自动驾驶中神经网络模型量化技术:INT8还是INT4?
Posted 黑芝麻智能科技
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了自动驾驶中神经网络模型量化技术:INT8还是INT4?相关的知识,希望对你有一定的参考价值。
编者按:在自动驾驶领域,神经网络的模型量化技术是一个研究热点。本文主要讨论在维持实时性与安全性两项重要指标的同时,INT8与INT4的模型量化数据比较,并揭示了INT8作为当前市场主流技术的原因。
作者 | 黄浴 黑芝麻智能自动驾驶技术研究副总裁
背景介绍
如今深度神经网络(DNN)已成为大多数AI应用程序中的常见算法,比如计算机视觉、语音识别和自然语言处理等方面,这些网络所表现的超强能力使其成为AI历史的里程碑。但是,它们一方面具有最先进的性能,另一方面却需要巨大的计算能力。因此可以看到,已经有许多硬软件的优化技术以及专门的体系结构开发,在不影响其准确度的情况下,能够高性能和高效率地运行这些模型【8】。
在AI最具有挑战性应用之一的自动驾驶系统中,DNN的优秀表现也比比皆是。对于自动驾驶领域而言,实时性和安全性这两项要求远超其它领域的指标。
NN模型加速和优化技术大致分为四个方案:参数量化、剪枝和共享、低秩分解、迁移/紧凑卷积滤波器和知识蒸馏等【1】。参数量化、剪枝和共享的方法探索模型参数的冗余,并尝试删除冗余和非关键参数。低秩分解的技术使用矩阵/张量分解来估计DNN的信息参数。迁移/紧凑卷积滤波器的方法设计了特殊的结构卷积滤波器,以减少参数空间,并节省存储/计算量。知识蒸馏方法学习蒸馏模型,并训练更紧凑的神经网络以复现较大网络的输出。
DNN模型可以具有上亿个参数,在计算中要存储的数据很大。研究表明,在最佳情况下,可以预测神经网络中超过95%的参数。这意味着,更简单的模型参数化可以保持DNN的性能。量化(quantization)被认为是满足DNN模型内存要求的最有效方法之一。减少内存限制的主要技术之一是减少量化位宽或比特宽(bit width)【3】。
模型参数可以采用32位/比特浮点(FP32)格式表示,但不如以定点(fixed point)格式表示,因为这几乎没有精度损失,甚至更高,但计算量却较低。这种策略不仅可以减少占用的内存,还可以减少与计算相关的功耗。但是,DNN模型的每一层对准确性都有不同的影响,因此可以使用细粒度的混合精度量化方法,其中每层权重和激活值的位宽不同。
现在人们已经证明,FP32训练的参数可以改成8位/比特整数(INT8)做推理,没有显著精度损失,甚至训练时候采用INT8也可以。Xilinx 公司实验中发现INT8可以在一个批处理大小的推理中实现性能无损,不用重新训练。
另外,DNN对噪声也具有鲁棒性。在权重或输入上添加噪声,有时候可以获得更好的性能。随机噪声充当正则化项,可以更好地泛化网络。量化DNN的低精度操作,也被看作是不会损害网络性能的噪声。
模型量化
量化是通过一组离散符号或整数值去逼近一个连续信号的过程。大多数情况是指低比特量化(low bit quantization)。早在1990年代就有人提出了将浮点参数转换为数值精度较低的数据类型这种量化神经网络的方法。 从2010年代起,因为INT8被证明可以加速推理(inference)而不会显着降低准确性,人们对这项技术重新产生了兴趣。
大多数神经网络都使用FP32进行训练(training)。FP32参数表示其实精度比所需精度更高。将FP32参数转换为低位/比特整数表示可以显著地减少带宽、能耗和芯片面积。
量化参数通常可以加速神经网络推理,实际情况取决于处理器和执行环境。有时候降低精度并不总是能达到预期的加速比。例如,由于量化和反量化的附加操作,INT8推理无法在FP32实现4倍加速。例如谷歌TensorFlow-Lite 和英伟达TensorRT 的INT8推理速度也只提高了2-3倍。批处理大小(Batch size)是指前向传递中处理多个图像的能力,增加这个可让Tensor RT在INT8精度实现3-4倍的加速。
神经网络模型的偏差项(bias terms)在线性方程中会引入了截距。它们通常被视为常量,帮助网络训练并适配给定数据。由于偏差占用最少的内存(例如,10进-12出的全联接网络即FCL,有12个偏差值,对应120个权重值),所以一般建议偏差保持满精度。如果做偏差量化,则可以乘上特征尺度和权重尺度。
常见技术
量化方法的研究可分为两个领域:1)量化觉察训练(Quantize-awaretraining,QAT);2)训练后量化(Post training quantization,PTQ)。
PTQ指对训练的模型量化权重并重新优化模型以产生尺度化的量化模型。QAT则是指微调稳定的满精度模型或者重新训练量化的模型,这样实数权重通常会尺度化为整数值。
量化方法也可以根据数据分组量化的方式大致分类为:1)按层方式;2)按通道方式。按照参数的量化带宽,可以定义为N-比特量化。还有另外一种划分方法是:1)确定性(deterministic quantization)2) 随机性(stochastic quantization)/概率性。确定性量化,其量化值与实际值之间存在一对一的映射关系;而随机性量化,其权重、激活值或梯度是离散分布的,而量化值是从这些离散分布中采样而来。
如果要量化的目的是实现硬件加速,则应首选确定性量化,因为可以预先指定适当的量化级别,以便在专用硬件上运行量化网络,对硬件的性能预期得到改善。概率量化与确定性量化的不同之处在于,其量化的权重更易于解释。可以通过概率量化来了解权重的分布,并且可以深入了解网络的工作原理。由于贝叶斯方法的正则化效应,借助概率量化还可以拥有稀疏的模型。
注:参数聚类和共享的做法有些不同。部分量化(partial quantization)方法使用聚类算法(例如k-均值)对权重状态进行量化,然后将参数存到一个压缩文件中。权重可以使用查找表或线性变换进行解压缩。通常这是在执行推理(inference)时进行。FCL(全联接层)可以通过这种方法极大地压缩权重。不过,这种方案仅是降低了模型的存储开销。
半精度浮点数 (half precision FP16) 在英伟达GPUs和ASIC加速器已经普遍应用,精度损失很小。可以采用FP16混合精度做模型训练,包括权重、激活数值和梯度等更新和存储,其中权重更新的累积误差用FP32。这样的做法已经证明可达到最佳性能,甚至比原来的浮点数网络更好。
饱和量化(Saturated quantization)用于带标定集(calibrationdataset)的标定算法,可生成特征的尺度量。激活值量化后与以前的浮点数据具有相似的分布。Kullback-Leibler发散度(也称为相对熵或信息发散度)标定量化(calibrated quantization)方法已被广泛应用,对许多常见模型,这样可以在不降低精度的情况下做到网络提速。另外模型微调过程也可以采用这种方法。
参数量化可以看成是一个穷举搜索问题,优化中发现的尺度量可以减少误差项。给定一个浮点数网络,量化器采用最小化L2误差得到初始尺度量,用于量化第一层权重。然后,调整尺度找到最低输出误差。如此这样,每个层依次执行该操作,直到最后一层。
量化工具
随着量化技术的发展和成熟,已经出现了不少软件工具,一般是针对特定开发平台提供给用户。
TensorFlow-Lite(TF-Lite)是谷歌的开源框架,用于移动或嵌入式设备的模型推理。它也提供用于量化网络的转换和解释的工具。TF-Lite提供了PTQ和QAT两种量化方式。
TensorRT是英伟达开发的C++库,可在其GPU平台做高性能NN模型推理。其低精度推理库会消除卷积层的偏差项,需要一个标定集来调整每层或每通道的量化阈值。然后,量化参数表示为FP32标量和INT8权重。TensorRT采用预训练浮点数模型,并生成可重用优化的INT8模型或16比特半精度模型。英伟达Pascal系列GPU已启用低精度计算,然后图灵(Turing)架构为INT4和INT8两种精度引入了专用计算单元。
黑芝麻智能在自己独立开发的神经网络模型加速芯片(华山一号A500和华山二号A1000)基础上,在提供自动驾驶解决方案的同时,也提供了模型转换和优化的工具,同时支持PTQ和QAT两种量化方式。
量化精度的选择
虽然量化精度INT8已经被工业界普遍接受【2,6】,但是不是可以选择更小量化精度,比如4-比特/位整数(INT4),在学术界一直在进行认真研究,因为主要的担心是:在进一步减少存储空间和加速计算同时,模型性能下降甚至出现溢出(overflow)的可能风险也在增加。QAT量化方法在付出重新训练的代价后,采用INT4的量化模型应用场合会较大,但稳定性还是需要大量的实验验证,尤其是安全性要求很高的自动驾驶领域,大家不得不慎重考虑。
到底采用INT4还是INT8,学术界已经有不少研究工作报道。事实上,工业界INT4的量化产品市场上还是很少见【7】。
2018年谷歌发表一个量化网络推理的白皮书【2】,给出如下实验论断:
权重按通道量化,激活值按层量化,均是INT8的PTQ,对各种CNN架构发现,其分类性能和浮点网络的差在2%以内。
即使不支持8位整数算术,将权重量化为INT8模型大小也可以减少4倍,简单的权重PTQ可实现。
在CPU和DSP上对量化网络延迟进行基准测试:与CPU浮点数相比,量化模型实现的速度提高了2-3倍;具有定点数SIMD功能的专用处理器(例如带HVX的Qualcomm QDSP)提速高达10倍。
QAT可以提供进一步改进:在INT8情况下,其精度相对浮点数网络下降低1%;QAT还允许将权重降低到INT4,其性能损失从2%到10%,其中较小网络带来的性能下降更大。
在TensorFlow和TensorFlow Lite中引入量化网络工具。
QAT的最佳实践,可以量化权重和激活值来获得高精度。
建议权重的按通道量化和激活值的按层量化,这是是硬件加速和内核优化的首选方案。也建议用于优化推理的未来处理器和硬件加速器支持4、8和16位/比特精度模型。
2018年英特尔的研究报告【4】宣称一个4位/比特精度PTQ方法,但实际上是INT8和INT4混合精度,不需要训练微调量化模型,也不需要提供相关数据集。它以激活值和权重的量化为目标,采用三种互补方法最小化张量级的量化误差,其中两个获得闭式的解析解。这三种方法具体如下:
1)整数量化分析限幅(Analytical Clipping forInteger Quantization,ACIQ):其限制(即限幅)张量的激活值范围。虽然这会给原始张量带来失真,但会减少包含大多数分布情况的舍入误差。其通过最小化均方误差测量值,从张量的分布中分析得出最佳剪裁值。该分析阈值可以与其他量化技术集成。
2)按通道比特分配(Per-channel bitallocation):引入比特分配策略确定每个通道的最佳比特宽度。给定平均通道比特宽的限制,目标是为每个通道分配所需的比特宽,使总均方误差最小。通过对输入分布进行假设,发现每个通道的最佳量化步长与其范围的2/3幂成正比。
3)偏差校正(Bias-correction):发现量化后权重平均值和方差存在固有偏差。建议一种简单的方法来补偿这种偏差。
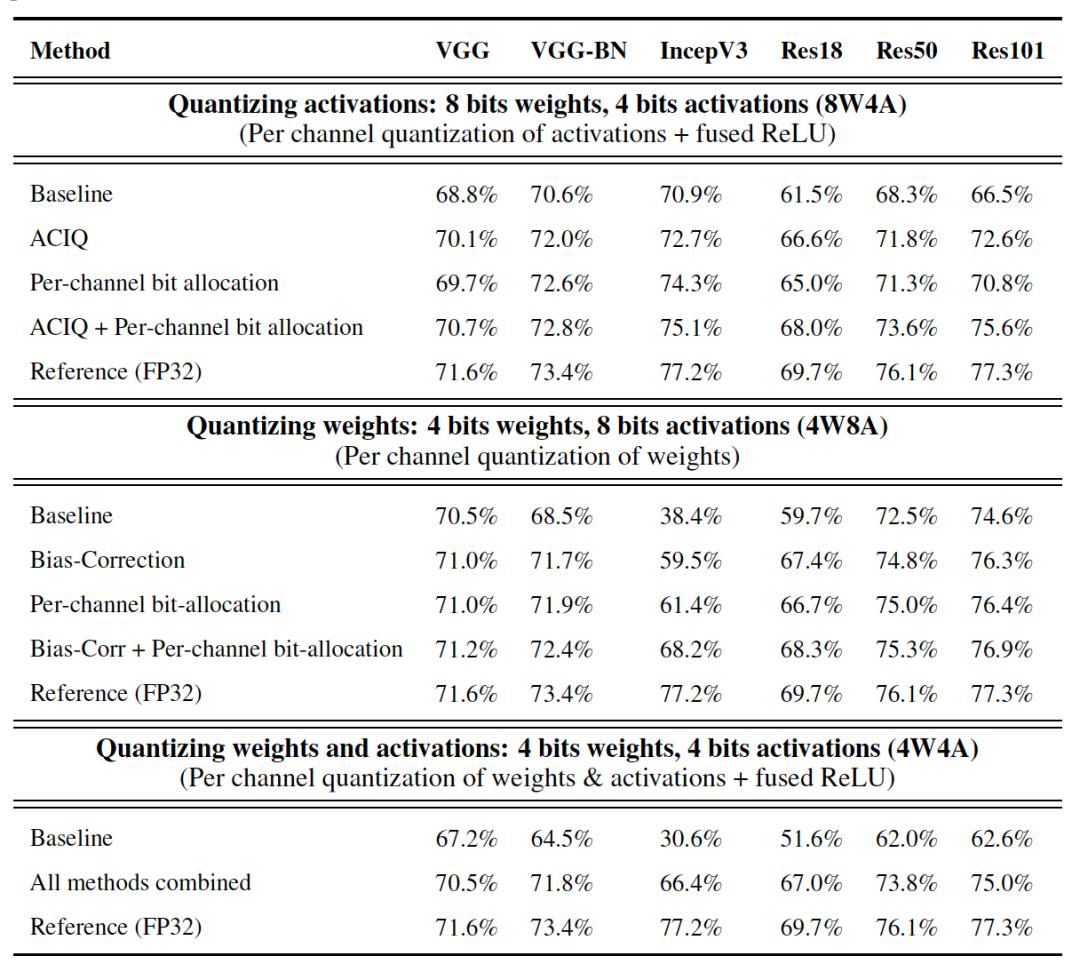
英特尔这个方法【4】在各种卷积模型中所达到的准确度仅比FP32基准低几个百分点。下表给出ImageNet Top-1验证的比较结果:
1)INT8权重和INT4激活值量化;
2)INT4权重和INT8激活值量化;
3)INT4权重和INT4激活值量化。
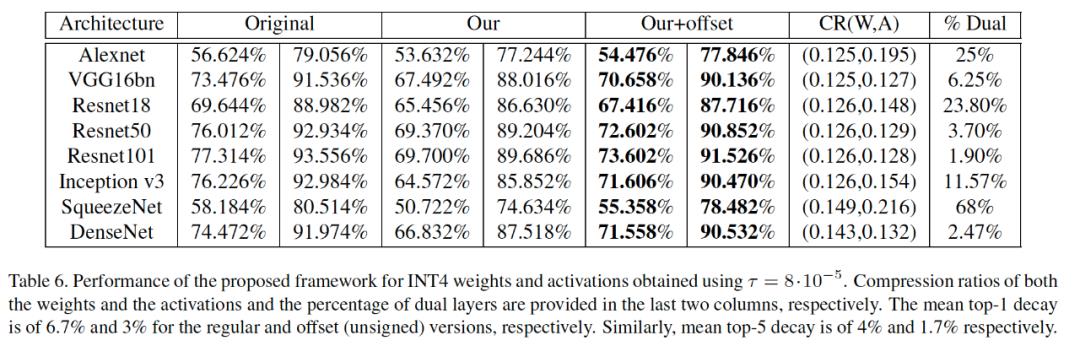
2019年华为发表的研究论文【5】提出线性量化任务可以定义成一个权重和激活值的最小均方误差(MMSE)问题,只是做低比特精度的NN模型推理,无需网络重新训练。其方法是在网络的每一层对受约束MSE问题进行优化,采用硬件觉察(HW-aware)方式对网络参数进行划分,对近似性较差的层使用多低精度量化张量方法。各种网络体系结构的多次实验,看到该方法做到了INT4模型量化。如下表给出实验中各种模型INT4量化权重和激活值的性能比较,即准确度损失和压缩率的对比。
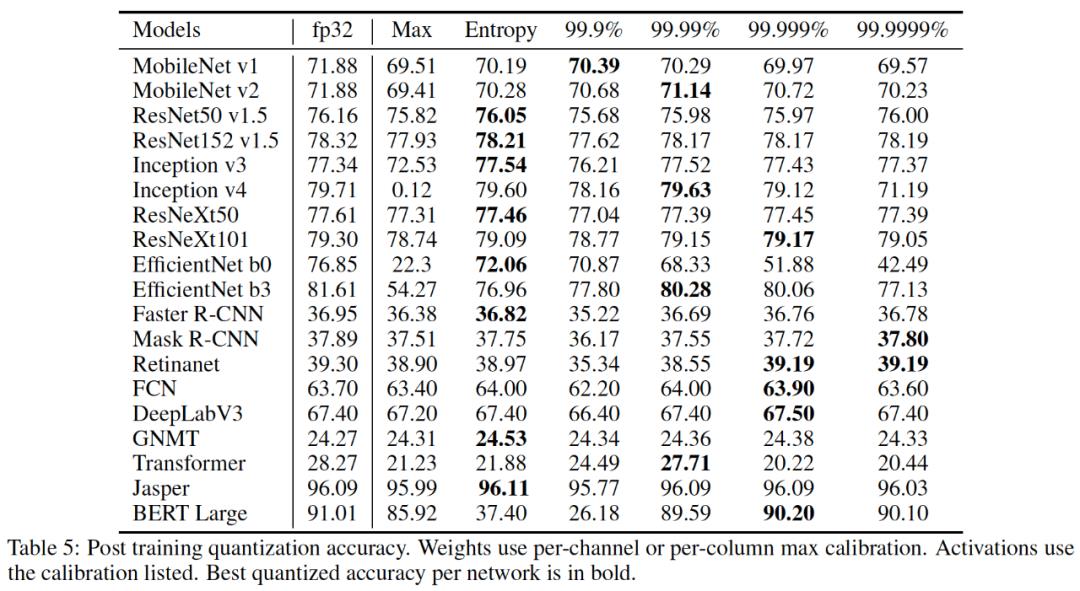
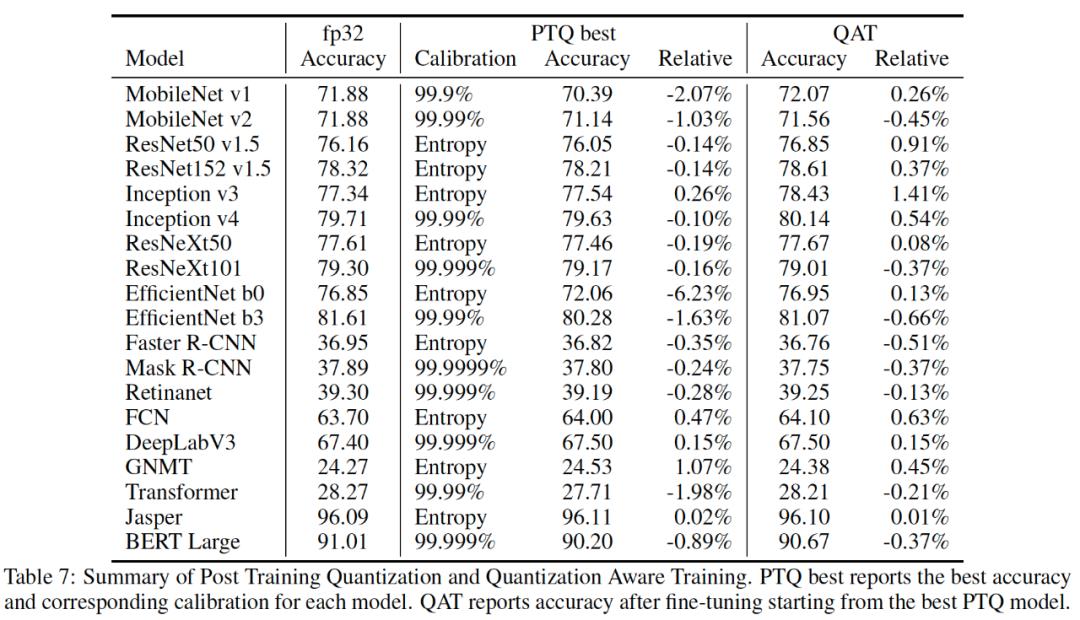
2020年英伟达论文提供了一个INT8量化工作的流程【6】,它将所研究的各种NN量化后模型和原浮点数模型的性能差别控制在1%以内,包括著名的MobileNets和BERT-large。以下两个表格给出了一些实验数据对比:
1)PTQ INT8 权重量化(按列或者按通道)
2)PTQ和QAT量化比较
最近加州伯克利分校论文【9】设计了一个2进制神经网络(Dyadic Neural Network),叫HAWQ-V3,是一个混合整数精度的量化网络,有特色的工作包括:
模型推理过程仅包括整数乘法,加法和移位(bit shifting),而无需任何浮点运算/转换或整数除法。
混合精度量化作为一个整数线性规划问题,在模型扰动和内存占用/延迟之间取得平衡。
在TVM开发第一个开源4位/比特和混合精度的量化工具,ResNet50模型部署到T4 GPU,与INT8量化相比, INT4的平均速度提高了1.45倍。
ResNet50模型INT8精度量化的准确度达到77.58%,比之前的整数量化性能高2.68%;而混合精度INT4/8量化比INT8的推理延迟降低23%,而准确度仍然达到76.73%。
结束语
可以看到定点数量化模型的位/比特越小,模型存储越小,执行加速越大,但相对浮点数模型的性能下降可能性越大,溢出的风险也越大。QAT相比PTQ来说,训练的负担带来的是量化性能的保证。
INT8在工业界已经是很常见的量化精度【2,6】,INT4精度还是需要测试NN模型量化后的性能下降是否可接受【7】。INT4/INT8混合精度应该是模型准确度和执行加速的一个折衷方案【4,9】。
在自动驾驶领域,NN模型量化必须要保证安全性的指标不能出现明显下滑,那么INT4精度显然承受的系统风险较大,估计在近几年的市场INT8仍然是自动驾驶NN模型量化的主流。
参考文献
[1].Y Cheng et al., “A Survey of Model Compression and Acceleration forDeep Neural Networks”,arXiv:1710.9182, 2018
[2].R Krishnamoorthi, “Quantizing deep convolutional networks forefficient inference: A white paper”, arXiv:1806.08342, 2018
[3].Y Guo, “ASurvey on Methods and Theories of Quantized Neural Networks”, arXiv:1808.04752,2018
[4].R Banner et al., “Post training 4-bit quantization of convolutionalnetworks for rapid-deployment”, arXiv:1810.05723, 2018
[5].Y Choukroun et al., “Low-bit Quantization of Neural Networks for EfficientInference”,arXiv:1902.06882, 2019
[6].HWu et al., “Integer Quantization For Deep Learning Inference: Principles AndEmpirical Evaluation”, arXiv:2004.09602, 2020
[7].Xilinx,“Convolutional Neural Network with INT4 Optimization on Xilinx Devices”,WP521 (v1.0.1) June 24, 2020
[8].TLiang et al., “Pruning and Quantization for Deep Neural NetworkAcceleration: A Survey”, arXiv:2101.90671, 2021
[9].ZYao et al., “HAWQ-V3: Dyadic Neural Network Quantization”, arXiv:2011.10680, 2021
往期推荐
以上是关于自动驾驶中神经网络模型量化技术:INT8还是INT4?的主要内容,如果未能解决你的问题,请参考以下文章