1K数据集+SpringBoot+Thymeleaf基于全文检索技术lucene开发的搜索引擎
Posted CodeLinghu
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了1K数据集+SpringBoot+Thymeleaf基于全文检索技术lucene开发的搜索引擎相关的知识,希望对你有一定的参考价值。
【1K数据集+SpringBoot+Thymeleaf】基于全文检索技术lucene开发的搜索引擎
一、需求分析
实现一个搜索框,能够索引指定数据集(数据取自数据库中)
实现索引内容的展示,图片展示
实现文本分类,排序等基础功能
索引数据量>1K (可自行爬取)
每次完成搜索能够进行一次评价一次检索效率
可做毕设/可做项目/大创
1.1、项目效果图展示
1.1.1前端页面展示:
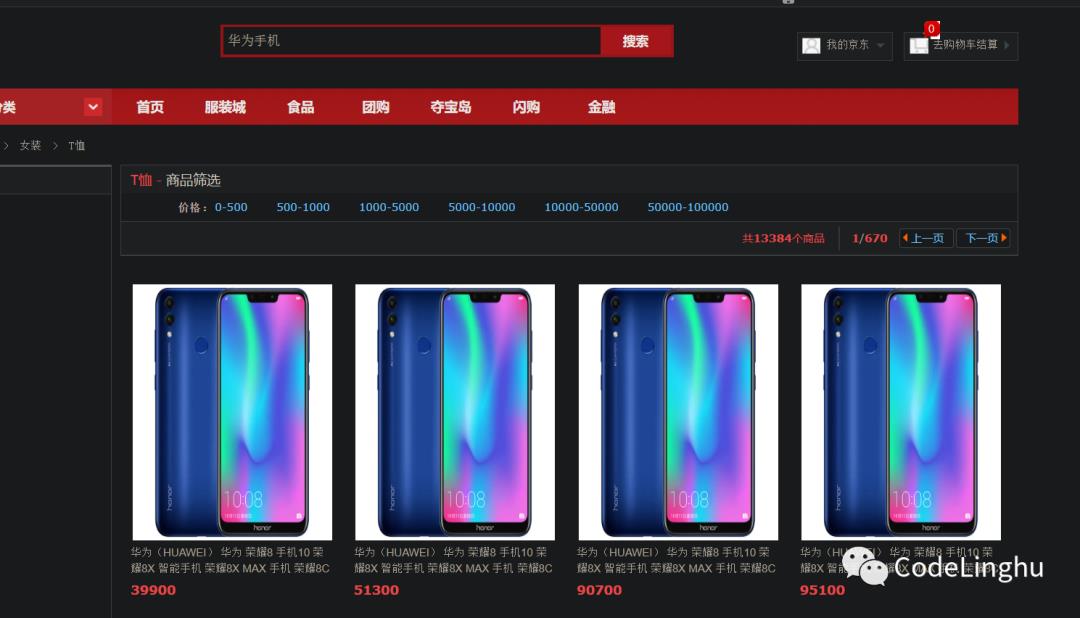
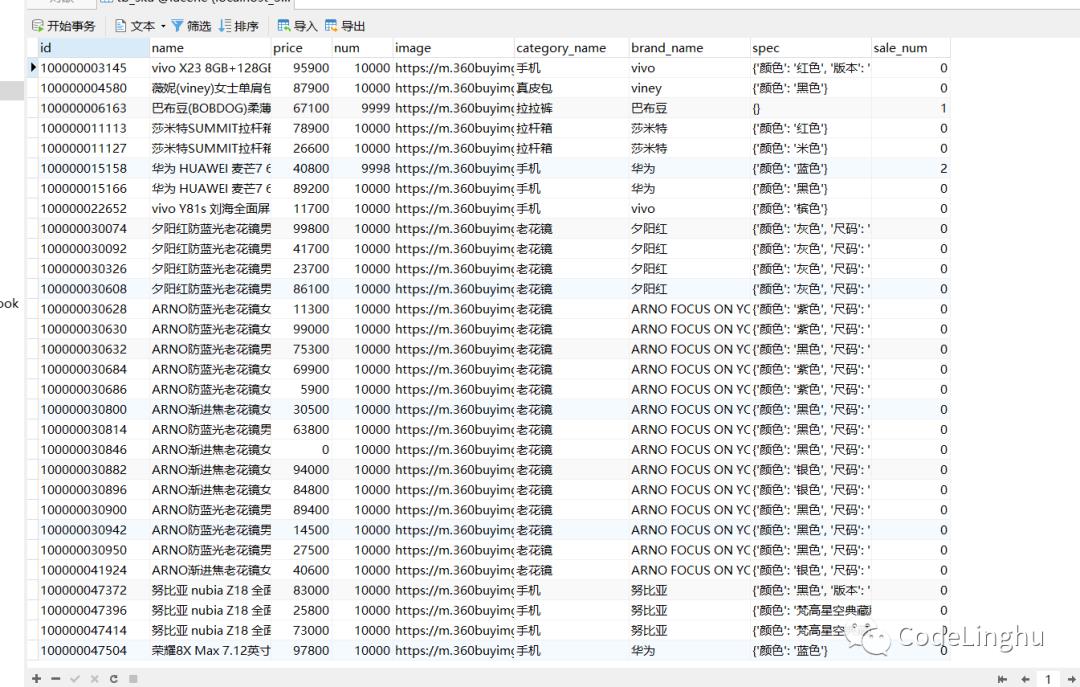
1.1.2数据库数据展示:
二、所用技术栈
SpringBoot
Thymeleaf模板渲染
mysql
ik中文分词
lucene 索引
json转换
HTML+CSS+JavaScript
2.1项目版本信息:
jdk1.8
mysql 5.7.29
lucene 7.7.2
maven 3.6.3
Windows 10系统
IntellJ IDEA 2019 2.14
Navicat for mysql 12.1.2
三、项目技术理论基础篇
本项目的重点是搜索/索引。所以我们首先认识一下所谓的搜索功能。
传统的搜索功能流程如图01-00.
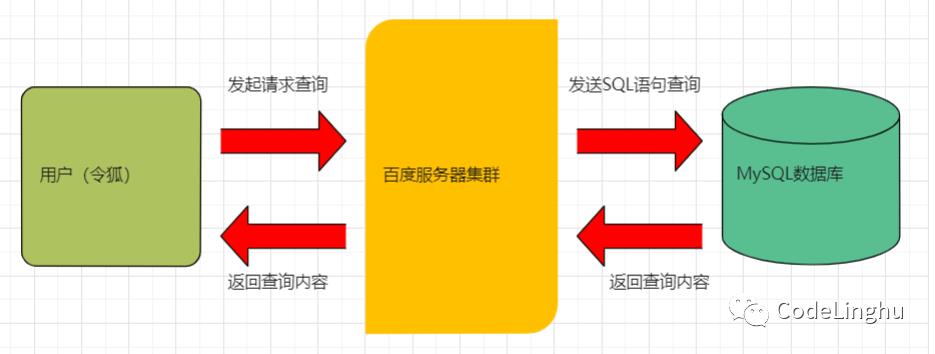
图01-00
以上搜索功能是目前企业中较为传统的一种搜索方式,其特点就是数据量少,承载不了高并发。
本项目所采用的搜索理论基础方案如图01-01.
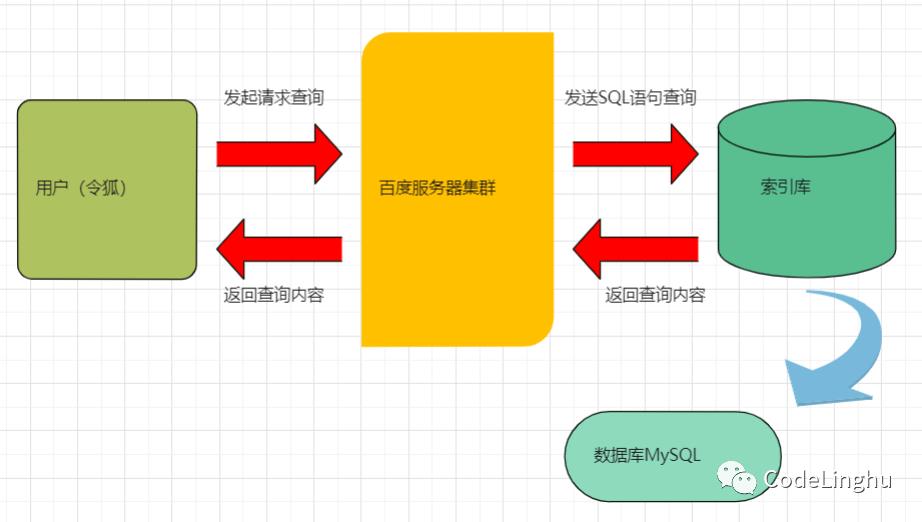
图01-01
使用新方案的优势:
降低了数据库压力
提升了数据库访问速度
通过lucene的API操作索引库访问数据库实现了业务与数据的有效隔离
数据查询有两种方案:
顺序查询
所谓顺序查询就是通过用户检索的内容进行字符串匹配,遍历所有的文档,当匹配到相同字符串便查询到当前文件,没有查到则继续扫描下一个文件,直到扫描完成所有文件。
倒排索引
倒排索引是指先将海量数据进行分词,形成一个索引表,查询时先查询索引表,通过索引表查询指定文件,这样可以做到有效去重查询相同内容文本的时间。为了做到倒排索引,我们才用的则是全文检索技术------lucene
3.1、Lucene相关认识(需要你认识到)
lucene是一种技术架构,不是一个成型的技术产品,而是半产品。
lucene是一个工具包,我们可以利用它完成索引工具的开发,制作属于自己的搜索引擎产品
Lucene在Java开发环境里是一个免费成熟的源代码工具
Lucene可以通过官方网站下载,当然我也会提供下载包链接()
Lucene是Apache公司的产品
Lucene实现全文检索的基本流程图:
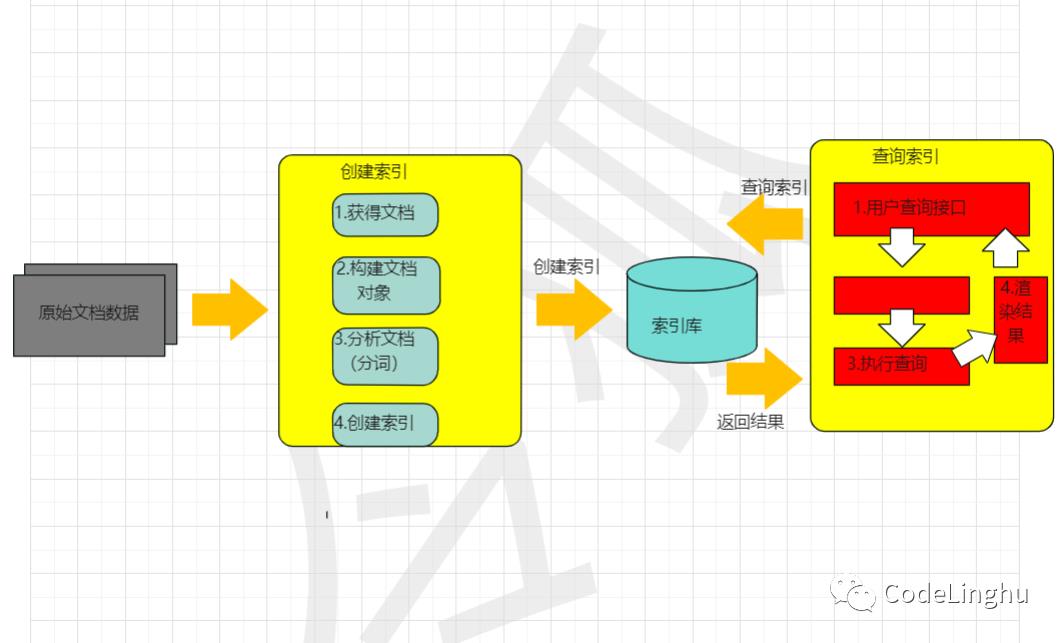
原始文档数据:
可以自行爬取数据,也可以用小哥提供的文档数据
文档数据放在小哥配套的文件夹(DataSources)里,是一个mysql文件,大家可以直接导入mysql即可。
文档:

拿到原始文档数据是为了建立索引,在索引前需要将原始内容创建文当
Document,文档Document中包含了许多 域Field分析文档(分词):
分析文档就是分词。将文档中的内容进行词组划分。
索引文档:
索引文档是为了更好地搜索。分词形成了词汇单元,通过索引词汇单元快速找到需要被索引到的内容。
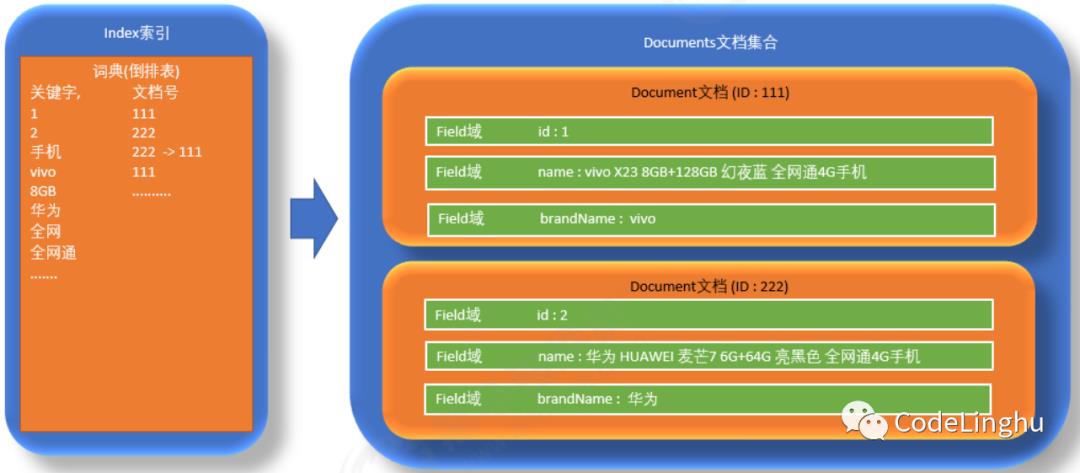
四、项目实战篇
4.1 Lucene的下载
可以通过官方网站下载lucene,也可以在小哥留的资料包里下载
解压后:
PS:queryparser:查询解析器
使用以上三个文件就可以实现本次项目中Lucene的功能。
4.2数据源下载
也在这个文件夹下面:

导入到mysql的效果:
4.3Java工程的创建
使用 DAO接口实现类获取mysql中的数据:
package cn.linghu.dao;
import cn.linghu.pojo.Sku;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.util.ArrayList;
import java.util.List;
/**
*
*/
public class SkuDaoImpl implements SkuDao {
public List<Sku> querySkuList() {
// 数据库链接
Connection connection = null;
// 预编译statement
PreparedStatement preparedStatement = null;
// 结果集
ResultSet resultSet = null;
// 商品列表
List<Sku> list = new ArrayList<Sku>();
try {
// 加载数据库驱动
Class.forName("com.mysql.jdbc.Driver");
// 连接数据库
connection = DriverManager.getConnection("jdbc:mysql://localhost:3306/lucene", "root", "123456");
// SQL语句
String sql = "SELECT * FROM tb_sku";
// 创建preparedStatement
preparedStatement = connection.prepareStatement(sql);
// 获取结果集
resultSet = preparedStatement.executeQuery();
// 结果集解析
while (resultSet.next()) {
Sku sku = new Sku();
sku.setId(resultSet.getString("id"));
sku.setName(resultSet.getString("name"));
sku.setSpec(resultSet.getString("spec"));
sku.setBrandName(resultSet.getString("brand_name"));
sku.setCategoryName(resultSet.getString("category_name"));
sku.setImage(resultSet.getString("image"));
sku.setNum(resultSet.getInt("num"));
sku.setPrice(resultSet.getInt("price"));
sku.setSaleNum(resultSet.getInt("sale_num"));
list.add(sku);
}
} catch (Exception e) {
e.printStackTrace();
}
return list;
}
}
4.3.1核心代码------实现索引流程:
\1. 采集数据
\2. 创建Document文档对象
\3. 创建分析器(分词器)
\4. 创建IndexWriterConfifig配置信息类
\5. 创建Directory对象,声明索引库存储位置
\6. 创建IndexWriter写入对象
\7. 把Document写入到索引库中
\8. 释放资源
package cn.linghu.test;
import cn.linghu.dao.SkuDao;
import cn.linghu.dao.SkuDaoImpl;
import cn.linghu.pojo.Sku;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.*;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.IndexWriterConfig;
import org.apache.lucene.index.Term;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
import org.apache.lucene.store.MMapDirectory;
import org.junit.Test;
import org.wltea.analyzer.lucene.IKAnalyzer;
import java.nio.file.Paths;
import java.util.ArrayList;
import java.util.List;
/**
* 索引库维护
*/
public class TestIndexManager {
/**
* 创建索引库
*/
@Test
public void createIndexTest() throws Exception {
//1. 采集数据
SkuDao skuDao = new SkuDaoImpl();
List<Sku> skuList = skuDao.querySkuList();
//文档集合
List<Document> docList = new ArrayList<>();
for (Sku sku : skuList) {
//2. 创建文档对象
Document document = new Document();
//创建域对象并且放入文档对象中
/**
* 是否分词: 否, 因为主键分词后无意义
* 是否索引: 是, 如果根据id主键查询, 就必须索引
* 是否存储: 是, 因为主键id比较特殊, 可以确定唯一的一条数据, 在业务上一般有重要所用, 所以存储
* 存储后, 才可以获取到id具体的内容
*/
document.add(new StringField("id", sku.getId(), Field.Store.YES));
/**
* 是否分词: 是, 因为名称字段需要查询, 并且分词后有意义所以需要分词
* 是否索引: 是, 因为需要根据名称字段查询
* 是否存储: 是, 因为页面需要展示商品名称, 所以需要存储
*/
document.add(new TextField("name", sku.getName(), Field.Store.YES));
/**
* 是否分词: 是(因为lucene底层算法规定, 如果根据价格范围查询, 必须分词)
* 是否索引: 是, 需要根据价格进行范围查询, 所以必须索引
* 是否存储: 是, 因为页面需要展示价格
*/
document.add(new IntPoint("price", sku.getPrice()));
document.add(new StoredField("price", sku.getPrice()));
/**
* 是否分词: 否, 因为不查询, 所以不索引, 因为不索引所以不分词
* 是否索引: 否, 因为不需要根据图片地址路径查询
* 是否存储: 是, 因为页面需要展示商品图片
*/
document.add(new StoredField("image", sku.getImage()));
/**
* 是否分词: 否, 因为分类是专有名词, 是一个整体, 所以不分词
* 是否索引: 是, 因为需要根据分类查询
* 是否存储: 是, 因为页面需要展示分类
*/
document.add(new StringField("categoryName", sku.getCategoryName(), Field.Store.YES));
/**
* 是否分词: 否, 因为品牌是专有名词, 是一个整体, 所以不分词
* 是否索引: 是, 因为需要根据品牌进行查询
* 是否存储: 是, 因为页面需要展示品牌
*/
document.add(new StringField("brandName", sku.getBrandName(), Field.Store.YES));
//将文档对象放入到文档集合中
docList.add(document);
}
//3. 创建分词器, StandardAnalyzer标准分词器, 对英文分词效果好, 对中文是单字分词, 也就是一个字就认为是一个词.
Analyzer analyzer = new IKAnalyzer();
//4. 创建Directory目录对象, 目录对象表示索引库的位置
Directory dir = FSDirectory.open(Paths.get("E:\\dir"));
//5. 创建IndexWriterConfig对象, 这个对象中指定切分词使用的分词器
IndexWriterConfig config = new IndexWriterConfig(analyzer);
//6. 创建IndexWriter输出流对象, 指定输出的位置和使用的config初始化对象
IndexWriter indexWriter = new IndexWriter(dir, config);
//7. 写入文档到索引库
for (Document doc : docList) {
indexWriter.addDocument(doc);
}
//8. 释放资源
indexWriter.close();
}
/**
* 索引库修改操作
* @throws Exception
*/
@Test
public void updateIndexTest() throws Exception {
//需要变更成的内容
Document document = new Document();
document.add(new StringField("id", "100000003145", Field.Store.YES));
document.add(new TextField("name", "xxxx", Field.Store.YES));
document.add(new IntPoint("price", 123));
document.add(new StoredField("price", 123));
document.add(new StoredField("image", "xxxx.jpg"));
document.add(new StringField("categoryName", "手机", Field.Store.YES));
document.add(new StringField("brandName", "华为", Field.Store.YES));
//3. 创建分词器, StandardAnalyzer标准分词器, 对英文分词效果好, 对中文是单字分词, 也就是一个字就认为是一个词.
Analyzer analyzer = new StandardAnalyzer();
//4. 创建Directory目录对象, 目录对象表示索引库的位置
Directory dir = FSDirectory.open(Paths.get("E:\\dir"));
//5. 创建IndexWriterConfig对象, 这个对象中指定切分词使用的分词器
IndexWriterConfig config = new IndexWriterConfig(analyzer);
//6. 创建IndexWriter输出流对象, 指定输出的位置和使用的config初始化对象
IndexWriter indexWriter = new IndexWriter(dir, config);
//修改, 第一个参数: 修改条件, 第二个参数: 修改成的内容
indexWriter.updateDocument(new Term("id", "100000003145"), document);
//8. 释放资源
indexWriter.close();
}
/**
* 测试根据条件删除
* @throws Exception
*/
@Test
public void deleteIndexTest() throws Exception {
//3. 创建分词器, StandardAnalyzer标准分词器, 对英文分词效果好, 对中文是单字分词, 也就是一个字就认为是一个词.
Analyzer analyzer = new StandardAnalyzer();
//4. 创建Directory目录对象, 目录对象表示索引库的位置
Directory dir = FSDirectory.open(Paths.get("E:\\dir"));
//5. 创建IndexWriterConfig对象, 这个对象中指定切分词使用的分词器
IndexWriterConfig config = new IndexWriterConfig(analyzer);
//6. 创建IndexWriter输出流对象, 指定输出的位置和使用的config初始化对象
IndexWriter indexWriter = new IndexWriter(dir, config);
//测试根据条件删除
//indexWriter.deleteDocuments(new Term("id", "100000003145"));
//测试删除所有内容
indexWriter.deleteAll();
//8. 释放资源
indexWriter.close();
}
/**
* 测试创建索引速度优化
* @throws Exception
*/
@Test
public void createIndexTest2() throws Exception {
//1. 采集数据
SkuDao skuDao = new SkuDaoImpl();
List<Sku> skuList = skuDao.querySkuList();
//文档集合
List<Document> docList = new ArrayList<>();
for (Sku sku : skuList) {
//2. 创建文档对象
Document document = new Document();
document.add(new StringField("id", sku.getId(), Field.Store.YES));
document.add(new TextField("name", sku.getName(), Field.Store.YES));
document.add(new IntPoint("price", sku.getPrice()));
document.add(new StoredField("price", sku.getPrice()));
document.add(new StoredField("image", sku.getImage()));
document.add(new StringField("categoryName", sku.getCategoryName(), Field.Store.YES));
document.add(new StringField("brandName", sku.getBrandName(), Field.Store.YES));
//将文档对象放入到文档集合中
docList.add(document);
}
long start = System.currentTimeMillis();
//3. 创建分词器, StandardAnalyzer标准分词器, 对英文分词效果好, 对中文是单字分词, 也就是一个字就认为是一个词.
Analyzer analyzer = new StandardAnalyzer();
//4. 创建Directory目录对象, 目录对象表示索引库的位置
Directory dir = FSDirectory.open(Paths.get("E:\\dir"));
//5. 创建IndexWriterConfig对象, 这个对象中指定切分词使用的分词器
/**
* 没有优化 小100万条数据, 创建索引需要7725ms
*
*/
IndexWriterConfig config = new IndexWriterConfig(analyzer);
//设置在内存中多少个文档向磁盘中批量写入一次数据
//如果设置的数字过大, 会过多消耗内存, 但是会提升写入磁盘的速度
//config.setMaxBufferedDocs(500000);
//6. 创建IndexWriter输出流对象, 指定输出的位置和使用的config初始化对象
IndexWriter indexWriter = new IndexWriter(dir, config);
//设置多少给文档合并成一个段文件,数值越大索引速度越快, 搜索速度越慢; 值越小索引速度越慢, 搜索速度越快
//indexWriter.forceMerge(1000000);
//7. 写入文档到索引库
for (Document doc : docList) {
indexWriter.addDocument(doc);
}
//8. 释放资源
indexWriter.close();
long end = System.currentTimeMillis();
System.out.println("=====消耗的时间为:==========" + (end - start) + "ms");
}
}
在E盘创建一个文件夹名为 dir作为我们的索引文件目录,执行代码成功之后, dir文件夹内会出现如图:
出现此图表示创建索引成功!
4.3.2pom文件中的依赖引入
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>cn.linghu</groupId>
<artifactId>luceneDemo</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding>
<skipTests>true</skipTests>
</properties>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.1.4.RELEASE</version>
</parent>
<dependencies>
<dependency>
<groupId>commons-io</groupId>
<artifactId>commons-io</artifactId>
<version>2.6</version>
</dependency>
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-core</artifactId>
<version>7.7.2</version>
</dependency>
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-analyzers-common</artifactId>
<version>7.7.2</version>
</dependency>
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-queryparser</artifactId>
<version>7.7.2</version>
</dependency>
<!-- 测试 -->
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
<scope>test</scope>
</dependency>
<!-- mysql数据库驱动 -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.48</version>
</dependency>
<!-- IK中文分词器 -->
<!-- <dependency>
<groupId>org.wltea.ik-analyzer</groupId>
<artifactId>ik-analyzer</artifactId>
<version>8.1.0</version>
</dependency>-->
<!--web起步依赖-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!-- 引入thymeleaf -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-thymeleaf</artifactId>
</dependency>
<!-- Json转换工具 -->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.51</version>
</dependency>
</dependencies>
</project>
后期还会进行项目总结,敬请期待。感谢支持!
跑项目之前需要在E盘建立一个
dir文件夹需要配置好数据库的信息/账户/密码
需要引入或导入相关的jar包
以上是关于1K数据集+SpringBoot+Thymeleaf基于全文检索技术lucene开发的搜索引擎的主要内容,如果未能解决你的问题,请参考以下文章
经典网络模型 ResNet-50 在 ImageNet-1k 上的研究 | 实验笔记+论文解读
SpringBoot入门篇--Thymeleaf引擎模板的基本使用方法
论文笔记:CTSpine1K: A Large-Scale Dataset for Spinal Vertebrae Segmentation in Computed Tomography