ElasticSearch
Posted weixin_42412601
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了ElasticSearch相关的知识,希望对你有一定的参考价值。
目录
1、ES是什么?
Elasticsearch (ES)是一个基于Lucene构建的开源、分布式、RESTful 接口全文搜索引擎。Elasticsearch 还是一个分布式文档数据库,其中每个字段均是被索引的数据且可被搜索,它能够扩展至数以百计的服务器存储以及处理PB级的数据。它可以在很短的时间内在储、搜索和分析大量的数据。它通常作为具有复杂搜索场景情况下的核心发动机。
简单说,ES就是一个擅长搜索分析数据的数据库。
2、能干啥?
- 数据搜索:比如百度、各类网站的站内搜索等等,Elasticsearch支持各种各样的检索:全文检索、结构化检索、部分匹配、自动完成、搜索纠错、搜索推荐等等。
- 数据分析
- 大型分布式日志分析系统ELK elasticsearch(存储日志)+logstash(收集日志)+kibana(展示数据)
- 比如BI(Business Intelligence)系统,分析某区域最近3年的用户消费金额的趋势以及用户群体的组成构成,产出相关的数张报表。一般用ES执行数据分析和挖掘,Kibana进行数据可视化。
- 大数据近实时处理:Elasticsearch可以将海量数据分散到多台服务器上去存储和检索,在秒级别对数据进行搜索和分析。
3、ES的基本构成
- 集群(Cluster):一个集群是由一个或多个节点(服务器)组成的,通过所有的节点一起保存你的全部数据并且提供联合索引和搜索功能的节点集合
- 节点(Node):一个节点是一个单一的服务器,是你的集群的一部分,存储数据,并且参与集群的索引和搜索功能
- 索引(Index):相当于
mysql的数据库。一个索引就是含有某些相似特性的文档的集合 - 类型(Type)表:相当于
mysql的表。mappings相当于数据库中表结构定义 - 文档(document) :相当于
mysql的行数据。一个文档是一个可被索引的基础信息单元。 - 字段(Fields):相当于
mysql的列
4、分片和复制
分片,类似mysql分库分表的概念。
分片出现的原因?
比如:有一个索引具有10亿级别的文档,占据了1TB的磁盘空间;你任意一个节点都没有那么大的磁盘空间;或者放下了但是处理速度太慢。为了解决这个问题,Elasticsearch提供了将索引划分成多份的能力,这些份就叫做分片。
ES 默认为一个索引创建 5 个主分片, 并分别为其创建一个副本分片. 也就是说每个索引都由 5 个主分片组成, 而每个主分片都相应的有一个 copy。唯一区别在于只有主分片才能处理索引请求.副本对搜索性能非常重要,同时用户也可在任何时候添加或删除副本。
分片和复制的数量可以在索引创建的时候指定。在索引创建之后,你可以在任何时候动态地改变复制的数量,但是你事后不能改变分片的数量。
5、Elasticsearch是如何做到快速索引的?
ES把文档数据写入到倒排索引(Inverted Index)的数据结构中,倒排索引建立的是分词(Term)和文档(Document)之间的映射关系,在倒排索引中,数据是面向词(Term)而不是面向文档的。在插入数据到索引的同时,Elasticsearch还为每个字段建立索引——倒排索引。
例如:
假设有个user索引,它有四个字段:分别是name,gender,age,address。画出来的话,大概是下面这个样子,跟关系型数据库一样
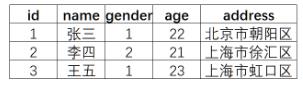
上面的例子,ES建立的索引大致如下:
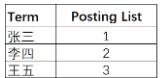
name字段对应的索引:
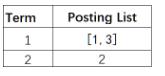
gender字段对应的索引:
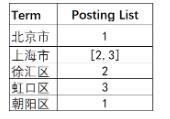
address字段对应的索引:
- Term(单词):一段文本经过分析器分析以后就会输出一串单词,这一个一个的就叫做Term(直译为:单词)
- Posting List(倒排列表):倒排列表记录了出现过某个单词的所有文档的文档列表及单词在该文档中出现的位置信息,每条记录称为一个倒排项(Posting)。根据倒排列表,即可获知哪些文档包含某个单词。实际的倒排列表中并不只是存了文档
ID这么简单,还有一些其它的信息,比如:词频(Term出现的次数)、偏移量(offset)等,可以想象成是Java中的对象 - Term Dictionary(单词字典):顾名思义,它里面维护的是
Term,可以理解为Term的集合 - Term Index(单词索引):为了更快的找到某个单词,我们为单词建立索引
Elasticsearch分别为每个字段都建立了一个倒排索引。比如,在上面“张三”、“北京市”、22 这些都是Term,而[1,3]就是Posting List。Posting list就是一个数组,存储了所有符合某个Term的文档ID。只要知道文档ID,就能快速找到文档。
可是,要怎样通过我们给定的关键词快速找到这个Term呢?
比如,我输入上海市,单词字典里那么多的term,怎么才能快速的找到上海市这个term呢?
当然是建索引了,为Terms建立索引,最好的就是B Tree索引(PS:MySQL就是B树索引最好的例子)。
term充当B+树中的key,通过term索引可以找到term在term Dictionary中的位置,进而找到Posting List,有了倒排列表就可以根据ID找到文档了,倒排列表里记录了相应的文档的id
6、B树
让我们来回忆一下MyISAM存储引擎中的索引是什么样的。
索引是帮助
mysql高效获取数据的数据结构。mysql索引使用的是B+tree实现的
在看MyISAM存储引擎中的索引之前,我们先看一下B树和B+树。
6.1、B树
如下图所示为一个3阶的B-Tree:
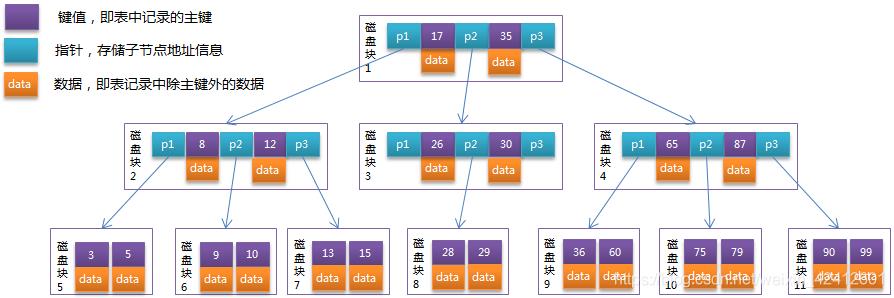
每个节点占用一个盘块的磁盘空间,一个节点上有两个升序排序的关键字和三个指向子树根节点的指针,指针存储的是子节点所在磁盘块的地址。两个关键词划分成的三个范围域对应三个指针指向的子树的数据的范围域。
以根节点为例,关键字为17和35,P1指针指向的子树的数据范围为小于17,P2指针指向的子树的数据范围为17~35,P3指针指向的子树的数据范围为大于35。
将磁盘块由磁盘读取到内存称为一次I/O操作
B树是怎么搜索数据的?
模拟查找关键字29的过程:
根据根节点找到磁盘块1,读入内存。【磁盘I/O操作第1次】 比较关键字29在区间(17,35),找到磁盘块1的指针P2。
根据P2指针找到磁盘块3,读入内存。【磁盘I/O操作第2次】 比较关键字29在区间(26,30),找到磁盘块3的指针P2。
根据P2指针找到磁盘块8,读入内存。【磁盘I/O操作第3次】 在磁盘块8中的关键字列表中找到关键字29。
范围查询:查找【9-28】的数据
自顶向下,查找到范围的下限9,同时10也找到;【磁盘I/O操作第1次】
中序遍历到元素12 【磁盘I/O操作第2次】
中序遍历到元素13,15 【磁盘I/O操作第3次】
中序遍历到元素17 【磁盘I/O操作第4次】
中序遍历到元素26 【磁盘I/O操作第5次】
中序遍历到元素28,遍历结束 【磁盘I/O操作第6次】
6.2、B+树
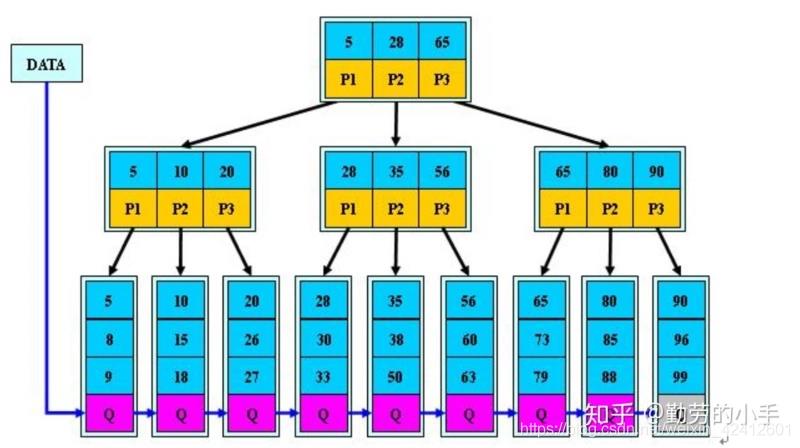
范围查询:查找【20-50】的元素
自顶向下,查找到范围的下限20,同时26,27也就找到了 【磁盘I/O操作第1次】
通过链表指针,遍历到元素28,30,33 【磁盘I/O操作第2次】
通过链表指针,遍历到元素35,38,50 【磁盘I/O操作第3次】
6.3、MyISAM 索引实现
MyISAM 引擎使用 B+Tree 作为索引结构,叶节点的 data 域存放的是数据记录的地址,注意是地址,不是具体的数据!
下图是 MyISAM 索引的原理图:
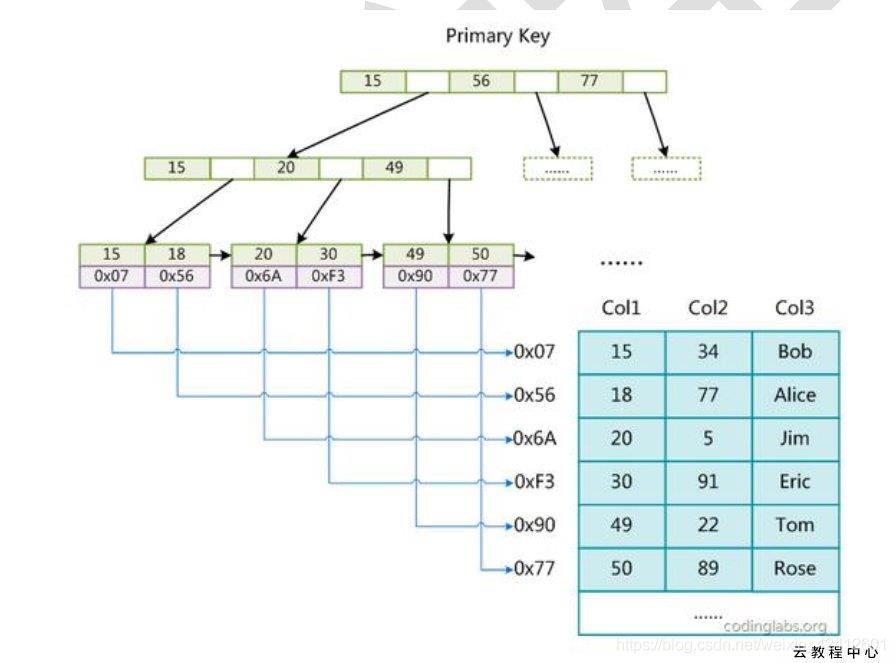
这里设表一共有三列,假设我们以 Col1 为主键,则图是一个 MyISAM 表的主索引(Primary key)示意。可以看出 MyISAM 的索引文件仅仅保存数据记录的地址。
MyISAM 的索引方式也叫做“非聚集索引”,之所以这么称呼是为了与 InnoDB的聚集索引区分。
7、文档路由原理
7.1、数据路由
Elasticsearch就是采用了hash路由算法,对document记录的id标识进行计算,产生了一个shard序号,通过这个shard序号就可以立即确认写到哪个shard里面。
假设我们往test_index这个索引里面写入了一条document记录(id=1024),然后按照路由算法shard = hash(routing_key) % number_of_primary_shards,计算出shard=1,那么就写到序号为1的那个primary shard中。
插入数据的时候,是可以自己设置主键的,如果不设置,系统自动生成一个主键。
7.2、数据写入
假设我们ES集群是下面这个样子的,3个primary shard,每个primary shard都有一个副本。
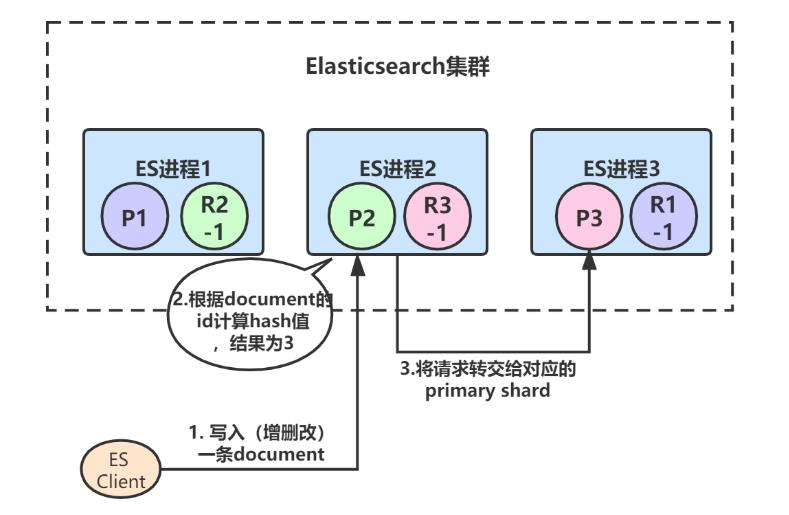
1、客户端(集成了Elasticsearch Client SDK)发起了一条document的写入请求,请求可能hit到任意某个ES节点上,hit到的这个节点也叫做coordinate node(协调节点):
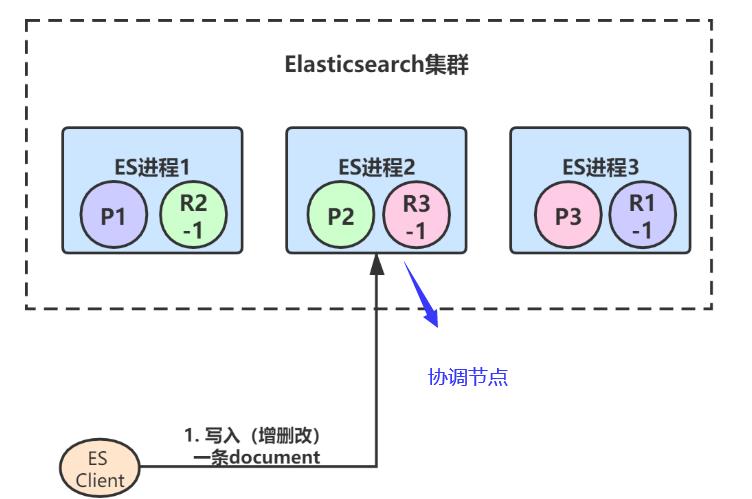
由于ES进程1、2、3构成了一个集群,所以每个ES节点其实都知道集群中的其它节点的信息,包括集群中一共有多少primary/replica shard,每个节点上分配着哪些primary/replica shard。
2、假设ES进程2节点(协调节点)接受到了请求,于是根据document的id进行hash计算,发现结果是3,也就是应该由P3这个primary shard处理这个请求,所以就会把请求转发给ES进程3节点上的P3:
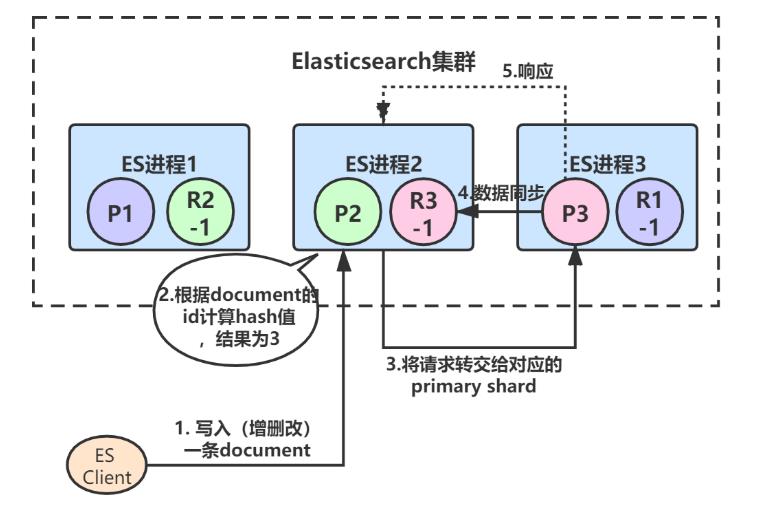
3、primary shard 3处理完请求后,会将数据同步到自己的replica shard(R3-1),同步完后响应ES进程2:
4、最后,ES进程2(协调节点)收到响应后,返回给ES client结果:
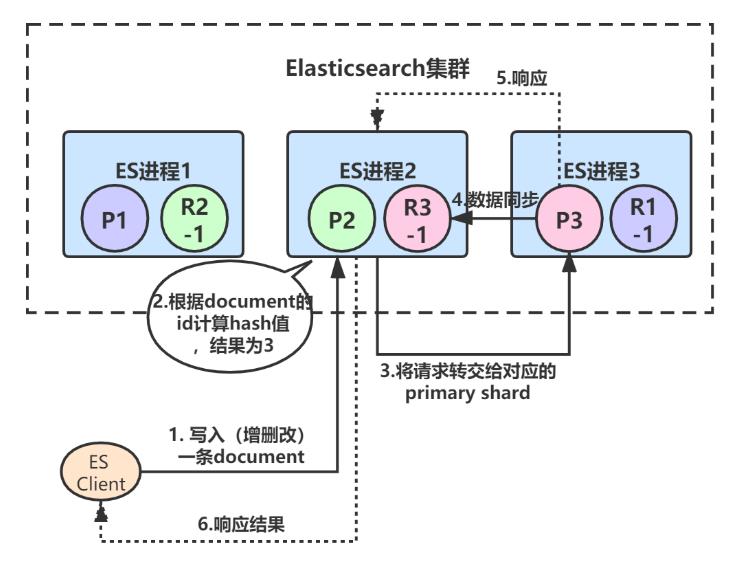
ES对于写请求,最终都是转交给primary shard去处理的。
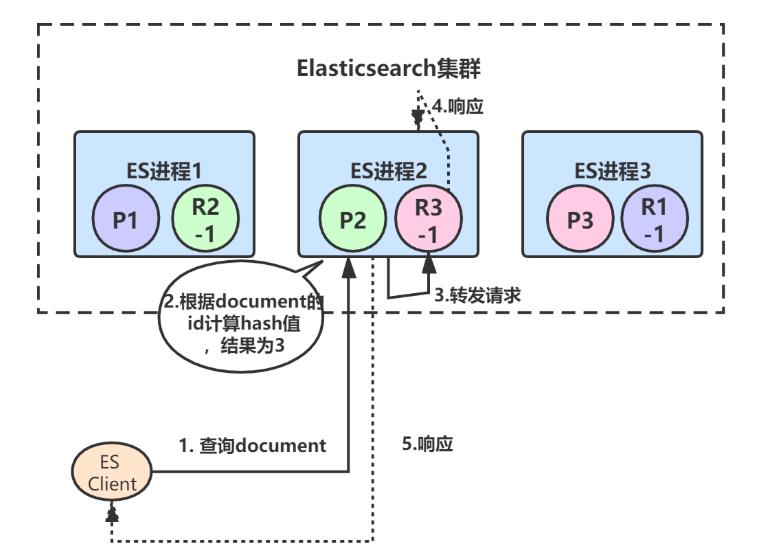
7.3、数据查询
document数据查询的原理基本和写入类似,只不过查询请求既可以由primary shard处理,也可以由replica shard处理,这样就提高了系统的吞吐量和性能。
coordinate node(协调节点)在接受到查询请求后,会采用round-robin算法[轮询],在对应的primary shard及其所有replica中选择一个发送请求,以达到读请求负载均衡的目的。
1、首先客户端发起查询某个document的请求,假设命中到ES进程2,ES进程2根据document Id计算出应该由primary shard 3来处理:
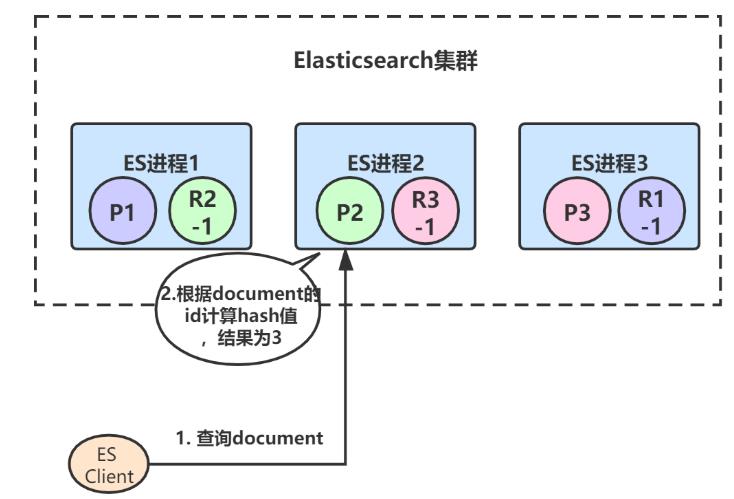
2、primary shard 3有一个replica,所以协调节点会采用round-robin轮询算法选取其中一个转发请求,比如选择了R3-1,然后将请求转发给它,R3-1查询得到结果后返回,最终ES进程2将结果返回给客户端
以上是关于ElasticSearch的主要内容,如果未能解决你的问题,请参考以下文章
使用标准库Ruby将数据标记到Elasticsearch批量中
Elasticsearch:如何在 Elasticsearch 中正确使用同义词功能