文本挖掘:窥探南方公园中的对话
Posted HelloooWorld
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了文本挖掘:窥探南方公园中的对话相关的知识,希望对你有一定的参考价值。
数据预处理
下载了south park前18季的脚本之后,先用Stanford CoreNLP做词干提取(stemming),词形还原(lemmazation), 去掉英文中没有太多含义的stop words(me, is...),下面再把经过正规化的脚本输入模型。
对话分析
谁最话痨?
如果把南方公园里的词数量按角色统计,谁说话最多?答案无疑是小胖Cartman!绝对的主角,各种主线的开拓者,吐槽最多语速最快的都是他。我们的前十五大话痨的统计结果里,小胖的词数近乎是另两位主角Kyle和Stan的两倍。紧随其后的是二爹和Butter,其余的角色说话多的有几对孩子爹妈,老师,其他同学。
谁在对谁说话?
在全18季中,看看谁和谁在对话?看看下面的对话流向图便知。
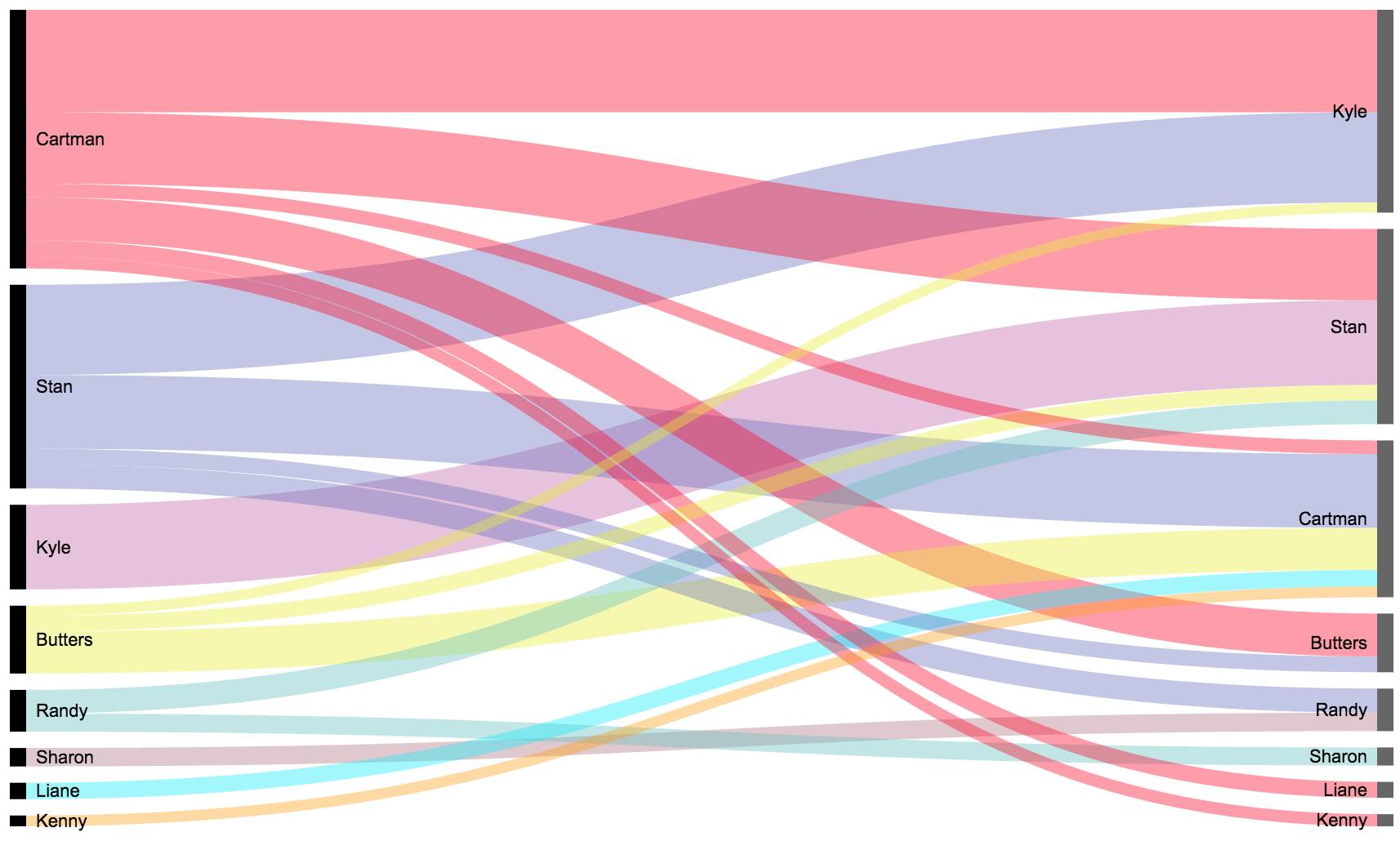
Cartman大部分的时候都在对Kyle,Stan和Butter讲话,偶尔自言自语,偶尔Kenny也会回应一下。Cartman的妈妈Liane虽然没出现在前15大话痨当中,却是Cartman的高频对话对象,看来小胖没事也是要找妈妈的。
二爹Randy常用的对话对象分别是儿子Stan和媳妇Sharon。这说明南方公园的人物场景设计以好友和家庭关系为核心开展。
从这个对话图中可以看到的另外一点是人物关系,比如全季度对话流中Cartman的人物关系最复杂,和各种各样的角色都有联系,这种关系会不会随时间变化呢?
对话对象随时间变化吗?
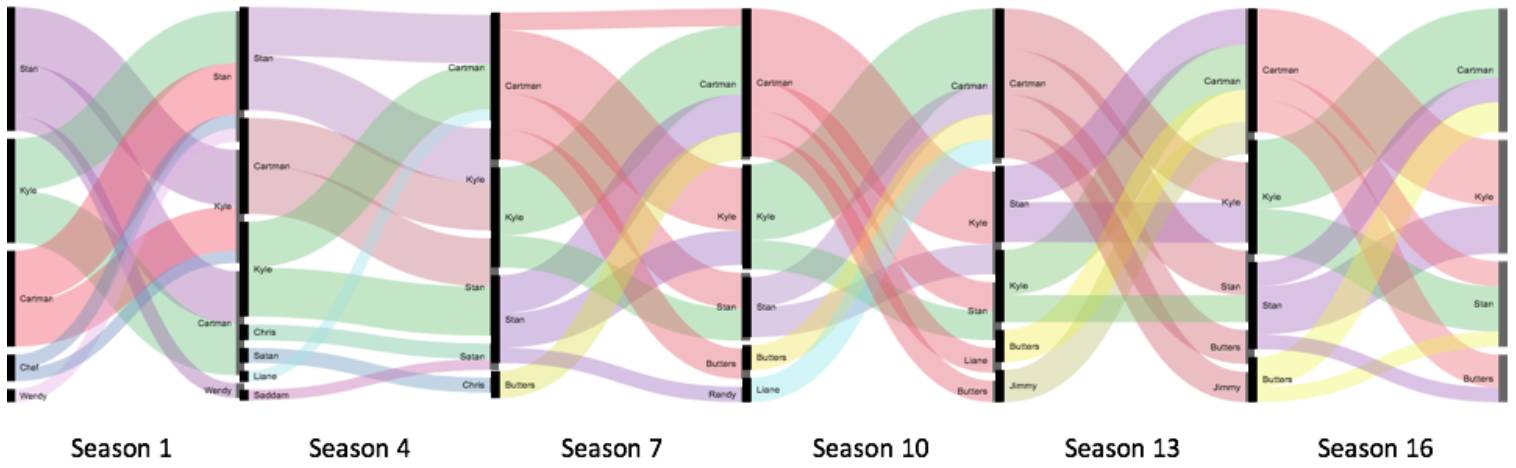
答案是yes,紫色的线条代表着从第一季开始挑大梁的Stan,紧接着到第四季里Stan的对话就被砍了,人物关系也简单许多,从第七季开始胖子(红)开始成为主角,Butter(黄)的对话也开始多起来。这说明随着时间的推移,编剧对角色的定位做了适量的改变。
话题分析
下面对具体对话内容进行分析。如果对已有的语料做bag of words假设(忽略语序),可以生成episode-term matrix,即对每个出现的词在每一集中出现的次数进行统计。用Latent Dirichlet Allocation 生成50个 topics,然后计算每一集最有可能的3个topics。为什么是3个而不是一个呢?可以看到前几个topics中有两个 topics是非常口语化的词,在South Park每个剧集中都大量出现,所以大部分剧集都会被标记上这两个常用topics;然后我们真正想留下的是每一集的个性化主题,所以选择抽取每个episode前3个topic中出了topic 1,2以外的主题做标记。
话题演变吗?
标记结果是,48个主题在前九季和后九季中的占比演变情况:
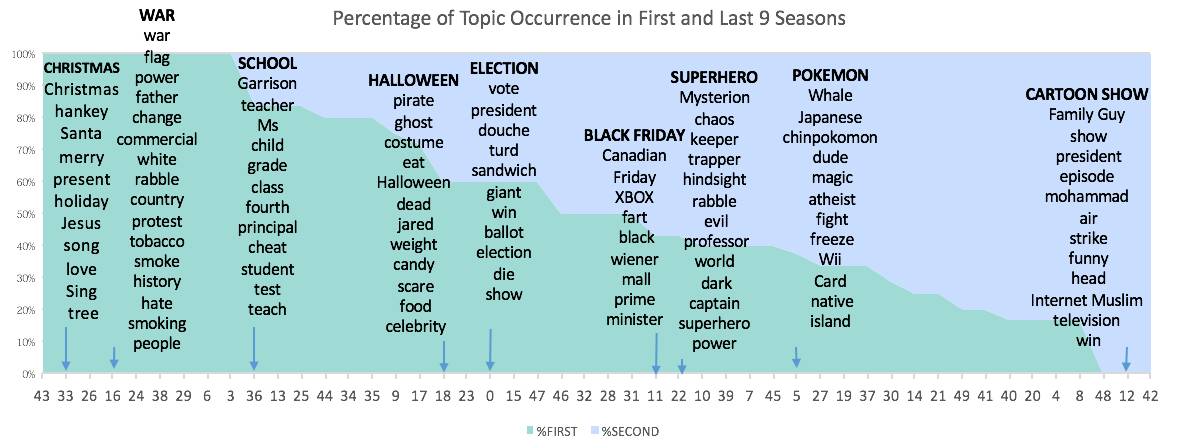
前九季里大量的学校,圣诞节和战争主题,逐渐过渡到后九季的电子游戏和黑同类卡通Family Guy。其中不乏总统竞选,黑五,超级英雄,万圣节等在前九季后九季都很受欢迎的主题。
不同人物话题不同?
除了分集主题归纳,还可以对人物话题进行归纳。

从Stan-Kyle经典组合,到凯子爸妈,到语句颇为正式的播音员,到俩变态老师,还有用语不正式的Cartman组,每一组用词反应出不同的语言习惯。
情感分析
一直想对不同季做情感分析,但一般的sentiment analysis只给出positive和negative两个标注,所以我们转向了商业试用产品IBM Watson的 tone analysis API,注册后获得credential就可以免费调用1000次接口了。
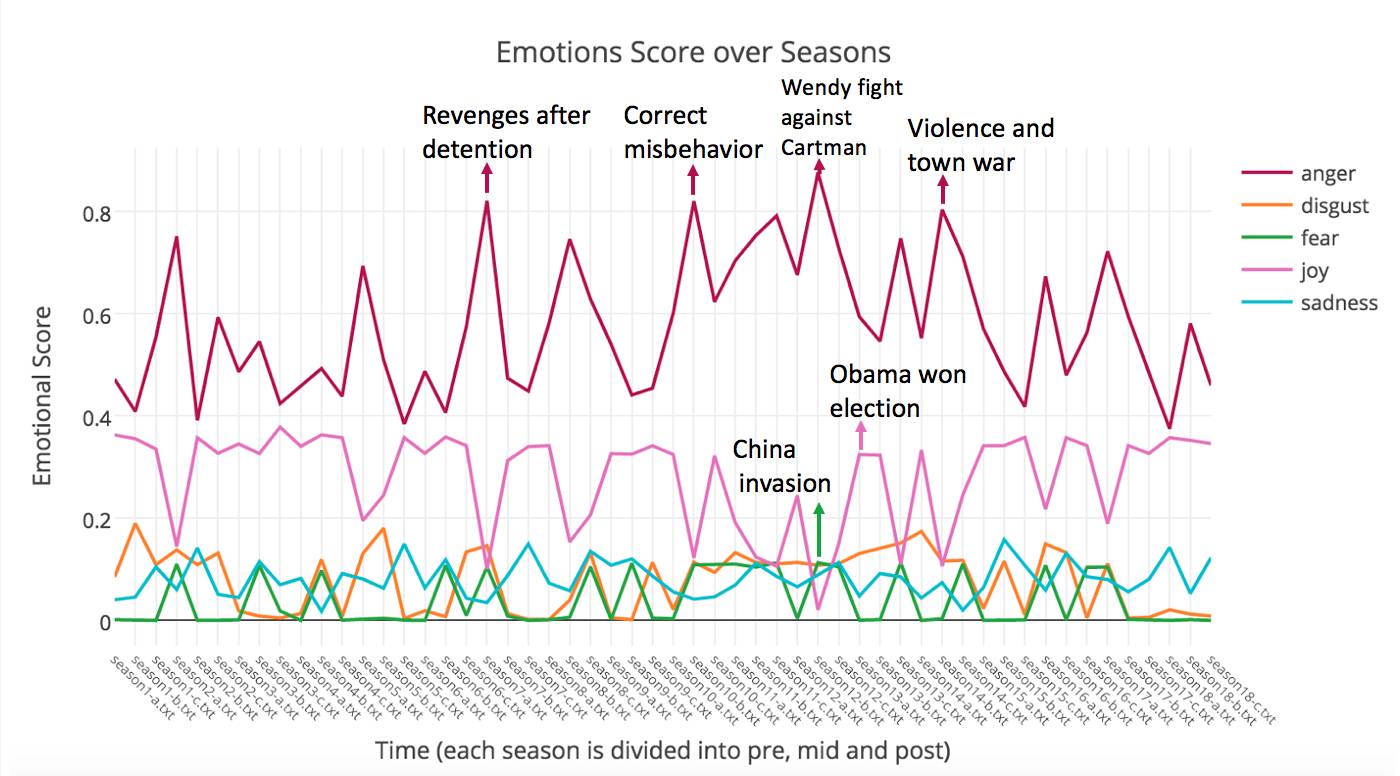
可以看到大部分剧集都有着很高的anger score(可能因为吐槽和脏话占大部分吧),做严重的几部分分别是第7季中间的复仇主题,第10季中间胖子妈纠正胖子行为,第12季 Wendy反抗胖子对她乳腺癌主题的研究,还有14季里新泽西入侵的town war。
另外一个有趣的观察是,fear score达到最高点的时候恰好是讲胖子看到2008年强大到开挂的北京奥运会以后担心中国崛起后入侵的。
还有就是joy score的一个高点是讲Obama赢选举的"About last night..."。
Kenny之死
sp经典老梗, “they killed Kenny?"。不想一次次追剧统计Kenny死了几次,只想写程序估算个趋势,就用Lucene library的query功能,寻找所有近似含有"kill Kenny"的语句,若Kenny的死没有出现在对话中,则不被记录。
可以看到Kenny的死主要在前两集里用到比较多,平均每0.75季kenny就会死一次,之后可能是这个梗被玩烂了编剧嫌没劲了,所以数量锐减,其中17,18集Kenny基本没死。
特殊名词词条统计
想知道Cartman最常提到谁吗?用CoreNLP的name entity recognition annotator抽取出来。看来Cartman最爱黑Jewish和Chinese了,最爱提的组织是Nintendo Wii还有KFC,最常问候的人除了三大主角还有Jesus他老人家。
这是我做过的最开心的一次作业了,不止因为做完就能毕业了,还因为对南方公园的数据挖掘真的能给人惊喜。想想自己一年半经历的各种project还有课程,都让我越来越喜欢data science,越来越喜欢think like a geek了,很高兴毕业后能在自己喜欢的行业和公司继续工作,继续遇到有趣的人,也祝愿所有读者都能在漆黑中找到照亮前路的明灯,play harder and laugh more!
以上是关于文本挖掘:窥探南方公园中的对话的主要内容,如果未能解决你的问题,请参考以下文章
8.0测试服BUILD26707文本挖掘 凯瑟琳与吉安娜对话