从聚合转移的统一视角浅谈卷积神经网络架构设计 | Paper Reading
Posted MomentaAI
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了从聚合转移的统一视角浅谈卷积神经网络架构设计 | Paper Reading相关的知识,希望对你有一定的参考价值。
#看Paper Reading直播,拿Momenta 顶级offer#
Momenta全球招聘顶尖人才,同时开放校招及实习岗位,
春季招聘期间,Momenta将举办多期线上Paper Reading分享会,
请来顶级大牛,深挖某一问题的来龙去脉,带你走进Momenta的学术世界。
————
线下宣讲会在全国范围相继开启,下一站将抵达上海:
#上海交通大学专场宣讲会#
4月17日(周二)下午18:00-20:00
上海交通大学闵行校区 铁生馆300号
#同济大学专场宣讲会#
4月18日(周三)下午18:00-20:00
同济大学嘉定校区 济人楼405
热招岗位:
深度学习研发工程师、SLAM/VIO/SFM研发工程师、决策规划算法研发工程师、软件开发工程师、机器人系统开发工程师......
人工智能大咖面对面交流,学术干货和精美礼品现场放送!
深度学习中卷积神经网络的拓扑结构设计有着极其重要的地位。一个高效的结构可以把速度和性能的平衡拉到一个更高的平衡点上,这在所有应用卷积网络的深度学习系统中都是非常关键的。
新架构的设计必须对已有的优秀的结构有一些较为深刻的认识并且在实践中积累大量的经验,4月10日晚,Momenta 高级视觉算法研究员李翔做客AI 慕课学院,用聚合-转移框架的视角对现有的代表性的卷积神经网络设计进行了总结。
主讲人

李翔
Momenta 高级视觉算法研究员
南京理工大学 PCALab 博士在读
李翔曾获阿里巴巴天池首届大数据竞赛冠军,滴滴 Di-Tech 首届大数据竞赛冠军。知乎专栏 DeepInsight 作者。早期负责 Momenta 车道线检测相关模块,现专注于神经网络基础算法研发。
直播回放
△ 视频回放
聚合-转移框架
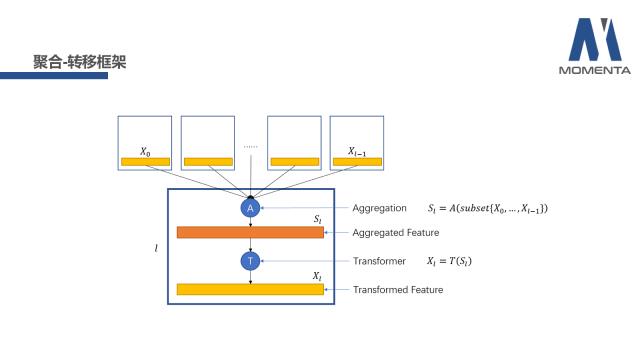
卷积神经网络通常都是由许多不同的层级结构组成的。上图的篮框部分是被定义的L层网络单元,它总体包含聚合(Aggregation)和转移(Transformer)两个部分。具体来说,聚合可用图示的函数表示,聚合函数A代表通过选择L以前层的X的一个子集作为输入,得到聚合特征S;转移的部分比较简单,将聚合特征S通过转移函数T得到L层的X。
这便是聚合-转移框架的视角,从这个视角出发,可对现有的卷积神经网络的架构进行解读。
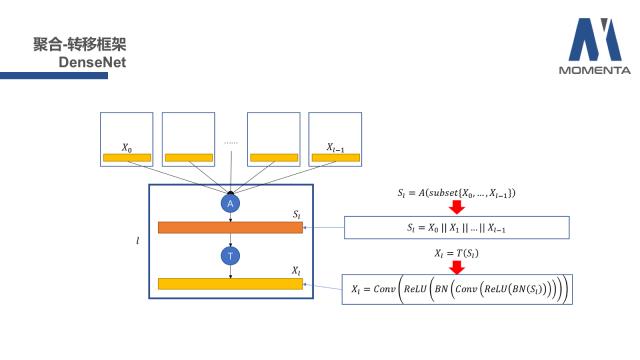
为了更加形象的理解,我们举一个具体的且耳熟能详的例子——DenseNet。DenseNet是CVPR 2017的最佳论文。从聚合-转移框架的视角(以上两个表达式)来看,subset子集收敛到所有的L层之前的X上;聚合函数A具体化为channel维度的拼接(concatenation),拼接可用两条竖线的符号标记;这是聚合部分的情况。
对于转移部分,一般在DenseNet中,转移函数T通常具象化为顺序2次的BN+ReLU+Conv。
聚合的子集

接下来,从子集的构成和聚合函数A入手,分别讨论他们目前已有的主流的形式。
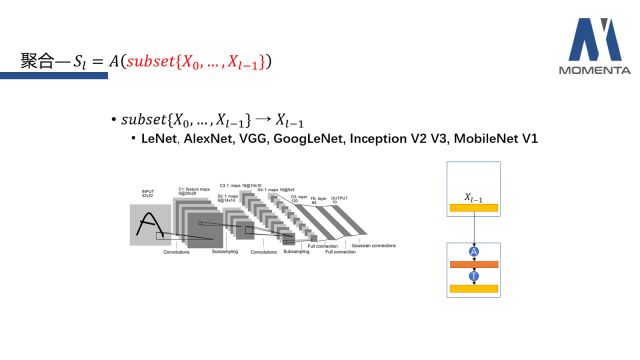
对于聚合函数A而言,第一种情况是子集(subset)只是选取L-1层的X。这个模式普遍出现于早期的feed-forward的神经网络中,主要代表有LeNet、AlexNet、VGG、GoogLeNet、InceptionV2 V3、MobileNetV1。
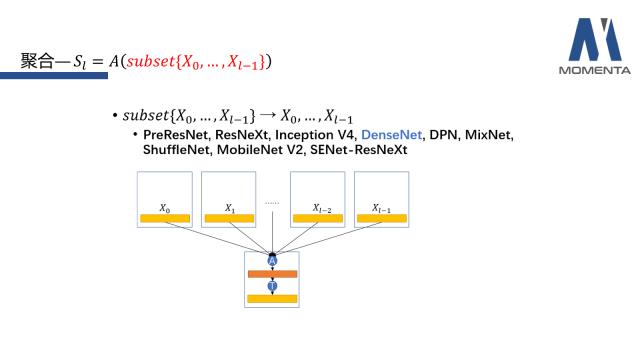
第二种情况是子集(subset)选择L层之前所有层的X,这是较为常见的。主要代表作有ResNet系列、DenseNet系列以及基于ResNet或者DenseNet提出改进的一些网络结构。
DenseNet是选择之前所有层进行密集的链接,但是ResNet是怎么回事?难道ResNet不是skip connection吗?下面将为大家推导解答ResNet和DenseNet在拓扑结构上的等价性。
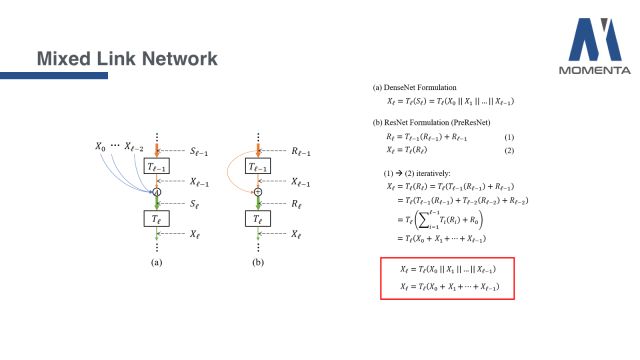
首先分析图中(a)的拓扑结构,这个拓扑结构基本上是DenseNet的结构,符号和聚合-转移框架是保持一致的,于是可以写出它数学上的表达式,具体化为channel维度的拼接,进行一步的转移后得到DenseNet标准的表达式,也是其论文中的原始定义。
再看图中(b)ResNet的结构,是一个标准的skip connection结构。根据ResNet的定义可写出表达式(1),从表达式中也体现了skip connection;同时表达式(2)即是中间feature X的表达。在得到表达式(1)和表达式(2)后,可将表达式(1)不断地循环地带入表达式(2)中,最后可以得到一个非常有意思的表达式。
最后,将(a)和(b)两个网络的表达式平行地写在一起,发现两者唯一的区别就在于聚合函数A,(a)DenseNet结构表现为channel维度的拼接,(b)ResNet结构表现为逐元素的相加。二者遵循的都是一个相同的Dense的拓扑连接结构。这部分的具体细节可以查看Mixed Link Network的论文。

提到这里,不得不回顾一个小往事。众所周知,ResNet前后其实提了两个版本。第一个版本是图(a),也是CVPR的最佳论文《Deep Residual Learning for Image Recognition》,第二个版本是图(b),是第一篇论文发表后的第二年发表的论文,名为《Identity Mappings in Deep Residual Networks》。
这两个版本的最大区别就是skip connection之后是否接relu。第一个版本接了relu,如果按照第一个版本,我们之前的推导是无法完成的。从实验上来讲,第一个版本的确也是存在一些问题的,图中是当时的实验结果,第一个版本的ResNet随着网络层数从一百层上升到一千多层,性能反而在下降。等到第二个版本,就完全符合了Dense的拓扑结构,随着网络变得很深,性能也能够稳定下降。这也充分地告诉我们,Dense的拓扑结构的确是具有一些非常优秀的性质,使得RenseNet和DenseNet在现有网络基础上都有着重要的影响力。
以上是在解释为什么ResNet其实是选择了之前所有层的X进行了聚合。
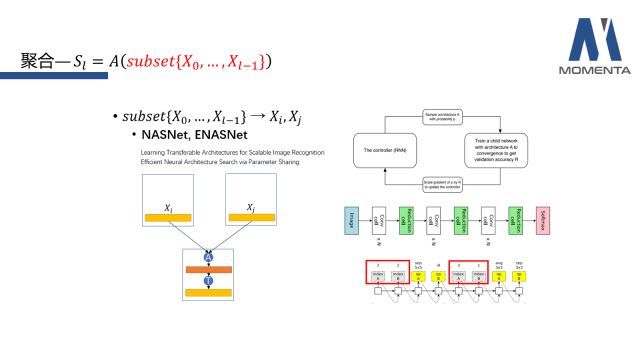
近期Google的一些network architecture search的工作(NASNet和ENASNet)采用了通过RNN去sample出2个L层之前的X进行聚合。他们的核心思想就是把Reinforcement Learning的思想引入到自动的架构设计中。具体来说,他们会使用一个RNN去sample出一些基础的连接结构,形成基元模块,使得网络性能更好。
RNN的输出基本分为两大类,一个是layer id,也就是选择之前的哪一层;另一个类是基础运算操作。图中红色框部分就是每次sample出的两个层的X。具体细节可以参考论文原文。
聚合函数A
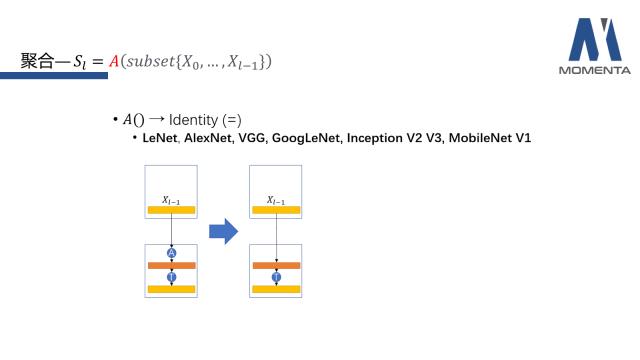
接下来介绍聚合函数A的几个代表形式。首先是恒等变换,也就是Identity函数,在通常的feed-forward网络中,聚合的特征是使用了上一层的feature X,在聚合过程中不会对feature进行任何操作,仅是转移至下一层。
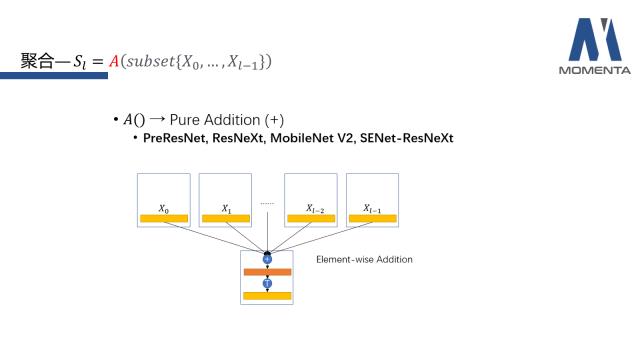
第二是逐元素(Element-wise)的相加,这类操作普遍出现在有skip connection的网络系列中,例如PreResNet、ResNeXt、MobileNetV2、SENet-ResNeXt。聚合的方式是在拿到子集(subset)的feature后,保证其维度一致,将每个位置的元素累加,随后进入转移环节。
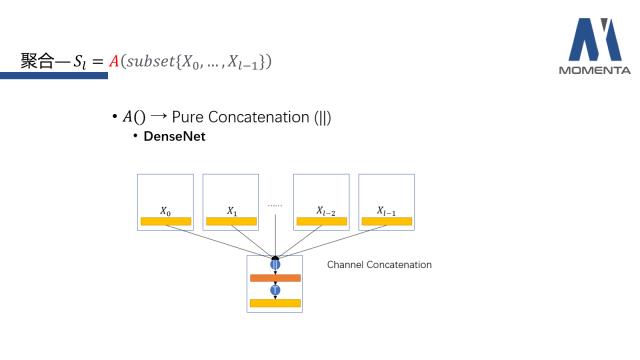
第三是通道(channel)上的拼接,代表作是DenseNet。这类形式是将所有feature在通道维度上进行一个扩增。通常,DenseNet的feature X的维度都比较小,保持量级不会过大,控制最终的feature维度在一定范围内。
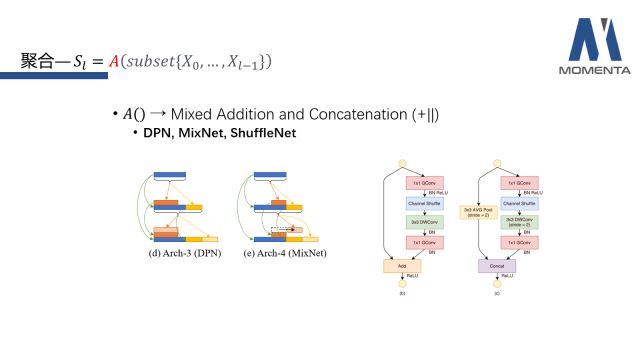
最后再介绍下混合了addition和concatenation的两种操作,混合的意思是在聚合的过程中既包括按位置的逐元素的相加,也包括channel维度的拼接,其主要代表作是DPN、MixNex和ShuffleNet。DPN可被视为拥有两条通路的网络,左边的通路为ResNet,右边的通路为DenseNet,进行feature上的拼接后,在转移过程中包含了逐元素的相加和channel维度的拼接。MixNet也是相似的原理,但去掉了严格意义上的ResNet的通路,把逐元素相加平均分摊到不断扩增的所有feature上。ShuffleNet则是在降采样的时候和非降采样的时候使用不同的两种操作,从而最终将其混合起来。
转移
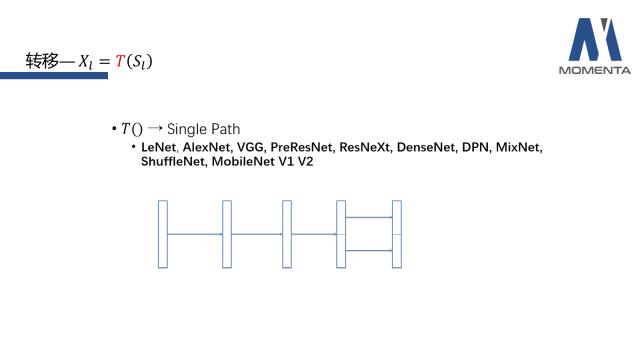
转移如果更加细致的划分可能可以有很多种分类方式,但由于篇幅限制本次只从两个方向简单地介绍转移的部分,分别是单路的转移和多路的转移(Single Path和Multiple Path)。通过顺序的卷积、组卷积等基元操作完成特征转移的网络都可被归纳为单路的转移(SinglePath)。在拥有聚合的feature之后,可以通过feed-forward(单向流)的方式,将基础的操作如concatenation、BN、pooling、激活函数等进行单向的组合,经过这一单路的组合,可以得到转移后的feature。单路的网络包括LeNet、AlexNet、VGG、PreResNet、ResNeXT、DenseNet、DPN、MixNet、ShuffleNet、MobileNetV1 V2等目前主流的网络,目前小型设备上使用的网络ShuffleNet、MobileNetV1 V2都是单路转移的设计,不涉及多路的转移。
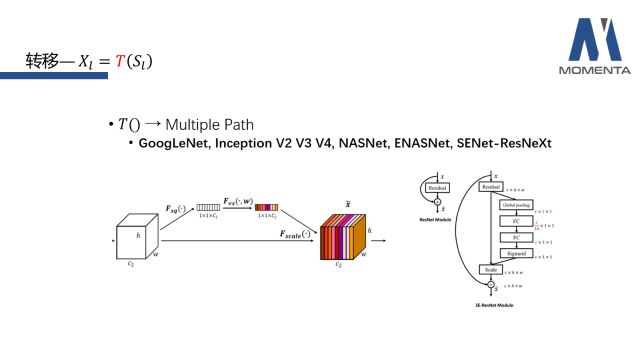
除了通过顺序的卷积、组卷积等基元操作完成特征转移的网络之外,其他的网络可被归纳为多路的转移(MultiplePath)。首要的代表作是GoogLeNet的Inception系列,Inception系列最早就是沿着多路的思路设计的,同一个feature会经过不同的深度、感受野的组织路径,进而设计出从V1到V4的系列版本。在迭代过程中,内部结构的变化越来越多,比如说把大的卷积替换成小的卷积的组合,然后卷积再进行分解,3乘3的分解成3乘1和1乘3等等。这一系列中唯一不变的便是其多路转移的设计思路。
值得一提的是,Momenta在ImageNet 2017的夺冠架构SENet便可以看作在特征转移的步骤中增加了一个multiple path,一路是identity,另一路是channel上的global attention。其实,转移部分还可以从更多更深入的角度在做分类和整理,我们今天仅从单路和多路的角度做了一些梳理,希望能给大家带来启发。
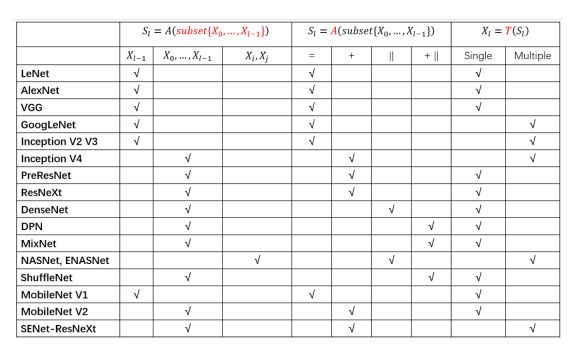
上图是本次分享的回顾,梳理了目前主流的架构。从子集选取的角度出发,可分为三种设计;从聚合函数的角度出发,可分为四种设计;从转移函数的角度出发,可简单分为两种设计。
希望这个表格能在子集选择、设计聚合函数和转移函数时给予大家启发。例如,现在借助网络架构搜索是一个很好的方向,比如NASNet和ENASNet,但其本身具有一定的局限性。首先搜索空间是被定义好的。当基础单元的研究没有到位时,搜索空间可能不会被定义得非常好,甚至有些很多结构在搜索空间里搜不到的,比如说Google的Inception结构,比如说DPN和MixNet这类混合的结构。它们在性能上的提升甚至可能往往并不如人工设计的结构。所以,接下来的网络设计应该是基础单元结合架构搜索同时前进,相互补充相互启发,从而达到共同的提高。

看完本期Paper Reading回顾,有没有什么心得想分享,在底下↓留言告诉我们,点赞数最高的三位可以获得精美礼品一个。
Momenta期待百里挑一的人才,扫描二维码,可查看更多热招岗位!
END
点击「阅读原文」,了解2018春季招聘详情
以上是关于从聚合转移的统一视角浅谈卷积神经网络架构设计 | Paper Reading的主要内容,如果未能解决你的问题,请参考以下文章
[Pytorch系列-50]:卷积神经网络 - FineTuning的统一处理流程与软件架构 - Pytorch代码实现