在SDN网络中基于深度强化学习的流量负载均衡
Posted SecurityLabUJN
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了在SDN网络中基于深度强化学习的流量负载均衡相关的知识,希望对你有一定的参考价值。
在SDN网络中基于深度强化学习的流量负载均衡
研究目的
主要贡献
具体方法
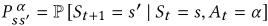 是状态转移概率矩阵,
是状态转移概率矩阵,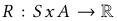 是一个奖励函数,
是一个奖励函数,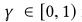 称为折扣因子。MDP模式包括一项指导特定状态选择行动的策略,表示为
称为折扣因子。MDP模式包括一项指导特定状态选择行动的策略,表示为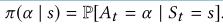 Q-learning过程是在对agent的每一个动作进行奖励和惩罚的帮助下进行的。通过反复尝试所有状态下的所有动作,能够学习到最好的状态动作对。Agent在状态-动作矩阵(Q表)中为每个状态选择一个动作,这个矩阵包括每个动作的回报估计。采取行动之后,根据行动的结果对代理人进行奖励或者惩罚,状态-动作矩阵用新的Q值更新,公式如下:
Q-learning过程是在对agent的每一个动作进行奖励和惩罚的帮助下进行的。通过反复尝试所有状态下的所有动作,能够学习到最好的状态动作对。Agent在状态-动作矩阵(Q表)中为每个状态选择一个动作,这个矩阵包括每个动作的回报估计。采取行动之后,根据行动的结果对代理人进行奖励或者惩罚,状态-动作矩阵用新的Q值更新,公式如下:
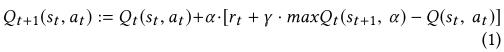
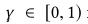 是折扣因子,
是折扣因子,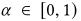 是学习率,rt是在时间t时的奖励,重复这个过程,直到模型的学习没有进一步的改进,训练的目标时使策略尽可能的准确,以便始终为给定的状态选择最佳的操作。由于有很多的状态无法用状态-动作表来表示,因此就使用CNN与Q-Learning结合起来。这样借助神经网络,智能的对Q值进行预测,就不用每个状态建立一个有不同Q值的矩阵,从而减少计算量,状态作为输入并返回估计的未来报酬作为输出来估计Q的可能值,此外还引入了一种从经验中学习的机制。大大提高了它的性能和网络的整体性能。
是学习率,rt是在时间t时的奖励,重复这个过程,直到模型的学习没有进一步的改进,训练的目标时使策略尽可能的准确,以便始终为给定的状态选择最佳的操作。由于有很多的状态无法用状态-动作表来表示,因此就使用CNN与Q-Learning结合起来。这样借助神经网络,智能的对Q值进行预测,就不用每个状态建立一个有不同Q值的矩阵,从而减少计算量,状态作为输入并返回估计的未来报酬作为输出来估计Q的可能值,此外还引入了一种从经验中学习的机制。大大提高了它的性能和网络的整体性能。
胖树拓扑:该网络拓扑主要用途使连接并行通用超级计算机处理器,它允许同时传输大量信息。胖树拓扑在数据重心网络中被广泛应用,胖树拓扑的主要实体使具有相同端口数量和相同带宽的交换机,交换机之间的连接方式是沿着树向上,如下图所示:
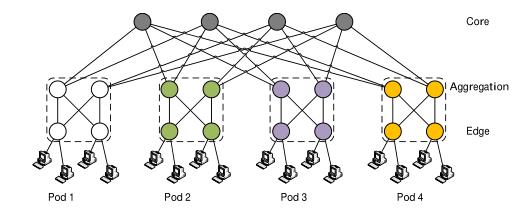
上边这个网络拓扑由4层和和K个pod,K表示每台交换机的端口数,K=4,上边的根,表示核心层,包含(k/2)2个交换机,然后往下是聚合层、边缘层、最后是主机层,位于叶子上。用K个端口的交换机构建胖树,最多支持3k/4个主机,胖树的pod由k/2个聚合交换机和k/2个边缘交换机组成,每个都连接到独立聚合交换机的端口,一个聚合交换机依次连接到k/2个边缘交换机和k/2个核心交换机。总结:通过每个pod中的这种连接,每个聚合交换机与所有的边缘交换机连接,所有的边缘交换机与所有的聚合交换机连接,每个pod连接到k2/4个主机和所有的核心交换机,最终每个核心交换机连接连接到所有的pod。
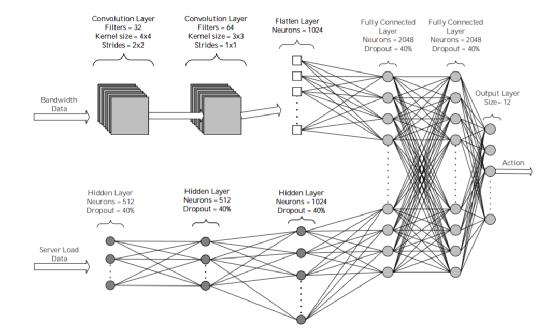
提出的深层神经网络(图2)由三个独立的神经网络组成,其中两个网络用作从网络收集的数据的输入和处理。第一种是卷积神经网络(CNN),由两个卷积层(卷积层,ReLu激活函数)和一个平坦层组成。CNN用于识别网络状态中的模式。第二种是简单的神经网络(NN),它由三个隐藏层组成,用于识别网络中服务器的CPU和内存负载。前两个网络的输出被引导到第三个神经网络,第三个神经网络有两个隐藏的完全连接层和一个输出层,并产生输出向量。建议解决方案中的代理、状态和操作如下:
代理-扮演SDN控制器的角色
状态-将状态定义为网络设备之间链路的带宽容量与服务器的CPU和内存负载的组合
Action-一个元组(S,D),其中S是将处理请求的服务器,D是该服务器将处理的后续请求数。
算法1是用来训练deep Q-learning

奖励函数如公式2:
模型的整体有效性通过成本函数(等式3)来衡量:
实验:使用mininet模拟的SDN网络,实验分为两大类,第一类涉及指定时间段内不同数量的请求,第二类涉及恒定数量的请求;为了得到更准确的结果来支持我们的建议,我们在每个实验中总共运行了10次迭代,并提取了每个负载平衡算法的平均性能。表3中的值是第一组实验的结果,在这组实验中,网络在4分钟内被30个并发用户的请求淹没。在记录的所有指标中,DQN模型都获得了更高的性能,因为它能够在服务器之间分配请求,从而使服务的请求量比其他两种算法高出大约40%。
以上是关于在SDN网络中基于深度强化学习的流量负载均衡的主要内容,如果未能解决你的问题,请参考以下文章