记一次压测中Mysql数据库异常分析过程
Posted Liu的性能测试江湖
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了记一次压测中Mysql数据库异常分析过程相关的知识,希望对你有一定的参考价值。
记录某次压测过程中出现了mysql数据库服务异常停止的整个分析过程,如何通过压测场景现象分析其本质性能问题,本章节中介绍了整个分析方法,希望对大家有借鉴作用。
压测场景介绍:
场景描述:某项目稳定性压测场景,中等压力(400tps)执行12小时。
问题描述:场景执行4小时后,TPS下降为0交易大部分超时报错。
部署架构:nginx+APP容器部署,Mysql数据库单独部署(配置16C32G)
问题分析过程:
1、应用层面分析,通过应用监控和日志分析并未发现应用层面存在OOM等异常。
2、数据库层面分析,查看报错后数据库服务器发现数据库进程停止了,通过应用日志发现4小时后大量有连接数据库失败信息
有以上初步分析结果为数据库存在问题,对数据库进行细化分析。
1)重点分析数据库的mysqld.log日志,查看异常点的错误信息,主要的报错信息如下:
2) 从数据库日志中也没有得到有效的指定信息,查看数据库的资源消耗情况,是否存在异常的情况
3) 从数据库整体资源监控看,CPU消耗很正常,但是磁盘IO消耗异常,特别是发生异常的前后。
以此分析数据库存在异常,跟磁盘IO相关,继续细化分析。
a、 当发生异常时,场景得到的响应耗时增长很大,tps下降为0,如果是数据库问题导致,是否存在慢SQL导致。查看数据库慢SQL日志进行分析(具体慢SQL的查看过程请查看之前文章获取)
b、 通过对应发生异常的时间点的慢SQL,发现存在异常慢SQL,耗时达到100秒到1000秒
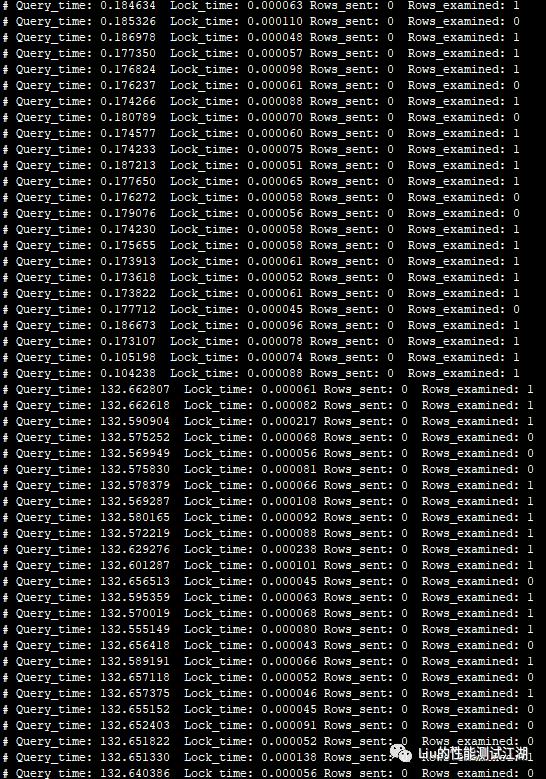
c、 细化分析慢SQL,发现慢SQL都存在操作同一个表,并且SQL比较简单,耗时细分统计发现几乎全部的耗时都是Sync_time导致,由此判断是SQL消耗都在binlog落盘的时间开销
怀疑是当时IO较高导致binlog落盘很慢,导致整体耗时较高
查看一下关于Sync_time相关的数据库参数,发现其中一个是sync_binlog,sync_binlog
设置成了1,也就是每次提交事务都将binlog的缓存写入到磁盘,这样的话会严重影响了磁盘的效率。根据查询相关资料,建议将此值修改为1000。
后续分析:
1、 其他的慢日志分析,1秒以内的SQL分析,发现Flush_time消耗较高
2、 查询跟Flush_time相关的参数为innodb_flush_log_at_trx_commit,设置为1,也就是每次提交事务,都会将innodb日志缓存写入磁盘,将其设置成2,每次事务提交是mysql都会把log buffer的数据写入到log file,但是flush操作不会同时进行,1的情况下每秒执行一次flush操作。通过相关资料查询建议修改此变量为2。
修改验证:
综上分析修改以上两个参数
set global sync_binlog=1000;
set global innodb_flush_log_at_trx_commit=2;
修改后进行场景回归执行验证,执行稳定性场景并未出现TPS下降异常和数据库进程异常。
后续建议:
由于修改以上两个参数影响到binlog的落盘频率,有可能会存在数据不同步的风险,因此生产为了安全考虑不允许修改,需要从其他方面入手改善对binlog的落盘压力。
1、在应用层考虑减少有更新操作的事务数量
2、更换跟生产数据库同样的服务器硬件配置,特别是磁盘存储设备。
整体分析思路:
现象(压测表现TPS下降为0)-应用分析-数据库分析-IO异常-慢SQL分析-binlog落盘影响-修改回归验证-最终建议
壁坑建议:
1、性能问题修复验证通过的结果不一定是最完美的结果,一定要结合生产进行综合评估。
2、Mysql数据库在压测吞吐较大的情况下,binlog落盘对于磁盘IO的消耗较高,如果叠加高频率的insert和索引维护会极大消耗磁盘IO,建议压测前数据库服务器的存储保持和生产一致,避免磁盘IO消耗成为瓶颈。
3、在项目开发中对于数据库事务提交,建议减少单次提交频率进行批量提交。
以上是关于记一次压测中Mysql数据库异常分析过程的主要内容,如果未能解决你的问题,请参考以下文章