Python基础之爬虫:爬取小说,图片示例
Posted 岩枭
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python基础之爬虫:爬取小说,图片示例相关的知识,希望对你有一定的参考价值。
一、用python里面的beautifulsoup爬取网页中的小说
原来网页内容:http://www.jueshitangmen.info/tian-meng-bing-can-11.html
#爬虫
from bs4 import BeautifulSoup
from urllib.request import urlopen
html=urlopen('http://www.jueshitangmen.info/tian-meng-bing-can-11.html')\\
.read().decode('utf-8')
#print(html)
#print('***********************************************************************************************************************')
soup=BeautifulSoup(html,features='lxml')
#获取所有p标签
all_p=soup.find_all('p')
#print(all_p)
f=open('flie.txt','a',encoding='utf-8')
for i in all_p:
print('\\n',i.get_text())
f.write('\\n'+i.get_text())
f.close()
#获取所有a标签
all_a=soup.find_all('a')
f=open('flie_a.txt','a',encoding='utf-8')
for i in all_a:
print('\\n',i.get_text())
f.write('\\n'+i.get_text())
f.close()执行程序效果:
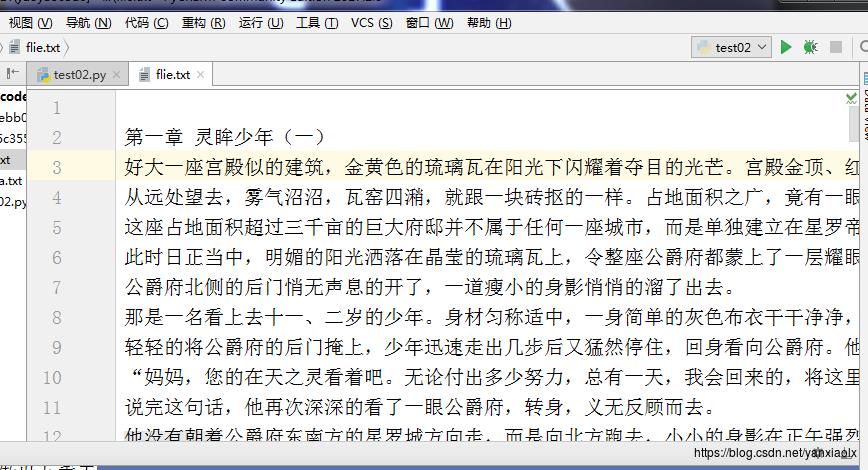
二、用python爬取图片,两种代码都可以成功爬取到图片信息:
代码一:
import urllib.request
import urllib.parse
import re
import os
#添加header,其中Referer是必须的,否则会返回403错误,User-Agent是必须的,这样才可以伪装成浏览器进行访问
#伪装成浏览器,防止反爬虫
header=\\
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.87 Safari/537.36',
"referer":"https://image.baidu.com"
url = "https://image.baidu.com/search/acjson?tn=resultjson_com&ipn=rj&ct=201326592&is=&fp=result&queryWord=word&cl=2&lm=-1&ie=utf-8&oe=utf-8&adpicid=&st=-1&z=&ic=0&word=word&s=&se=&tab=&width=&height=&face=0&istype=2&qc=&nc=1&fr=&cg=girl&pn=pageNum&rn=30&gsm=1e00000000001e&1490169411926="
keyword = input("请输入搜索关键词:")
#字符转码
keyword = urllib.parse.quote(keyword,"utf-8")
n = 0
j = 0
error = 0
while(n<3000):
n+=1
#url
url1 = url.format(word=keyword,pageNum=str(n))
#获取请求
rep = urllib.request.Request(url1,headers=header)
rep = urllib.request.urlopen(rep)
#读取网页内容
try:
html = rep.read().decode("utf-8")
except:
print("出错啦!")
error = 1
print("-------当前页面数:"+str(n))
if(error==1):continue
#正则匹配:需要的数据都是放在:("thumbURL": "https://ss2.bdstatic.com/70cFvnSh_Q1YnxGkpoWK1HF6hhy/it/u=1593875716,602632714&fm=27&gp=0.jpg")
p = re.compile("thumbURL.*?\\.jpg")
#获取匹配的结果
s = p.findall(html)
#图片存储路径
if os.path.isdir("D://pictest/图片") !=True:
os.makedirs(r"D://pictest/图片")
#获取图片的url
for i in s:
i = i.replace("thumbURL\\":\\"","")
print(i)
urllib.request.urlretrieve(i,"D://pictest/图片/picnum.jpg".format(num=j))
j+=1
print("总共爬取的图片数:"+str(j))
代码二:
import urllib.request
import urllib.parse
import re
import os
#添加header,其中Referer是必须的,否则会返回403错误,User-Agent是必须的,这样才可以伪装成浏览器进行访问
#伪装成浏览器,防止反爬虫
header=\\
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.87 Safari/537.36',
"referer":"https://image.baidu.com"
url = "https://image.baidu.com/search/acjson?tn=resultjson_com&ipn=rj&ct=201326592&is=&fp=result&queryWord=word&cl=2&lm=-1&ie=utf-8&oe=utf-8&adpicid=&st=-1&z=&ic=0&word=word&s=&se=&tab=&width=&height=&face=0&istype=2&qc=&nc=1&fr=&cg=girl&pn=pageNum&rn=30&gsm=1e00000000001e&1490169411926="
keyword=input('请输入搜索关键词:')
#字符转码
keyword=urllib.parse.quote(keyword,'utf-8')
n=0
j=0
error=0
while(n<3000):
n+=30
url1=url.format(word=keyword,pageNum=str(n))
#获取请求
rep=urllib.request.Request(url1,headers=header)
#打开网页
rep=urllib.request.urlopen(rep)
#读取网页内容
try:
html=rep.read().decode('utf-8')
except:
print('出错了')
error=1
print('出错页数:'+str(n))
if error==1:
continue
#正则匹配
p=re.compile('thumbURL.*?\\.jpg')
#获取正则匹配到的结果,返回list
s=p.findall(html)
if os.path.isdir('D://pic')!=True:
os.makedirs('D://pic')
with open('testPc.txt','a') as f:
#获取图片url
for i in s:
i=i.replace('thumbURL\\":\\"','')
print(i)
f.write(i)
f.write('\\n')
#保存图片到D://pic
urllib.request.urlretrieve(i,'D://pic/picnum.jpg'.format(num=j))
j+=1
f.close()
print('总共爬取图片数为:'+str(j))执行程序运行结果:

以上是关于Python基础之爬虫:爬取小说,图片示例的主要内容,如果未能解决你的问题,请参考以下文章