词即可,结果如下:
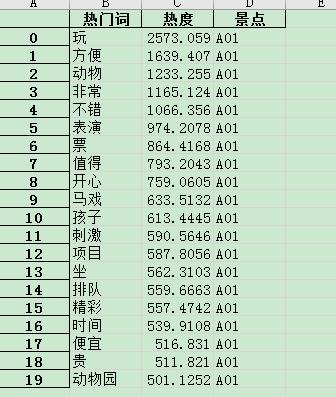
返回目录
第二问
第二问看起来更像是一个回归问题。我们可以将每一个要预测的评分单独领出来看,原理都是一样的。下面我们将用 总得分 为例,以景区评分和景区评论为例,(酒店应该能一样处理)。
数据预处理
首先,对于每一个景区,首先我们看一下下面的评论:
[‘是亲子游的绝佳场所,门票就是有点贵,不过可以接受,爷爷奶奶不放心小朋友也跟上来了,当天我们十点多就到了,错过了节假日,人也还是多,不过错峰出行我们一天是把动物园逛完了,两种路线都逛完了,早上我们先坐的缆车,缆车人多,排了半小时队,小火车是把步行区转完了去坐的,到了下午四点半刚好小火车到站就下雨了,地铁站到男北门都有接驳车,很方便的,总之这次还算满意,就是有些动物表演没有看到,只看到了大象表演’,
⋯ \\cdots ⋯
‘非常值得去,大人小孩都适合,超赞’,
‘玩了整整一天也没走完!很好玩!园区整个气氛都很好!剧场也很好看!自驾区不是很大 ,可以近距离接触动物但是不能跟它们互动,也是为他们的健康生存环境提供保障!感觉**的动物比别的动物园的要有生气。步行区每一个动物区会有工作人员讲解。很热情’,
‘大马戏确实精彩,小朋友看得津津有味!就是入场前排队够辛苦,1个多小时,就为了抢个靠前的位置。告诉大家座位怎么选择,进去得早一定要坐在靠近vip旁的座位区域,并且越靠近大过道越好,大过道是中场巡游队伍的必经之路,看点多,互动多!’,
…]
拼接成长文档
我们把上述多条评论,拼接长一个长文档。如下所示:
‘是亲子游的绝佳场所,门票就是有点贵,不过可以接受,爷爷奶奶不放心小朋友也跟上来了,当天我们十点多就到了,错过了节假日,人也还是多,不过错峰出行我们一天是把动物园逛完了,两种路线都逛完了,早上我们先坐的缆车,缆车 ⋯ \\cdots ⋯
⋯ \\cdots ⋯
⋯ \\cdots ⋯慢慢品尝。我们还参观了澳洲考拉园,一只只考拉胖乎乎的,安静地趴在树上,有的呆萌地看着我们,有的吃着它们最爱的食物——桉树叶,还有很多在呼呼大睡,考拉的一天中有16-20小时在睡觉中度过,以保存体力。在这里,我们看到了来自世界各地的动物,并和它们亲密接触,增长了许多新的知识,度过了丰富愉快的一天。 张通 2016.2.19’
二元语法模型
将上述长文档应用二元语法模型,可得:
‘是亲’, ‘亲子’, ‘子游’, ‘游的’, ‘的绝’, ‘绝佳’, ‘佳场’, ‘场所’, ‘所门’, ‘门票’ , ⋯ \\cdots ⋯,‘张通’, ‘通2016.2’, ‘2016.219’
TF-IDF 词袋模型
将二元语法处理后的,所有景区的评论,计算每一个 二元语法对 的 TF-IDF 值,最后将非结构化的文本变量,转换成结构化的矩阵(表格),维度为 50 × 52112 50\\times 52112 50×52112。
以第一条为例,转换为 TF-IDF 词袋模型如下:
第一条数据转为 TF-IDF 后的词袋向量 array([0.00116274, 0.00167242, 0.00095672, …, 0.00095672, 0.00116274,
0.00116274])
主成分分析
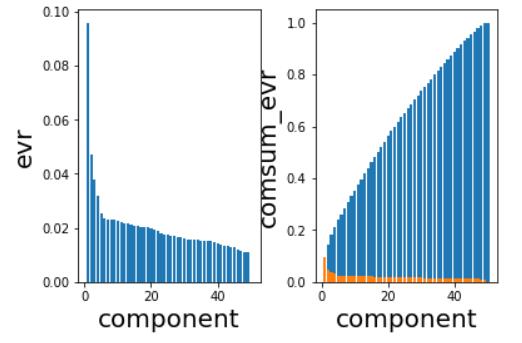
由于数据的列数很多,容易造成维度灾难,因此,我们需要将数据的特征进行过滤,而过滤的方法,就是主成分分析。
采用主成分分析,把数据的特征数量压缩到 50 个,并计算出每一个压缩后的 component 的 解释方差比例,可得,解释方差比例的累计和为 1,也即,这样的压缩,对数据的信息量的伤害为 0 。
如下图所示:
以 第一个景区为例, PCA 降维后,数据变成:
array([-1.68994101e-01, 3.26284120e-01, -2.03793613e-01, 5.89370914e-02, -9.35922161e-02, -2.51508576e-01, 3.78558675e-01, 7.05692275e-02, -4.16033273e-01, -1.81721112e-01, 4.20139548e-01, 2.84291262e-01, 3.37132250e-01, -2.28629811e-02, -5.94469206e-02, -1.67600090e-03, -7.70992057e-02, -3.87051901e-03, -3.28939425e-02, -3.73762031e-02, 9.71094914e-04, -2.04070515e-02, -2.32928290e-02, -6.36482369e-03, -6.32732889e-03, -3.73402358e-02, -3.66035380e-03, -1.83090879e-02, -1.13344678e-02, -2.88144971e-03, -2.00398235e-02, -1.26781652e-02, 3.37551560e-03, 3.55317514e-03, 4.00455734e-03, -4.53867966e-03, 1.40175621e-02, 1.23485020e-02, 1.34451975e-03, 2.15593117e-03, -8.77957890e-03, 4.91522134e-03, 6.37077315e-03, 2.62896402e-03, 1.00657005e-03, 3.01058968e-03, 3.34705357e-03, 4.93059973e-03, 2.21677774e-03, -1.92554306e-16])
标准化
对数据进行标准化,使得数据的均值为 0,方差为 1。
以第一景区为例,标准化后,数据变成:
array([-0.60297716, 1.66311881, -1.15430138, 0.36418058, -0.64906391,
-1.81890344, 2.74262484, 0.51301419, -3.03987708, -1.34141918,
3.1354722 , 2.12977549, 2.53656589, -0.1733286 , -0.45559222,
-0.01286204, -0.59721058, -0.03013938, -0.25660464, -0.29457977,
0.00770422, -0.16352289, -0.19238472, -0.05314515, -0.05307961,
-0.31636371, -0.03106931, -0.15651265, -0.09757317, -0.02511877,
-0.17593458, -0.1117227 , 0.0299099 , 0.03159465, 0.03567348,
-0.0406828 , 0.12582731, 0.11149707, 0.01227103, 0.02003915,
-0.08244402, 0.04673619, 0.06111316, 0.02539171, 0.00984843,
0.03048308, 0.03437755, 0.05178526, 0.02353909, -0.02830126])
回归模型建立
根据“天下没有免费午餐”定律,在选择一个特定的机器学习算法时,需要从大量的算法中筛选最佳的算法。
我们从下面这些算法中筛选最优算法:
| 算法 | 线性回归 | k近邻算法 | 支持向量机 | 决策树 | 随机森林 | AdaBoost |
|---|---|---|---|---|---|---|
| 符号 | lr | kNN | SVR | dtr | rf | ada |
其中随机森林的基模型是最大深度为 5 的决策树,AdaBoost 的基模型是线性回归。
最佳参数选择
不过要从上述算法中,筛选最佳算法,首先要筛选算法的最合适参数。筛选的方法是网格寻优法:
| 算法 | 参数网格 |
|---|---|
| lr | 无 |
| kNN | {‘n_neighbors’:[3,5,7,9,11,13,15]} |
| SVR | grid = { ‘C’:[0.1, 0.25, 0.5, 0.75, 1, 1.25, 1.5, 1.75, 2, 2.25, 2.5, 2.75, 3], ‘kernel’:[‘linear’,‘rbf’,‘poly’], ‘epsilon’:[0, 0.01, 0.05, 0.1] } |
| dtr | grid = {‘max_depth’:[4, 9, 13, 17, 21, 25], ‘ccp_alpha’:[0,0.00025,0.0005,0.001,0.00125,0.0015,0.002,0.005,0.01,0.05,0.1]} |
| rf | 基模型个数:4, 9, 13, 17, 21, 25 |
| ada | 基模型个数:5, 15, 25 |
结果如下:(给出原图啦,不然你们不信)

模型筛选
得到最佳参数之后,就可以筛选最佳的算法了。这里我们将所有的最佳参数,用交叉验证,对每一个算法,算出 10 组精确度和均值,结果如下:
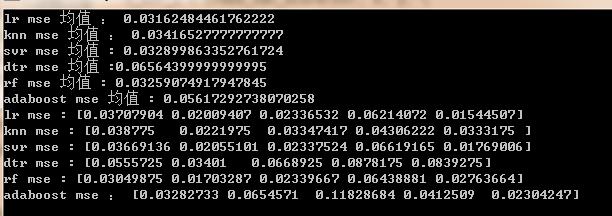
然后选最低的 线性回归模型就行咯。(不怕麻烦的话,也可以进行 T 检验)
应用与评价
将数据集按照 7:3 的比例拆分成训练集、测试集,在训练集上训练模型,在测试集上过测试模型,并分别计算 MSE:

第三问
有效性分析的问题,其实就是找出“重复”语句的问题。这里的重复不是语义上的重复,而是文字上的重复。有鉴于此,这里将采用聚类的方法解决。
这里的聚类,应该是以全部评论作为数据集进行评论。当然,个人觉得也可以以景区进行分组,后再聚类删除。鉴于后一种比较合理,所以本文将采用先分组,后聚类。
数据预处理
以 景区 A01为例:
首先为了实现聚类,就需要将非结构化的文本转换为结构化的表格。这里考虑先采用条件随机场对数据进行分词同上所述。
停用词过滤
词频词袋模型
我们计算所有评论构成的语料库中,每一个词,在每一条评论中出现的频次,从而将非结构化文本,转换为结构化的向量。
聚类
这里将采用 DBSCAN 聚类:
DBSCAN 的参数有: ϵ \\epsilon ϵ 用于决定“聚类圈”的直径,和 m i n s a m p l e s min_samples minsamples,用于决定聚类簇中包含的最小样品数。通过 DBSCAN 聚类,能够将那些单词词频和分布相近的特征聚合在一起。当然,DBSCAN 也会产生“游离个体”,而这些游离个体大概率是那些有效的评论。
不过,在聚类之前,需要筛选出一个聚类的最好参数:
聚类参数筛选
保持
m
i
n
s
a
m
p
l
e
s
=
2
min_samples=2
minsamples=2 不变,遍历
ϵ
=
[
0.1
,
0.2
,
⋯
,
2
]
\\epsilon=[0.1, 0.2 ,\\cdots, 2]
ϵ=[0.1,0.2,⋯,2]。观察每一次聚类后,聚类簇数和游离个体数,如下图所示:
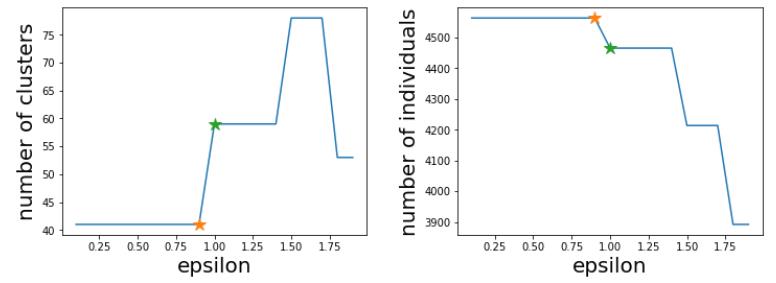
从上图看出,当 ϵ = 0.9 \\epsilon=0.9 ϵ=0.9 出现转折。我们先看 ϵ = 0.8 \\epsilon=0.8 ϵ=0.8 时的情况,首先找出聚类簇和簇下面的样品数,如下所示:
{0: 8, 1: 6, 2: 6, 3: 2, 4: 2, 5: 2, 6: 2, 7: 2, 8: 2, 9: 2, 10: 2, 11: 2, 12: 2, 13: 2, 14: 3, 15: 2, 16: 2, 17: 2, 18: 2, 19: 2, 20: 2, 21: 4, 22: 3, 23: 2, 24: 2, 25: 2, 26: 2, 27: 2, 28: 2, 29: 2, 30: 2, 31: 3, 32: 2, 33: 2, 34: 2, 35: 2, 36: 2, 37: 2, 38: 2, 39: 2, -1: 4564}
其中 -1 为游离个体。
我们找出聚类簇最多的簇,也即聚类簇 0 ,并输出样品内容,如下所示:
275 The Chimelong Happy World is worth a visit. Th…
282 The Chimelong Happy World is worth a visit. Th…
285 The Chimelong Happy World is worth a visit. Th…
289 The Chimelong Happy World is worth a visit. Th…
290 The Chimelong Happy World is worth a visit. Th…
293 The Chimelong Happy World is worth a visit. Th…
Name: 评论内容, dtype: object
可以看到,聚类效果还是相当好的,大致筛选出了无效的样品。
对于 ϵ = 0.9 \\epsilon=0.9 ϵ=0.9 的聚类,我们也同样处理,首先找出聚类簇和簇下面的样品数,如下所示:
{0: 2, 1: 56, 2: 6, 3: 6, 4: 2, 5: 2, 6: 3, 7: 2, 8: 2, 9: 2, 10: 2, 11: 2, 12: 2, 13: 2, 14: 2, 15: 2, 16: 2, 17: 2, 18: 15, 19: 2, 20: 2, 21: 2, 22: 2, 23: 2, 24: 2, 25: 2, 26: 2, 27: 3, 28: 3, 29: 2, 30: 2, 31: 2, 32: 2, 33: 2, 34: 2, 35: 2, 36: 2, 37: 4, 38: 2, 39: 2, 40: 2, 41: 2, 42: 2, 43: 2, 44: 2, 45: 2, 46: 2, 47: 2, 48: 2, 49: 2, 50: 3, 51: 2, 52: 2, 53: 2, 54: 2, 55: 2, 56: 2, 57: 2, -1: 4466}
我们找出聚类簇最多的簇,也即聚类簇 1 ,并输出样品内容,如下所示:
120 可以可以可以可以可以可以可以可以可以可以可以,可以可以可以可以可以可以可以可以可以可以可以可…
233 好好好好,确实不错,方便!
295 很好很好很好很好很好很好很好很好很好
336 总的来说还不错,取票挺方便!
352 人多多多多多多多多多
521 好好好好好好好好好好好好好好好好好好好好!
523 好好,很好,很好,很好,很好,很好
533 哈哈哈哈哈哈过哈哈哈哈哈哈哈哈哈
614 便宜了不少,很给力了,取票方便,
619 太好玩了,值得一去!!!!!!
621 好好好好好好好好好好好好好好好好
664 价格便宜,取票方便,挺靠谱的!
671 我们玩的很好大家很高兴
689 kehaolebuchuojiumenpiaoyoudiangui
788 价格便宜,取票方便,很棒!
975 可以,很方便,点赞。。。很好。。。
1225 取票很方便,价格便宜,靠谱
1290 精彩绝伦,美轮美奂!
1616 很好,很好,很好,很好,。。。。。。。。。。。。
1966 取票方便,快捷,服务好
1984 不错,很精彩,很刺激
2072 取票方便,服务好。便宜
2086 取票方便,服务号,总体不错!
2532 很好玩,同时有很多的回忆
2582 好好好好好好好好好好好好好好好好
2616 The monkey is cute
2767 还不错,取票超级方便。
2943 还可以吧……也不是很恐怖
3086 很方便很好,而且去的时候也没什么人
3148 很好看。。不错,很刺激
3262 还不错,就是品种不是很多,
3306 很方便!!!!!!!!
3410 取票方便,价格便宜,非常好。
3449 不错啊!很好很好很好很好很好很好
3485 玩的不是很多,一般般!
3501 动物园很好玩!值得一去!
3596 值得来,可以玩一整天
3832 嗨皮,激动人心,,,,。。。。。。
3843 又便宜,取票又方便,服务很好
3861 取票很方便,价格也便宜
3866 取票方便快捷,而且便宜
3894 第二次看了,还是一样精彩
3925 取票很方便,又便宜。
3951 方便,不错,好好好好
3957 不错啊,取票方便服务好
3976 取票方便、价格便宜,服务好!
4025 很好玩,可以去去大家
4173 不错,挺方便的!!!!!!!!!!!!!
4225 可以,经常去!!!!!
4234 都很方便,就是人太多了。
4288 好刺激啊!有很多好多的。
4335 好,取票很方便,还能便宜一点
4366 价格比景点便宜,取票也很方便!
4485 不错,玩的还可以,!
4512 好的好的好的好的好的好的好的
4635 取票方便、 价格便宜,
我们也可以看类别第二多的那些评语长什么样:
916 取票很方便,小孩子玩的很开心
2453 玩得很好,取票方便,該省錢!
2535 孩子玩的很开心,取票很方便。
2785 很好玩,跟刺激,取票很方便!
2896 很刺激很好玩,取票也很方便
3686 取票方便很好玩挺值的
3719 超级好玩!取票方便快捷。很满意
4026 很好玩,小朋友很开心,取票很方便,
4099 很好玩啊 而且去那取票也很方便
4167 取票很方便,玩得很开心
4214 取票很方便,可玩项目很多很刺激
4326 很好玩,取票很方便…………
4339 很好玩,很刺激,取票也很方便
4377 取票方便,孩子们玩的很开心。
4538 取票很方便,玩得很开心
第三多的长什么样?
275 The Chimelong Happy World is worth a visit. Th…
282 The Chimelong Happy World is worth a visit. Th…
285 The Chimelong Happy World is worth a visit. Th…
289 The Chimelong Happy World is worth a visit. Th…
290 The Chimelong Happy World is worth a visit. Th…
293 The Chimelong Happy World is worth a visit. Th…
Name: 评论内容, dtype: object
可以看到, ϵ = 0.9 \\epsilon=0.9 ϵ=0.9 比 ϵ = 0.8 \\epsilon=0.8 ϵ=0.8 的效果更好,但误分类比较多。再来看看一些冷门的聚类簇,比如 44,内容如下:
3380 玩的项目还是比较多,比较刺激,就是最近天气太热
3381 玩的项目还是比较多,比较刺激,就是最近天气太热
还有其他:
3336 不错哦。玩得很开心,出票也很快
4451 很好,出票很快,玩得很开心
3280 **真心不错,值得一玩!
4194 **很不错,值得玩一趟!
因此,最终敲定 ϵ = 0.9 \\epsilon=0.9 ϵ=0.9,作为聚类参数。
输出结果
使用 m i n s a m p l e s = 2 , ϵ = 0.9 min_samples=2, \\epsilon=0.9 minsamples=2,ϵ=0.9 对数据进行聚类,最后从聚类簇中筛选一条最常的保留,其余删除。对于游离数据,则完全保留,即可得出结果。如下所示(仅以景区 1 为例):
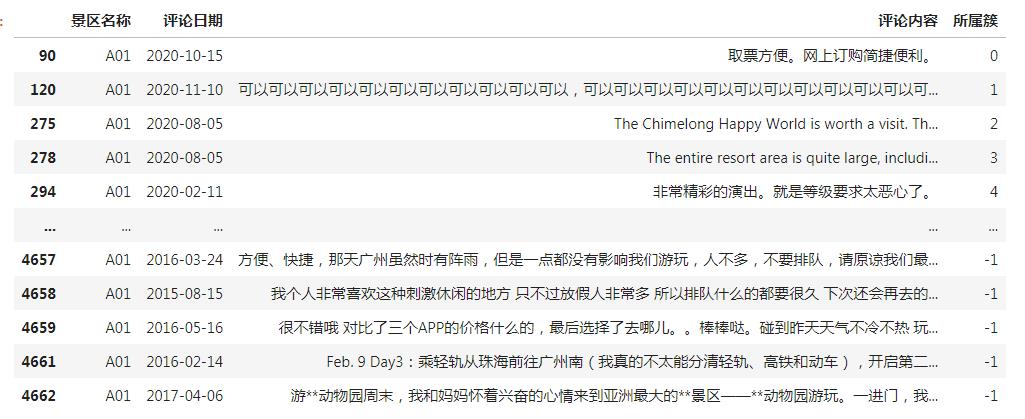
为什么要保留一条呢?因为一些刷评,不是恶意的。有可能是因为评论审核的缘故,导致无法马上出现在评论区。但客户没有看到评论区马上出现评论的情况下,就会重复发送。所以,对于这些类似刷评的东西,不能一概打死,还是要保留一条。
第四问
我理解的问题四是,首先根据综合评分,挑出层次为 高、中、低的景区,再用 NLP 的方法提取出景区的特色。
(这里仅以景区为例)
三个层次
如何挑出高、中、低三个景区呢?我们以景区评分中的 总得分 的上四分位数、中位数、下四分位数对应的景区,作为代表高、中、低三个景区。
又或者,将 总得分 落在 IQR 以内的所有景区,作为层次中景区的代表。其余两端分别作为 高层次、低层次的代表。
其中,低层次的景区有:
[‘A02’, ‘A03’, ‘A04’, ‘A05’, ‘A08’, ‘A10’, ‘A11’, ‘A19’, ‘A24’, ‘A27’, ‘A31’, ‘A41’, ‘A43’]
中层次的景区有:
[‘A01’, ‘A06’, ‘A07’, ‘A09’, ‘A12’, ‘A13’, ‘A14’, ‘A15’, ‘A16’, ‘A17’, ‘A18’, ‘A20’, ‘A22’, ‘A25’, ‘A26’, ‘A28’, ‘A29’, ‘A30’, ‘A32’, ‘A33’, ‘A34’, ‘A42’, ‘A46’, ‘A47’]
高层次的景区有:
[‘A21’, ‘A23’, ‘A35’, ‘A36’, ‘A37’, ‘A38’, ‘A39’, ‘A40’, ‘A44’, ‘A45’, ‘A48’, ‘A49’, ‘A50’]
为了处理方便,这里仅从上述景区中,随机(不重复地)筛选其中 10% 的景区,作为代表景区。
挑选特色
数据预处理
长文档
首先对每一个层次,对下面的所有景区中的所有评论,拼接成一个长文档,从而得到高、中、低三个长文档。以高层次为例,得到的长文档如下:
景区挺干净的,卫生间新建的,很不错。就是门票偏贵,还要交10块钱停车费徒步上去,累的大半死,不过山上的风景很美人太多,泡温泉时每个池都很多人。热矿床上躺着的人横七竖八,应该加以管理。服务区茶水提供充足…!!!!!!!!里面很大有坐观音望海,风景好靓!有很多景色点。不是,因为我是本地人才推荐这个地方。去的地方虽然不是很多,相比之下那些上百几十块钱门票的著名景点,这个**公园很值得去。我门票才十几块钱
当然,也可以结合第三问,将无效评语删除。
关键句提取
根据 BM25 + TextRank 算法,从每一个长文档中,提取 100 条关键句。以高层次为例:
[‘值得推荐哦风景不错’,
‘挺方便的环境还有空气都不错’,
‘还是挺方便的不错的景点’,
‘个人觉得门票有点贵了……非常值得去的景区’,
‘这里的景色很美环境不错’,
‘景区里不错’,
‘真的不错很好’,
⋯ \\cdots ⋯
‘空气很好揭西著名景区’,
‘但其实值得看的地方不是很多’,
‘值得去中国文化园林风格便宜又实惠去中山**’,
‘性价比超高不错’,
‘去到景区直接可拿票’,
‘里面的绿色环境也很好’,
‘不过晚上的风景更加不错’,
‘一个值得去待上一段时间的地方’,
‘很不错’,
‘回酒店也非常值得去’,
‘非常值得观赏’,
‘景点领票超方便’,
‘确实是一个不错的选择’,
‘很好玩’]
热门词提取与结果分析
根据第一问地方法,找出每一个层次的关键句中的前 20 个热门词。
首先是高端层次,热门词有:
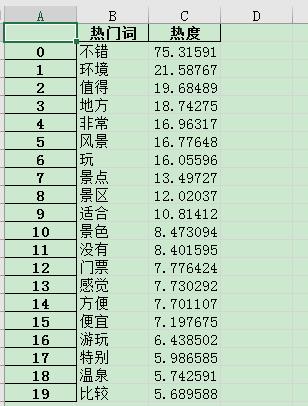
所以大致可以得出:高端景区的特色是便宜、风景好、通行方便,玩的地方比较多,并且有温泉之类的特色景点和服务。
然后是中端景点:
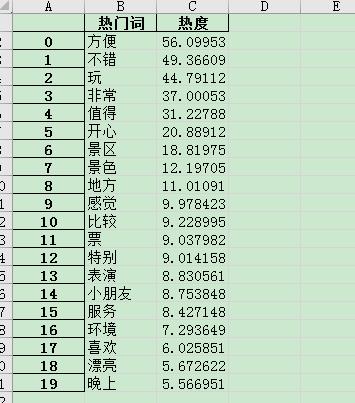 中端景点的特色是方便,服务好,风景漂亮,且在晚上时景点更加优美。
中端景点的特色是方便,服务好,风景漂亮,且在晚上时景点更加优美。
然后是低端景区:
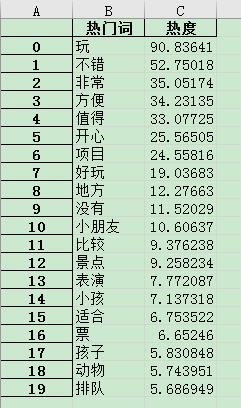
可以总结出,低层次的景区一般适合低龄化人群,比如小孩、小朋友、孩子,并且会有一些动物可供观赏,有一些娱乐设备。但缺点在于需要排队,买票不方便。
至此,泰迪杯 2021 C 题就结束啦
提高
由于时间原因,这里所说的都不会实现,但具有很大的参考意义,并且可实现性也比较多。
第一题
首先,对于第一题,首先我们需要先去掉无效的数据,换句话说,我们需要先做第三问,再做第一问。
之后,热度也与时间有关。我们可以制定一个函数,让每一条评论的热度计算,随着时间会出现衰退。而衰退的幅值,可以根据最近时间、最远时间,以及最大热度,最小热度统计出来。
第二题
除了回归模型之外,还可以使用深度学习模型。
第二,数据预处理方面,主成分分析也可以考虑使用其他方法,多多尝试,比如用递归删除特征等等。
此外,二元语法将非结构化文本,化为结构化数据,也不是唯一的。可以用分词的方法,或者更高级的,词向量的方法来解决。
第三题
多尝试其他聚类方法,也可以用深度学习来聚类,比如自动编码器。
第二,停用词过滤是否有必要,是一个问题。
第四题
词向量是否有插足的余地?并且(时间缘故,我没有先做第三问后做第四问啦…)。
第二,就是特色从热门词中提取,是否合适?直接从关键句中提取不行吗?
代码
关注+私信+说明清楚
如果本篇博文对您有所帮助,请不要吝啬您的点赞 ☺️
以上是关于2021 泰迪杯 C 题的主要内容,如果未能解决你的问题,请参考以下文章