记一次mysql性能优化过程
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了记一次mysql性能优化过程相关的知识,希望对你有一定的参考价值。
摘要: 所谓mysql的优化,三分是配置的优化,七分是sql语句的优化,通过一些案例分析,希望给大家在工作中带来一些思路
由于配置是运行过那么长时间,很稳定,基本上不考虑,所以本次主要是sql的优化,并且集中在开源中国的个人空间。下面是这次优化的数据库版本:
案例一:粉丝查询优化
粉丝查询有2条sql
--查询所有粉丝
SELECT user FROM osc_friends f INNER JOIN osc_users u
ON u.id=f.user AND f.friend=? AND f.user<>? ORDER BY create_time DESC
--查询粉丝数量
SELECT COUNT(friend) FROM osc_friends f INNER JOIN osc_users u
ON u.id=f.user AND f.friend = ? AND f.user <> ?这两个查询在业务可以优化,inner join一个osc_users表目的是去掉osc_friends里面自带了自己的userid,偏偏osc_users表是比较大的表,为啥这样设计,可以看看早年红薯分享的OSChina 用户动态设计说明
优化思路
简化sql,自带的userid的逻辑放到代码层去处理
优化后
SELECT user FROM osc_friends f WHERE f.friend=? ORDER BY create_time DESC
SELECT COUNT(*) FROM osc_friends f WHERE f.friend = ?sql简化了很多,大大提升了查询速度
小结
有时候业务处理放到代码层,能达到意想不到的效果
案例二:私信优化
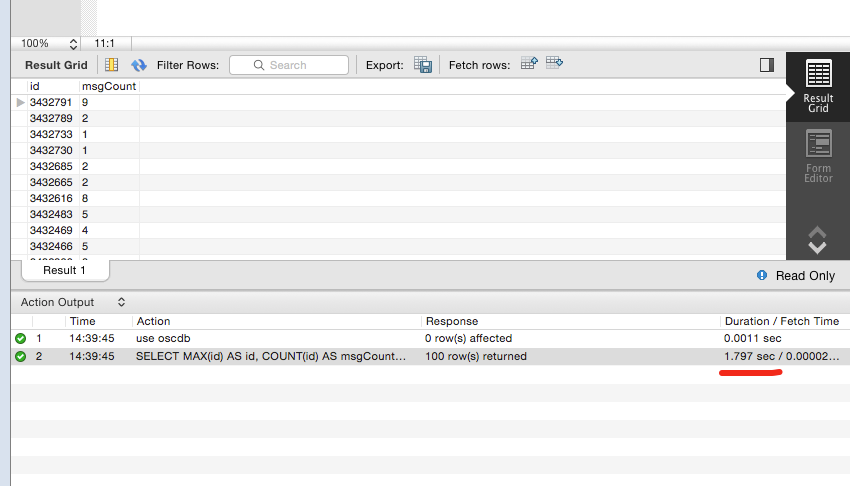
SELECT MAX(id) AS id, COUNT(id) AS msgCount
FROM osc_msgs WHERE user = 12 GROUP BY friend ORDER BY id DESCosc_msgs表存储着所有的私信纪录,随着时间推移,该表慢慢变大,一次查询成本变高,基本都要1秒多
优化思路
取私信表的最新的两个人的对话放入一个新建的osc_last_msgs表,每次发私信更新osc_last_msgs表,这个表只记录最新的私信,这样优化后的私信列表sql就不需要在msg表里面找数据,只需要去osc_last_msgs表寻找.
优化后
SELECT * FROM osc_last_msgs WHERE user=? ORDER BY msg_id DESC
小结
把数据量从大化小的典型案例
案例三 评论优化
SELECT
l1.id
FROM
osc_opt_logs l1,
osc_opt_logs l2
WHERE
l1.obj_type IN (101, 111, 113, 116, 119, 121)
AND l2.obj_type IN (
100,
110,
112,
114,
118,
120,
123,
124,
122,
125,
126,
127,
99
)
AND l1.parent_id = l2.id
AND l2. USER = 12
ORDER BY
l1.id DESC
LIMIT 20;尝试建立联合索引进行优化,不过效果不佳,因为optlog表特别的大,因此联表查询效率极低,占用查询缓存空间极大。
优化思路
添加一个reply_user字段,将回复的动弹进行标记,这样子就可以简化整个联表查询操作
优化后
SELECT id FROM osc_opt_logs where reply_user = 12 ORDER BY id DESC limit 20;小结
适当的冗余字段可以降低sql的复杂度
案例四 索引优化
索引优化主要还是依赖explain命令,关于explain命令相信大家并不陌生,具体用法和字段含义可以参考官网explain-output,这里需要强调rows是核心指标,绝大部分rows小的语句执行一般很快。所以优化语句基本上都是在优化rows。
一般来说.
- rows<1000,是在可接受的范围内的。
- rows在1000~1w之间,在密集访问时可能导致性能问题,但如果不是太频繁的访问(频率低于1分钟一次),又难再优化的话,可以接受,但需要注意观察
- rows大于1万时,应慎重考虑SQL的设计,优化SQL
这个没有绝对值可参考,一般来说越小越好,,如果100万数据量的数据库,rows是70万,通过这个可以判断sql的查询性能很差,如果100万条数据量的数据库,rows是1万,从我个人的角度,还是能接受的。
另外就是extra的信息,该列包含MySQL解决查询的详细信息 ,重点关注出现关键字:
Using filesort:当Query 中包含order by 操作,而且无法利用索引完成排序操作的时候,MySQL Query Optimizer 不得不选择相应的排序算法来实现。
Using temporary:在某些操作中必须使用临时表时,在 Extra 信息中就会出现Using temporary ,主要常见于 GROUP BY 和 ORDER BY 等操作中
当执行计划Extra 出现Using filesort 、Using temporary 时,可以考虑是否需要进行sql优化和调整索引,最后再调整my.cnf 中与排序或者临时表相关的参数,如sort_buffer_size或者tmp_table_size.
比如下面这个:

原因是mysql查询只使用一个索引,如果where字句用了索引的话,那么order by 中的列是不会使用索引的。所以order by的条件也需要添加到索引里面组成联合索引,优化后

还有一个需要注意的点是,索引有个最左前缀的原则:联合索引(a,b,c)可以匹配(a)、(a,b)、(a,b,c)但不可以匹配(b,c)
小结
explain SQL语句应该是日常开发中的习惯动作,有时explain出来的结果,可能会出于偏离设计的意料之外
案例五 关注数据库状态
当满满期待优化后有大幅度性能提升的时候,现实总是跟你开玩笑,经过测试检查,发现不是sql的问题,有可能是跟服务器有关,用top命令看了发现mysql进程的cpu占用率一直在100%左右,这就奇怪了,用show processlist看了一下mysql的进程,发现一个可疑的sql一直在执行,kill 掉后cpu占用率马上下来了

小结
当你发现数据库cpu或者io有异常现象时候,用show processlist看看数据库在忙什么
写在最后
经过这次优化,个人空间打开速度提升了,总结几条心得:
1.不要指望所有SQL语句都能通过SQL优化,业务上的调整带来意想不到的效果;
2.所有的性能优化都是空间换时间,通过冗余来提高性能,大体思路都是大化小,分而治之
3.explain是sql优化的入门
4.索引利大于弊,多用,善用之
如果再卡,可能会从分库分表,读写分离这方面入手了。
优化前跟优化后的mysql是大大的不同,同样用mysql,支撑起了淘宝,腾讯,facebook,但却对你的业务系统支撑起来很吃力?
以上不正之处请指出。
以上是关于记一次mysql性能优化过程的主要内容,如果未能解决你的问题,请参考以下文章