今天带你们用python爬虫,爬取最新更新的小说网站
Posted 不加班的程序员丶
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了今天带你们用python爬虫,爬取最新更新的小说网站相关的知识,希望对你有一定的参考价值。

百度搜索请求
我们通过百度网页的搜索框进行搜索时,提交的url请求是这样的:
https://www.baidu.com/s?wd=搜索词&pn=10&rn=50
请求的url为https://www.baidu.com/s,带三个参数:
-
wd:搜索的关键词
-
pn:当前需要显示搜索结果记录在总搜索结果的序号,如总搜索有300条记录满足要求,现在要求显示第130条记录,则pn参数值设为130即可
-
rn:每页显示记录数,缺省为10条,可以自行设定,但如果设定超过50,则会强制显示为每页10条。
百度返回搜索结果
百度返回的搜索结果有多种方式确定,老猿认为如下方式最简单:
以搜索小说《青萍》为例来看其中的一个返回记录:
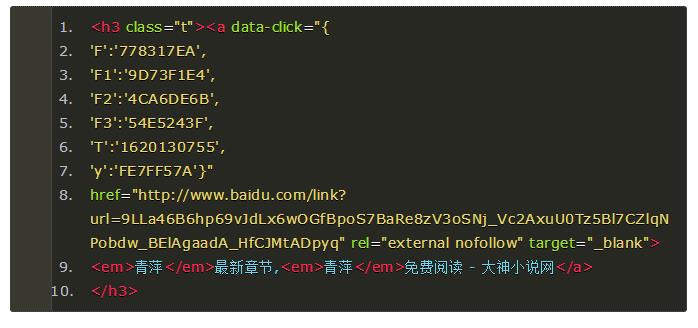
整个搜索返回的结果在一个h3的标签内,返回的搜索结果对应url在a标签内,具体url由href来指定。这里返回的url实际上是一个百度重定向的地址,可以通过打开该url访问对应网站,并通过返回响应消息获取真正网站的URL。
小说网站关于最新更新的展现及html报文格式
根据老猿分析,约占30%的小说网站关于最新更新章节的展现类似如下:

首先有类似“最新章节”或“最新更新”或“最近更新”等类似提示词,在该提示词后是显示最新章节的章节序号及章节名的一个链接,对应的报文类似如下:
这个报文的特点是:
“最新章节”的文本信息与小说最新章节的链接在同一个父标签内。另外需要说明的是返回的章节url并不是绝对地址,而是小说网站的相对地址。
老猿对搜索小说查找最新章节都是基于以上格式的,因此实际上程序最终获取的小说网站只占了整个搜索结果的30%左右,不过对于看小说来说已经足够了。
实现思路及代码
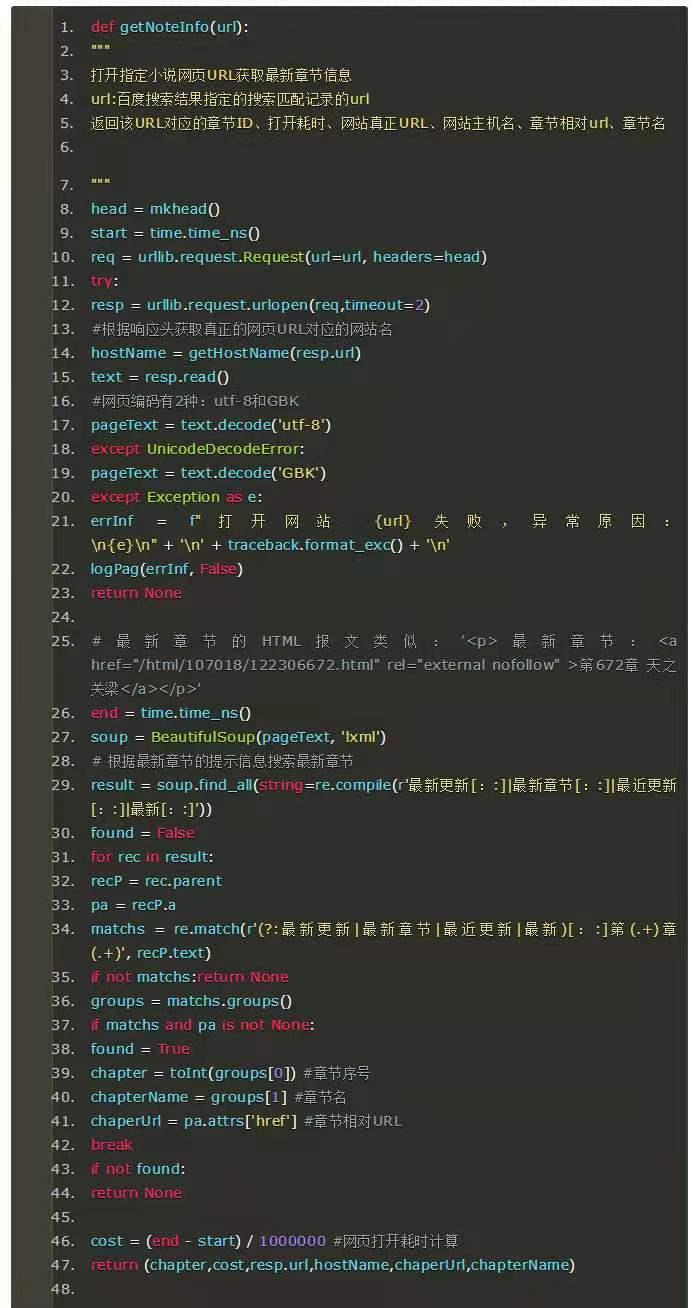
根据url获取网站名

根据百度返回搜索结果地址打开网站获取小说信息
基于2.3部分介绍的小说网站返回内容,我们来根据百度返回搜索结果的URL来打开对应小说网站,并计算从请求发起到响应返回的时间:
搜索案例
以搜索月关大大的青萍作为案例,执行搜索的语句为:![]()

使用Python搜索指定小说最新更新章节以及访问最快网站的实现思想和关键应用代码,实现自动搜索小说最新更新章节以及获取访问最快的网站。
以上的实现由于已经获取最新章节的链接,再稍微改进,就可以直接将最新章节下载到本地观看。
需要相关资料的资料的可以扫一扫【爬虫】

以上是关于今天带你们用python爬虫,爬取最新更新的小说网站的主要内容,如果未能解决你的问题,请参考以下文章