OpenCV与机器视觉
Posted lwlv
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了OpenCV与机器视觉相关的知识,希望对你有一定的参考价值。
最近在网易云课堂把南科大于仕琪团队的OpenCV教程完整看了一遍,对图像处理或者机器视觉又有了一个系统性的理解。OpenCV中文网站就是他创建的,他的研究团队及其相应成果可以在个人网站中查阅。回想过去在图像处理方面的点点滴滴,做了一个详细的梳理和总结。希望各路大侠能各抒已见,提出宝贵意见或建议,从而也能得到一些启发和感悟,便于更好得根植这个方向。
目录
1 初识图像处理
1.1 视频中的车流量统计
最开始接触图像处理应该是在2011年的华中地区大学生数学建模上。当时有道题很有意思,给了一段约5分钟的道路交通视频,然后要求我们用数学模型统计视频中的车流量。说高大上一点就是用数据通讯传输技术、电子控制技术、计算机处理技术等方法实现对视频的分析与处理,提取关键信息,便于报警、记录、分析等,只是这个题目是统计视频中的车辆总数。于是查了下资料发现MATLAB提供了视频提取和图像处理包,而且数字图像在电脑上就是M*N*P的矩阵,其中P是通道数,比如RGB图像通道数就是3,灰度图像通道数单一就是1。MATLAB在矩阵处理方面具有很好地优势,又刚好学过MATLAB的课程,所以就选用MATLAB进行模型的建立。这里有个小细节,用MATLAB加载视频的时候始终失败,需要安装xvid解码器,这样MATLAB就可以加载视频文件了。MATLAB可以获取的视频文件的基本信息有,文件名、文件大小、时间、帧率FPS、总帧数等。对于每一帧图像,我们可以得到信息是,它是一个288(height)*352(width)*3(RGB)的三维像素矩阵,每个数据的范围都在0~255,也就是用无符号8位数来表示颜色值,比如在点(50,50)处的像素值是(0,0,0)就代表那个点是黑色,如果是(255,255,255)就是白色,(255,0,0)则是红色。即每个点的颜色是通过R,G,B红绿蓝这三种按照不同比例混合而成的。考虑三维矩阵的处理比较麻烦,数据量大,就先对图像进行一个处理,比如变成灰度图像或二值化图像。效果如下:

一般灰度图像是对于某个的像素值RGB进行一个算术平均或者其他权重进行处理,这样图像的通道数就由3变为了1,可以大大减少计算量。而二值化图像又是灰度图像进行再处理,高于某个阈值的全是1,低于某个阈值是全0,这样的图像矩阵里面就只有0和1了,非黑即白。很明显转换成灰度后的图像更清楚,而二值化处理后的图像颜色比较深的车易被忽略掉。因此,我们采取了对每一帧图像进行灰度处理。对于车流量的统计,常用的算法有背景差分法、帧差法、边缘检测法、灰度比较法等,其中
- 帧差法是将相邻的两帧图片相减,按车道开固定窗口对保留的运动车辆信息进行检测,环境光线的变化对其影响不大,但该方法常因车辆换道或相邻车道的车辆部分覆盖了被检测车道检测窗而引起误检。
- 边缘检测法能够在不同的光线条件下检测到车辆的边缘。然而,当车辆色彩较暗或位于阴影中,使车辆边缘模糊,则可能引起漏检。
- 灰度比较法常用于对路面和车辆的灰度值进行比较来检测是否有车,其算法简单,计算量小,易于实现,尽管该方法受光线影响较大。
不过对于这些方法当时也没时间去仔细研究和实践,就想了一个简单粗暴的方法。我们仔细研究了每一帧图像,因为拍摄角度是固定的,图像大小固定,车道在图像也是固定的,只是车在不断变化。图像中的车道宽度大概在30个像素,而车宽肯定小于每个车道的宽度,所以决定在每个车道画出一条黑色实线,我们称之为虚拟检测线。如下图。

这里选取的检测线还是有讲究的,基本在靠近摄像头的位置,距离太远车道和车辆比较模糊,其次每个车道的检测线没有在同一条线上,但也不能相隔太远防止车辆变道。然后不断for循环遍历当前帧与前一帧在这个检测线上的像素值是否有变化,有变化则说明有车辆经过,但不是说有变化就统计加1。因为实际车辆经过检测线这个过程中,图像像素也会产生微小变化,比如车窗颜色和车头或车位的差异。所以还要考虑车辆完全通过后前后两帧的图像像素没有变化。因此,具体如何判别车辆完全经过图像,我们需要考虑一个累计值。当第一次出现变化时便设置一个标识符,简单说就是一个flag,然后连续往后考察很多帧的值是否有变化,并且是按每条车道去单独统计车流量,最后加起来算总和。伪码如下:
temp 虚拟检测线上灰度值的基准值
temp(i) 第i帧图片虚拟检测线上的灰度值
sum 统计的车辆数
T 阀值
for i=1:n 一帧一帧的比较
if |temp-temp(i)| > T 判断是否达到阀值
sum + = 1; 满足条件,计数
end最后我们通过这种方法得到的结果是这段视频的车辆总数是261,与标准的272相比,误差为4.04%。分析主要原因是视频中某些车的颜色和路面相近或者光照影响,又经过灰度处理后导致模型计算时并没有把车辆统计进去,当然也有车辆变道同时占据两个车道被统计了两次的情况。于是就很自然的想用双线检测线会不会准确,效果小。

我们就只考察一个车道,看准确率是否会提高,双线画线的逻辑显然跟单线的不一致,具体如下:
- 上下两条检测线记为a,b。车先经过a,然后再经过b。
- 两条采样线的长度均为30个像素,相距为5个像素。
- 对于第n帧图,只在一条线上检测到差值变化信号不能直接断定有车。仅当a,b同时出现较大差值的变化时,可以认定当前确实有一辆车经过。
- 同理,在一定范围内增加更多的检测线可以更好的提高检测精度,但必须保证两端最外边线的间距小于一般的车长。
- 具体实现采用两个数组standard1(1:30)和standard2(1:30)来实现,分别记录两条标准线上的各点灰度值。
而且我们发现这样的双线检测的方法还能粗略计算一下车速用于判断是否超速,方法如下:
- 在上采样线检测到差值差值信号瞬间时,记录下此时的帧数n,随后下采样线检测到差值信号的瞬间,再记录下那个时刻的帧数m。
- 每一秒含有25帧图像。即相邻两帧时差为0.04秒。
- 实际中的上下采样线的距离可以测量。我们设为D。
- 则汽车通过的速度为V=D/[(m-n)/25],即V=25×D/(m-n)。
此外,关于阈值的计算,显然由于每一个车道的光照不同,视角不同,选用一个差值作为一个统一的标准显然是不可靠的。所以需要根据不同的车道,需要赋予了个适当的阀值。为了计算每个车道的最大阀值,我们采用的是静态取点,即在车道附近一定范围内取一些不受车影响的而且有代表的点。计算整个过程中那些静态点差值的变化,以变化的最大值作为该车道的阀值,最后得出来是50。不过由于比赛时间有限(仅三天),而且知识面有限,很多想法也不知道怎么实现,很多图像处理的方法也不了解。最后就草草收场了,好在还拿了一个小奖。
1.2 赛后小感
过了这么多年回过头再看这次比赛,还是觉得挺不容易的。毕竟当时不懂的东西太多,还不到大三,很多知识都是现学的,对于模型完全是自创的一个新方法。虽然仅限这道题、这个特定环境下的模型,也没什么扩展性、计算实时性、误差来源分析、不同方法比较等,主要都没怎么参考论文啥的,也不知道如何查阅论文。比赛期间除了技术实现,还要写类似“八股文”一样东西,比如为什么选用这个模型/方法,做这个模型有什么假设或前提,模型的优缺点,模型的改进等等,都快赶上写学术研究论文了,时间太紧张。不过也正因为此,奠定了我在图像处理和学术研究的基础,而且感觉图像处理还挺容易上手的,尤其是在计算机中,我们把它看成一个数字矩阵,图像处理的基本所有方法都可以看作是对这个数字矩阵做各种变换,从而可以得到不同效果,还挺有意思的。
2 机器人的视觉研究
2.1 研究背景
2013年的时候加入智能体研究基地团队(Base of Intelligent Agent Research),实验室有一个双轮差动的轮式移动机器人,移动平台是英集斯自动化公司提供的。其中运动电机为24V/70W 高性能空心杯MAXON电机,配有减速比为33:1的减速箱,同轴安装有500 线的光电编码器以确保电机控制的精度。上位机可通过向DSP(TMS320LF2407)运动控制卡发送控制命令,驱动电机转动实现机器人的移动。上位机和下位机通过RS232串口通信,示意图如下。

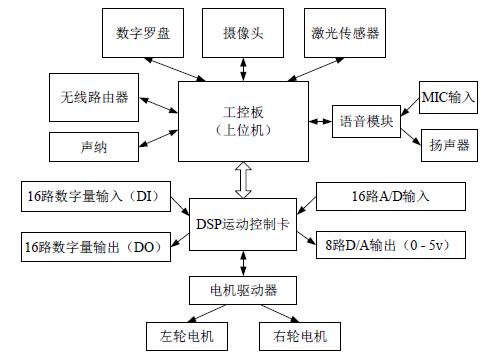
现在的机器人硬件系统应该都是这么搭建的吧(大同小异),当然这篇文章不是讨论机器人,而是讨论视觉在机器人上的应用,对研究机器人感兴趣可移步至《ROS与机器人》。机器人的下位机接口已被厂商开发好了,对于上位机,其实也就是一台T2350/1.86GHz/0.99GB的WinXP工控机,只需调用运动控制接口,下发速度指令即可。从上面的系统框图可以看出,有了这个机器人平台可以做很多方面的研究,比如激光SLAM导航,语音识别,机器人视觉等。因为之前有过比赛的经验,个人觉得有在图像处理方面有一点基础,而且当时有个博士师兄正好在研究人脸识别,对OpenCV及其环境的搭建很熟,所以我决定尝试研究下机器人视觉。首先是使用kinect一代的深度相机,安装kinect SDK后里面就自带一些教程,可以看到RGB图像和深度图像,也有骨骼识别、手势识别等例程。kinect一代底座有个马达可以调节镜头的视角,有点像一根连杆支撑上面的镜头,因此当移动机器人的时候,很明显感觉画面在晃动,而且画面有几百毫秒的延时,图像质量也不是太好。于是果断换Logitech的USB摄像头,并开始看《OpenCV(中文版)》,O'Reilly出版社,也是于仕琪团队翻译的。当时书里面还是讲的OpenCV1.0的语法,还是用的IplIMage方法去操作图像,我用的版本是2.4.4,好在差别不算太大。
2.2 OpenCV基础知识
这里简单介绍下图像处理的常用方法,无论是Windows还是Ubuntu下安装OpenCV网上都有太多教程,版本越新越好,功能越强大。安装OpenCV的时候可以留一下它又所依赖的库,比如与硬件通讯相关,图像压缩与解码等,这也是调用OpenCV中的API便可以加载图片或摄像头或视频的原因。
2.2.1 图像/视频的基本操作
正如1.2节所说,图像在计算机中是以数字矩阵的方式呈现,所以对于图像的操作就是对矩阵的操作。矩阵的常用操作无非是创建一个新矩阵,相加,相减,左乘,右乘,复制,取块矩阵等。尤其是取图像中某一块矩阵,还取了一个很好听的名字,叫感兴趣区域(ROI,region of interest),比如选取一块矩形、椭圆区域等,将其填充为黑色或白色等。因此,对于矩阵运算,除了Eigen库外,OpenCV偶尔也可派上用场。虽然OpenCV还是没能像MATLAB操作矩阵那么方便,但我发现越往后API封装得简直越来越好,Mat类、imshow、imwrite、subplot等等这些都跟MATLAB的语法一样或类似了。这里需要注意的有两点,OpenCV里面储存彩色图像的顺序是BGR;再就是图像的元素类型,一般是8U(即 8 位无符号整数,范围0~255),也可以是16S、32F等,对应C/C++中 uchar 、 short 、 float 等基本数据类型。在做图像变换时,尤其要注意图像的类型,防止计算时超出范围而造成程序运行崩溃。
其次,OpenCV提供了一些简单的回调函数进行交互,如键盘响应事件,鼠标响应事件和滚动条控制器等。不过真正要开发GUI的话,这几个事件响应应该是不够的。
最后补充一点,彩色图像用RGB去表示是因为红绿蓝是最基本的三原色光,它们按不同比例相加可以得到其他任何颜色。这种加色法广泛应用于电子系统中,也是最常见的和比较容易理解的。除了RGB颜色模型外,还有其他的方法表征颜色,比如HSV模型(Hue表示颜色,Saturation表示饱和度,Value表示亮度)。OpenCV还提供了API用于不同颜色模型的转换,对于图像的增强和色调滤镜,使用HSV空间去分析就具有很好的效果。
2.2.2 阈值分割与形态学
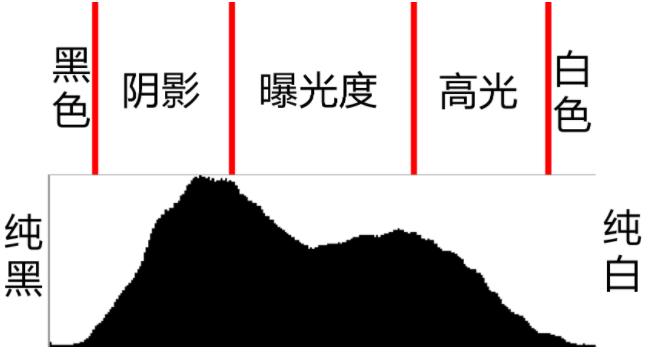
对灰度图像完成的阈值化操作称为灰度图像二值化,简称图像二值化。我一般喜欢称之为阈值分割,这是一个很常用的处理方式,大致思路是比如8U类型的图像,大于某个阈值T我就设定为0,小于T的保持不变,这样很亮的地方就被黑色遮盖住了,稍微灰暗的地方就会凸显出来,所以对于图像的二值化处理可以不仅限于单通道的灰度图像,多通道的图像也同样可以,得到的效果也显然不一样。阈值分割又可细分为5类:二值化,二值化反,阈值截断,阈值取零和阈值取零反,看字面意思也基本能看出这几种方法的差异,就是对于给定的阈值进行不同的逻辑操作。但绝大多数情况下,我们很难人为的找准阈值,于是便有了自适应阈值方法。这里得先引入一个概念就是图像直方图,比如8U的图像,矩阵中所有值的范围都在[0,255],然后将0~255当作X轴,0~255这256个值分别有多少个显示在Y轴上,这样的图便称为图像直方图,如下。实际上这样的图在手机拍照的详细信息中可广泛看到。
 (图片来自网络)
(图片来自网络)
自适应阈值方法中OTSU和Triangle 都是基于直方图分布实现的全局阈值计算的方法,其中OTSU的是通过计算类间最大方差来确定分割阈值的阈值选择算法,而Triangle三角法基于直方图的单峰与斜边的最大距离确定阈值。因此,OTSU 算法对直方图有两个峰,中间有明显波谷的直方图对应图像二值化效果比较好;Triangle三角法对直方图单峰分布的图像效果比较好,主要用于凸显最明显的那块区域,比如细胞壁检测。
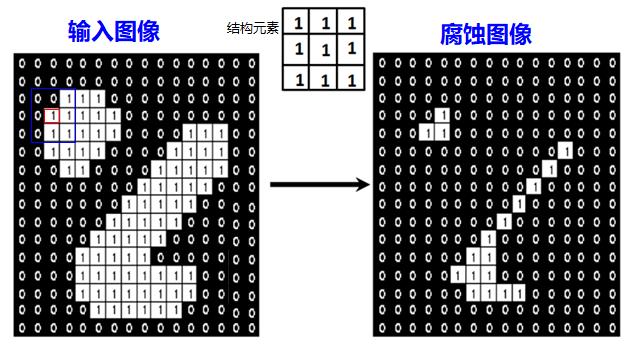
图像形态学的操作有一个结构元素,或者叫滑动窗口。结构元素不是一个像素,而且一个几何形状的像素块,比如矩形 、十字交叉 、圆形等。这个结构元素从左至右、从上到下遍历整个矩阵,并按照一定规则处理结构元素对应矩阵块里的数值。比如当矩阵块里的数值与结构元素的一致时,不进行处理;有不一致全部按0处理,这样白色区域变会减少,也就是图像的腐蚀,如下图所示的示意图。
 (图片来自网络)
(图片来自网络)
如果对于上述描述的过程进行相反操作,那么图像的白色区域变会扩大,这就是膨胀。腐蚀和膨胀还可以组合起来对图像进行操作,比如开运算是对输入图像执行先腐蚀后膨胀操作,而闭运算是对图像执行先膨胀后腐蚀操作。腐蚀可对图像进行局部缩小,碰撞可对图像进行局部放大,因此开运算可有效清除二值图像中小的白色噪声像素块凸显高亮区域,闭运算则能填充二值图像中小的黑色像素凸显灰暗区域。个人觉得这些概念没必要特意去记住,具体情形具体分析即可。
其次连通区域分析,它主要通过扫描图像中的每个像素点,对像素值相同且相互连通像素点标记为相同的标签,最终将像素点相同的区域连成一个闭合回路。扫描的方式可以是从上到下,从左到右,也可以是基于每个像素单位。常用的扫描方法是两步法,具体过程是首先检查是否有邻域被标记像素点,如果有一个或者多个邻域像素点被标记,则选择最小的标记作为当前前景像素点的标记。合并过程通过检查连通等价,对连通区域替换最小等价标记,最终得到输出。连通区域的分析可很好得用于文本分割或分析,如下图所示。
 (图片来自网络)
(图片来自网络)
最后轮廓提取与Blob检测,寻找轮廓就是提取二值化图像中的边缘点集或对应的层次信息,然后沿着边缘连续的像素点绘制成轮廓,也是基于连通区域分析,具体算法过程可参考论文《Topological structural analysis of digitized binary images by border following. Satoshi Suzuki et al, Computer Vision, Graphics, and Image Processing, 30(1):32–46, 1985》。轮廓提取在图像几何分析、对象检测与识别中都非常有用。Blob检测就是对于图像中一组相互连通的像素点,它们具有一些共通的属性,要把这些区域都找出来并标记。Blod检测也会调用轮廓检测的方法,差别在于Blob检测方法更高级一点,更适合检测不规则的斑点或比较复杂的连通区域,比如下图。
 (图片来自网络)
(图片来自网络)
2.2.3 图像滤波与变换
图像滤波主要为了去除图像里面的噪声,是图像预处理很重要的一环。具体处理方法是使用一个小型滤波器(比如3x3),输出中心点的像素值由周围8个决定,如下图所示。
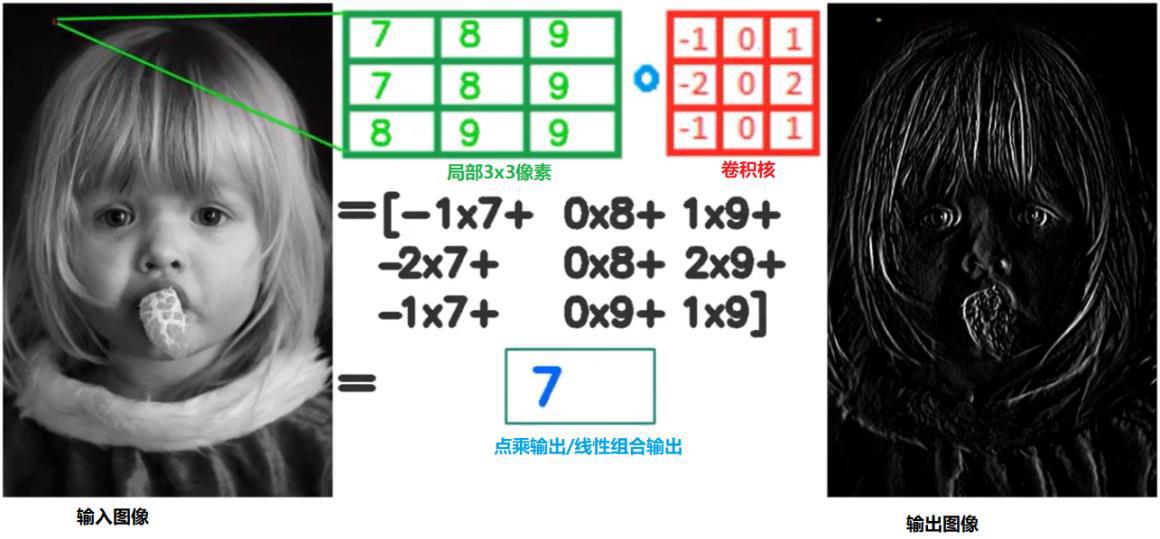 (图片来自网络)
(图片来自网络)
如果输出像素依赖的是输入像素的线性组合,则称为线性滤波器;如果输入输出是非线性的,则称为非线性滤波器。通过滤波器的方法对图像进行的操作称之为卷积,而滤波器则称为卷积核,真是一个高大上的名字,其实完全可以看作是一个滑动的窗口遍历图像,在每个小窗口进行运算。因此从这也可看出,图像的卷积和泛函分析中定义的卷积略有差别(泛函分析中卷积概念,通过两个函数f 和g 生成第三个函数的一种数学算子,即F[g(x)*f(x)] = F[g(x)]F[f(x)])。在进行滤波的过程需要注意的就是图像的边界处,也就是矩阵的四个边。通常有以下几种方法计算或者处理边界像素卷积:零值填充,再造边界和反射边界。
图像滤波可细分为方形/均值滤波(卷积核所有像素的对中心像素的贡献相等),高斯滤波(邻域像素根据到中心像素距离不同有着不同的权重),中值滤波(基于排序统计理论的一种能有效抑制噪声的非线性滤波)和双边滤波(一种非线性、边缘保留、有效去噪声的滤波方法)。它们的区别如下:
- 均值滤波可对图像进行快速、简单的平滑处理,对于噪声的处理很差。
- 高斯滤波是一种比均值滤波稍微好一点的线性滤波,也不会改变原图像的边缘走向。
| 椒盐噪声 | 高斯噪声 | 计算速率 | |
| 中值滤波 | 效果好 | 效果不好 | 速度快,计算少 |
| 双边滤波 | 效果不佳 | 效果好 | 计算复杂 |
卷积核除了可以用作滤波,还能对图像进行梯度操作。比如图像从左向右看,像素值不断增大;或者从上到下看,像素值不断增大,这些都能反映出图像的梯度变化。计算图像的X,Y方向上的梯度采用如下算子(这里又叫算子这个概念了),也称作Prewitt 算子,是一种一阶算子。

为了更好的降低噪声影响,同时提升梯度计算的稳定性,可以首先进行高斯模糊,然后再进行梯度计算。而高斯模糊也是卷积操作,先进行高斯模糊再进行梯度计算是两步卷积操作。把这两步卷积整合为一步卷积操作就是Soble算子,它隐含一个高斯模糊操作。经过这些梯度运算或者另外一种形式的滤波,我们可以把图像中的轮廓信息凸显出来。此外还有拉普拉斯算子,是一种二阶导数滤波,能更好地提取边缘信息。图像都具有求导的性质,是不是觉得挺难以理解,其实跟微积分里面所说的梯度含义一样(公式也一样),所以我们不能太死抠概念或公式,得看到它的本质和用途,多总结、类比,活学活用。最后一个很有名的检测就是Canny算法,分三个步骤:1.梯度计算;2.非极大值抑制;3.双阈值和边缘连接。
说完滤波,接下来就是图像的几何变换。几何变换一类称为仿射变换(Affine Transform),另外一类称为单应性变换(Homography)。变换的基本操作可表述为如下:
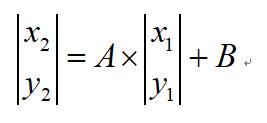
其中A表示变换矩阵,B为平移系数,因此图像几何变换也可以看错是坐标旋转、映射等,最终结果就是图像放大、缩小、平移、旋转等。在OpenCV中我们需给定这个变换矩阵,再使用warpAffine函数。但通常情况下,我们是不知道变换矩阵的,这时就需要用到单应性变换。OpenCV有一个很稳定的估算方法拟合所有的相关点,findHomography函数。图像的几何变换对于图像全景拼接和特征点匹配具有最大意义。
2.2.4 图像的特征提取
图像的特征提取是图像处理的关键也是难点,图像的特征包含特征点及其所对应的描述子,这些可看作是图像的DNA。也就是描述一幅图像最基本的单元,图像如何进行什么变换,图像的特征点不会变化。常见的图像特征提取方法有SIFT、SUFR、ORB等。其中SIFT特征提取方法同时具备迁移、尺度、旋转不变性,但是速度慢;SIFT特征提取方法比SURF计算要快;ORB主要是在快速关键点检测算法跟BRIEF描述子算法上改进而成的,它的关键点检测通过FAST算法发现关键点,然后通过Harris角点检测与金字塔提取多尺度特征。对于特征描述子,ORB使用BRIEF描述子,但是BRIEF描述子在匹配时候本身不具备旋转不变性,稳定性不高,因此ORB通过改进BRIEF描述子对点对旋转生成多个查找表实现对特征描述子的计算。
当提取到特征点后,我们再通过特征匹配来寻找不同图像中的相同部分,并标记出来。匹配方法有两种,一种是暴力匹配,一种是FLANN匹配,示例如下。
 (图片来自网络)
(图片来自网络)
2.2.1~2.2.4节所描述的一些基本理论和算法大多是20世纪八九十年代甚至更早就提出来的,非常成熟稳定,也是目前应用最广的。总结一下,数字图像处理可看作是对于矩阵的操作。比如阈值分割用去除高像素值的部分或者低像素值的部分;形态学操作主要是通过一个小窗口去遍历图像,对图像轮廓进行提取;滤波处理主要用于图像平滑和降噪;几何变换和特征提取则是至少两幅图像的操作和比较了,不得不佩服前人们的智慧以及数学之美。发展这么多年,在网络上应该无论什么语言都能找到相应的实现例子。有了这些基础知识和实践,在很多做图像处理或美颜的公司工作应该不成问题。
2.3 OpenCV与机器人控制结合
学习2.2节讲了图像处理的一些常规方法,现在要应用到机器人中,还存在很多其他方面的问题有待解决。对于机器人来说,图像就是它的眼睛,可做的研究有物体跟踪、物体识别导航及路径规划等。
- 物体跟踪:物体可以是特定形状或者特定颜色的,轮廓提取并计算出轮阔半径/直径OpenCV都提供有API,然后把直径作为反馈,让机器人保持与特定物体一定距离实现跟踪。而且前面有师兄们做出过demo,但是这种场景单一,识别也仅限特别物体,可扩展性不强,也不是当时的研究热点。
- 物体识别:要解决的关键问题在于分类和识别,也就是机器人对于采集到的图片能筛选出有用信息,并作出相应反应,比如抓取、语音播报、辅助定位等。而机器人具有甄别能力的前提有是离线训练好很多不同模型的物体并导入到机器人,很多机器学习或深度学习的方法用上,那时深度学习还不火。而纯粹的图像分类进行正样本训练和负样本训练又感觉跟机器人没太大关系。抓取又不是实验室现有平台的强项,对于机械臂的研究又得深入很久。因此,在这个方向没有继续展开。
- 导航:导航对于机器人来说一直是个热点话题。有地图才能定位才能规划,而地图需要人为去建。一般是激光slam建图和导航,视觉再文章很难(当时VSLAM也没那么发达)。还有一种机制就是学习,让机器人采集周围场景信息,然后能够根据场景输出运动信息(比如速度,位置等)。这种方法不仅用到了图像处理的方法,也得结合机器学习,最后还应用到了机器人中,是一个不错的方向。
我们知道图像的数据量一般很大,比如640*480的彩色图像,每一帧图像所包含的像素点就有921,600个。因此降维很关键,而且降维后的关键信息还能保留。很容易想到的有灰度、滤波去除噪点、压缩、PCA、特征提取等。因此对于运动中的机器人,它看到的场景就是如下:

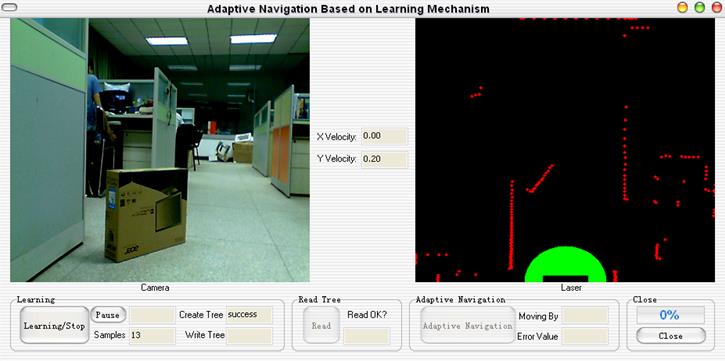
然后我们再将采集到的图像和机器人运动信息放入到一种机器学习算法IHDR中,它能够生成一种树形结构的数据库。机器人再次在场景中时,通过当前场景去检索已建立好的数据库从而输出运动信息,这样便完成了机器人的学习。一般来说机器学习方法是一种离线的形式,也就是预先用大量样本学习一个知识库后,在线运行时直接使用。与之相对应的在线学习是指不必离线学习获得知识库,直接运行时知识库是从零起步,逐渐丰富,因此它是一种增量式的学习。而IHDR算法就具有这种增量式的学习效果,这样机器人就能够进行在线的自主学习。后来我们一起做了一个上位机来实现这一功能,如下图所示。
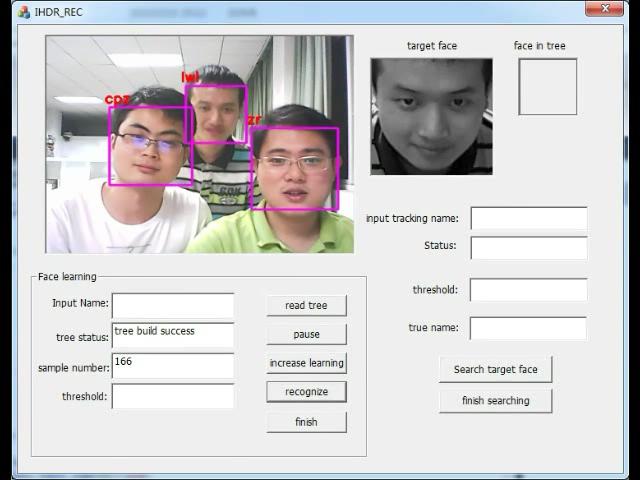
在线学习时,即便边采集图像和运动信息边训练,耗时也很短。不过IHDR不足处在于输入的维数必须是统一的,而实际情况是场景中可能没有足够多的特征点可供提取。此外,当样本足够大的时候,IHDR的存储和检索会收到影响。后来师兄又将其应用在多人脸识别上,直接在线采集,采集完了之后马上就能识别出对应的人脸,如下图所示。我还取了一个很复杂的名字“a coarse real-time online tracking system on face detection and recognition from cluttered scenes”。
3 显著性检测和Photometric Stereo
3.1 显著性检测
对于图像处理中使用的各种方法,我们可以再上升到一个更高层次的理论体系——显著性检测。这是一种受生物启发而得到的概念,又可细分为自下而上的目标驱动模型和自上而下的任务驱动模型。自上而下的模型是针对训练样本中有代表性的特征,能够检测某些固定大小以及类别的目标。而自下而上的方法通过基于底层视觉信息,能有效检测细节信息,而不是全局形状信息,且计算复杂度也通常低于自上而下模型。再说高大上一点就是生命体视觉分为两个阶段,一些基本的特征提取会在第一阶段完成,即自下而上的注意。而第二阶段的选择由主观信息实现,即自上而下的注意(源于1980年Triesman等人提出的注意力特征综合理论)。归纳一下就是,自上而下的注意是一个认知过程,由人的心理状态和认知因素决定的,比如知识、当前的或者预期的目标;而自下而上的注意是一个感知过程,通常是基于底层的视觉信息,只是单纯地从场景中提取出显著的区域,一般具有强烈对比度的区域或与周围有明显不同的区域能吸引人们的注意力。
实际上,仔细想想便可看出自上而下的研究是基于机器学习或深度学习,需要有大量的样本作为支撑,而自下而上的研究是基于图像中本身的信息尤其是细节,也就是传统的图像处理方法。显著性检测对于计算机视觉中的预处理和降低计算复杂度具有重要意义,因为涉及到的图像处理基础和数学知识非常多,有特别多大牛在这方面做工作,具体可参见《图像显著性检测总结》。这里给一个例子,同一个检测方法在不同场景中,看看效果如何。具体方法为基于元胞自动机的检测,论文《Qin Y, Lu H, Xu Y, et al. Saliency detection via cellular automata[C]. IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2015: 110-119》。


显然可以看出,在不同场景下,提取到的显著性目标完全不同。这就是由图像本身的差异或细节或“DNA”决定的。
3.2 Photometric Stereo技术
前面介绍的图像处理方法都是针对单一图像,所有可获取到的信息都只能这个数字矩阵中,因此无论怎么复杂高级的变换我们可提取到的信息还是有限。然而我们还可以再加入一些其他辅助信息,比如两个摄像头,并知道摄像头的距离及其视角,这样就类似于人的双眼,同一时间两个摄像头看到的图片信息肯定不一样,从而我们依据一些算法可实现双目测距;比如加入红外测距仪我们可以测出场景中任意点到摄像头中心的距离(当然测距范围有限),这也是Kinect、Xtion、RelSense等传感器的简单原理。有了深度信息我们就能得到点云,捕获更丰富的信息。Photometric Stereo技术是2015年去英国西英格兰大学访学,在Centre for Machine Vision(CMV)实验室了解到的。从名字就可大致看出photometric,通过照片或者光度使得到的图像信息不仅限于平面,还可以包含平面的法向量,从而建立一个三维模型,如下图所示。

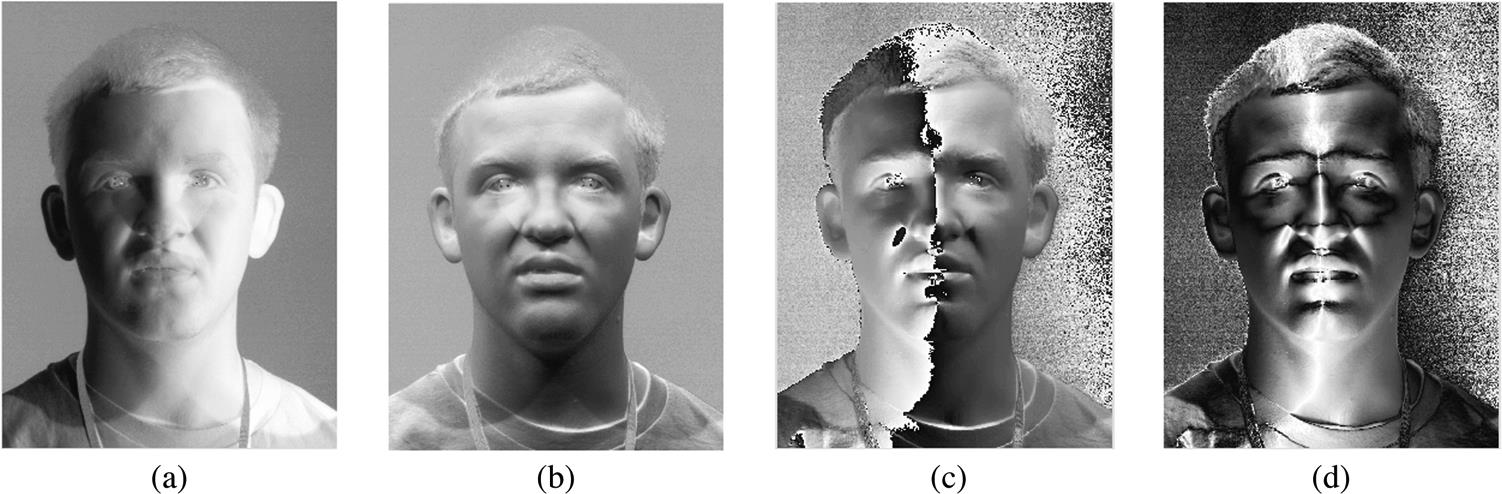
Photometric Stereo tutorials中介绍基本原理,相应的代码可以在GitHub上找到。
4 ROS+机器视觉
ROS是加入HANS后才真正用上,关于ROS的使用这里不加以阐述。在ROS中通过cv_bridge包实现ros图像和opencv图像的转换,然后通过image_transport包订阅和发布图像数据。因此,ROS和OpenCV的结合主要在于解决环境配置问题,然后图像转换问题,最后所发布的信息或者接口可以被其他ROS节点调用。
4.1 简单demo
当时因为在研究AGV,主要了激光导航、磁带导航,就有人提出能不能再加上视觉进行辅助定位,比如识别特定轨迹。我于是就做了一个简答的demo,具体流程是:由于黑色像素较为明显,因此先对图像进行灰度处理变成单通道的,再进行Ostu阈值分割(大津法),得到二值化的图像就只有0和1了,其中为0的部分为黑色,最终我们提取黑色部分,并计算其长度。效果如下,详细可参考《运用ROS和OpenCV进行简单的图像处理之检测》。
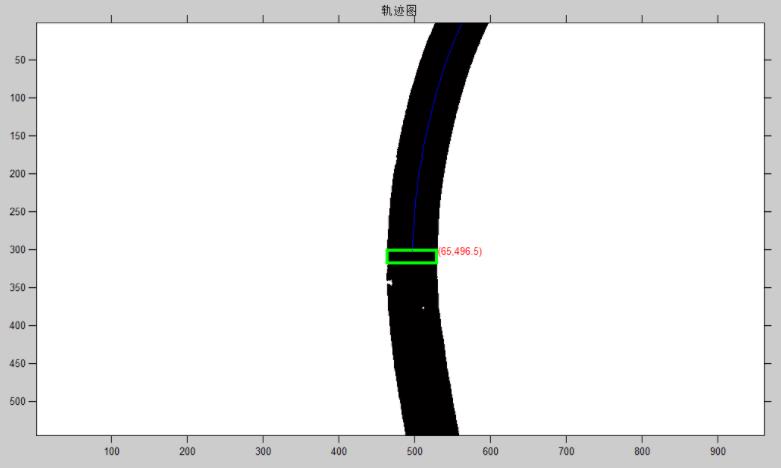
此外,我们还可以做一些二维码识别、定位的工作。尤其是二维码识别,现在OpenCV的版本已经支持识别和解析了。
4.2 再引入PCL
PCL(point cloud library)点云库就更深一层了,通常是结合深度相机比如kinect、realsense等,其VSLAM、精准识别也在不断的研究中。这里我们使用点云仅仅是为了探测地面的平整度,首先我们得找一个标准的、平整的地面运用RANSC方法,并根据投影到地面的点云计算出地面的平面方程(三维的,且这个坐标系是基数AGV车体中心),如下图所示。然后AGV继续行驶时再实现刷新当前地面的平面方差。当前面出现凸起物或者凹陷物时,显然计算的平面方差会与之前标定的有偏差,且点云会有凸起或者凹陷的部分,我们需要将其识别出来用于标识障碍物并加入到局部路径规划中。不过这个想法或者实验并没有能真正的做好和用好。
- 没有考虑到地面本身有坡度的情形。
- 可能数据量太大,或者深度相机本身有测量误差,有些孤立点没有很好的过滤造成计算偏差。(研究点云库也是一个需要长期积累的过程)

5 总结与展望
以上便是机器视觉的一些基本理论,以及本人在这方面工作的一些所见所闻所感。这是一个很好的研究方向,希望有更多的人能投入到实际产品的应用中,而不仅仅将这些看起来、听起来高大上的算法只在实验室中得以论证。
在实际工业产品中,Halcon是运用最广的商业机器视觉库,德国MVtec公司开发的一套完善的标准的机器视觉算法包。基解决问题最多、最基本的便是模板匹配,虽然网上受OpenCV关于模板匹配的应用多如牛毛,但工业产品中为什么还以Halcon为主呢?因为工业产品要求太苛刻,哪怕1%的误差也是不允许的,一定要很强的鲁棒性。所以图像处理很有意思、OpenCV很好用,但能真正带着问题和做产品的思维去用,就会发现有太多有待解决的问题等在面前,激励着我们不断努力去探索和攻克。。。
LWL于深圳
以上是关于OpenCV与机器视觉的主要内容,如果未能解决你的问题,请参考以下文章
机器视觉行业实践技巧 -- OpenCV技巧与方法:避坑指南
OpenCV 机器视觉入门精选 100 题(附 Python 代码)
毕业设计 - 题目:基于机器视觉opencv的手势检测 手势识别 算法 - 深度学习 卷积神经网络 opencv python