浅谈大数据HDFS架构演变的来世今生
Posted 数据之其然
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了浅谈大数据HDFS架构演变的来世今生相关的知识,希望对你有一定的参考价值。
1、hadoop1.0问题
1.1、单点故障问题【HA方案】
Hadoop2的设计出现HA方案,主要解决单点故障问题
JournalName集群可以保证事务性一致(数据都是一样)、没有单点故障问题!
1.1.1、如何判断JournalName集群正常提供服务呢?
只要存活的节点数大于二分之一,我们就认为这个JournalName集群是健康的,可以进行读写服务
JournalName是同步数据、元数据的角色,在集群部署3~5个JournalName就可以(哪怕1000个节点,5个JournalName已经到天花板了)
JournalName可以理解成大数据的kafka效果
1.1.2.、NameNode角色划分
在高可用的架构只有一个NameNode(Active),而另一个是NameNode(standBy)主要是同步元数据
1.1.3、自动切换,引入zookeeper集群
如何保证能被自动切换呢?
两个NameNode(Active、standBy)启动后,都会向zookeeper进行注册,而zookeeper会准备好一把锁,在这两个NameNode(Active、standBy)中,谁载到这把锁,谁就是Active。
但是这样远远不够,在NameNode里,一般也会准备两个ZKFC进程。
1.1.4、ZKFC进程有什么用?
主要是接空NameNode,并在集群中保持心跳,会告诉zookeeper,NameNode健康的状况
比如:NameNode(Active)服务消失了,zookeeper可以知道健康状况
1.1.5、为什么要引入ZKFC?
在特殊情况下,zookeeper不一定可以感受的到,比如:NameNode发生FGC情况,把进程几秒钟就结束了、持续2分钟,而如NameNode(Active)进程还在,但是不工作了,可以通过ZKFC方式告诉zookeeper,而zookeeper知道后将会把这把锁给另一个NameNode(standBy),就完成了主备切换【解决有状态单点故障问题】
1.2、内存受限
大数据围绕“分而治之”
Hadoop2的设计出现联邦方案,主要解决HDFS1的内存受限
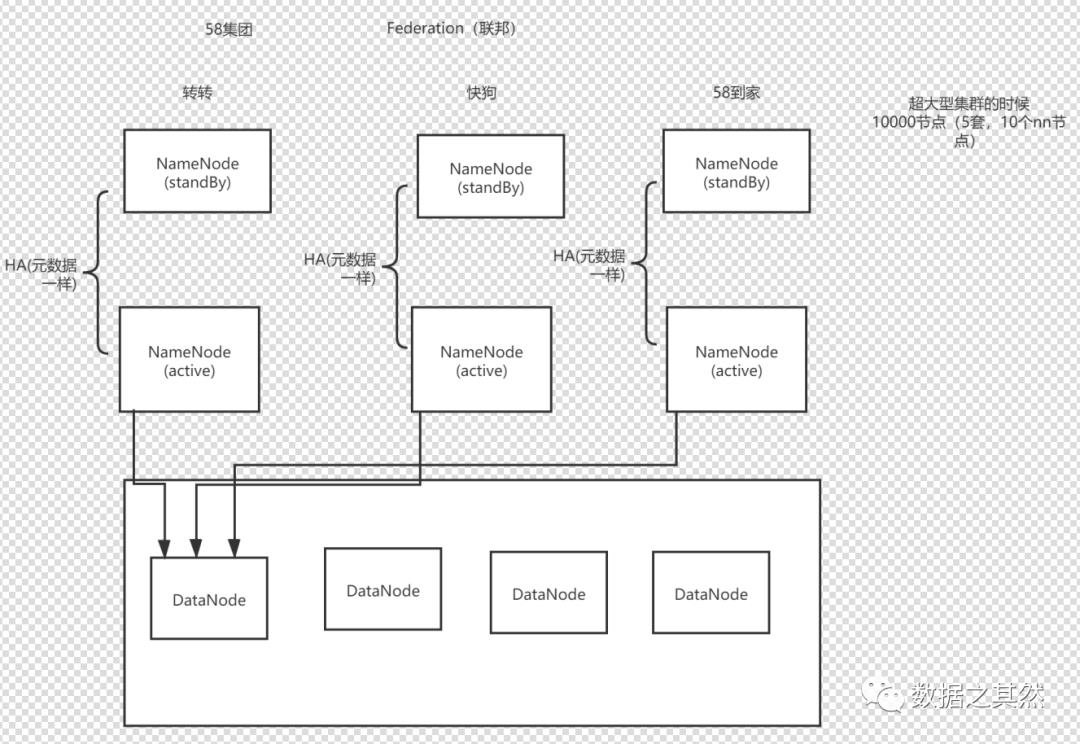
两个NameNode存储元数据不一样,会出现什么问题?如图所示:

会出现单点故障问题,可采用高可用(HA)架构解决,如图所示:

大数据围绕分而治之思想思路去讲,如不够可以扩容下去,就解决单点故障问题。
说明:对于1000个节点以上就可以考虑这种方案,这钟方案是美国设计出来的,英文名叫Federation。
需要了解:
在HDFS2的HA方案里,只支持一个主,一个备,而到了HDFS3的HA方案可支持多个NameNode,一个主,一个备,然而在联邦方案发HA,却可以支持两个NameNode,分别是:
NameNode(Active)、NameNode(StandBy)
Hadoop3设计出现HA方案,可支持多个NameNode,引入纠错码技术
2、HDFS支持亿级流量的秘密
2.1、因为NameNode管理了元数据,用户所有的操作请求都要操作Namenode,大一点的平台一天需要运行几十万, 上百万的任务。一个任务就会有很多个请求,这些所有的请求都打到NameNode这儿(更新目录树),对于 Namenode来说这就是亿级的流量,Namenode是如何支撑亿级流量的呢?
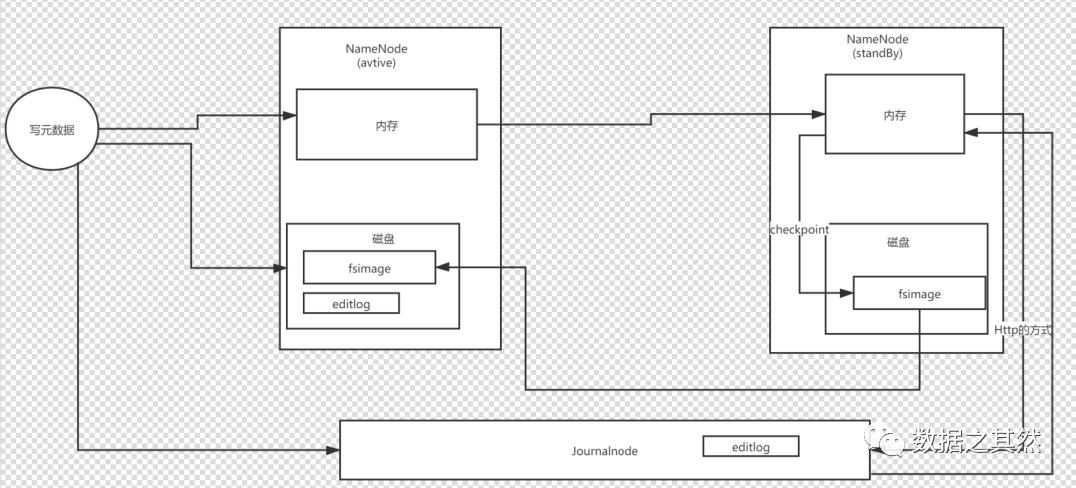
启动hdfs后
(1)首先进行文件系统进行格式化后在NameNode(Active)会产生fsimages(元数据)文件,将会加载到磁盘上
(2)请求会一份写到内存中,另一份写到磁盘中产生一个或多个editlog,把数据合并一下就是一个fsimages(元数据)文件
(3)editlog也可以往JournaInde集群写数据,而JournaInde集群可以往上同步数据到NameNode(StandBy)里,然后会加载到内存里面,每隔一个周期进行checkpoint,这时候它会把内存中的数据写到磁盘里面,生成一个fsimages文件
思考题:
为什么每隔一个周期进行checkpoint,这时候它会把内存中的数据写到磁盘里面,生成一个fsimages文件,而在NameNode(StandBy)磁盘的fsimages文件为啥需要替换NameNode(Active)磁盘的fsimages文件呢?架构设计为什么这样做?
原因:
首先若把请求的元数据文件更新到NameNode(Active)的内存,另一方面把元数据文件写到磁盘的地方,当重启NameNode后,内存的文件将会清空,而磁盘元数据文件还是有,这时候我们需要对editlog文件进行合并,产生新一个fsimages文件,但是时间久了,会产生很多小文件,并且还需要对小文件日志进行回放,当它的量达到一定的程度,它启动耗时特别长(10分钟、半小时、一个小时),导致集群不可用!
解决方案:
editlog往JournaInde集群写数据,而JournaInde集群可以往上同步数据到NameNode(StandBy)里,然后会加载到内存里面,实时去合并在NameNode(StandBy)磁盘的fsimages文件替换NameNode(Active)磁盘的fsimages文件,主要作用是加快启动时间
写磁盘支持高并发、高性能有什么解决方案?
把磁盘写转化为内存写,这个方案叫刷缓冲方案
知其所以然、知其所以必然,知其然而不知其所以然;蒙惠者虽知其然,而未必知其所以然;也这是我们从学习实践中得出的深切体会!分享完毕,谢谢!
以上是关于浅谈大数据HDFS架构演变的来世今生的主要内容,如果未能解决你的问题,请参考以下文章