[Pytorch系列-49]:卷积神经网络 - 迁移学习的统一处理流程与软件架构 - Pytorch代码实现
Posted 文火冰糖的硅基工坊
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了[Pytorch系列-49]:卷积神经网络 - 迁移学习的统一处理流程与软件架构 - Pytorch代码实现相关的知识,希望对你有一定的参考价值。
作者主页(文火冰糖的硅基工坊):文火冰糖(王文兵)的博客_文火冰糖的硅基工坊_CSDN博客
本文网址:https://blog.csdn.net/HiWangWenBing/article/details/121312731
目录
第1章 关于Fine Tuning与Transfer Trainning概述
第1章 关于Fine Tuning与Transfer Trainning概述
1.1 理论基础
 https://blog.csdn.net/HiWangWenBing/article/details/121312417
https://blog.csdn.net/HiWangWenBing/article/details/1213124171.2 迁移学习的关键步骤
(1)步骤1:全连接层的初步训练
基于第三方(如官网)提供的预定义模型以及其预训练好的模型参数,锁定特征提取层,替换全连接层,并在自己的数据集上只重新训练全连接层,从而第三方训练好的神经网络能够适配到自身数据集和图片分类的业务需求上。
本步骤训练模型的基本策略是:
- 一边在训练集上训练,一边在验证集上验证。
- 选择在整个验证集上,而不是验证集的一个batch上,其准确率最高的模型参数以及优化器参数作为最终的模型参数
- 在整个验证集,而不是batch的目的:增加在测试集上的泛化能力
- 在验证集上准确率最高的目的: 防止在训练集上的过拟合
(2)步骤2:全网络的优化训练
相对于步骤1,步骤2的主要完成
- 加载步骤1的训练模型,并基于此模型进一步训练
- 开放整个网络(包括特征提取)和全连接层
- 降低学习率100倍,以便在根据精细的层面进行训练
1.3 本文概述
本文主要针对步骤-1的pytorch实现。
1.3 训练环境
文本以Resnet + CIFAR100 + GPU为例。
对于没有GPU的学习环境,可以把案例中的网络修改成:Alexnet + CIFAR10 + CPU, 只需要几行的代码改动,并不影响软件流程和架构。
第2章 输入数据集
2.1 定义数据集加载时的数据格式的转换
#2-1 准备数据集
# 数据集格式转换
transform_train = transforms.Compose(
[transforms.Resize(256), #transforms.Scale(256)
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])])
transform_test = transforms.Compose(
[transforms.Resize(256), #transforms.Scale(256)
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])])2.2 加载数据集
从本地加载数据集文件中加载数据集,如果没有数据集,自动从官网上在线下载数据集
# 训练数据集
train_data = dataset.CIFAR100 (root = "../datasets/cifar100",
train = True,
transform = transform_train,
download = True)
# 测试数据集
test_data = dataset.CIFAR100 (root = "../datasets/cifar100",
train = False,
transform = transform_test,
download = True)
print(train_data)
print("size=", len(train_data))
print("")
print(test_data)
print("size=", len(test_data))Files already downloaded and verified Files already downloaded and verified Dataset CIFAR100 Number of datapoints: 50000 Root location: ../datasets/cifar100 Split: Train StandardTransform Transform: Compose( Resize(size=256, interpolation=bilinear, max_size=None, antialias=None) CenterCrop(size=(224, 224)) ToTensor() Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]) ) size= 50000 Dataset CIFAR100 Number of datapoints: 10000 Root location: ../datasets/cifar100 Split: Test StandardTransform Transform: Compose( Resize(size=256, interpolation=bilinear, max_size=None, antialias=None) CenterCrop(size=(224, 224)) ToTensor() Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]) ) size= 10000
2.3 定义数据集批处理data_loader
# 批量数据读取
batch_size = 32
train_loader = data_utils.DataLoader(dataset = train_data, #训练数据
batch_size = batch_size, #每个批次读取的图片数量
shuffle = True) #读取到的数据,是否需要随机打乱顺序
test_loader = data_utils.DataLoader(dataset = test_data, #测试数据集
batch_size = batch_size,
shuffle = True)
print(train_loader)
print(test_loader)
print(len(train_data), len(train_data)/batch_size)
print(len(test_data), len(test_data)/batch_size)<torch.utils.data.dataloader.DataLoader object at 0x0000015158CCF4C0> <torch.utils.data.dataloader.DataLoader object at 0x000001516F052640> 50000 1562.5 10000 312.5
备注:
批处理的长度与GPU的内存,图片文件的大小有关,8G的GPU, batch size设定为32比较合适。
2.4 展现一个批次的图片
(1)定义显示函数
def img_show_from_torch(img_data, title = None, debug_flag = False):
# 颜色通道还原
img_data = img_data.numpy()
img_data = img_data.transpose(1,2,0)
# 标准化的还原
mean = [0.485, 0.456, 0.406]
std = [0.229, 0.224, 0.225]
img_data = std * img_data + mean
# 像素值限制
img_data = np.clip(img_data, 0, 1)
if(debug_flag == True):
print("PIL Image data")
#print("image_shape: ", img_data.shape)
#print("image_dtype: ", img_data.dtype)
print("image_type: ", type(img_data))
print(img_data)
# 显示图片
fig, ax = plt.subplots()
ax.imshow(img_data)
ax.set_title(title)
def img_show_from_torch_batch(img_data, title = None, debug_flag = False):
# 把多张图片合并成一章图片
img_data = utils.make_grid(img_data)
# 显示单张图片
img_show_from_torch(img_data, title = title, debug_flag = debug_flag)(2)获取一个批次的图片
#显示一个batch图片
print("获取一个batch组图片")
imgs, labels = next(iter(train_loader))
print(imgs.shape)
print(labels.shape)(3)显示单张图片
img_show_from_torch(img_data = imgs[0], debug_flag = False)
(4)显示批次图片
img_show_from_torch_batch(imgs)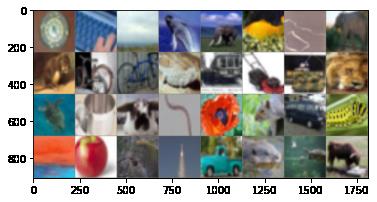
第3章 定义前向计算的网络
3.1 定义操作神经网络训练是否能够训练的函数
# 设置网络参数的trainable属性, 即设置梯度迭代使能的属性
def set_model_grad_state(model, trainable_state):
for param in model.parameters():
param.requires_grad = trainable_state# 显示网络参数允许trainable的参数,即梯度迭代使能的参数
def show_model_grad_state_enabled(model):
print("params to be trained:")
for name, parameters in model.named_parameters():
if(parameters.requires_grad == True):
print(name, ':', parameters.requires_grad)3.2 定义创建神经网络的函数
该函数的主要任务包括:
- 创建指定的官网预定义的神经网络(默认是1000分类),支持多种神经网络,可扩展。
- 锁定特征提取层
- 根据自身的需要,替换全连接层,适配到自身的图片种类分类(如100分类或10分类)
- use_pretrained = True时,自动自动远程下载预训练参数,并利用预训练的模型参数(主要针对ImageNet)初始化神经网络
# model_name: 模型的名称
# num_classes:输出种类
# lock_feature_extract:是否锁定特征提取网络
# use_pretrained:是否需要使用预训练参数初始化自定义的神经网络
# feature_extact_trainable: 特征提取层是否能够训练,即是否需要锁定特征提取层
def initialize_model(model_name, num_classes, use_pretrained = False, feature_extact_trainable = True):
model = None
input_size = 0
if(model_name == "resnet"):
if(use_pretrained == True):
# 使用预训练参数
model = models.resnet101(pretrained = True)
# 锁定特征提取层
set_model_grad_state(model, feature_extact_trainable)
#替换全连接层
num_in_features = model.fc.in_features
model.fc = nn.Sequential(nn.Linear(num_in_features, num_classes))
else:
model = models.resnet101(pretrained = False, num_classes = num_classes)
input_size = 224
elif(model_name == "alexnet"):
if(use_pretrained == True):
# 使用预训练参数
model = models.alexnet(pretrained = True)
# 锁定特征提取层
set_model_grad_state(model, feature_extact_trainable)
#替换全连接层
num_in_features = model.classifier[6].in_features
model.classifier[6] = nn.Sequential(nn.Linear(num_in_features, num_classes))
else:
model = models.alexnet(pretrained = False, num_classes = num_classes)
input_size = 224
elif(model_name == "vgg"):
if(use_pretrained == True):
# 使用预训练参数
model = models.vgg16(pretrained = True)
# 锁定特征提取层
set_model_grad_state(model, feature_extact_trainable)
#替换全连接层
num_in_features = model.classifier[6].in_features
model.classifier[6] = nn.Sequential(nn.Linear(num_in_features, num_classes))
else:
model = models.vgg16(pretrained = False, num_classes = num_classes)
input_size = 224
return model, input_size备注:
从上述代码可以看出,利用官网提供的API,很方便定义一个复杂的预定义神经网络。
3.3 创建并显示创建的神经网络
# 创建网络实例
model, input_size = initialize_model(model_name = "resnet", num_classes = 100, use_pretrained = True, feature_extact_trainable=False)
print(input_size)
print(model)224
ResNet(
(conv1): Conv2d(3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(maxpool): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
(layer1): Sequential(
(0): Bottleneck(
(conv1): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(downsample): Sequential(
(0): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): Bottleneck(
(conv1): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(2): Bottleneck(
(conv1): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
)
(layer2): Sequential(
(0): Bottleneck(
(conv1): Conv2d(256, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(downsample): Sequential(
(0): Conv2d(256, 512, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): Bottleneck(
(conv1): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(2): Bottleneck(
(conv1): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(3): Bottleneck(
(conv1): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
)
(layer3): Sequential(
(0): Bottleneck(
(conv1): Conv2d(512, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(downsample): Sequential(
(0): Conv2d(512, 1024, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(2): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(3): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(4): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(5): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(6): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(7): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(8): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(9): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(10): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(11): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(12): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(13): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(14): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(15): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(16): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(17): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(18): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(19): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(20): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(21): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(22): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
)
(layer4): Sequential(
(0): Bottleneck(
(conv1): Conv2d(1024, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(downsample): Sequential(
(0): Conv2d(1024, 2048, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): Bottleneck(
(conv1): Conv2d(2048, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(2): Bottleneck(
(conv1): Conv2d(2048, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
)
(avgpool): AdaptiveAvgPool2d(output_size=(1, 1))
(fc): Sequential(
(0): Linear(in_features=2048, out_features=100, bias=True)
)
)
备注:
(fc): Sequential( (0): Linear(in_features=2048, out_features=100, bias=True)
- 从这里可以看出,全连接层被替换,1000分类被替换成100分类。也就是说,加载的预训练参数,包括特征提取层和全连接层,但全连接被替代了,需要重新训练。
3.4 展示需要训练的网络参数
# 检查需要训练的参数
show_model_grad_state_enabled(model)params to be trained: fc.0.weight : True fc.0.bias : True
备注:
在这里,只有全连接层的参数需要训练,而特征提取层暂不训练。
第4章 模型训练
4.1 定义模型训练流程与策略(重点、重点、重点)
# 模块迁移学习/训练的定义:
# 一边在训练集上训练,一边在验证集上验证
# 策略:
# 最终选择在整个验证集上,而不是验证集的一个batch上,其准确率最高的模型参数以及优化器参数作为最终的模型参数
# 在整个验证集,而不是batch的目的:增加在测试集上的泛化能力
# 在验证集上准确率最高的目的: 防止在训练集上的过拟合
def model_train(model, train_loader, test_loader, criterion, optimizer, device, num_epoches = 1, check_point_filename=""):
# 记录训练的开始时间
time_train_start = time.time()
print('+ Train start: num_epoches = {}'.format(num_epoches))
# 历史数据,用于显示
batch_loss_history = []
batch_accuracy_history = []
best_accuracy_history = []
# 记录最好的精度,用于保存此时的模型,并不是按照epoch来保存模型,也不是保存最后的模型
best_accuracy = 0
best_epoch = 0
#使用当前的模型参数,作为best model的初始值
best_model_state = copy.deepcopy(model.state_dict())
# 把模型迁移到 GPU device上
model.to(device)
# epoch层
for epoch in range(num_epoches):
time_epoch_start = time.time()
print('++ Epoch start: {}/{}'.format(epoch, num_epoches-1))
epoch_size = 0
epoch_loss_sum = 0
epoch_corrects = 0
# 数据集层
#每训练完一个epoch,进行一次全训练样本的训练和一次验证样本的验证
for dataset in ["train", "valid"]:
time_dataset_start = time.time()
print('+++ dataset start: epoch = {}, dataset = {}'.format(epoch, dataset))
if dataset == "train":
model.train() # 设置在训练模式
data_loader = train_loader
else:
model.eval() # 设置在验证模式
data_loader = test_loader
dataset_size = len(data_loader.dataset)
dataset_loss_sum = 0
dataset_corrects = 0
# batch层
# begin to operate in mode
for batch, (inputs, labels) in enumerate(data_loader):
# (0) batch size
batch_size = inputs.size(0)
#(1) 指定数据处理的硬件单元
inputs = inputs.to(device)
labels = labels.to(device)
#(2) 复位优化器的梯度
optimizer.zero_grad()
# session层
with torch.set_grad_enabled (dataset == "train"):
#(3) 前向计算输出
outputs = model(inputs)
#(4) 计算损失值
loss = criterion(outputs, labels)
if(dataset == "train"):
#(5) 反向求导
loss.backward()
#(6) 反向迭代
optimizer.step()
# (7-1) 统计当前batch的loss(包括训练集和验证集)
batch_loss = loss.item()
# (7-2) # 统计当前batch的正确样本的个数和精度(包括训练集和验证集)
# 选择概率最大的索引作为分类值
_, predicteds = torch.max(outputs, 1)
batch_corrects = (predicteds == labels.data).sum().item()
batch_accuracy = 100*batch_corrects/batch_size
#(8-1)统计当前dataset总的loss(包括训练集和验证集)
dataset_loss_sum += batch_loss * batch_size
#(8-2)统计当前dataset正确样本的总数(包括训练集和验证集)
dataset_corrects += batch_corrects
# 把训练结果添加到history log,用于后期的图形显示
batch_loss_history.append(batch_loss)
batch_accuracy_history.append(batch_accuracy)
if(batch % 100 == 0):
print('++++ batch done: epoch = {}, dataset = {}, batch = {}/{}, loss = {:.4f}, accuracy = {:.4f}%'.format(epoch, dataset, batch, dataset_size//batch_size, batch_loss, batch_accuracy))
# 统计dataset的平均loss
dataset_loss_average = dataset_loss_sum/dataset_size
# 统计dataset的平均准确率
dataset_accuracy_average = 100*dataset_corrects/dataset_size
# 统计当前epoch总的loss
epoch_loss_sum += dataset_loss_sum
# 统计当前epoch总的正确数
epoch_corrects += dataset_corrects
# epoch_size
epoch_size += dataset_size
#模型保存:此处策略为:在验证集上,每次精度提升的时候,都保存一次模型参数,防止过拟合
if (dataset == "valid") and (dataset_accuracy_average > best_accuracy):
# 保存当前的最佳精度(防止过拟合)
best_accuracy = dataset_accuracy_average
# 保存最佳epoch(检查是否有过拟合训练)
best_epoch = epoch
print('+++ model save with new best_accuracy = '.format(best_accuracy))
# 获取当前的模型参数
best_model_state = copy.deepcopy(model.state_dict())
state = {
"state_dict": model.state_dict(),
"best_accuracy": best_accuracy,
"optimizer": optimizer.state_dict(),
}
if (check_point_filename != ""):
torch.save(state, check_point_filename)
best_accuracy_history.append(best_accuracy)
time_dataset_done = time.time()
time_dataset_elapsed = time_dataset_done - time_dataset_start
print('+++ dataset done:epoch = {}, dataset = {}, loss = {:.4f}, accuracy = {:.4f}%, elapsed time = {:0f}m {:.0f}s'.format(epoch, dataset, dataset_loss_average, dataset_accuracy_average, time_dataset_elapsed//60, time_dataset_elapsed %60))
# 统计epoch的平均loss
epoch_loss_average = epoch_loss_sum/epoch_size
# 统计epoch的平均正确率
epoch_accuarcy_average = 100*epoch_corrects/epoch_size
time_epoch_done = time.time()
time_epoch_elapsed = time_epoch_done - time_epoch_start
print('++ epoch done: epoch = {}, loss = {:.4f}, accuracy = {:.4f}%, elapsed time = {:0f}m {:.0f}s'.format(epoch, epoch_loss_average, epoch_accuarcy_average, time_epoch_elapsed//60, time_epoch_elapsed %60))
# 恢复最佳模型
model.load_state_dict(best_model_state)
# 记录训练的结束时间
time_train_done = time.time()
time_train_elapsed = time_train_done - time_train_start
print('+ Train Finished: elapsed time = {:0f}m {:.0f}s'.format(time_train_elapsed//60, time_train_elapsed %60))
return (model, batch_loss_history, batch_accuracy_history, best_accuracy_history)4.2 指定反向计算的loss函数
# 指定loss函数
loss_fn = nn.CrossEntropyLoss()
#loss_fn = nn.NLLLoss()
print(loss_fn)CrossEntropyLoss()
4.3 指定反向计算的优化器/算法
# 指定优化器
Learning_rate = 0.01 #学习率
# optimizer = SGD: 基本梯度下降法
# parameters:指明要优化的参数列表
# lr:指明学习率
#optimizer = torch.optim.Adam(model.parameters(), lr = Learning_rate)
optimizer = torch.optim.SGD(model.parameters(), lr = Learning_rate, momentum=0.9)
print(optimizer)4.4 训练前的准备
# 训练前准备
# 检查是否支持GPU,如果支持,则使用GPU训练,否则,使用CPU训练
if torch.cuda.is_available():
device_name = "cuda:0"
else:
device_name = "cpu"
# 生成torch的device对象
device = torch.device(device_name)
print(device)
#把模型计算部署在GPUS上
model = model.to(device)
#把loss计算转移到GPU
loss_fn = loss_fn.to(device) # 自适应选择法
#loss_fn.cuda() # 强制指定法
#保存训练后的模型
model_trained_path = "../models/checkpoint.pth"
# 定义迭代次数
epochs = 104.5 开始训练
checkpoint_file = "../checkpoints/alexnet_checkpoint.pth"
model, batch_loss_history, batch_accuracy_history, best_accuracy_history = model_train(
model = model,
train_loader = train_loader,
test_loader = test_loader,
criterion = loss_fn,
optimizer = optimizer,
device = device,
num_epoches = epochs,
check_point_filename = checkpoint_file)display_interval = 200)
+ Train start: num_epoches = 10 ++ Epoch start: 0/9 +++ dataset start: epoch = 0, dataset = train ++++ batch done: epoch = 0, dataset = train, batch = 0/1562, loss = 4.5650, accuracy = 0.0000% ++++ batch done: epoch = 0, dataset = train, batch = 200/1562, loss = 2.6052, accuracy = 28.1250% ++++ batch done: epoch = 0, dataset = train, batch = 400/1562, loss = 2.1804, accuracy = 31.2500% ++++ batch done: epoch = 0, dataset = train, batch = 600/1562, loss = 1.3488, accuracy = 65.6250% ++++ batch done: epoch = 0, dataset = train, batch = 800/1562, loss = 2.1539, accuracy = 40.6250% ++++ batch done: epoch = 0, dataset = train, batch = 1000/1562, loss = 2.1013, accuracy = 53.1250% ++++ batch done: epoch = 0, dataset = train, batch = 1200/1562, loss = 1.8998, accuracy = 40.6250% ++++ batch done: epoch = 0, dataset = train, batch = 1400/1562, loss = 1.6806, accuracy = 46.8750% +++ dataset done:epoch = 0, dataset = train, loss = 2.0600, accuracy = 47.2180%, elapsed time = 3.000000m 26s +++ dataset start: epoch = 0, dataset = valid ++++ batch done: epoch = 0, dataset = valid, batch = 0/312, loss = 1.6182, accuracy = 59.3750% ++++ batch done: epoch = 0, dataset = valid, batch = 200/312, loss = 1.9491, accuracy = 50.0000% +++ model save with new best_accuracy = +++ dataset done:epoch = 0, dataset = valid, loss = 1.7268, accuracy = 55.0900%, elapsed time = 0.000000m 40s ++ epoch done: epoch = 0, loss = 2.0044, accuracy = 48.5300%, elapsed time = 4.000000m 7s ++ Epoch start: 1/9 +++ dataset start: epoch = 1, dataset = train ++++ batch done: epoch = 1, dataset = train, batch = 0/1562, loss = 2.2609, accuracy = 43.7500% ++++ batch done: epoch = 1, dataset = train, batch = 200/1562, loss = 1.9580, accuracy = 59.3750% ++++ batch done: epoch = 1, dataset = train, batch = 400/1562, loss = 1.5650, accuracy = 56.2500% ++++ batch done: epoch = 1, dataset = train, batch = 600/1562, loss = 1.7263, accuracy = 53.1250% ++++ batch done: epoch = 1, dataset = train, batch = 800/1562, loss = 1.4484, accuracy = 71.8750% ++++ batch done: epoch = 1, dataset = train, batch = 1000/1562, loss = 1.5200, accuracy = 46.8750% ++++ batch done: epoch = 1, dataset = train, batch = 1200/1562, loss = 1.6857, accuracy = 50.0000% ++++ batch done: epoch = 1, dataset = train, batch = 1400/1562, loss = 1.4532, accuracy = 56.2500% +++ dataset done:epoch = 1, dataset = t以上是关于[Pytorch系列-49]:卷积神经网络 - 迁移学习的统一处理流程与软件架构 - Pytorch代码实现的主要内容,如果未能解决你的问题,请参考以下文章
[Pytorch系列-31]:卷积神经网络 - torch.nn.Conv2d() 用法详解
[Pytorch系列-45]:卷积神经网络 - 用GPU训练AlexNet+CIFAR10数据集
[Pytorch系列-46]:卷积神经网络 - 用GPU训练ResNet+CIFAR100数据集
[Pytorch系列-35]:卷积神经网络 - 搭建LeNet-5网络与CFAR10分类数据集