搜索引擎-Lucene | 技术达人
Posted 京西
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了搜索引擎-Lucene | 技术达人相关的知识,希望对你有一定的参考价值。
常用的搜索功能
对于搜索我们并不陌生,例如:“我的电脑”、“应用系统”、“百度”……
大家可以思考一下:以上几种搜索有什么相同点与不同点?
相同点:都是从输入条件中匹配出检索的结果。
不同点:查询范围不同(磁盘、数据库、互联网)。
我们都知道数据库搜索用like模糊查找,那么站内搜索、互联网搜索又是通过什么方式呢?他与数据库查找又有什么不同呢?接下来我们先从概念说起。
搜索引擎概念
搜索引擎由用户接口、索引器 、检索器和搜索器四个部分组成。
用户接口:输入用户查询、显示查询结果、提供用户相关性反馈机制。
索引器:理解搜索器所搜索的信息,从中抽取出索引项。
检索器:在索引库中快速检出文档,进行相关度评价,排序等。
搜索器:在互联网中漫游、发现和搜集信息。
索引器与检索器合称为全文检索技术。
全文检索概念
全文检索是:“从很多文本中建立索引并快速找出想要的数据”。
我们可以把这句话做一下分词:很多、文本、建立索引、快速查找、想要的数据。
解释一下各个词的含义:
很多:互联网海量的数据都能够处理。
文本:只处理文本内容,不处理视频,音频,语义等。
建立索引:这里举个例子:你要搜索“1+1等于几” 搜索结果会是包含“1+1等于几”的文本;而不是去理解你的语义而结果变成“2”。
快速查找:数据量再大必须要快速响应,一般在毫秒级别。
想要的数据:首先是数据要准确,其次要有相关度排名以及结果集列表等才算是想要的数据。
综上所述,我们可以简单将全文检索特点概况为:
1、准确、快速、结果列表、相关度排序;
2、只处理文本、不处理语义以及多媒体;
3、不同于数据库like查询数据库搜索不满足快速、准确、相关度排序等特点;
4、适用场景:站内搜索,如购物网,论坛,文章等。
全文检索总结:
全文检索——搜索引擎中的索引器与检索器统称,是抽象概念。
Lucene——实现全文检索的技术框架。
Lucene
1.建立工程
我们可以到apache官网下载Lucene开发包,开发环境只需要加入:
1、lucene-core-v.jar (核心包)
2、lucene-analyzers-common-v.jar (分词器)
3、lucene-highlighter-v.jar(高亮)
4、lucene-queryparser-v.jar (分词依赖)
5、lucene-memory-v.jar (高亮依赖)
建立普通Java项目导入以上jar,就可以开发了。
2.LuceneAPI概念
搜索引擎可以表示为下图:
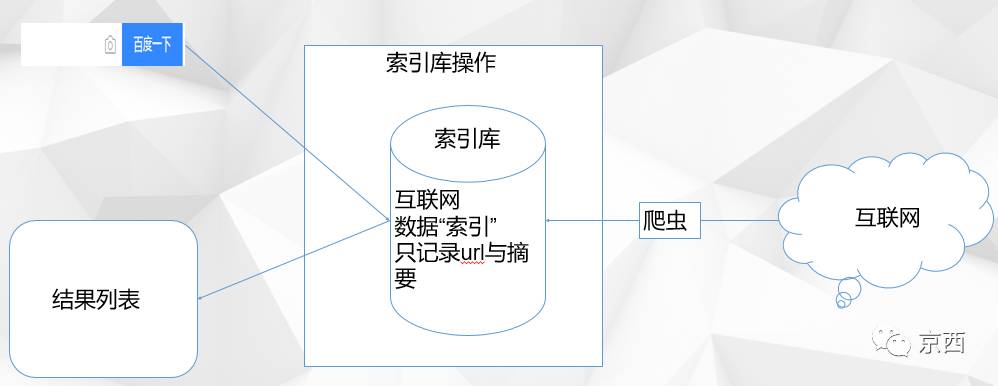
去头去尾,我们只关心索引库部分(全文检索),那么它又是如何工作的? 如下图:
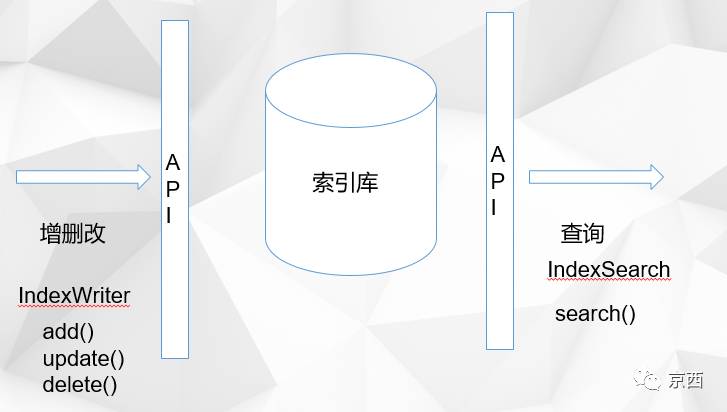
这时我们看到索引库分为两部分,查询与操作。其中操作部分提供了一个IndexWriter接口以及增,删,改方法。查询提供了IndexSearch接口以及search方法。
IndexWriter又是如何存入互联网数据的呢?其实很简单Lucene将所有文本都抽化成了一个对象:Document。
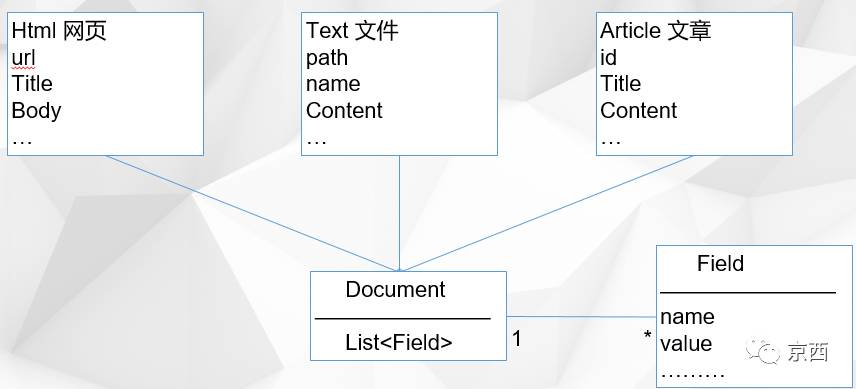
所有要保存的内容都转化成了Document对象,其中每个字段转化成Field,Field类似Map,存入key以及value。
举例:我想存入一篇html文章,只需要几个步骤:
1、new Document对象
2、new Field("url","baidu.com") ,new Field("body","body")
3、document.add(field1),document.add(field2)
我们在看上图document对象建立好以后,就可以用Lucene提供的API进行保存了。
下面贴出一个简单的代码实例,大家也可以思考一下:如何进行相关度排名,如何进行分词,如何将相关词高亮展示。索引库内部又是如何工作的,数据存储又是什么样的。
建立索引:

查询:


欲知后事如何,且听下回分解。
更多精彩内容点击“阅读原文”
以上是关于搜索引擎-Lucene | 技术达人的主要内容,如果未能解决你的问题,请参考以下文章
技术干货 | 搜索那点事儿:Lucene文件存储和读取技术详解