2023年第十一届泰迪杯数据挖掘挑战赛C题:泰迪内推平台招聘与求职双向推荐系统构建 建模及python代码详解 问题一
Posted Better Bench
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了2023年第十一届泰迪杯数据挖掘挑战赛C题:泰迪内推平台招聘与求职双向推荐系统构建 建模及python代码详解 问题一相关的知识,希望对你有一定的参考价值。

相关链接
【2023年第十一届泰迪杯数据挖掘挑战赛】C题泰迪内推平台招聘与求职双向推荐系统构建 建模及python代码详解 问题一
【2023年第十一届泰迪杯数据挖掘挑战赛】C题泰迪内推平台招聘与求职双向推荐系统构建 建模及python代码详解 问题二
【2023年第十一届泰迪杯数据挖掘挑战赛】C题泰迪内推平台招聘与求职双向推荐系统构建 建模及python代码详解 问题三
【2023年第十一届泰迪杯数据挖掘挑战赛】C题泰迪内推平台招聘与求职双向推荐系统构建 建模及python代码详解 问题四
1 题目
一、问题背景
在新时代背景下,随着大学生毕业人数不断增加,大学生求职问题已成为广泛关注的社 会热点。而且受疫情影响,诸多企业的招聘都改为线上进行,脱离时间和空间的限制,招聘 需求不断上涨,有近六成企业招聘需求增加,其中需求量较大的科技研发、数字化、蓝领技 能岗位都存在不同程度的人才短缺。但从人才供给来看,应届生数量增加,2022 年高校毕 业生达到创纪录的 1076 万人,而且部分企业校招开展暂缓或推迟,因此出现校招需求缩减 或冻结,这些因素都加剧了应届生就业的严峻形势。基于种种因素,出现就业竞争压力大、 招聘与求职信息不对称等现象。
泰迪内推平台是聚焦于“大数据+”和“人工智能“领域的求职招聘网站,该平台融合了多家企业发布的招聘信息,同时平台也为求职者提供求职信息的展示。为缓解毕业生就业 压力,同时满足企业对人才的需求,泰迪内推平台会定期为高校学生提供优质岗位推荐,解 决毕业生就业的同时也缓解企业用人难的问题,为校企之间搭建起资源互换的桥梁,力求实 现人才的供需对接和教育资源转化,通过深化产教融合,促进教育链、人才链、产业链与创 新链有机衔接。
因此,对招聘信息进行分析研究,了解不同职业领域的需求特点,挖掘兴起的数据类行 业相应的人才需求现状及发展趋势,为广大求职者提供正确的就业指导有着重要意义。
二、解决问题
1.招聘信息爬取
从泰迪内推平台(https://www.5iai.com/#/index)的“找工作“页面和“找人才”页面,爬取所有招聘与求职信息并整理,依据招聘信息ID记录每条招聘信息并保存为“result1 - 1.csv”文件,求职信息则依据求职者ID记录并保存为“result1-2.csv”文件,涉及的招聘信息ID和求职者ID均来自网址路径后端的数字串,如图1所示。(模板文件见附件1中的CSV文件)

图1 某招聘信息网页
2.招聘与求职信息分析
应用问题 1 的招聘信息与求职信息构建画像:根据采集的企业招聘信息,从招聘岗位、 学历要求、岗位需求量、公司类型、薪资待遇、岗位技能、企业工作地点等多个方向建立招 聘信息画像;根据采集求职者求职信息,从预期岗位、薪资需求、知识储备、学历、工作经 验等多个方向建立求职者画像。
3.构建岗位匹配度和求职者满意度的模型
在招聘和求职过程中,企业面对多位优质求职者,将会考虑求职者能力要求、技能掌握 等多方面,岗位匹配度是体现求职者满足企业招聘要求的匹配程度;同样,求职者对于多种 招聘信息,也会依据自身条件和要求,选取符合自己心意的岗位,因此求职者满意度指标可 客观体现求职者对企业招聘岗位的满意程度。对于不满足岗位最低要求的求职者,企业可定 义其岗位匹配度为 0。同样,对于不满足求职者最低要求的岗位,求职者可定义其求职者满 意度为 0。
根据问题2的招聘信息与求职者信息,构建岗位匹配度和求职者满意度的模型,基于该模型,为每条招聘信息提供岗位匹配度非0的求职者,将结果进行降序排序存放在“resul3 - 1. csv”文件中,以及为每位求职者提供求职者满意度非0的招聘信息,将结果进行降序排序存放在“result3 - 2. csv”文件中。(模板文件见附件1中的CSV文件)
4.招聘求职双向推荐模型
假设招聘流程如下:设某岗位拟聘人,泰迪内推平台向企业推荐岗位匹配度非0的n位求职者发出第一轮报价,求职者如果收到多于1个岗位的报价,则求职者选取满意度最高的岗位签约,每个求职者只允许选择1个岗位签了约。第一轮结束后,平台根据当前各招聘信息的剩余岗位数,向后续被推荐求职者发出第二轮报价,如此继续,直到招聘人数已满或者向所有拟推荐求职者均已发出提供为止。
在上述招聘流程中,由于条件优秀的岗位求职者都愿意去,而条件优秀的求职者各岗位 都愿意录用,很难做到履约率达到百分之百,因此履约率高低是评价平台的推荐系统优劣的 重要指标。这里的履约率定义为:
履约率=所有岗位的签约人数之和/所有拟聘岗位人数之和
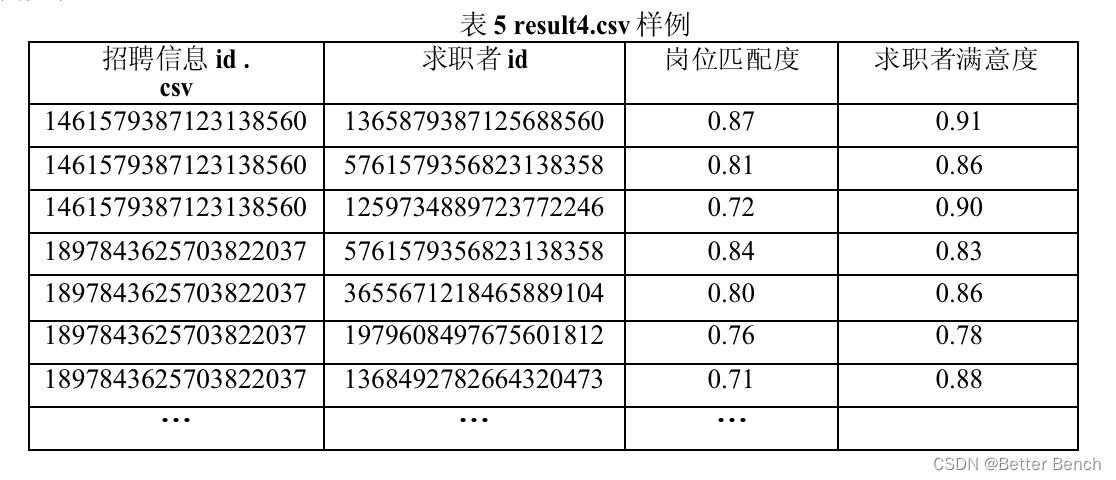
请为平台设计招聘求职双向推荐模型,使得履约率指标达到最高。并将招聘岗位与求职者签约成功的结果存放在“resul4.csv”文件中。
三、附件说明
附件1是问题1,问题3和问题4的模板文件,文件均为csv文件,采用ANSI编码。Result1-1.csv:从泰迪内推平台爬取的招聘信息,文件参考表1格式。
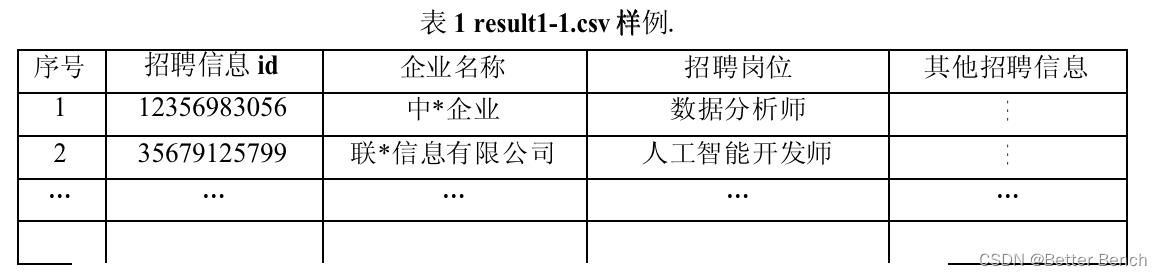
Result1-2.csv:从泰迪内推平台爬取的求职信息,文件参考表2格式。表2 result1-2.csv样例.

result3 - 1. - csv:该文档存储每条招聘信息中岗位匹配度非0的求职者,需将结果进行降序排序,具体字段名和样例见表3。
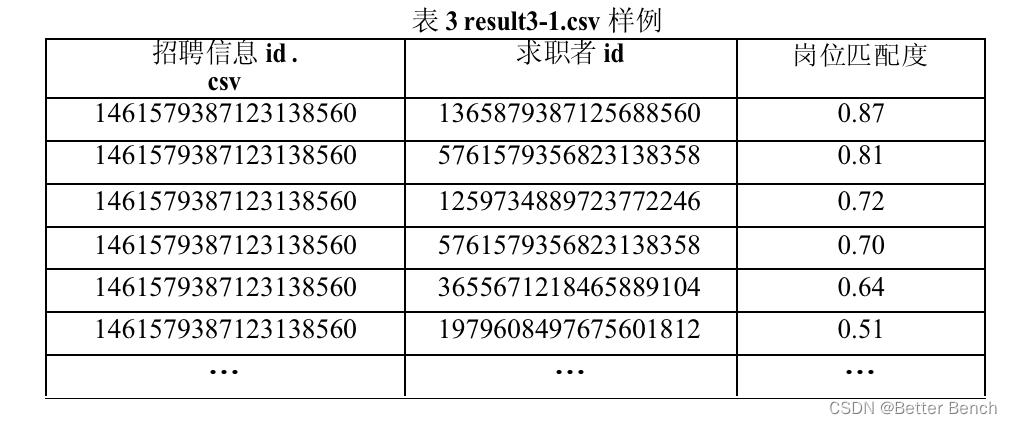
result3 - 2. - csv:该文档存储每位求职者满意度非0的招聘信息,需将结果进行降序排序,具体字段名和样例见表4。
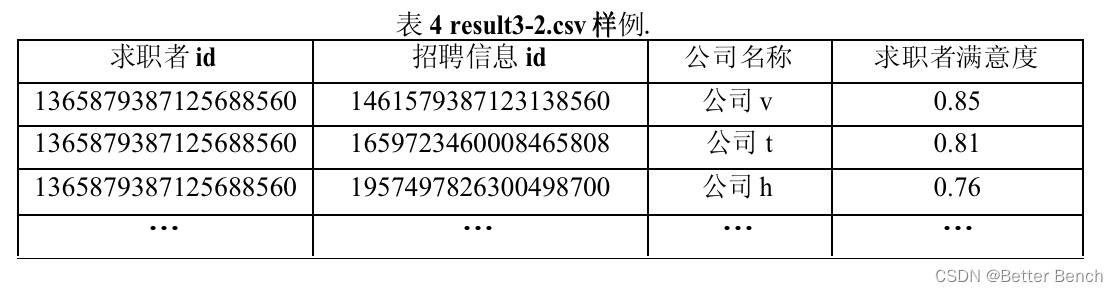
result4.csv:根据履约率最高的模型,提供招聘岗位签约成功后的求职者ID。该结果需对招聘信息ID进行排序,并对每个招聘信息的数据按岗位匹配度降序排序,具体字段名和样例见表5。
2 问题一思路分析及python代码实现
(1)爬取招聘信息
import requests
import pandas as pd
import json
data = []
headers =
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (Khtml, like Gecko) Chrome/111.0.0.0 Safari/537.36'
def print_hi(page):
。。。略,请下载完整代码
response = requests.get(url, headers=headers)
html = json.loads(response.text)
for i in html["data"]["content"]:
item = '招聘信息id': i["id"], '公司地址': i["enterpriseAddress"]["detailedAddress"].replace('\\xa0', ''),
'招聘岗位': i["positionName"], '公司类型': i["enterpriseExtInfo"]["personScope"],
'最低薪资': i["minimumWage"], '最高薪资': i["maximumWage"],
'员工数量': i["enterpriseExtInfo"]["econKind"], '学历': i["educationalRequirements"],
'岗位经验': i["exp"], '企业名称': i["enterpriseExtInfo"]["shortName"],
'企业类型': i["enterpriseExtInfo"]["industry"]
print(item)
data.append(item)
def main():
for j in range(1, 159):
print_hi(page=j)
df = pd.DataFrame(data)
。。。略
# 按间距中的绿色按钮以运行脚本。
if __name__ == '__main__':
main()
(2)爬取人才信息
import requests
import pandas as pd
import json
data = []
headers =
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/111.0.0.0 Safari/537.36'
def print_hi(page):
。。。略,请下载完整代码
response = requests.get(url, headers=headers)
html = json.loads(response.text)
for i in html["data"]["content"]:
item = '求职者id': i["id"], '姓名': i["username"],
'预期岗位': i["expectPosition"], '预期最低薪资': i["willSalaryStart"],
'预期最高薪资': i["willSalaryEnd"],
'地区': i["city"]
ite = []
for j in i["keywordList"]:
ite.append(j['labelName'])
item['技能'] = ite
print(item)
data.append(item)
def main():
for j in range(1, 1093):
print_hi(page=j)
df = pd.DataFrame(data)
。。。略
# 按间距中的绿色按钮以运行脚本。
if __name__ == '__main__':
main()
3 下载后的数据及代码

(1)招聘信息
有1575个样本
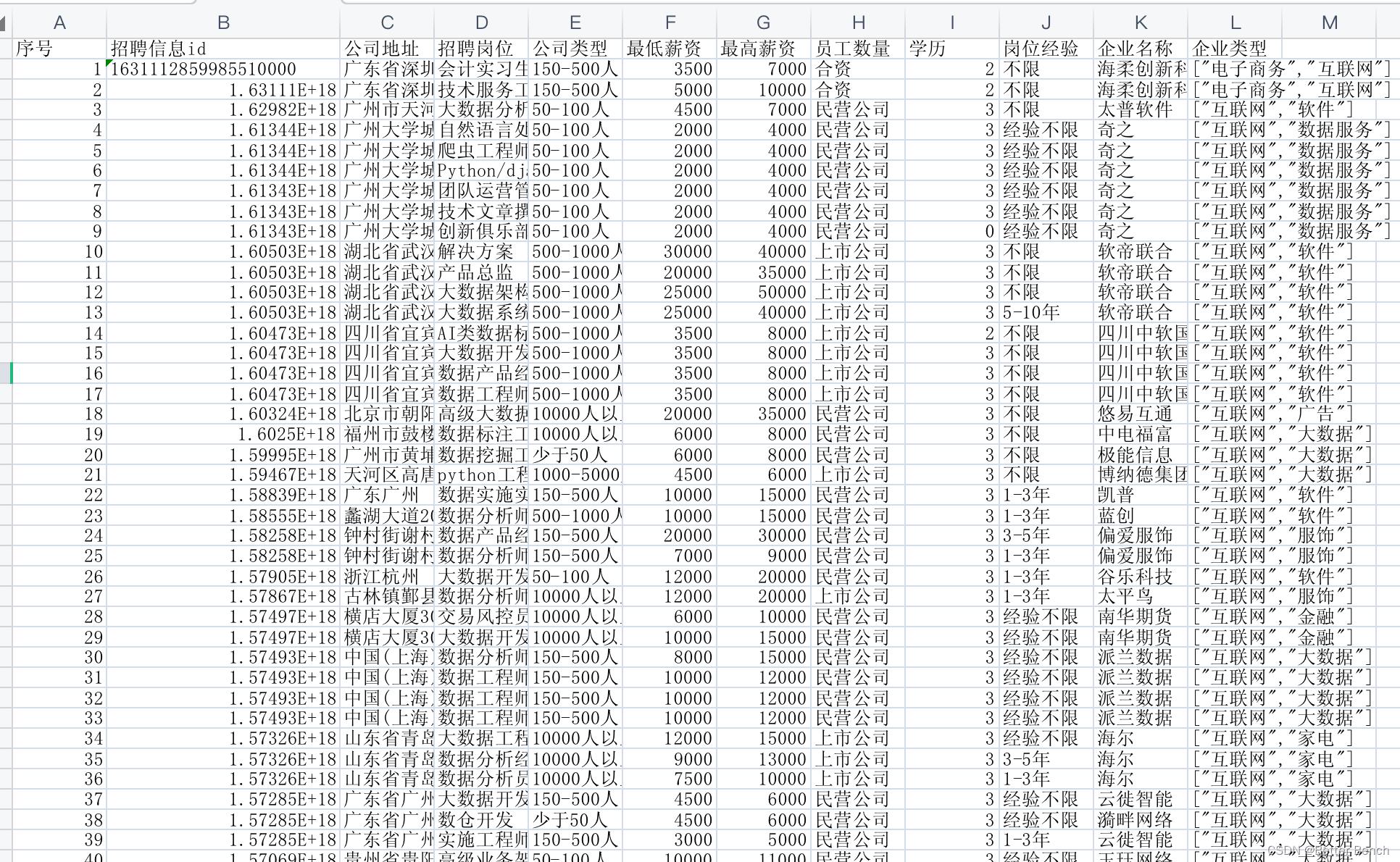
(2)人才信息
有10916个样本

第十一届泰迪杯数据挖掘挑战赛A 题:新冠疫情防控数据的分析 思路+代码(持续更新)
【第十一届泰迪杯数据挖掘挑战赛】A 题:新冠疫情防控数据的分析 思路+代码(持续更新)
问题背景
自 2019 年底至今,全国各地陆续出现不同程度的新冠病毒感染疫情,如何控制疫情蔓
延、维持社会生活及经济秩序的正常运行是疫情防控的重要课题。大数据分析为疫情的精准
防控提供了高效处置、方便快捷的工具,特别是在人员的分类管理、传播途径追踪、疫情研
判等工作中起到了重要作用,为卫生防疫部门的管理决策提供了可靠依据。疫情数据主要包
括人员信息、场所信息、个人自查上报信息、场所码扫码信息、核酸采样检测信息、疫苗接
种信息等。
本赛题提供了某市新冠疫情防疫系统的相关数据信息,请根据这些数据信息进行综合分
析,主要任务包括数据仓库设计、疫情传播途径追踪、传播指数估计及疫情趋势研判等。
解决问题
- 根据核酸检测中阳性人员的出行时间与场所追踪密接者,将结果保存到
“result1.csv”文件中(文件模板见附件 1 中的 result1.csv)。 - 由问题 1 的结果,根据密接者的出行时间与场所追踪相应的次密接者,将结果保存
到“result2.csv”文件中(文件模板见附件 1 中的 result2.csv)。 - 建立模型,分析接种疫苗对病毒传播指数的影响。
- 根据阳性人员的数量及辐射范围,分析确定需要重点管控的场所。
- 为了更精准地进行疫情防控和人员管理,你认为还需要收集哪些相关数据。基于这
些数据构建模型,分析其精准防控的效果。
注 在解决上述问题时,要求结合赛题提供的数据信息表建立数据仓库,实现数据治理
的内容,请在论文中明确阐述做了哪些数据治理工作,具体是如何实现的。
!!注意:以下代码是在Aistudio上面写的,因此就没有建立相关数据库,根据题目要求你们自行建立数据库,然后在代码中进行读取就好了。
代码下载
代码下载地址:第十一届泰迪杯数据挖掘挑战赛-ABC-Baseline
-
大家Fork项目即可查阅所有代码了(free)
-
本项目仅供学习参考,鼓励大家以赛促学,为了保证比赛的公平性(只提供初级Baseline及简易思路分享)
-
若涉嫌违规,将会第一时间删除项目
注:思路仅代表作者个人见解,不一定正确。
数据分析
- 导入常用的包
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from tqdm import tqdm
import warnings
warnings.filterwarnings('ignore')
%matplotlib inline
- 导入文件的时候发现,附件的编码有问题,因此我们需要封装一个获取文件编码的函数
# 获取文件编码
import chardet
def detect_encoding(file_path):
with open(file_path,'rb') as f:
data = f.read()
result = chardet.detect(data)
return result['encoding']
- 读入所有附件
# 读取人员信息表
df_people = pd.read_csv('../datasets/附件2.csv',encoding = detect_encoding('../datasets/附件2.csv'))
# 读取场所信息表
df_place = pd.read_csv('../datasets/附件3.csv',encoding = detect_encoding('../datasets/附件3.csv'))
# 个人自查上报信息表
df_self_check = pd.read_csv('../datasets/附件4.csv',encoding = detect_encoding('../datasets/附件4.csv'))
# 场所码扫码信息表
df_scan = pd.read_csv('../datasets/附件5.csv',encoding = detect_encoding('../datasets/附件5.csv'))
# 核算采样检测信息表
df_nucleic_acid = pd.read_csv('../datasets/附件6.csv',encoding = detect_encoding('../datasets/附件6.csv'))
# 提交示例1
result = pd.read_csv('../datasets/result1.csv',encoding = detect_encoding('../datasets/result1.csv'))
# 提交示例2
result1 = pd.read_csv('../datasets/result2.csv',encoding = detect_encoding('../datasets/result2.csv'))
- 简单的查看一下提交示例
# 查看提交示例
result.head()
result1.head()
- 从提交示例可以看出,该问题应该是让我们制定一个策略去追踪密接者
- 并根据制定的策略获取密接者的其它信息
- 各附件的描述性统计
- 为了让描述性统计更直观,这里给描述性统计封装了一个函数
# 数据描述性统计
def summary_stats_table(data):
'''
a function to summerize all types of data
分类型按列的数据分布与异常值统计
'''
# count of nulls
# 空值数量
missing_counts = pd.DataFrame(data.isnull().sum())
missing_counts.columns = ['count_null']
# numeric column stats
# 数值列数据分布统计
num_stats = data.select_dtypes(include=['int64','float64']).describe().loc[['count','min','max','25%','50%','75%']].transpose()
num_stats['dtype'] = data.select_dtypes(include=['int64','float64']).dtypes.tolist()
# non-numeric value stats
# 非数值列数据分布统计
non_num_stats = data.select_dtypes(exclude=['int64','float64']).describe().transpose()
non_num_stats['dtype'] = data.select_dtypes(exclude=['int64','float64']).dtypes.tolist()
non_num_stats = non_num_stats.rename(columns="first": "min", "last": "max")
# merge all
# 聚合结果
stats_merge = pd.concat([num_stats, non_num_stats], axis=0, join='outer', ignore_index=False, keys=None,
levels=None, names=None, verify_integrity=False, copy=True, sort=False).fillna("").sort_values('dtype')
column_order = ['dtype', 'count', 'count_null','unique','min','max','25%','50%','75%','top','freq']
summary_stats = pd.merge(stats_merge, missing_counts, left_index=True, right_index=True, sort=False)[column_order]
return(summary_stats)
-
人员信息表
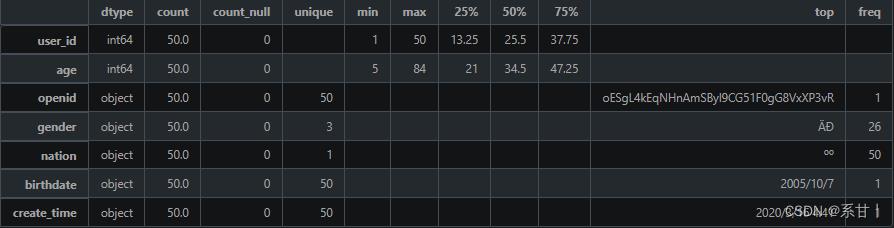
数据说明- user_id:人员 ID,用于唯一标识一个人员。
- openid:微信 OpenID,用于关联该人员的微信账号信息。
- gender:人员的性别,可选值为“男”或“女”。
- nation:人员所属的民族,如汉族、蒙古族、藏族等。
- age:人员的年龄,以整数表示。
- birthdate:人员的出生日期,格式一般为“YYYY-MM-DD”。
- create_time:该记录的创建时间,用于记录人员信息的更新时间。
以下分析结果均基于示例数据
-
people总共50条数据。
-
年龄区间是[5,84]
Tips:年龄跨度比较大,自然而然,我们可以根据年龄做特征工程。
-
在gender中,总共有三个类别(可能存在“未知”类别),在题目中只给了两个类别。
Tips:如果后面需要根据性别进行分析或特征工程的话,需要考虑怎么处理第三个类别。
-
nation民族只有一个类别,而在全量数据中大概率不会只存在一个类别的
Tips:如果后续需要用到该列进行聚合分析或特征工程,可以在Baseline中写好动态的代码。
-
birthdate和create_time在这里都是对应着50个不一样的时间
Tips:注意关注时间的始末,与其它相关联的时间进行比较,这样可以挖掘出更多信息或筛选出一些异常情况。
在全量数据中,时间大概率是有重复值的,也要考虑重复时间是否对解题有一定的影响亦或者重复时间的含义。
-
场所信息表

数据说明- grid_point_id:场所 ID,用于唯一标识一个场所。
- name:场所的名称,如公司、餐厅、超市等。
- point_type:场所的类型,如商业、娱乐、文化、医疗等。
- x_coordinate:场所的 X 坐标,以米为单位,用于表示场所在地图上的位置。
- y_coordinate:场所的 Y 坐标,以米为单位,用于表示场所在地图上的位置。
- create_time:该记录的创建时间,用于记录场所信息的更新时间。
以下分析结果均基于示例数据
-
X、Y坐标,这或许是一个很好用来可视化的数据
Tips:可以根据X、Y坐标对其它特征进行可视化(包括但不限于name、point_type)
但是需要注意的是这只是示例数据,全量数据可能会比较庞大,可视化出来的效果可能没有理想那么好 -
name是场所名,在示例数据中没有重复数据(但不代表全量数据中不会出现重复)
Tips:针对重复的场所名,是否可以聚合起来做数据统计呢?亦或者其它
-
point_type场所类型,在示例数据中总共有17个不同的场所类型,其中类型为娱乐的场所最多
Tips:娱乐只是在示例数据中的结果,不一定是全量数据的。可以根据这一列特征做更多的数据分析,或许还可以进行特征工程
全量数据中有可能出现不同样本中X,Y值相同而对应的name或point_type等其它特征不同的情况。具体问题具体分析,不要什么都当作异常值
-
个人自查上报信息表
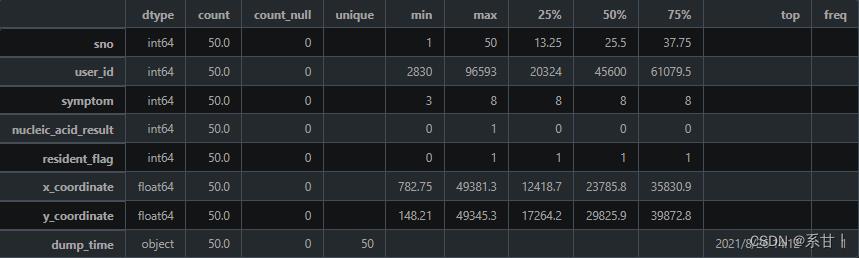
数据说明- sno:序列号,用于唯一标识一条自查记录。
- user_id:人员 ID,对应于“人员信息表”中的 user_id,用于关联自查记录与相应的人员。
- x_coordinate:上报地点的 X 坐标,以米为单位,用于表示上报地点在地图上的位置。
- y_coordinate:上报地点的 Y 坐标,以米为单位,用于表示上报地点在地图上的位置。
- symptom:症状,用于记录自查者的症状情况。可选值为:1 发热、2 乏力、3 干咳、4 鼻塞、5 流涕、6 腹泻、7 呼吸困难、8 无症状。
- nucleic_acid_result:核酸检测结果,用于记录自查者的核酸检测情况。可选值为:0 阴性、1 阳性、2 未知(非必填)。
- resident_flag:是否常住居民,用于记录自查者的居住情况。可选值为:0 未知、1 是、2 否。
- dump_time:上报时间,用于记录自查记录的上报时间。
以下分析结果均基于示例数据
-
symptom,可以看出症状类别在示例数据中是不全的,在示例数据中几乎都是无症状(8)
Tips:在全量数据中,所有类别的数据应该都会存在的,因此在写Baseline的时候可以考虑先写好数据分析可视化的代码。
这一列特征还有一个特点是,在特征工程的时候,可以很好的和其它特征衍生出很多可解释性的交叉特征(eg:symptom-nucleic_acid_result) -
nucleic_acid_result,resident_flag同理
-
这里的X,Y坐标和上表的并不一样,可以挖掘一下两者的区别
Tips:可以根据这X,Y坐标确定该人在什么场所进行的信息上报。
-
dump_time(上报时间),可以将这一列和nucleic_acid_result,X、Y坐标结合,可以挖掘出阳性患者上报期间所在的场合以及周围的人
-
场所码扫码信息表
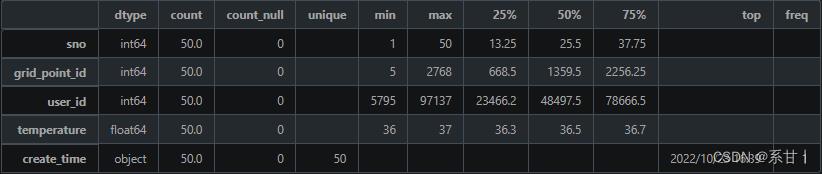
数据说明- sno:序列号,用于唯一标识一条扫码记录。
- grid_point_id:场所 ID,对应于“场所信息表”中的 grid_point_id,用于关联扫码记录与相应的场所。
- user_id:人员 ID,对应于“人员信息表”中的 user_id,用于关联扫码记录与相应的人员。
- temperature:体温,用于记录扫码者的体温情况。
- create_time:扫码记录时间,用于记录扫码记录的时间戳。
以下分析结果均基于示例数据
-
temperature(体温),在示例数据中最小值是36,最大值是37,这数值貌似都在人体正常体温的范畴
Tips:可以将该列与个人信息表中的特征进行交叉分析,在全量数据中大概率会有39左右或更高的体温,因此在写Baseline的时候最好将其考虑进去。
-
create_time(扫码记录时间),我们可以将扫码记录的时间当成该人员即时的体温时间,然后与其它表的特征及时间进行比较
Tips:例如可以与个人自查上报信息表的上报时间以及采样日期进行比较
-
核酸采样检测信息表
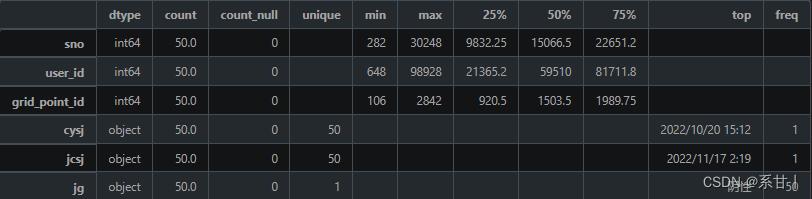
数据说明- sno:序列号,用于唯一标识一条核酸采样记录。
- user_id:人员 ID,对应于“人员信息表”中的 user_id,用于关联核酸采样记录与相应的人员。
- cysj:采样日期和时间,用于记录核酸采样的日期和时间。
- jcsj:检测日期和时间,用于记录核酸检测的日期和时间。
- jg:检测结果,用于记录核酸检测的结果。可选值为:阴性、阳性、未知。
- grid_point_id:场所 ID,对应于“场所信息表”中的 grid_point_id,用于关联核酸采样记录与相应的场所。
以下分析结果均基于示例数据
-
这里出现了两个时间,一个是采样时间,一个是检测时间,那么按照逻辑来说检测时间是会比采样时间晚的
Tips:小心驶得万年船,我们在这里加个判断,如果判断成立,那么该样本就可以视为异常值了
-
对于结果这一列,在示例中结果均为阴性
Tips:我们知道它总共会是有三个类别的,因此写Baseline的时候尽量考虑进去
-
由于前两题没涉及到附件7,因此在这里就没有导入
-
数据可视化建议
数据分析时可以做以下可视化单表可视化
-
人员信息表:可以进行人口统计学分析,如性别、年龄、民族等分布情况,还可以通过人员 ID 与其他表格进行关联分析。
-
场所信息表:可以进行地理信息分析,如场所分布情况、场所类型分布情况、场所密度等分析。
-
个人自查上报信息表:可以进行疫情监测分析,如症状分布情况、症状与核酸检测结果的关联分析、上报人员的位置分布情况等分析。
-
场所码扫码信息表:可以进行疫情监测分析,如扫码记录分布情况、扫码记录与核酸检测结果的关联分析等。
-
核酸采样检测信息表:可以进行疫情监测分析,如阳性人员的分布情况、核酸检测阳性率分析、阳性人员的接触场所与密切接触者分析等。
关联分析
-
个人自查上报信息表和核酸采样检测信息表:可以分析个人上报的症状与核酸检测结果之间的关系,以及症状与检测结果对不同年龄、性别、民族等人群的影响。
-
场所信息表和场所码扫码信息表:可以分析不同场所的扫码情况,了解人们在哪些场所更容易扫码;也可以分析场所内体温异常者的情况,了解哪些场所的防疫工作存在漏洞。
-
个人自查上报信息表和场所码扫码信息表:可以根据个人自查上报的症状,分析不同场所的症状发生情况,了解哪些场所的防疫措施需要进一步加强。
-
核酸采样检测信息表和个人自查上报信息表、场所码扫码信息表:可以分析阳性人员的出行情况,追踪密接者,及时采取隔离措施。
-
Task1
Baseline实现了根据某个阳性人员的核酸检测记录,找出他在检测前后14天内去过的场所,然后再找出去过这些场所的人员,进而确定可能的密接者。具体的实现步骤如下:
-
首先,通过传入的阳性人员ID,在核酸检测记录中筛选出该阳性人员的检测记录,并获取阳性者的采样与检测时间。
-
接着,根据阳性人员在采样时的场所ID,确定第一个阳性人员所在的场所列表。
-
然后,通过阳性人员的ID与场所码扫码信息表进行拼接,获取阳性人员前后十四天所去的场所(第二个阳性人员所在的场所列表)。
-
将两个场所列表进行合并并去重。
-
最后,根据场所码扫码信息表中的所有User_id与场所信息表合并,通过场所列表和时间进行筛选,从而追踪密接者ID
Baseline实现了基于核酸检测记录,找出阳性人员在检测前后14天内去过的场所,并通过这些场所找出可能的密接者。
# 获取阳性者信息
positive_user_id = df_nucleic_acid[df_nucleic_acid['jg'] =='阳性']['user_id'].values.tolist()
def Potential_contacts(df_people,df_place,df_self_check,df_scan,df_nucleic_acid,positive_user_id):
# 筛选出阳性者的核酸检测记录
df_positive_test = df_nucleic_acid[df_nucleic_acid['user_id'] == positive_user_id]
# 获取阳性者的检测时间
positive_test_time = pd.to_datetime(df_positive_test['cysj'].iloc[0])
df_self_check['dump_time'] = pd.to_datetime(df_self_check['dump_time'])
df_scan['create_time'] = pd.to_datetime(df_scan['create_time'])
# 获得阳性人员核酸检测的场所
positive_users_place1 = pd.merge(df_positive_test, df_place, on='grid_point_id')['name'].tolist()
# 获得阳性人员在测验时间前后14天去的场所
positive_users_place2 = pd.merge(df_positive_test, df_scan, on='user_id')[['user_id','create_time','cysj','grid_point_id_y']]
# 计算前14天和后14天
delta = pd.Timedelta(days=14)
# 计算最小时间和最大时间
min_date = positive_users_place2['cysj'].min() - pd.Timedelta(days=14)
max_date = positive_users_place2['cysj'].max() + pd.Timedelta(days=14)
# 筛选出符合要求的数据
mask = (positive_users_place2['create_time'] >= min_date) & (positive_users_place2['create_time'] <= max_date)
positive_users_place2 = positive_users_place2.loc[mask, ['user_id', 'grid_point_id_y']]
positive_users_place2 = positive_users_place2.rename(columns='grid_point_id_y': 'grid_point_id')
positive_users_place2 = pd.merge(positive_users_place2, df_place, on='grid_point_id')['name'].tolist()
# 将两个列表合并去重
positive_place = list(set(positive_users_place1+positive_users_place2))
# 获取去过上述场所的人员
# 按照密接时间筛选
df_potential_contacts = df_scan[(df_scan['create_time'] >= positive_test_time - pd.Timedelta('14D')) & (df_scan['create_time'] <= positive_test_time + pd.Timedelta('14D'))]
# 按照场所筛选
df_potential_contacts = df_potential_contacts[df_potential_contacts['grid_point_id'].isin(df_place[df_place['name'].isin(positive_place)]['grid_point_id'])]
# 整合信息并按照要求输出
result = pd.DataFrame(
'序号': range(1, len(df_potential_contacts)+1),
'密接者ID': df_potential_contacts['user_id'].values,
'密接日期': df_potential_contacts['create_time'].dt.date.astype(str),
'密接场所ID': df_potential_contacts['grid_point_id'].values,
'阳性人员ID': [positive_user_id] * len(df_potential_contacts)
)
return result
为本题封装了名为 Potential_contacts的函数,该函数的目的是找到所有可能与阳性者有接触的人员信息。
函数的具体逻辑如下:
- 从 df_nucleic_acid 中获取 positive_user_id 对应的阳性者的核酸检测记录和检测时间。
- 将 df_self_check 和 df_scan 数据框中的时间列转换为 datetime 类型。
- 从 df_place 中获取 positive_user_id 在核酸检测时间点去过的场所列表 positive_users_place1。
- 从 df_scan 中获取 positive_user_id 在核酸检测时间点前后 14 天去过的场所列表 positive_users_place2。
- 将 positive_users_place1 和 positive_users_place2 合并去重得到 positive_place,即 positive_user_id 去过的所有场所。
- 从 df_scan 中筛选出在 positive_test_time 前后 14 天有扫码记录的人员(即潜在密接者)df_potential_contacts。
- 从 df_place 中筛选出 positive_place 中的场所,并将这些场所的 grid_point_id 与 df_potential_contacts 中的 grid_point_id 匹配得到所有潜在密接者的位置信息。
整合潜在密接者的信息和阳性者的信息,并返回一个数据框,其中包含序号、密接者 ID、密接日期、密接场所 ID 和阳性人员 ID 等信息。
Task2
代码持续在Aistudio上更新,大家可以Fork查看。更新完才会更新文章
以上是关于2023年第十一届泰迪杯数据挖掘挑战赛C题:泰迪内推平台招聘与求职双向推荐系统构建 建模及python代码详解 问题一的主要内容,如果未能解决你的问题,请参考以下文章