数据仓库设计
Posted Xiao Miao
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据仓库设计相关的知识,希望对你有一定的参考价值。
文章目录
数据仓库设计
一、数据仓库的功能和应用场景
1.OLTP:联机事务处理
场景:为了满足公司买卖的业务场景,而给用户提供了注册、登记、订单等功能,为了实现这些功能而存储了数据
数据的使用者:用户
特点
业务数据管理和存储
读写速度:快
满足事务性的需求
数据量相对较小
工具
一般选用关系型数据库来实现:mysql、Oracle
2.OLAP:联机分析处理
场景:为了满足运营决策的需求,将公司各种各样的数据,实现数据分析的管理
数据的使用者:运营、运维、领导层、数据分析师
特点
读写速度要求:按照一定时间周期进行处理,每个小时,每天,离线数据仓库:T+1
数据量:非常庞大
事务性的需求:不需要
工具
一般使用专业数据仓库工具来实现:Hive、GreepNum
3.数据仓库功能
功能
为了满足OLAP场景下的数据管理需求
存储:实现各种数据统一化的存储
处理:将各种原始数据进行规范化的处理,提供给各个需求方
本质
是一种分布式、统一化的、规范化的数据管理的设计模型
4.数据仓库应用
应用场景:满足企业中所有数据的统一化存储,通过规范化的数据处理来实现企业的数据分析应用
二、数据仓库的特点
数据仓库的核心特点
1.面向主题
按照主题划分的应用需求
数据库:面向业务的
人事部门:人事管理系统:人事数据库中
在职人员信息
离职人员信息
财务部门:财务管理系统:财务数据库中
支持数据表
收入数据表
盈利数据表
为了满足不同的业务,讲不同的数据放在不同的应用系统中
数据仓库:面向主题的
数据仓库:公司中所有的数据全部通过数据采集或者数据同步进入数据仓库【超市 = 所有数据】
数据集市/主题域:一般都是按照部门划分【商品类别=数据类别】
- 销售数据集市
- 财务数据集市
- 人事数据集市
- 运维数据集市
- 运营数据集市
数据主题:各个应用对应的主题【商品细分 = 应用类别】
订单主题
收入主题、支出主题、税务主题
在职人员主题、离职人员主题
应用日志主题、机器日志主题
来源分析主题、用户分析主题……
2.数据集成
存储整个公司所有数据,为公司所有数据的需求方提供数据
数据仓库本身不产生数据,也不使用数据
数据仓库会将整个公司采集到的所有数据源的数据进行存储,提供给各个数据的应用方
3.非易失/稳定性
按照数据仓库的业务需求,没有更新和删除的业务
更新:没有,如果修改了数据,修改了数据的真实性,分析的结果就不对了
删除:没有,工作中会出现删除老的历史数据,不会删除使用的数据
4.时变性/动态性
数据仓库中会按照时间记录时间发生变化的数据状态
数据仓库中的数据随着时间的变化会不断增加
变化状态:增加
三、数据仓库的核心流程
1.ETL
1.1功能
Extract、Transform、Load:抽取、转换、加载,将原始数据根据需求进行处理,将处理好的数据再写入HDFS
1.2阶段:两个阶段
数据生成
数据采集
采集:采集后的数据放在HDFS上
/nginx/log/source/2021-05-09/20210509.log
数据不一定是标准的结构化格式
ETL:过滤、补全、转换
/nginx/log/etl/2021-05-09/20210509.log
通过代码进行开发:MapReduce、SparkCore
入库:将ETL以后的每一天的数据作为Hive表的一个分区
数据存储
ETL场景:数据本身就是结构化的,直接加载到Hive表中
实现:通过SQL来实现ETL
数据计算
数据应用
1.3实现
过滤、转换、补全
过滤:将不需要的数据,或者非法的数据进行过滤
数据中有10个字段,发现一条数据只有1个字段
数据中重要的字段丢失:ip/userid/sessionId
转换:将原始数据格式变成我们想要的数据格式
解密:数据本来采集的时候是加密的,ETL时候实现解密操作
格式:18/Aug/2021:19:30:00 =》 2021-08-18 19:30:00
补全:需要使用的数据,但是原始数据中没有
通过解析IP地址:得到用户所在的位置:国家、省份、城市
通过时间信息:补全年、月、日、周、季度
2.分层
功能:规定数据在数据仓库中处理的步骤
实现:每一层就是一个数据库,不同层的数据表在不同的数据库中
3.建模
功能:决定了数据表如何构建
实现:ER建模、维度建模等
四、指标设计
指标的概念:对数据统计分析得到的结果,就是指标,也成为指数,指标是通过数值来体现的
功能:通过指标来衡量事实的结果,反应事实的好坏
大数据分析的目的:发现产品公司或者平台存在的问题,解决问题
指标:通过指标来发现问题
常见基础指标
每个行业的需求不同,指标也不同
PV:page view,用于反映网页的访问量
字段:url
统计:count(url)
UV:unnique view:用于反映网站的用户访问量
字段:访客id,userid,uuid,guid
访客id:只要访问了,就有这个给id,统计UV:统计访问人数
会员id:登陆了,就有会员id,统计登陆人数
会话id:与服务端构建了连接,服务端会分配session id
计算:count(distinct userid)
IP:用于反应用户ip的个数,ip可以反映用户群体的分布
字段:ip
计算:count(distinct ip)
跳出率:只访问了一个页面的会话个数/总的会话个数
字段:sessionld
计算:pv等于1的session个数count(case pv=1 else sessionid else null)/总的会话个数count(distinct sessionid)
越低代表用户粘性越高,平台的运营越好
二跳率:代表了两个页面及以上的会话个数/总的会话个数
字段:sessionid
计算:pv等于1的session个数count(case pv>1 else sessionid else null)/总的会话个数count(distinct sessionid)
平均访问时常:总的session访问时常/总的session个数
字段:time,sessionid
计算:sum(访问最后一个页面的时间 - 访问第一个页面时间)/count(distinct sessionid)
五、维度设计
1.维度的概念:
用于描述事实的角度
用于细化对指标时事的分析,更加精确发现对应的问题
大数据分析目的:发现问题,调整方案,支撑运营和决策
指标:UV:100
描述:昨天的UV是1000,今天的UV是100
结果:是不好的,因为基于维度做了对比
指标如果不基于组合维度进行分析得到,这个指标是没有意义的
昨天的UV是1000,今天的UV是100
基于多个组合维度看
地区维度
昨天的1000,是10个地区的结果,每个地区都有100
今天的100,是一个地区的结果,这个地区有100个uv
2.维度的功能
基于组合更加细化我们的指标,来更加精确的发现问题
问题:去年营业额2000万,今年营业额2000万[基于时间年维度]
目的:问什么今年营业额没有增长?
实现:发现问题
校区的问题
去年每个校区都是100万
统计今年每个校区的营业额[基于时间年+学科]
是否有个别校区拖后腿,其他小区都在增长,而这个校区降低了
学科的问题
统计今年每个学科的营业额[基于时间年+学科]
每个月对应的营业额
3.常见维度
时间维度:年、季度、月、周、天、小时
地区维度:国家、省份、城市
平台维度:网站、APP、小程序、H5
操作系统维度
校区维度
学科维度
4.下钻与上卷
下钻:当前我们的分析是基于一个大的维度进行分析,要下钻到一个更细的维度进行分析
先按年分析
然后按小时分析
上卷:当前我们的分析是基于一个小的维度的进行分析,要上卷到一个大的颗粒维度来进行分析
先按每个小时分析
先按每个小时分析
然后按照每天分析
六、建模:ER模型
1.ER模型的应用
关系实体模型
一般应用于OLTP的关系型数据库系统来实现业务数据库的建模,实现满足业务的数据存储
思想:实现业务存储、通过外键构建数据关联关系、避免冗余存储,记录事件的产生
2.ER模型的构建
step1:找到所有实体,以及每个实体的属性
step2:找到所有实体之间的关系
step3:建表,每个实体与每个关系都是一张表
角色
实体、属性、关系
举个栗子
小明在商店买了一双800块的鞋
实体
小明:用户实体
用户id 用户name 用户age 手机 密码
商品:店铺实体
店铺id 店铺名称 营业执照 经营范围 地址
鞋:商品实体
商品id 店铺名称 尺寸 颜色 价格
关系
订单:实体之间的购买关系
订单id 用户id 店铺id 商品id 订单价格 支付方式
建表
实体:用户、商品、店铺
关系:订单
优点:
符合数据库的设计规范,没有冗余数据,保证性能,业务的需求把握的比较全面
缺点:
设计时候非常复杂,必须找到所有实体和关系,才能构建
七、建模:维度模型
1.维度模型的应用
一般应用于大数据的数据仓库的模型构建,用于通过不同维度来反映事情的好坏
2.维度模型的构建
角色
维度:基于不同维度下的指标的结果,看待指标的角度
事实:就是通过指标来反映事实
流程
构建所有维度
基于维度分析事实
举个栗子
小明在商店买了一双800块
维度
小明:用户维度
商店:店铺维度
鞋:商品维度
事实:指标[数值]
一双:衡量多少
800块:衡量贵或者便宜
维度表
一个维度可以有一张表,也可以有多张表
事实表
多个事实放在一张表中
时间维度 地区维度 平台维度 UV PV IP 跳出率 二跳律
什么是维度模型?
基于不同维度实现统计分析各种指标事实,用于描述事实的结果
八、事实表
1.事实指标值的分类
1.1可加类型
基于不同的维度和统计可以直接进行累加的值
举个栗子:PV
统计这个月每天的PV
累加每天的PV,统计这个月的PV
2.半可加类型
在有一些维度下可以累加,在有一些维度下不可以累加
举栗:银行余额
可以累加:账户维度
不可累加:时间
3.不可加类型:在任何维度下,指标的累加是没有意义的
举例:比例类型
不建议产生空值,事实表中是不会出现空值
即使指标没有结果,也为0
2.事实表的分类
2.1事务事实表
原始的事务数据,业务数据
例如:订单信息表:记录每一条订单事实的信息
时间 订单id 商品id 订单价格
2021-01-01 12:00:00
2021-01-01 12:00:01
2.2周期快照事实表
基于事务事实表按照一定的周期进行聚合
例如:订单统计表:统计每天的订单总个数和订单总金额
天 订单总数 订单总金额
2020-01-01 1000 2000
大数据就是统计分析的结果表
2.3累积快照事实表
事实的结果随着时间的变化而不断完善
例如:订单状态表
订单id 提交成功 支付成功 发货状态 收货状态 退货状态
order001 12:00:00 12:00:00
2.4无事实事实表
特殊的事实表,无事实的事实表中没有度量值,只有多个维度外键,一般用于业务维度关联
举例:可以统计分析哪些商品销售的比较好,商品销售量,销售总金额
需求:哪些商品今天没有卖出
无状态事实表中:记录所有上架的商品信息
所有商品id
今天 商品id
订单事实表:记录所有被销售的商品信息
订单中的商品id
今天 订单id 商品id
九、维度表
1.雪花模型
雪花模型的结构
维度模型构建的方式:决定了维度表与事实表怎么关联
雪花模型:如果对于一个维度,它有子维度,将子维度关联在父维度上的
优点:减少数据冗余存储
缺点:每一次要想获取具体的数据,必须关联每一张子表,性能比较差
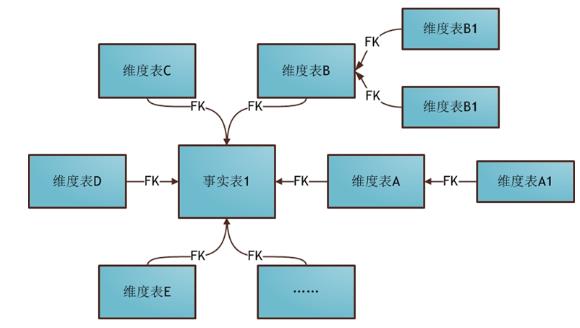 雪花模型的构建
雪花模型的构建
时间维度
事实表
时间维度 地区维度 平台维度 UV IP PV
时间维度:B
时间维度id year:外键 month:外键 day :外键
1 1 1 1
4 19 -1 -1
年维度表
yearid yearvalue
1 2000
……
10 2009
……
100 2099
2.星型/星座模型
星型模型的设计
所有维度表直接关联事实表
优点
每次查询时候,直接获取对应的数据结果,不用关联其他的维度子表,可以提高性能
缺点
数据冗余度比较高
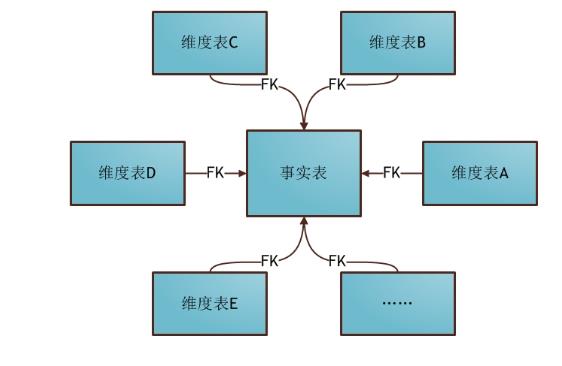
星型模型的构建
时间维度表
时间维度id year month day type
1 2020 01 01 day
2 2020 01 02 day
……
4 2020 1 -1 month
4 2020 -1 -1 year
地区维度表
地区维度id 国家 省份 城市 类型
1 中国 上海 浦东 市
2 中国 上海 徐汇 市
……
10 中国 上海 -1 省
11 中国 -1 -1 国
需求:统计基于基于时间维度下以及地区维度下的PV、UV、IP
事实表
时间维度id 地区维度id PV UV IP
1 1 10 1 1
4 -1 1000 100 20
星座模型
星座模型:基于星型模型的演变,多个事实共同同一个维度表
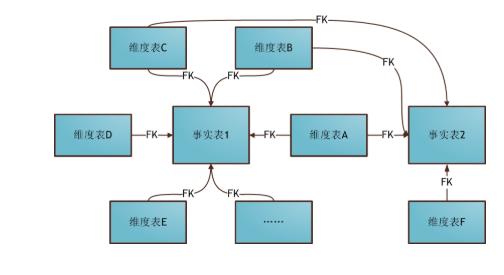
十、渐变维度
渐变维度问题
维度数据发生变化,如何处理发生变化的数据
举例
每个用户会对应一个工作地区,2019年在北京

2020搬到了三亚

现在是2020年,需要对2019年的北京的数据进行统计,这条数据是否参与统计?
如果参与统计,数据是如何存储的?
处理方案
SCD1:通过更新维度记录直接覆盖已存在的值
当2020年对2019年对北京进行统计的时候,按照覆盖的机制,这个人没有北京的记录,不会被统计,结果不准确
SCD2:构建拉链表,根据不同的时间来标记这一列不同的状态
记录这个用户的所有状态的变化
| 用户id | 所在的地区 | 时间标记:start | 时间标记:end |
|---|---|---|---|
| 1001 | beijing | 2018-01-01 | 2020-01-01 |
| 1001 | sanya | 2020-01-01 | 2021-01-01 |
| 1001 | meiguo | 2021-01-01 | 9999-12-31 |
工作中的需求是可以指定日期查询对应的状态
where starttime< 2019 and end > 2019
默认应该处理最新的状态:通过9999-12-31,来标记这是最新的状态
where endtime = 9999-12-31
SCD3:通过增加列的方式来记录每个状态
| 用户id | 工作城市1 | 工作城市2 |
|---|---|---|
| 10001 | beijing | sanya |
不能满足需求,一般不用
十一、分层
目的:
决定数据在数据仓库中处理的流程
实现:
每一层在HIve中就是一个数据库而言,每一层的表放在对应的数据库中
原始数据层
名称:ODS层,原始数据层或者操作数据层
功能:用于存储最原始的数据
数据仓库层
名称:DW层
数据应用层
名称:DA/APP/ADS,存储最终要被使用的数据的
功能:存储结果
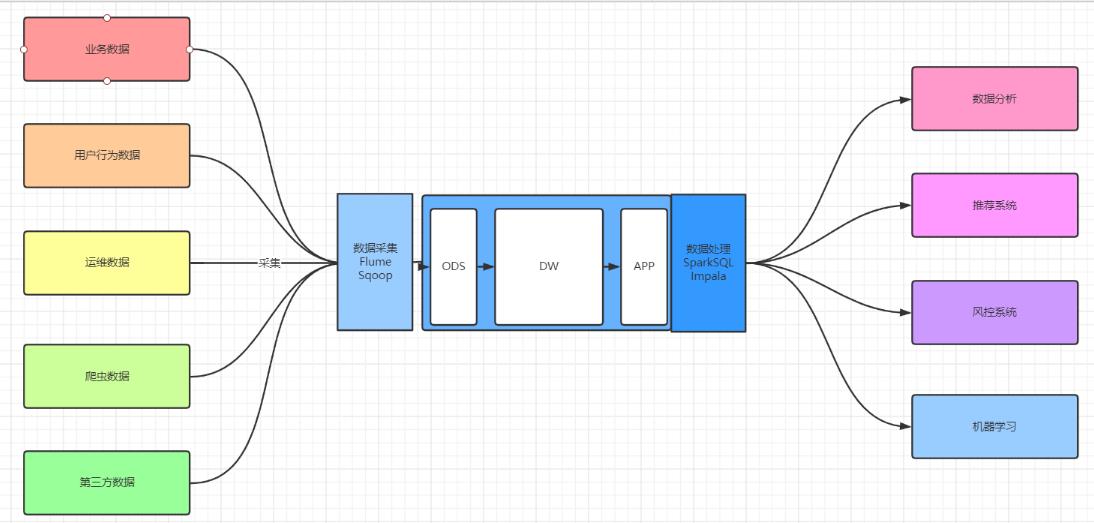
十二、常见层次
实施
每个公司的分层都不一样,常见的层次要记住功能
ODS:原始数据层
专门用于存储原始数据,数据与原始业务数据是一致的
DWD层:详细数据层
一般用于将ODS的结果进行ETL处理,存储在DWD层中
DWM:中间数据层
用于对DWD层的数据进行轻量级的通用性的处理和聚合的
一般看业务,如果简单的业务,一般不需要DWM层
DWS/DM:汇总数据层/数据集市层
用于实现最终的所有维度的指标的聚合分析,不同的部门需要的数据进行单独的划分
APP/DA/ADS:数据应用层
应用存储最后的应用结果
DIM:维度数据层
用于存储维度表的数据
有的公司的维度表放在数据仓库Hive中,有的公司的维度表是在MySQL中
TMP:临时数据层
一般用于存储一些临时数据表
十三、分层案例
电商案例:

斗鱼案例:
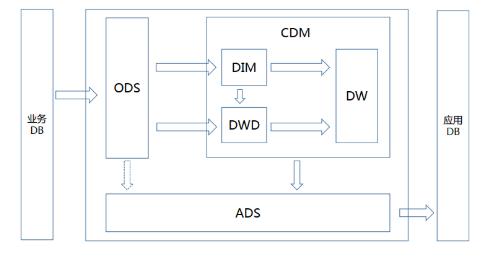
以上是关于数据仓库设计的主要内容,如果未能解决你的问题,请参考以下文章
Express实战 - 应用案例- realworld-API - 路由设计 - mongoose - 数据验证 - 密码加密 - 登录接口 - 身份认证 - token - 增删改查API(代码片段
基于SpringBoot的仓库管理系统-仓库管理系统毕业设计-库存管理系统代码
整理最全规范之Git仓库管理规范,Java开发规范,最全Java命名规范,数据库开发设计规范,接口设计规范