Redis数据库——Redis集群模式(主从复制哨兵Cluster)
Posted 小白的成功进阶之路
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Redis数据库——Redis集群模式(主从复制哨兵Cluster)相关的知识,希望对你有一定的参考价值。
Redis数据库(四)——Redis集群模式(主从复制、哨兵、Cluster)
一、Redis主从复制
- 通过持久化功能,redis保证了即使在服务器重启的情况下也不会丢失(或少量丢失)数据,因为持久化会把内存中的数据保存到硬盘上,重启会从硬盘上加载数据,但是由于数据是存儲在一台服务器上的,如果这台服务器出现硬盘故障等问题,也会导致数据丢失。
- 为了避免单点故障,通常的做法是将数据库复制多个副本以部署在不同的服务器上,这样即使有一台服务器出现故障,其他服务器依然可以继续提供服务,为此, redis提供了复制(replication)功能,可以实现当一台数据库中的数据更新后,自动将更新的数据同步到其他数据库上。
- 在复制的概念中,数据库分为两类,一类是主数据库(master) ,另一类是从数据(slave) 。主数据可以进行读写操作,当写操作导致数据变化时会自动将数据同步给从数据库,而从数据库一般是只读的,并接受主数据同步过来的数据。一个主数据库可以拥有多个从数据库,而一个从数据库只能拥有一个主数据库。
1、主从复制流程

-
【1】若启动一个slave机器进程,则它会向master机器发送一个“sync command”命令,请求同步连接
-
【2】无论是第一次连接还是重新连接,master机器都会启动一个后台进程,将数据快照(RDB)保存到数据文件中(执行RDB操作),同时master还会记录修改数据的所有命令,并缓存在数据文件中
-
【3】后台进程完成缓存操作后,master机器就会向slave机器发送数据文件,slave端机器将数据文件保存在硬盘上,然后将其加载到内存中,接着master机器就会将修改数据的所有操作一并发送给slave端机器。若slave出现故障导致宕机,则恢复正常后会自动重新连接
-
【4】master机器收到slave端机器的连接后,将其完整的数据文件发送给slave端机器,如果master同时收到多个slave发来的同步请求,则master会在后台启动一个进程以保存数据文件,然后将其发送给所有的slave端机器,确保所有的slave端机器都正常工作
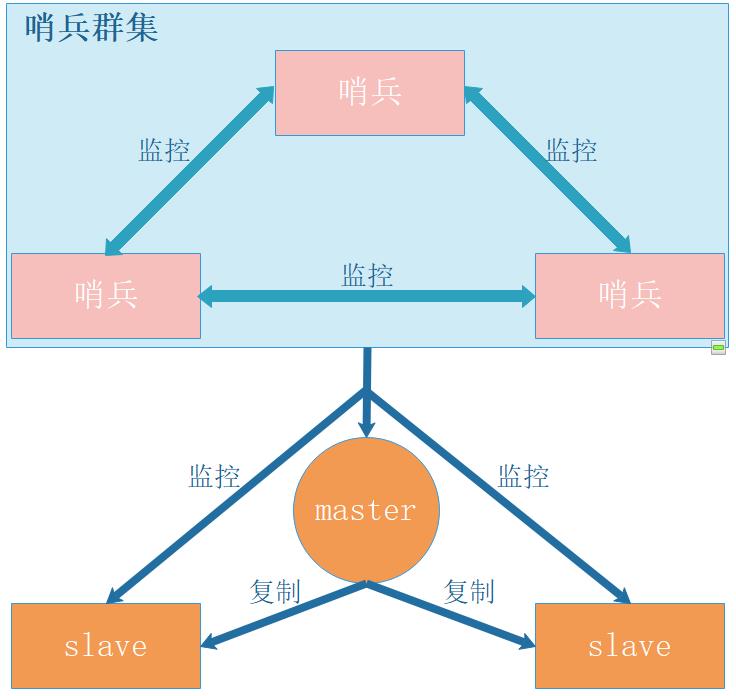
二、哨兵模式
1、哨兵模式集群架构
- 哨兵是Redis集群架构中非常重要的一个组件,哨兵的出现主要是解决了主从复制出现故障时需要认为干预的问题
2、哨兵模式主要功能
- 【1】集群监控:负责监控 Redis master 和 slave 进程是否正常工作
- 【2】消息通知:如果某个 Redis 实例出现故障,那么哨兵负责发送消息作为报警通知给管理员
- 【3】故障转移:如果 master node 挂掉了,会自动转移到 slave node 上
- 【4】配置中心:如果故障转移发生了,通知 client 客户端习新的 master 地址
3、哨兵监控整个系统节点的过程
- 【1】首先主节点的信息是配置在哨兵的配置文件中
- 【2】哨兵节点会和配置的主节点建立起两条连接命令连接和订阅连接
- 【3】哨兵会通过命令连接每10s发送一次INFO命令,通过INFO命令,主节点会返回自己的run_id 和自己的从节点信息
- 【4】哨兵会对这些从节点也建立两条连接命令连接和订阅连接
- 【5】哨兵通过命令连接向从节点发送INFO命令,获取到他的一些信息:
- run_id(redis服务器id)
- role(职能)
- 从服务器的复制偏移量 offset
- 其他
- 【6】通过命令连接向服务器的 _sentinel:hello 频道发送一条消息,包括自己的ip端口、run_id、配置(后续投票的时候会用到)等
- 【7】通过订阅连接对服务器的 _sentinel:hello 频道做监听,所以所有的向该频道发送的哨兵消息都能被接收到
- 【8】解析监听到的消息,进行分析提取,就可以知道还有哪些别的哨兵服务节点也在监听这些主从节点了,更新结构体将这些哨兵节点记录下来
- 【9】向观察到的其他的哨兵节点建立命令连接
4、主观下线
- 哨兵节点会每秒一次的频率向建立了命令节点的实例发送ping命令,如果在 down-after-milliseconds 毫秒内没有做出有效响应包括(pong/loading/masterdown)以外的响应,哨兵就会将该实例在本结构体中的状态标记为 sri_s_down 主观下线
5、客观下线
- 当一个哨兵节点发现主节点处于主观下线状态时,就会向其他的哨兵节点发出询问,该节点是否已经主观下线。如果超过配置参数 quorum 个节点认为是主观下线时,该哨兵节点就会将自己维护的结构体中该主节点标记为 sri_o_down 客观下线
6、master 选举
- 在认为主节点客观下线的情况下,哨兵节点间会发起一次选举,命令为: SENTINEL is-master-down-by-addr,只是 run_id 这次会将自己的 run_id 带进去,希望接受者将自己设置为主节点。如果超过半数以上的节点返回将该节点标记为 leader 的情况下,会有该 leader 对故障进行迁移
7、故障迁移
- 【1】在从节点中挑选出新的从节点
- 通讯正常
- 优先级排序
- 优先级相同时选择offset最大的
- 【2】将该节点设置成新的主节点 slaveof no one ,并确保在后续的 INGO 命令时,该节点返回状态为 master
- 【3】将其他的从节点设置成从新的主节点服务, slaveof 命令
- 【4】将旧的主节点变成新的主节点的从节点
8、优点与缺点
- 【优点】:高可用,哨兵模式是基于主从模式的,所有主从模式的优点,哨兵模式都有;主从可以自动切换,系统更健壮,可用性更高
- 【缺点】:redis 比较难支持在线扩容,在群集容量达到上限时在线扩容会变得很复杂
三、Cluster群集
- redis的哨兵模式基本已经可以实现高可用、读写分离,但是在这种模式,每台redis服务器都存储相同的数据,很浪费内存资源,所以加入了 Cluster 群集模式,实现了redis的分布式存储,也就是说,每台redis节点存储着不同的内容
- 群集部署建议至少3台以上的master节点,建议使用3主3从六个节点的模式
- Cluster 群集由多个redis服务器组成的分布式网络服务群集,群集中有多个master主节点,每个主节点都可读可写,节点之间会互相通信,两两相连,redis群集无中心节点
【1】在 redis-Cluster 群集中,可以给每个主节点添加从节点,主节点和从节点直接遵循主从模型的特性,当用户需要处理更多读请求的时候,添加从节点可以扩展系统的读性能
【2】redis-Cluster 的故障转移:redis群集的主节点内置了类似 redis sentinel 的节点故障检测和自动故障转移功能,当群集中的某个主节点下线时,群集中的其他在线主节点会注意到这点,并且对已经下线的主节点进行故障转移
【3】群集进行故障转移的方法和 redis sentinel 进行故障转移的方法基本一样,不同的是,在集群里面,故障转移是由集群中其他在线的主节点复制进行的,所以群集不必另外使用 redis sentinel
四、实验一(主从复制)
| 主机 | IP地址 | 软件 / 安装包 / 工具 |
|---|---|---|
| Master | 192.168.184.10 | redis-5.0.7.tar.gz |
| Slave1 | 192.168.184.30 | redis-5.0.7.tar.gz |
| Slave2 | 192.168.184.50 | redis-5.0.7.tar.gz |
#关闭防火墙和核心防护
systemctl stop firewalld
systemctl disable firewalld
setenforce 0
#进行redis的安装(所有主机都需要安装)
yum install -y gcc gcc-c++ make
cd /opt
tar zxvf redis-5.0.7.tar.gz
cd /opt/redis-5.0.7/
make -j 2 && make PREFIX=/usr/local/redis install
cd /opt/redis-5.0.7/utils
./install_server.sh
Please select the redis executable path [/usr/local/bin/redis-server] /usr/local/redis/bin/redis-server
ln -s /usr/local/redis/bin/* /usr/local/bin/
#Master节点(192.168.184.10):
vim /etc/redis/6379.conf
bind 0.0.0.0 #70行,修改bind 项,0.0.0.0监听所有网段
daemonize yes #137行,开启守护进程
logfile /var/log/redis_6379.log #172行,指定日志文件目录
dir /var/lib/redis/6379 #264行,指定工作目录
appendonly yes #700行,开启AOF持久化功能
/etc/init.d/redis_6379 restart #重启redis服务
#slaves节点(192.168.184.30、192.168.184.50):
vim /etc/redis/6379.conf
bind 0.0.0.0 #70行,修改bind 项,0.0.0.0监听所有网卡
daemonize yes #137行,开启守护进程
logfile /var/log/redis_6379.log #172行,指定日志文件目录
dir /var/lib/redis/6379 #264行,指定工作目录
replicaof 192.168.184.10 6379 #288行,指定要同步的Master节点IP和端口
appendonly yes #700行,开启AOF持久化功能
/etc/init.d/redis_6379 restart
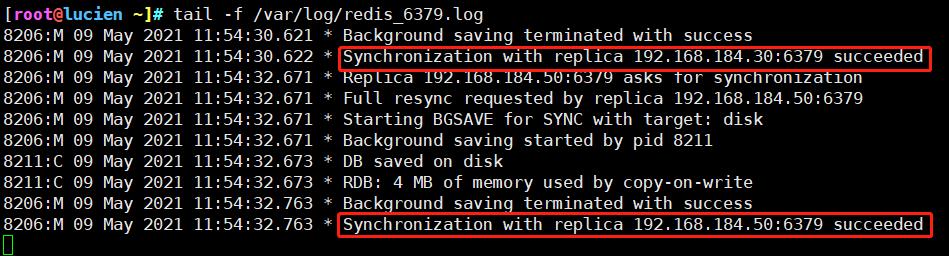
#进行主从复制验证
tail -f /var/log/redis_6379.log #查看master节点日志
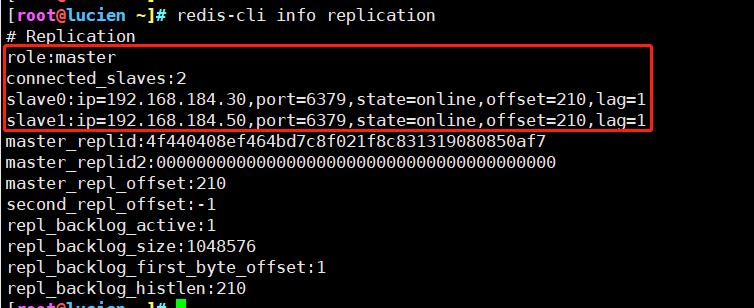
redis-cli info replication #master上验证从节点
五、实验二(哨兵模式)
- 哨兵的核心功能:在主从复制的基础上,哨兵引入了主节点的自动故障转移
- 哨兵:是一个分布式系统,用于对主从结构中的每台服务器进行监控,当出现故障时通过投票机制选择新的 master 并将所有 slave 连接到新的 master 。所以整个运行哨兵的集群的数量不得少于3个节点。
#修改配置文件(所有节点)
vim /opt/redis-5.0.7/sentinel.conf
protected-mode no #17行,关闭保护模式
port 26379 #21行,Redis哨兵默认的监听端口
daemonize yes #26行,指定sentinel为后台启动
logfile "/var/log/sentinel.log" #36行,指定日志存放路径
dir "/var/lib/redis/6379" #65行,指定数据库存放路径
sentinel monitor mymaster 192.168.184.10 6379 2 #84行,修改 指定该哨兵节点监控192.168.184.10:6379这个主节点,该主节点的名称是mymaster,最后的2的含义与主节点的故障判定有关:至少需要2个哨兵节点同意,才能判定主节点故障并进行故障转移
sentinel down-after-milliseconds mymaster 30000 #113行,判定服务器down掉的时间周期,默认30000毫秒(30秒)
sentinel failover-timeout mymaster 180000 #146行,故障节点的最大超时时间为180000(180秒)
#启动哨兵模式
redis-sentinel /opt/redis-5.0.7/sentinel.conf & #先启动master,再启动slave
#查看哨兵信息
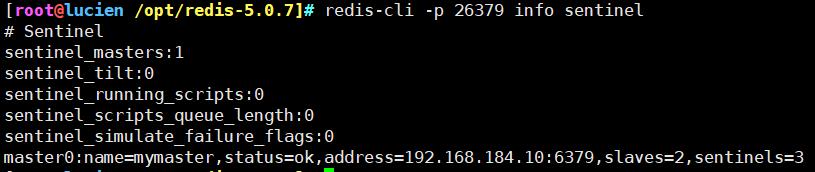
redis-cli -p 26379 info sentinel
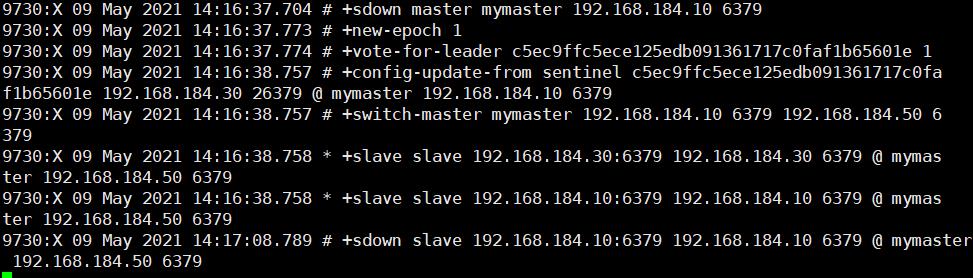
#模拟故障
netstat -natp | grep redis
kill -9 redis的进程
#查看哨兵的信息
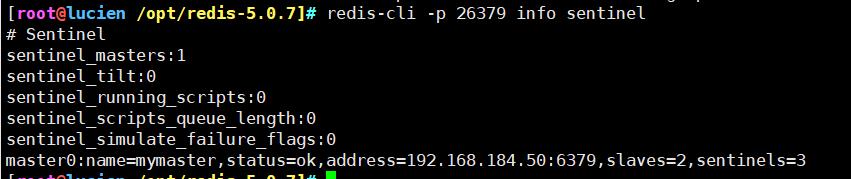
redis-cli -p 26379 info sentinel
#查看日志
tail -f /var/log/sentinel.log



六、实验三(Cluster群集)
| 主机 | IP:端口 | 软件/安装包/工具 |
|---|---|---|
| Master1 | 192.168.184.10:7001 | redis-5.0.7.tar.gz |
| Slave1 | 192.168.184.60:7006 | redis-5.0.7.tar.gz |
| Master2 | 192.168.184.30:7003 | redis-5.0.7.tar.gz |
| Slave2 | 192.168.184.70:7007 | redis-5.0.7.tar.gz |
| Master3 | 192.168.184.50:7005 | redis-5.0.7.tar.gz |
| Slave3 | 192.168.184.80:7008 | redis-5.0.7.tar.gz |
#其他5个文件夹的配置文件以此类推修改,注意6个端口和IP都要不一样。
vim /etc/redis/6379.conf
bind 192.168.184.10 #70行,修改bind项,监听自己的IP
protected-mode no #89行,修改,关闭保护模式
port 7001 #93行,修改,redis监听端口,
daemonize yes #137行,以独立进程启动
cluster-enabled yes #833行,取消注释,开启群集功能
cluster-config-file nodes-6379.conf #841行,取消注释,群集名称文件设置,无需修改
cluster-node-timeout 15000 #847行,取消注释群集超时时间设置
appendonly yes #700行,修改,开启AOF持久化
#重启服务
/etc/init.d/redis_6379 restart
#加入集群
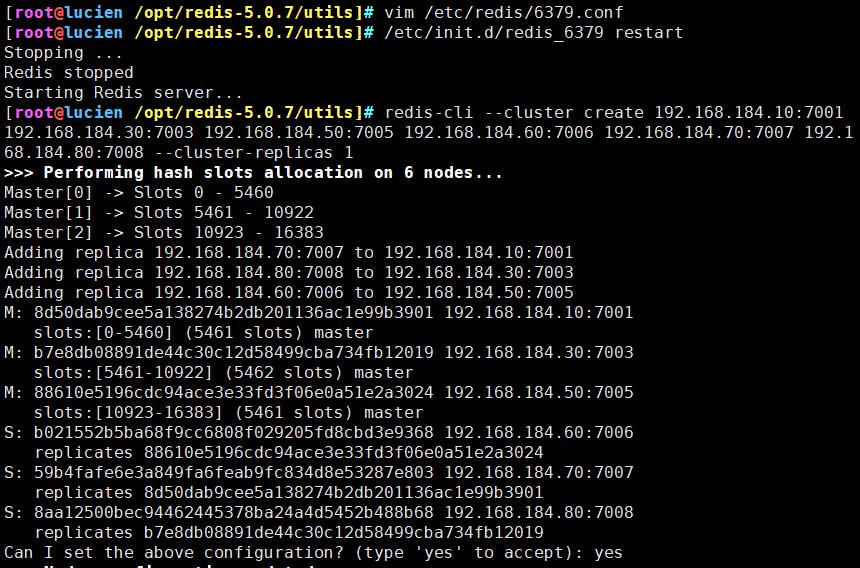
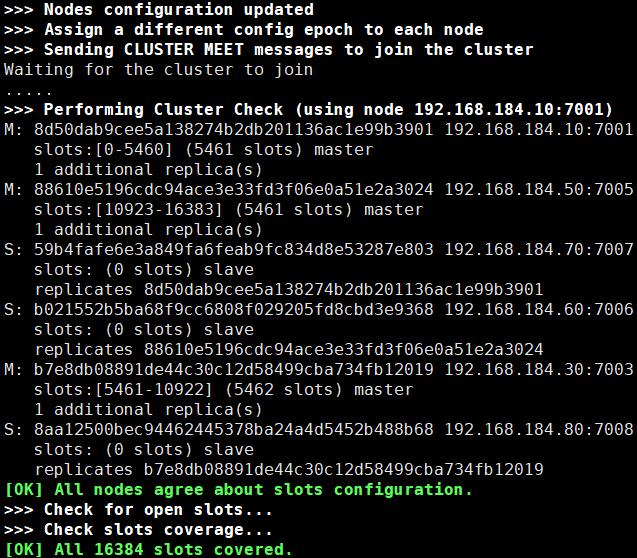
redis-cli --cluster create 192.168.184.10:7001 192.168.184.30:7003 192.168.184.50:7005 192.168.184.60:7006 192.168.184.70:7007 192.168.184.80:7008 --cluster-replicas 1
redis-cli -h 192.168.184.10 -p 7001 -c #加-c参数,节点之间就可以互相跳转
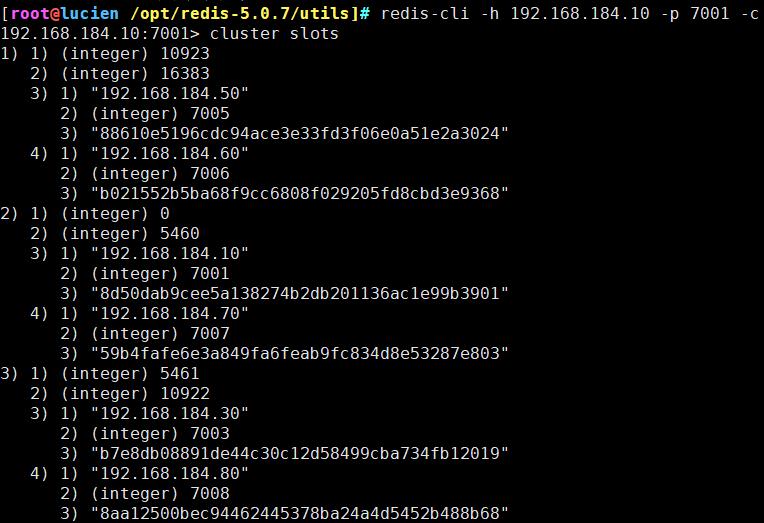
cluster slots #查看节点的哈希槽编号范围
set sky blue
cluster keyslot sky #查看name键的槽编号
总结
主从复制流程
- 【1】slave向master机器发送“sync command”命令,请求同步连接
- 【2】master通过fork启动子进程,将数据快照及缓存命令保存到数据文件中
- 【3】master向slave发送数据文件,slave保存到硬盘后加载到内存,接着master会将修改数据的所有操作一并发送给slave。若slave出现故障导致宕机,则恢复正常后会自动重新连接
- 【4】master收到slave的连接后,将完整的数据文件发送给slave,如果有多个同步请求,则master启动一个后台进程保存数据文件,然后发送给所有的slave
哨兵主要功能
- 【1】集群监控:负责监控 Redis master 和 slave 进程是否正常工作
- 【2】消息通知:如果某个 Redis 实例出现故障,那么哨兵负责发送消息作为报警通知给管理员
- 【3】故障转移:如果 master node 挂掉了,会自动转移到 slave node 上
- 【4】配置中心:如果故障转移发生了,通知 client 客户端习新的 master 地址
Cluster群集的功能
- 【】数据分区:数据分区(或称数据分片)是集群最核心的功能。
- 集群将数据分散到多个节点,一方面突破了Redis单机内存大小的限制,存储容量大大增加;另一方面每个主节点都可以对外提供读服务和写服务,大大提高了集群的响应能力。
- Redis单机内存大小受限问题,在介绍持久化和主从复制时都有提及;例如,如果单机内存太大,bgsave和bgrewriteaof的fork操作可能导致主进程阻塞,主从环境下主机切换时可能导致从节点长时间无法提供服务,全量复制阶段主节点的复制缓冲区可能溢出。
- 【】高可用:集群支持主从复制和主节点的自动故障转移(与哨兵类似);当任一节点发生故障时,集群仍然可以对外提供服务。
以上是关于Redis数据库——Redis集群模式(主从复制哨兵Cluster)的主要内容,如果未能解决你的问题,请参考以下文章