Ubuntu从零安装 Hadoop And Spark
Posted _luckylight
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Ubuntu从零安装 Hadoop And Spark相关的知识,希望对你有一定的参考价值。
安装 linux 以Ubuntu为例
选择镜像,虚拟机安装
虚拟机下,直接安装镜像即可,选择好自己的配置,一定要注意路径名选好,而且和你虚拟机的名称匹配,这里我的镜像是 ubuntu-20.04.2.0-desktop-amd64.iso
切换一下中文
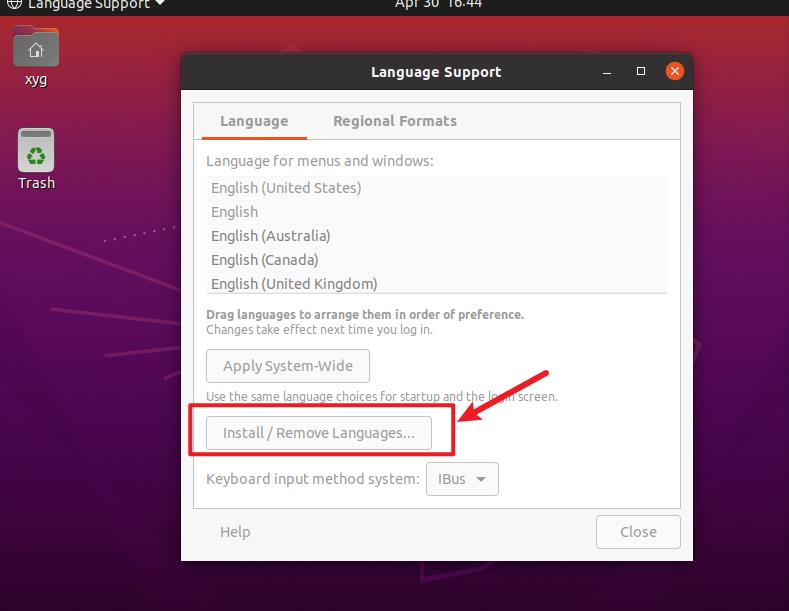
注意重启之后,这一部分保留英文
安装 VMTools
为了方便 复制粘贴,建议安装 VMTools,这里不再给出如何安装
提前准备工作
创建用户
首先我们创建hadoop用户,并将/bin/bash 作为他的 默认 shell,并设置他的密码以及增加管理员权限
(CTRL + SHIFT + V 是linux 下的 粘贴快捷键)
sudo useradd -m hadoop -s /bin/bash
sudo passwd hadoop
sudo adduser hadoop sudo
设置成功后,我们退出,使用 hadoop 用户登录此linux系统
更新apt
sudo apt-get update
安装 Vim
vim 是 vi 的升级版,快捷好用,为了编辑文本,我们可以使用 vim,也可以使用 vi,或者是 gedit,看个人喜好
sudo apt-get install vim
安装 SSH
SSH 为 Secure Shell 的缩写。是较可靠,专为远程登录会话和其他网络服务提供安全性的协议。利用 SSH 协议可以有效防止远程管理过程中的信息泄露问题。
具体查看 SSH的内容可以直接去百度
从客户端来看,SSH提供两种级别的安全验证。
第一种级别(基于口令的安全验证)
只要你知道自己帐号和口令,就可以登录到远程主机。所有传输的数据都会被加密,但是不能保证你正在连接的服务器就是你想连接的服务器。可能会有别的服务器在冒充真正的服务器,也就是受到“中间人”这种方式的攻击。
第二种级别(基于密匙的安全验证)
需要依靠密匙,也就是你必须为自己创建一对密匙,并把公用密匙放在需要访问的服务器上。如果你要连接到SSH服务器上,客户端软件就会向服务器发出请求,请求用你的密匙进行安全验证。服务器收到请求之后,先在该服务器上你的主目录下寻找你的公用密匙,然后把它和你发送过来的公用密匙进行比较。如果两个密匙一致,服务器就用公用密匙加密“质询”(challenge)并把它发送给客户端软件。客户端软件收到“质询”之后就可以用你的私人密匙解密再把它发送给服务器。
用这种方式,你必须知道自己密匙的口令。但是,与第一种级别相比,第二种级别不需要在网络上传送口令。
第二种级别不仅加密所有传送的数据,而且“中间人”这种攻击方式也是不可能的(因为他没有你的私人密匙)。但是整个登录的过程可能需要10秒 [2] 。
集群、单节点模式都需要用到SSH登陆(类似于远程登陆,你可以登录某台Linux电脑,并且在上面运行命令),Ubuntu 默认已安装了 SSH client,此外还需要安装 SSH server:
sudo apt-get install openssh-server
安装后,可以使用如下命令登陆本机:
localhost 等价于 127.0.0.1 本机 ip
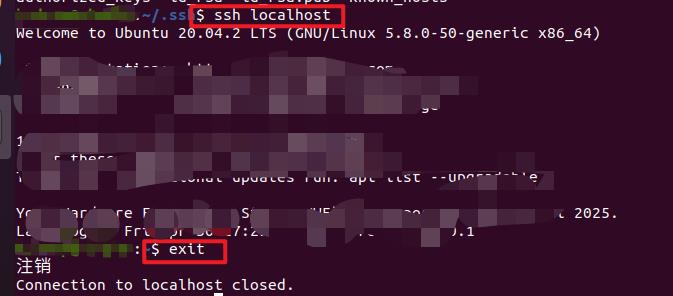
ssh localhost
输入密码之后便可以进入

但这样登陆是需要每次输入密码的,我们需要配置成SSH无密码登陆比较方便。
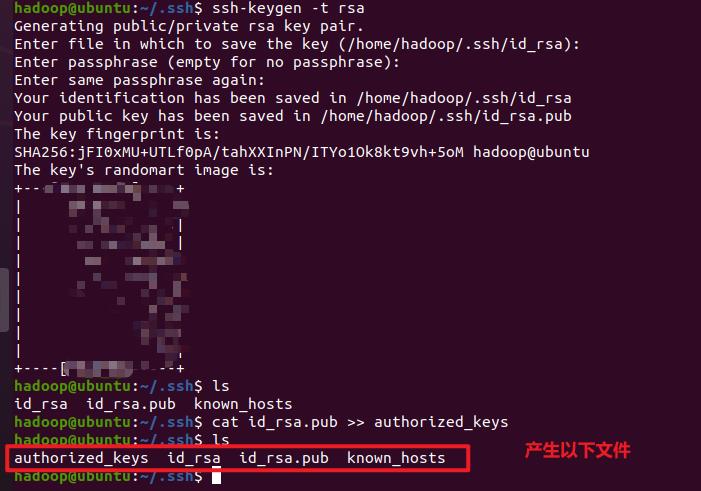
首先退出(使用exit 命令)刚才的 ssh,就回到了我们原先的终端窗口,然后利用 ssh-keygen 生成密钥,并将密钥加入到授权中:
exit # 退出刚才的 ssh localhost
cd ~/.ssh/ # 若没有该目录,请先执行一次ssh localhost
ssh-keygen -t rsa # 会有提示,都按回车就可以
cat id_rsa.pub >> authorized_keys # 加入授权
重新尝试发现不需要密码了
安装 Hadoop 和 Java
Java
查看可用 java 版本
apt search openjdk
apt安装 open jdk,这里选择 openjdk-14-jdk
sudo apt install openjdk-14-jdk
java --version 查看是否安装成功
java --version
配置java环境
下面我来介绍一下如何配置java 的环境
为方便,我们在 ~/.bashrc 中进行设置
修改home目录下的 .bashrc 文件
.bashrc 文件主要保存着个人的一些个性化设置,如:命令别名、环境变量等。 参考中有其他修改方法。
首先,我们打开配置文件
gedit ~/.bashrc
在配置文件中加入一行
export JAVA_HOME=/usr/lib/jvm/java-14-openjdk-amd64
请注意,这部分 JAVA_HOME=的内容需要你个人去文件目录中查看,毕竟下载的 openjdk版本不同
下面,我们让配置生效,并且验证配置是否成功
source ~/.bashrc # 使变量设置生效
echo $JAVA_HOME # 检验是否设置正确

安装 hadoop
在这里,我下载的是 hadoop-3.3.0.tar.gz,版本可以执行百度下载即可,选择一个下载速度快的
首先,我们将文件解压,到/usr/local 目录下,重命名并修改用户主,注意,选择自己的 hadoop 版本号
cd ~/下载
sudo tar -zxvf ./hadoop-3.3.0.tar.gz -C /usr/local # 解压到/usr/local中
cd /usr/local/
sudo mv ./hadoop-3.3.0/ ./hadoop # 将文件夹名改为hadoop
sudo chown -R hadoop:hadoop ./hadoop # 修改文件权限
hadoop单机测试
Hadoop 默认模式为非分布式模式,无需进行其他配置即可运行。非分布式即单 Java 进程,方便进行调试。
现在我们可以执行例子来感受下 Hadoop 的运行。Hadoop 附带了丰富的例子(运行 bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.0.jar 可以看到所有例子),包括 wordcount、terasort、join、grep 等。
在此我们选择运行 grep 例子,即将 input 文件夹中的所有文件作为输入,筛选当中符合正则表达式 dfs[a-z.]+ 的单词并统计出现的次数,最后输出结果到 output 文件夹中。
cd /usr/local/hadoop
mkdir input
cp ./etc/hadoop/*.xml input # 将配置文件作为输入文件
./bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-*.jar grep input output 'dfs[a-z.]+'
cat ./output/* # 查看运行结果
倘若提示 JAVA_HOME 未定义,你先 echo “$JAVA_HOME”,然后查看 ~/.bashrc 文件,以及 source ~/.bashrc 一下,再次输出 $JAVA_HOME 是否可以
hadoop伪分布式配置
Hadoop 可以在单节点上以伪分布式的方式运行,Hadoop 进程以分离的 Java 进程来运行,节点既作为 NameNode 也作为 DataNode。
Hadoop 的配置文件位于 /usr/local/hadoop/etc/hadoop/ 中,伪分布式需要修改2个配置文件 core-site.xml 和 hdfs-site.xml 。Hadoop的配置文件是 xml 格式,每个配置以声明 property 的 name 和 value 的方式来实现。
修改配置文件 core-site.xml (gedit /usr/local/hadoop/etc/hadoop/core-site.xml),将当中的
<configuration>
</configuration>
修改为下面配置:
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
同样的,修改配置文件 hdfs-site.xml:
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/data</value>
</property>
</configuration>
配置完成后,执行 namenode 的格式化:
bin/hdfs namenode -format
注意
在这一步以及后面启动 Hadoop 时若提示 Error: JAVA_HOME is not set and could not be found. 的错误,则需要在文件 ./etc/hadoop/hadoop-env.sh 中设置 JAVA_HOME 变量,即找到 export JAVA_HOME=${JAVA_HOME}这一行,改为 export JAVA_HOME=/usr/lib/jvm/java-14-openjdk-amd64 (就是之前设置的JAVA_HOME位置),再重新尝试即可。
下面我们输入命令,查看是否成功
./sbin/start-all.sh #开启
jps
最后需要关闭
./sbin/stop-all.sh # 关闭
输入命令后的运行效果如下
hadoop 伪分布式测试
注意测试的时候一定要打开 hadoop, 即运行 sbin/start-all.sh
运行完之后, sbin/stop-all.sh
安装 Spark,并使用PySpark测试
Spark的安装
可以直接看这个参考网站,很合适
按照链接的做法
- 首先将下载好的 Spark 安装包解压至 /usr/local 的目录下
- 然后修改 /usr/local/spark/conf 目录下的配置文件
spark-env.sh

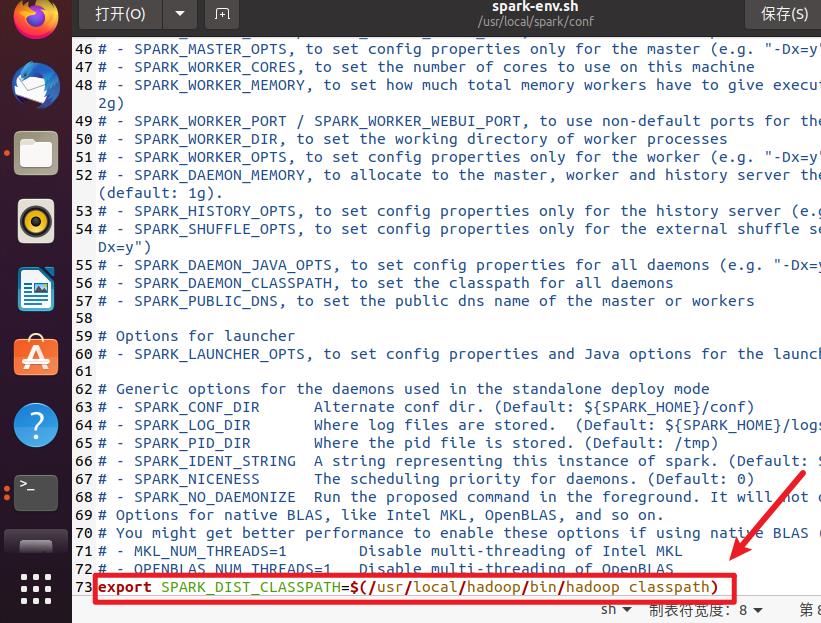
- 之后,我们修改环境变量
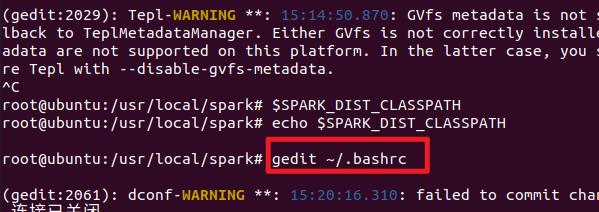
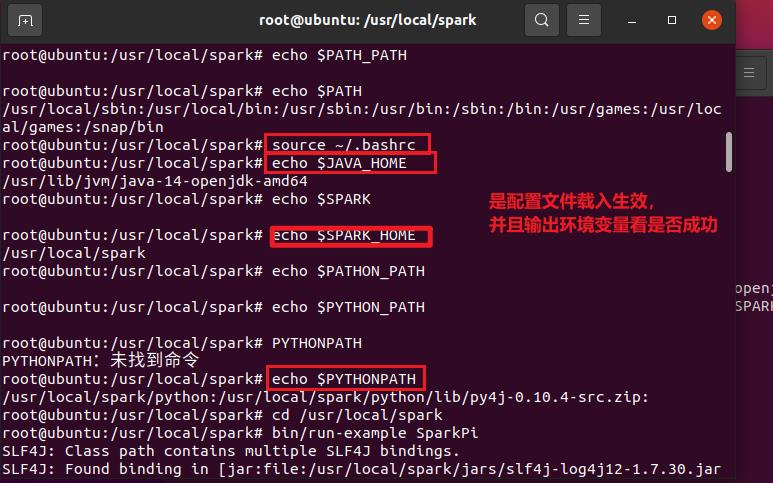
这里进行勘误,应该在 hadoop 用户下进行,否则修改的是 root 的配置文件,而不是我们 hadoop 用户的配置文件!


- 最后我们运行测试一下
执行时会输出非常多的运行信息,输出结果不容易找到,可以通过 grep 命令进行过滤(命令中的 2>&1 可以将所有的信息都输出到 stdout 中,否则由于输出日志的性质,还是会输出到屏幕中):

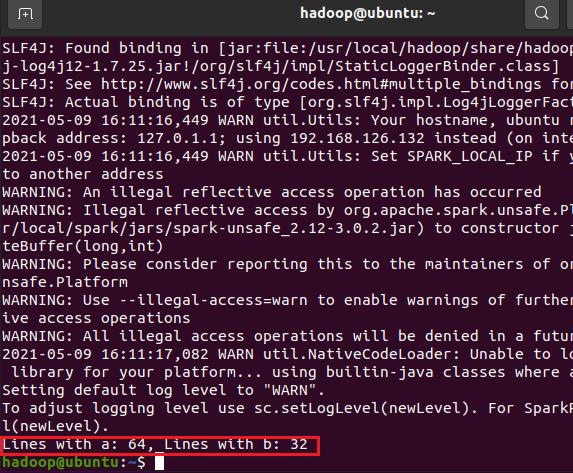
Spark的测试
运行的代码
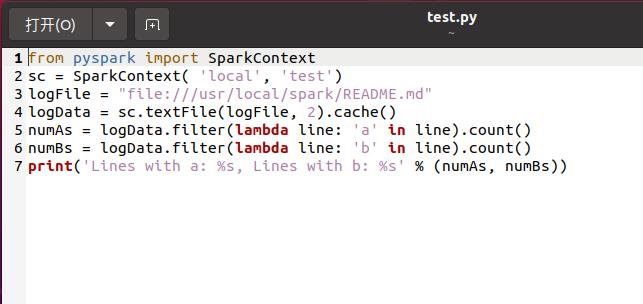
出现一个问题
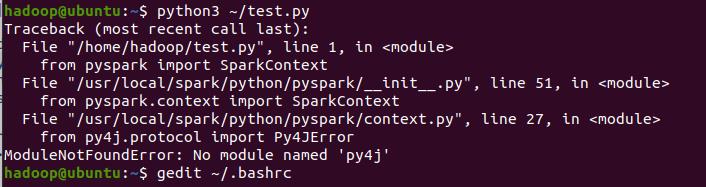
原来是路径写错了
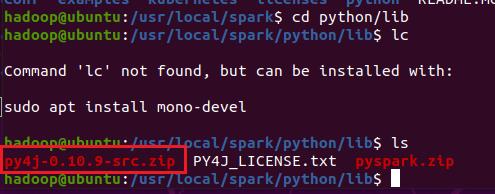


参考链接
https://blog.csdn.net/qinzhaokun/article/details/47804923
以上是关于Ubuntu从零安装 Hadoop And Spark的主要内容,如果未能解决你的问题,请参考以下文章