三问了解哈希表和哈希冲突
Posted 恪愚
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了三问了解哈希表和哈希冲突相关的知识,希望对你有一定的参考价值。
什么是哈希表?
哈希表也叫散列表,它是基于数组的。这间接带来了一个优点:查找的时间复杂度为 O(1)、当然,它的插入时间复杂度也是 O(1)。还有一个缺点:数组创建后扩容成本较高。
哈希表中有一个“主流”思想:转换。一个重要的概念是将「键」或「关键字」转换成数组下标。这由“哈希函数”完成。
什么是哈希函数?
由上,其作用就是将非 int 的键/关键字转化为 int 的值,使可以用来做数组下标。
比如,HashMap 中就这样实现了哈希函数:
static final int hash(Object key){
int h;
return (key==null)?0:(h=key.hashCode())^(h>>>16); // 通过异或提高hash的“散列度”,降低冲突
}
其中利用了 hashCode 完成转换。虽然哈希函数有很多种实现,但都应当满足这三点:
- 计算得到的是非负整数;
- 如果
key1==key2,则hash(key1)==hash(key2); - 如果
key1!=key2,则hash(key1)!=hash(key2);
- 并不是所有的键/关键字都需要被转换才能做下标(索引)
- 就像 JS 中也有类似的、但仅用于检测键是否能用来做数组下标的方法:JavaScript数组索引检测中的数据类型问题
什么是哈希冲突?
上面提到了 hashMap —— 一个java中提供的数据集。我们先来了解下:首先,hashMap 本质上是一个容器,它为了达到快速索引的目的,使用了数组结构“快速定位”的特性。
hashMap 中为了更快找到插入的值,建立了插入值和数组下标的关系:pos(下标)=key(值)%size(数组大小)。
比如:数组长度为10
- 插入100,有100%10=0;
- 插入201,有201%10=1;
- 插入403,有403%10=3;
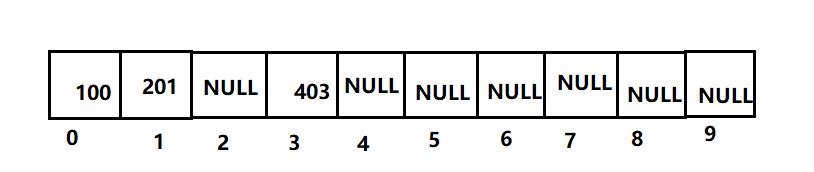
但是如果这样设计的话,我现在再插入200,会怎么样?
这就是数组的一个缺点:插入特殊值比较“费劲”。不如我们干脆将数组涉及成这样:
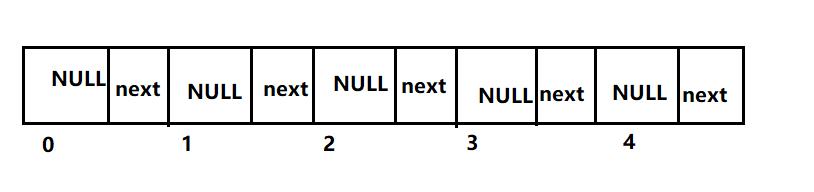
引入链表特性,一个节点就包括一个值和一个next指针。
现在再插入上面那些值,就变成了这样:
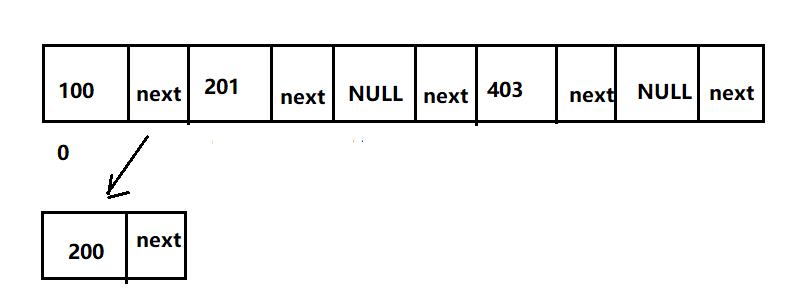
这时候如果再插入值300,怎么做?
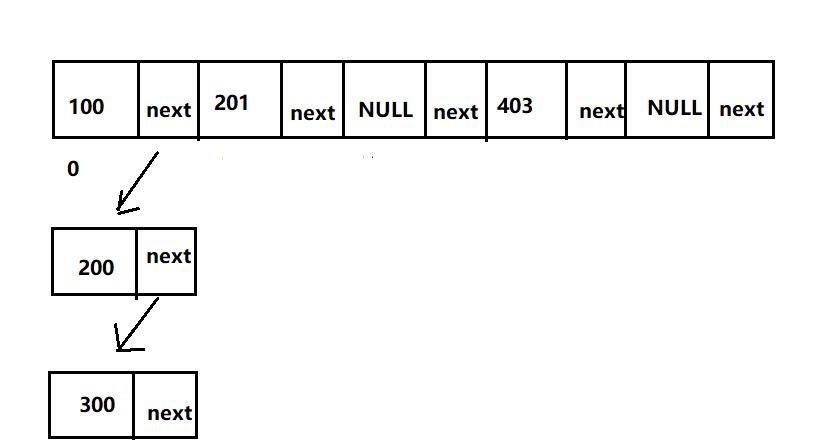
类似这样(当两个或以上的key的pos相同,且key不同)其实就是我们提到的“hash冲突”,而 hashMap 中解决hash冲突的方法就是上面说的“单链表”!
但是这又有一个问题:虽然用有序链表的方式可以减少不成功的查找时间(因为只要有一项比查找值大,就说明没有我们需要查找的值),但是不能加快成功的查找。如果冲突的链表太长,则链表查找时需要从“头”遍历的劣势就暴露出来了 —— 针对这个问题,JDK1.8后用 红黑树 做了优化!
但是我们先撇开红黑树,用单链表的形式说明一下哈希表的操作:
/**
* 链表基类:链表法解决哈希冲突用的是有序链表!
*/
public class SortedLinkList {
private Link first;
public SortedLinkList(){
first = null;
}
/**
* 链表插入
* @param link
*/
public void insert(Link link){
int key = link.getKey();
Link previous = null;
Link current = first;
while (current!=null && key >current.getKey()){
previous = current;
current = current.next;
}
if (previous == null)
first = link;
else
previous.next = link;
link.next = current;
}
/**
* 链表删除
* @param key
*/
public void delete(int key){
Link previous = null;
Link current = first;
while (current !=null && key !=current.getKey()){
previous = current;
current = current.next;
}
if (previous == null)
first = first.next;
else
previous.next = current.next;
}
/**
* 链表查找
* @param key
* @return
*/
public Link find(int key){
Link current = first;
while (current !=null && current.getKey() <=key){
if (current.getKey() == key){
return current;
}
current = current.next;
}
return null;
}
}
链表法哈希表插入:
public void insert(int data) {
Link link = new Link(data);
int key = link.getKey();
int hashVal = hash(key);
array[hashVal].insert(link);
}
链表法哈希表查找:
public Link find(int key) {
int hashVal = hash(key);
return array[hashVal].find(key);
}
链表法哈希表删除:
public void delete(int key) {
int hashVal = hash(key);
array[hashVal].delete(key);
}
除了链表法,解决哈希冲突还有一个方法:开放寻址法。
在开放地址法中,若数据不能直接存放在哈希函数计算出来的数组下标时,就需要寻找其他位置来存放。在开放地址法中有三种方式来寻找其他的位置,分别是
- 线性探测
- 二次探测
- 再哈希法
以上是关于三问了解哈希表和哈希冲突的主要内容,如果未能解决你的问题,请参考以下文章