Centos环境下从零部署Hadoop分布式集群
Posted "Hello World".
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Centos环境下从零部署Hadoop分布式集群相关的知识,希望对你有一定的参考价值。
一、Hadoop安装前期准备
- 为了更清晰的管理安装软件,这里在/opt下创建两个文件夹,module用来安装软件,software用来存放需要的安装包,jar包等资源。
cd /opt
sudo mkdir module
sudo mkdir software
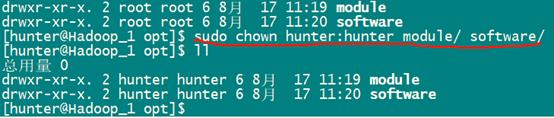
- 将这两个文件夹操作权限赋予hunter(当前用户):即hunter用户可以对这两个文件夹执行操作,此步骤可避免在后续的安装过程中,因权限问题导致的安装出错等问题,也避免了频繁地使用root用户进行操作。
sudo chown hunter:hunter module/ software
二、安装包上传
-
将JDK和Hadoop的JAR包上传到software文件夹下(用secureFX工具上传比较简单)
注:Hadoop下载地址 http://hadoop.apache.org/
JDK下载地址:https://www.oracle.com/java/technologies/javase-jdk11-downloads.html

-
修改所属
sudo chown hunter:hunter Hadoop-2.7.7tar.gz jdk-8…….tar.gz

- 解压jdk到/opt/module
tar -zxvf jdk-.tar.gz -C /opt/module/
- 切换到/opt/module/jkd目录下可以查看jdk所在路径:/opt/module/jdk1.8.0_231

三、配置Java环境变量
- 配置java环境变量
sudo vi /etc/profile
- 在末尾添加JAVA路径(自己根据存放的位置灵活修改)
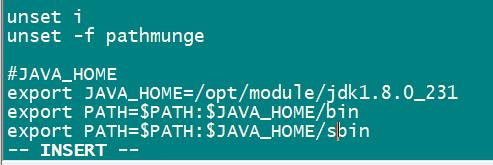
- 刷新配置文件,使其生效
source /etc/profile

- 查看jdk版本,判断是否安装成功
java -version

至此,Java环境已配置好。
四、部署Hadoop
- 首先进入到software,解压Hadoop包到/opt/module
tar -zxvf hadoop-2.7.7.tar.gz -C /opt/module/

- 添加Hadoop环境变量,首先拿到Hadoop所在路径:/opt/module/hadoop-2.7.7

- 编辑配置文件,将Hadoop环境变量添加上
sudo vi /etc/profile

- 在刚才我们配置的JAVA环境下添加如下信息
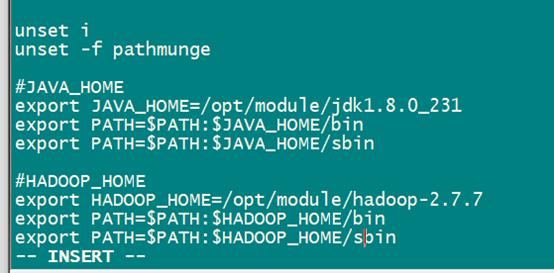
- 刷新配置文件,使其生效
source /etc/profile
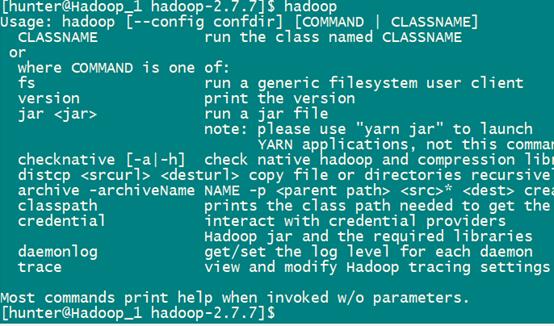
- 检查是否配置成功,出现如下图片中信息,说明已经Hadoop环境配置成功
hadoop
至此,该主机上的Hadoop环境已准备好(还需要修改Hadoop配置文件以完成Hadoop的配置)
4.1 修改Hadoop配置文件(分布式Hadoop集群部署)
- 集群规划表,下面按照这个规划表进行配置(自己灵活改动)
| Hadoop1 | Hadoop2 | Hadoop3 | Hadoop4 | |
|---|---|---|---|---|
| HDFC | NN | DN | SNN/DN | DN |
| YARN | NM | NM/RM | NM | NM |
- 首先切换到Hadoop-2.7.7/etc文件夹下
- 修改hadoop-env.sh,添加以下内容(图片中红线内容)
vi Hadoop-env.sh

- 接下来切换到/opt/module/hadoop-2.7.7/etc/hadoop下
cd /opt/module/hadoop-2.7.7/etc/hadoop
- 修改core.xml,内容如下
vi core.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<!-- Put site-specific property overrides in this file. -->
<configuration>
<!-- 指定HDFS中Namenode的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://Hadoop1:9000</value>
</property>
<!-- 指定hadoop运行时产生文件的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop-2.7.7/data/tmp</value>
</property>
</configuration>
- 修改hdfs-site.xml,添加以下内容
vi hdfs-site.xml
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>Hadoop3:50090</value>
</property>
</configuration>
- 修改yarn-site.xml,添加以下内容
vi yarn-site.cml
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<!-- reducer获取数据的方式 -->
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定YARN的ResourceManager的地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>Hadoop2</value>
</property>
<!-- 日志聚集功能开启 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 日志保留时间设置为7天 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
</configuration>
- 在mapred-site.sh中修改java环境变量,和Hadoop中的java环境变量配置方法相似
vi mapred-site.sh
- 创建slaves文件(Hadoop3.x中将slaves更换成了works,配置内容一样),用来存储节点名,添加以下内容(前提是已经为每个节点配置hosts,这里的Hadoop1,2等就相当于节点的ip地址了)
vi slaves
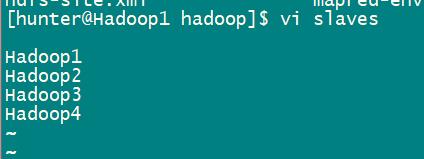
至此,我们已经在Hadoop1这个节点上配置好了Hadoop所需要的相关信息,接下来,在其他节点上需要执行上面同样的操作,当然也可以使用集群分发脚本,将该节点配置好的文件分发到集群中的其他节点(集群分发脚本后续更新)
当在每个节点上都配置好了以上信息后,就可以对集群进行格式化和启动了
4.2 Hadoop启动
- 新搭建的集群,首先需要格式化Namenode,在hadoop-2.7.7下执行以下命令。
bin/hdfs namenode -format
- 格式化成功后,就可以启动Hadoop集群了
start-dfs.sh
- 启动YARN,按群我们的集群规划,需要到Hadoop2这个节点去启动YARN
start-yarn.sh
注意:
- 以上步骤亲测有效,参考该步骤进行Hadoop集群的搭建时,涉及到的文件路径和环境变量请灵活调整。
- 本人也处于学习过程中,以上算是自己搭建Hadoop环境过程中做的笔记,在此分享给大家,仅供参考,若有没写明白的地方,可相互交流学习。
以上是关于Centos环境下从零部署Hadoop分布式集群的主要内容,如果未能解决你的问题,请参考以下文章